






1.介绍
原子操作是指在多线程环境中不会被中断的操作,即该操作在执行过程中不会被其他线程或进程打断,并以此确保了数据的一致性和完整性,避免了竞态条件,在多线程编程中,原子操作常用于实现同步机制,如互斥锁、信号量、原子变量等。 原子操作通常由硬件直接支持,执行效率高。
2.前置知识
2.1存储模型
我们都知道计算机组成里有CPU与主存,同时CPU的运算速度又远大于主存读写速度,为了解决这一现象,后续的CPU设计中引入了多级缓存,它平衡了主存与CPU的性能差异。同时,为了写出高性能的代码,我们应该尽量让缓存命中,避免CPU等待主存读取数据。
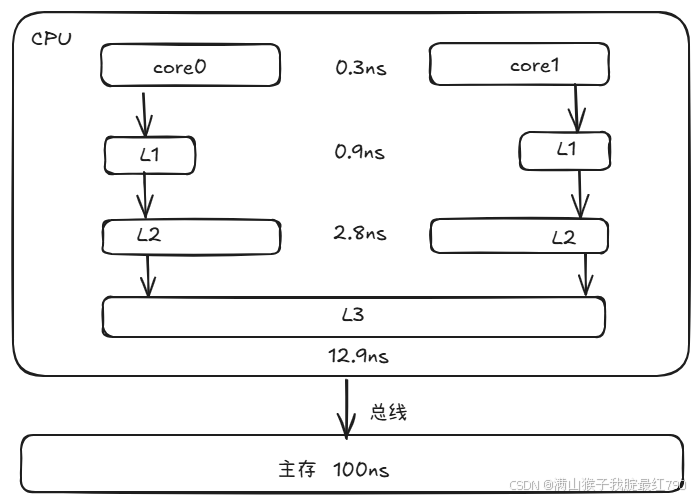
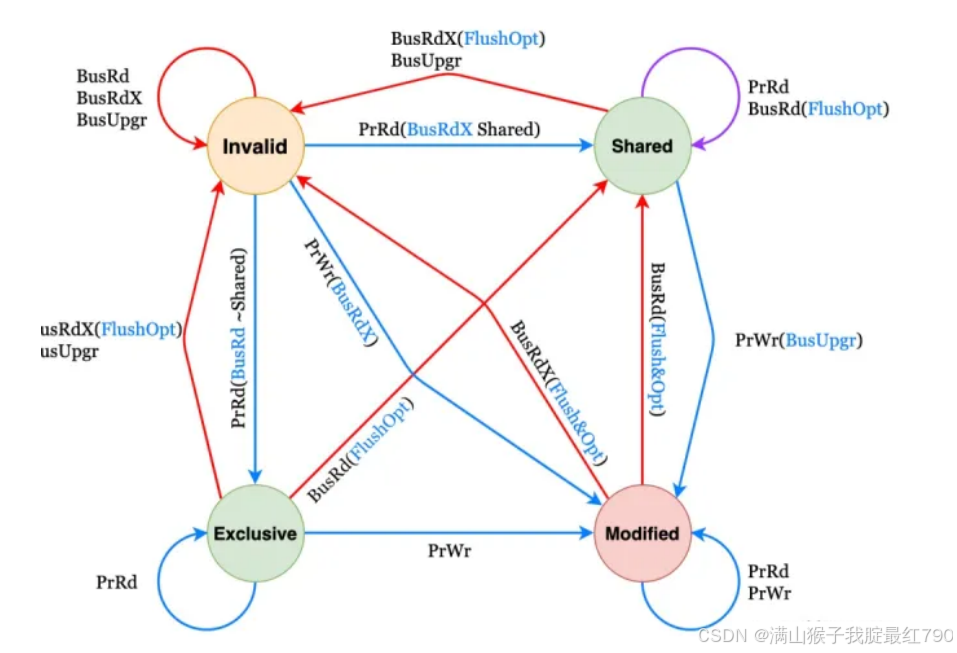
而为了保证缓存一致性,又有了缓存一致性协议(MESI),MESI 协议是一个基于失效的缓存一致性协议,支持 write-back写回缓存的常用协议。主要原理:通过总线嗅探策略(将读写请求通过总线广播给所有核心,核心根据本地状态进行响应)。
状态分为以下四种:
- Modified(M):某数据已修改但是没有同步到内存中。如果其他核心要读该数据,需要将该数据从缓存同步到内存中,并将状态转为S。
- Exclusive(E):某数据只在该核心当中,此时缓存和内存中的数据一致。
- Shared(S):某数据在多个核心中,此时缓存和内存中的数据一致。
- Invaliddate(I):某数据在该核心中以失效,不是最新数据。
主要事件:
- PrRd:核心请求从换存块中读出数据。
- PrWr:核心请求向缓存块写入数据。
- BusRd:总线嗅探器收到来自其他核心的读出缓存请求。
- BusRdX:总线嗅探器收到另一核心写⼀个其不拥有的缓存块的请求。
- BusUpgr:总线嗅探器收到另一核心写⼀个其拥有的缓存块的请求。
- Flush:总线嗅探器收到另一核心把一个缓存块写回到主存的请求。
- FlushOpt:总线嗅探器收到一个缓存块被放置在总线以提供给另一核心的请求,和 Flush 类似,但只不过是从缓存到缓存的传输请求。
对应状态迁移如下图:
2.2内存模型
这里所指内存模型对应缓存一致性模型,作用是对同一时间的读写操作进行排序。在不同的 CPU 架构上,这些模型的具体实现方式可能不同,但是 C++11 帮你屏蔽了内部细节,不用考虑内存屏障,只要符合上面的使用规则,就能得到想要的效果。可能有时使用的模型粒度比较大,会损耗性能,当然还是使用各平台底层的内存屏障粒度更准确,效率也会更高,对程序员的功底要求也高。具体分为以下几种:
- memory_order_relaxed:松散内存序,只用来保证对原子对象的操作是原子的,在不需要保证顺序时使用。
-
memory_order_release:释放操作,在写入某原子对象时,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去,并且当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见;通常与 memory_order_acquire 或memory_order_consume 配对使用。
-
memory_order_acquire:获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见。
-
memory_order_consume:同 memory_order_acquire 类似,区别是它仅对依赖于该原子变量操作涉及的对象,比如这个操作发生在原子变量 a 上,而 s = a + b;那 s 依赖于 a,但 b 不依赖于 a;当然这里也有循环依赖的问题,例如:t = s + 1,因为 s 依赖于 a,那 t 其实也是依赖于 a 的;在大多数平台上,这只会影响编译器的优化;不建议使用。
-
memory_order_acq_rel:获得释放操作,一个读‐修改‐写操作同时具有获得语义和释放语义,即它前后的任何读写操作都不允许重排,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见,当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见。
-
memory_order_seq_cst:顺序一致性语义,对于读操作相当于获得,对于写操作相当于释放,对于读‐修改‐写操作相当于获得释放,是所有原子操作的默认内存序,并且会对所有使用此模型的原子操作建立一个全局顺序,保证了多个原子变量的操作在所有线程里观察到的操作顺序相同,当然它是最慢的同步模型
3.原子变量
顾名思义,原子变量就是一种具备原子性的变量,它的操作要么全部完成,要么全部不完成,不会被中途打断,从而避免竞态条件,C/C++的标准库都提供了相关的类型。
这里选择用C11的atomic_int,它是 C++11标准中定义的原子整型变量类型,C++11也有std::atomic,它 引入的一个模板类,用于实现原子操作。std::atomic提供了一种方式来确保对共享数据的访问是线程安全的,避免了竞态条件和数据竞争。我们还可以通过不同的内存顺序模型(如 memory_order_relaxed,memory_order_acquire,memory_order_release 等)控制内存可见性和同步行为。C++11为我们隐藏了太多细节,为了学习我们不用它。
我们先来介绍相关操作:
#include <stdbool.h>
#include <stdlib.h>
#include <stdatomic.h>
int main() {
atomic_int lock;
//初始化atomic_int值
atomic_init(&lock, 0);
//加载值
int value = atomic_load(&lock);
//存储值
atomic_store(&lock, 1);
//交换值
int old_value = atomic_exchange(&lock, 1);
int expected = 0;
int desired = 1;
//比较交换值
bool success = atomic_compare_exchange_weak(&lock, &expected, desired);
//自增
old_value = atomic_fetch_add(&lock, 1);
//自减
old_value = atomic_fetch_sub(&lock, 1);
return 0;
}现在我们来写一个多线程操作同一个资源的简单demo:
#include <pthread.h>
#include <stdio.h>
int count = 0;
void* incrby(void* arg) {
int num = *(int*)arg;
for (int i=0; i < num; i++) {
++count;
}
}
int main() {
int num = 400;
pthread_t pid[5];
for(int i = 0; i < 5; ++i) {
pthread_create(&pid[i], NULL, incrby, &num);
}
for(int i = 0; i < 5; ++i) {
pthread_join(pid[i], NULL);
}
printf("count = %d\n", count);
return 0;
}编译运行看看现象:

可以看到我们第二次运行时出现了状况,与我们预期的值不一样,很显然这里出现了多个线程同时自增,导致多次自增实际值增长了1。
现在我们把全局变量换成原子变量:
#include <stdbool.h>
#include <stdlib.h>
#include <stdatomic.h>
#include <pthread.h>
#include <stdio.h>
atomic_int lock;
int count = 0;
void* incrby(void* arg) {
int num = *(int*)arg;
for (int i=0; i < num; i++) {
//++count;
atomic_fetch_add(&lock, 1);
}
}
int main() {
int num = 400;
pthread_t pid[5];
atomic_init(&lock, 0);
for(int i = 0; i < 5; ++i) {
pthread_create(&pid[i], NULL, incrby, &num);
}
for(int i = 0; i < 5; ++i) {
pthread_join(pid[i], NULL);
}
printf("count = %d\n", atomic_load(&lock));
return 0;
}
编译运行看结果:
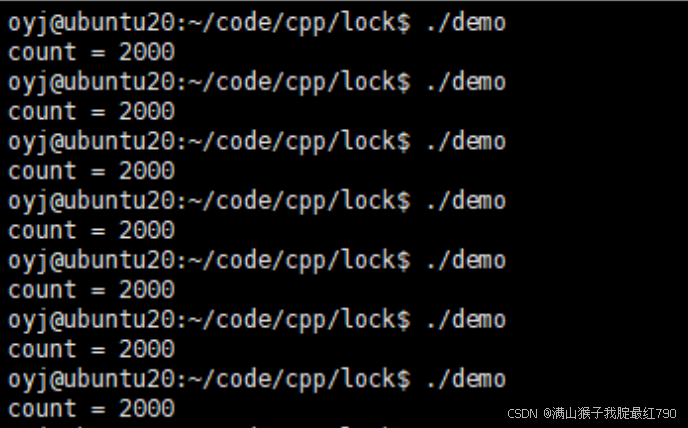
ok,可以看到运行了很多次结果都正常。
4.锁实现
基于原子变量来实现一个自旋锁,原理很简单,我们需要定义一个原子变量,把它初始化为0,当一个线程进出相关区域加锁时,将值改为1,因为原子变量的原子性,多个线程同时操作,也只会有一个成功,其他的线程继续自选查看原子变量的值,自旋等待条件成立。
下面是代码实现:
#include <stdatomic.h>
typedef struct spinlock {
atomic_int lock;
} spinlock;
static inline void spinlock_init(struct spinlock *lock) {
// 初始化为0,表示没人持有锁
atomic_init(&lock->lock, 0);
}
static inline void spinlock_lock(struct spinlock *lock) {
do {
// atomic_exchange_explicit会返回交换的旧值也就是,如果没有线程拿到锁
// 那么返回0,表示当前线程成功拿到锁,可以直接返回,如果返回1,表示当前
// 线程没拿到锁需要继续自旋, memory_order_seq_cst是默认的内存序效果最好性能最低
}while(atomic_exchange_explicit(&lock->lock, 1, memory_order_seq_cst));
}
static inline void spinlock_unlock(struct spinlock *lock) {
// 把原子变量值改为0,表示释放锁
atomic_store_explicit(&lock->lock, 0, memory_order_seq_cst);
}
static inline void spinlock_destroy(struct spinlock *lock) {
// 不需要管理资源什么都不做
(void)lock;
}ok,把我们的自旋锁加入最开始的代码测试:
#include <stdbool.h>
#include <stdlib.h>
#include <stdatomic.h>
#include <pthread.h>
#include <stdio.h>
#include <stdatomic.h>
typedef struct spinlock {
atomic_int lock;
} spinlock;
int count = 0;
static inline void spinlock_init(struct spinlock *lock) {
// 初始化为0,表示没人持有锁
atomic_init(&lock->lock, 0);
}
static inline void spinlock_lock(struct spinlock *lock) {
do {
// atomic_exchange_explicit会返回交换的旧值也就是,如果没有线程拿到锁
// 那么返回0,表示当前线程成功拿到锁,可以直接返回,如果返回1,表示当前
// 线程没拿到锁需要继续自旋, memory_order_seq_cst是默认的内存序效果最好性能最低
}while(atomic_exchange_explicit(&lock->lock, 1, memory_order_seq_cst));
}
static inline void spinlock_unlock(struct spinlock *lock) {
// 把原子变量值改为0,表示释放锁
atomic_store_explicit(&lock->lock, 0, memory_order_seq_cst);
}
static inline void spinlock_destroy(struct spinlock *lock) {
// 不需要管理资源什么都不做
(void)lock;
}
void* incrby(void* arg) {
spinlock* lock = (spinlock*)arg;
for (int i=0; i < 400; i++) {
spinlock_lock(lock);
++count;
spinlock_unlock(lock);
}
}
int main() {
pthread_t pid[5];
spinlock lock;
spinlock_init(&lock);
for(int i = 0; i < 5; ++i) {
pthread_create(&pid[i], NULL, incrby, &lock);
}
for(int i = 0; i < 5; ++i) {
pthread_join(pid[i], NULL);
}
spinlock_destroy(&lock);
printf("count = %d\n", count);
return 0;
}编译运行看结果:
ok,抛开性能不谈,确实达到了我们要的效果。
学习参考:0voice · GitHub


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









