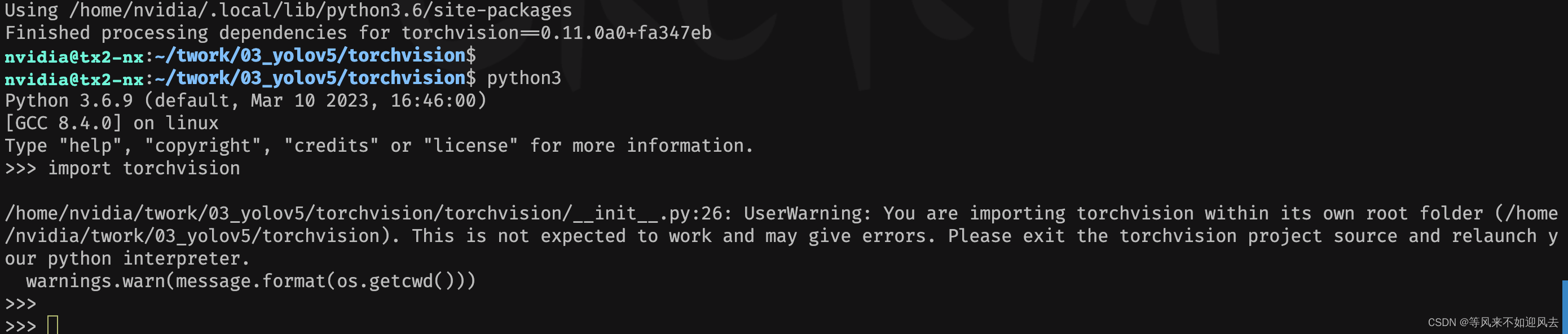
torchvision 是自己本地构建的 验证torchvision nvidia@tx2-nx:~/twork/03_yolov5/torchvision$ nvidia@tx2-nx:~/twork/03_yolov5/torchvision$ python3 Python 3.6.9 (default, Mar 10 2023, 16:46:00) [GCC 8.4.0] on linux Type








 超级会员免费看
超级会员免费看

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











