




微信公众号、知乎号(同名):李歪理,欢迎大家关注
(论文最近更新:2025.2.24)
摘要
实现语音对话系统(SDS)中的全双工通信,需要在听、说、思考之间进行实时协调。本文提出了一种语义语音活动检测(VAD)模块,作为对话管理器(DM),以高效管理全双工SDS中的轮次切换。该语义VAD模块是一个轻量级(5亿参数)的大语言模型(LLM),在全双工对话数据上进行微调,能够预测四种控制标记以调节轮次切换和保持状态,区分有意和无意的插话,同时检测查询完成,以处理用户的暂停和犹豫。通过在短时间间隔内处理输入语音,语义VAD实现了实时决策,而核心对话引擎(CDE)仅在生成回复时被激活,从而降低了计算开销。该设计允许对话管理器独立优化,无需重新训练核心对话引擎,平衡了交互准确性与推理效率,为可扩展的下一代全双工SDS奠定基础。
关键词:全双工,语音对话系统,语音活动检测,对话管理,大语言模型
1. 引言
语音对话系统(Spoken Dialogue Systems,SDS)在大语言模型(LLMs)的推动下取得了显著进展,使人机交互变得更加自然和具备上下文感知能力。然而,实现真正的全双工通信(即SDS能够同时听与说)仍然具有挑战性。许多现有的SDS仍运行在轮流交互(半双工)或“伪全双工”的模式下,这种模式由于无法理解用户的状态和意图,导致交互不够流畅。相比之下,人类对话具有无缝的轮次交替特性。除了轮次交替之外,全双工SDS还需应对多个挑战,例如干扰性说话者、用户的犹豫、以及区分有意与无意的插话,以提升自然性和交互效率。
关于如何实现SDS中的全双工通信,已有大量研究。早期的方法依赖于独立的神经网络模块来完成检测和分类任务,但这些方法在稳定性和鲁棒性方面存在局限。Shin 等人使用语音事件检测进行实时查询更新,但无法处理更广泛的交互场景。Lin 等人提出了 Duplex Conversation 系统,利用多模态模型来检测用户状态并管理轮次。近期的方法则尝试将交互控制直接嵌入LLM中,虽然提升了自动化程度,但也带来了推理开销的增加。Wang 等人提出了 NeuralFSM,通过有限状态机微调LLM,实现说话与聆听的同步。类似地,Zhang 等人提出了一种基于时分复用策略的LLM微调方法,用于全双工对话。VITA 引入了状态标记和双工机制,用于处理非唤醒和语音中断交互;Moshi 将一个基础LLM与更小型Transformer相结合,实现了实时流式预测。Mai 等人则提出了 RTTL-DG,一种无文本的语音对话模型,支持插话和笑声,以实现更自然的轮次交替。
为了在对话质量、系统稳定性与推理效率之间取得平衡,本文提出将“语义语音活动检测(semantic VAD)”用作全双工语音对话系统(SDS)的对话管理器(DM)。传统的声学VAD通过声学特征来缓解背景说话者带来的干扰,语义VAD则利用大语言模型(LLM)的能力,基于语义信息检测用户的状态和意图。我们通过在精心设计的全双工文本对话数据上对一个小型(0.5B参数量)LLM进行微调来实现语义VAD。该模型可预测四种控制标记——开始说话(start-speaking)、开始聆听(start-listening)、继续说话(continue-speaking)和继续聆听(continue-listening)——以动态引导系统交互行为。该对话管理器以短时间间隔运行,实现了实时交互管理,能够区分有意与无意的插话,并检测用户查询是否已完成,从而有效应对用户的停顿与犹豫。与以往工作相比,我们的方法在保持对话管理能力的同时,显著提升了计算效率:借助LLM的语义理解能力,实现了更精确的对话控制;而采用轻量化LLM则降低了计算成本。此外,DM与核心对话引擎(CDE)的解耦优化也保证了系统的可扩展性。
2. 全双工语音对话系统
2.1 全双工语音对话系统中的关键挑战
在语音对话系统(SDS)中实现无缝的全双工交流,需要准确识别并区分用户的行为、状态与意图。然而,由于以下问题,实时的轮替对话仍具有挑战性:
- 干扰说话者:背景语音可能导致自动语音识别(ASR)和对话管理出错,从而引发意外激活或错误回应。
- 用户的停顿与犹豫:仅凭静音无法判断用户是否完成了提问,这常常导致系统过早响应或出现不必要的延迟。
- 无意中的打断:用户的附和、回馈语(如“嗯”、“我懂了”)或是对他人说话,可能被误判为对话指令,进而打断SDS的正常响应,破坏对话连贯性。
要解决这些问题,必须整合声学与语义信息,从而实现健壮、具备语境感知能力的全双工交互。
2.2 所提出的全双工语音对话系统设计
该全双工语音对话系统(SDS)由六个关键模块组成:声学回声消除(AEC)、声学语音活动检测(VAD)、自动语音识别(ASR)、语义VAD、作为核心对话引擎的LLM(CDE)以及文本转语音(TTS),如图1(a)所示。用户语音会被依次处理,前四个模块以较短的时间间隔运行,从而确保系统的实时响应性;而核心对话引擎(CDE)仅在需要时才会被激活,以最小化计算开销。
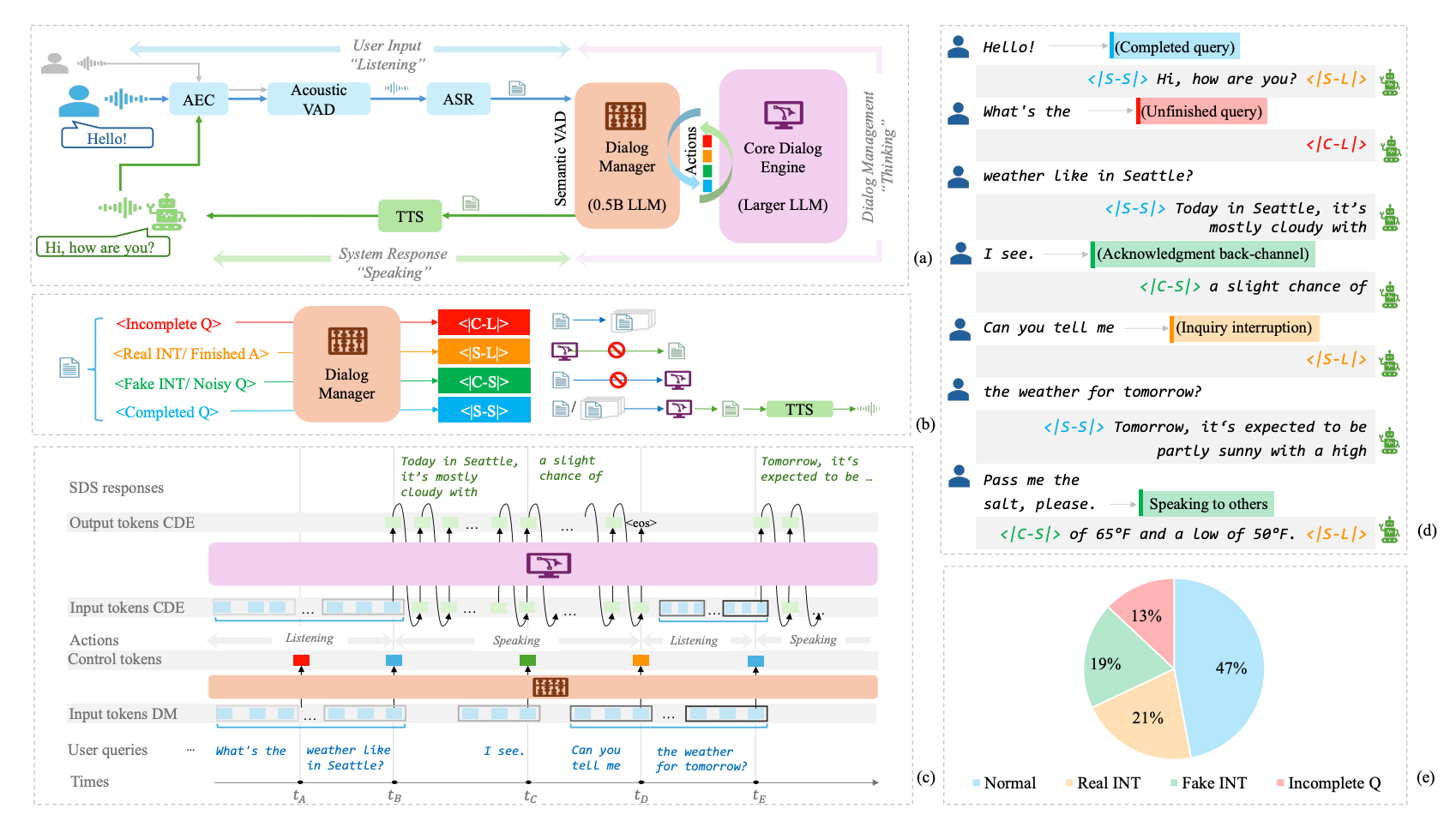
我们将声学VAD与语义VAD结合使用,以应对前述挑战,实现鲁棒且流畅的全双工交互:
- 声学VAD:我们设计的声学VAD具备说话人识别与距离感知能力,可利用距离信息和说话人嵌入(若提供)来识别目标说话者的语音活动,并减少其他说话者的干扰。
- 语义VAD:作为对话管理器(DM),语义VAD由一个微调后的 0.5B 规模 LLM 实现,能够利用 LLM 的语义理解能力和上下文感知能力,预测控制标记(control tokens),以动态管理轮换对话。它能够有效处理用户犹豫、准确区分真实和虚假的打断行为。
本研究的重点是语义VAD的引入。我们的目标不是提升问答能力,而是通过指令微调(instruction tuning)训练对话管理器,使其在多种全双工交互场景中遵循结构化规则并采取恰当行动。该方法只需少量高质量数据与轻量级的微调,具有高效实用的优势。与依赖浅层特征的神经网络型对话管理器(NN-based DMs)不同,我们的微调LLM可以通过语义理解实现更精准的交互管理。相比于将DM直接集成进大模型CDE的方法,我们的方法通过将高频决策任务交由轻量级LLM完成,同时将DM与CDE分开优化,降低了推理成本并提升了系统的可扩展性。
3. 服务于对话管理的语义VAD
3.1 交互场景与动作标记
大多数用户与语音对话系统(SDS)的交互遵循标准的问答流程,通常不会出现打断。然而,在打断发生时,我们在设计中优先考虑用户体验,仅允许用户主动打断系统。
对话管理器(DM)通过执行两个关键任务(分别对应特定的动作标记,如图1(b)所示),使SDS在“说话”和“听取”模式之间切换:
- 用户状态检测:判断用户是否已经说完话。
- 问题未完成:DM预测 <|Continue-Listening|>(<|C-L|>),系统继续聆听,并缓存历史语句,直到识别到完整的查询。
- 问题完成:DM提示SDS进入 <|Start-Speaking|>(<|S-S|>)状态。系统回应完毕后,再切换为 <|Start-Listening|>(<|S-L|>)状态,等待进一步输入。
- 用户意图分析:判断用户的打断是否需要回应。
- 有意打断(真实INT):如果用户有意引导对话方向,SDS应立即停止说话,并切换为 <|Start-Listening|>(<|S-L|>)状态。示例包括否认、表示不满、进一步提问或改变话题等。
- 无意打断(伪INT):若打断不具有破坏性,SDS应继续保持 <|Continue-Speaking|>(<|C-S|>)状态。示例包括肯定回应、附和语(如“嗯哼”、“对的”)、对他人讲话或无关评论等。
3.2 对话管理
如图 1© 所示,对话管理器(DM)处理两个主要输入:(1) 来自语音识别(ASR)的用户查询 token,(2) 来自核心对话引擎(CDE)的历史响应 token。为简明起见,图中未明确显示历史响应 token 作为 DM 输入的一部分,但实际上它们也被纳入分析。
DM 通过分析这些输入来判断下一步动作,从而调控整个交互流程。DM 是系统中的主要决策模块,持续管理“聆听”和“说话”状态;而 CDE 仅在需要生成高质量回复时被调用。当 DM 预测出 <|Start-Speaking|>(<|S-S|>)标记时,CDE 才会被激活,使用过去的用户查询和系统回复执行标准的大语言模型(LLM)推理任务。通过让 DM 承担高频实时决策,仅在必要时才调用 CDE,本系统实现了计算效率与对话质量的优化,确保了全双工语音对话系统的可扩展性与实用性。
3.3 全双工对话数据
本节重点介绍语义 VAD 的核心内容,详细说明了数据生成过程及量身定制提示词的设计方法。
为了训练对话管理器(DM),我们需要带有四种控制标记的全双工对话标注数据(如图 1(d) 所示)。由于目前没有公开数据集满足这些要求,我们使用了大语言模型 API 元宝(Yuanbao)来生成多样化、自然的全双工对话。
为了生成用于创建全双工对话数据的提示词(prompts),我们设计了一种算法,如算法 1 所示。这些提示词的目的是指导大语言模型生成带有控制标记的全双工对话数据。

每个提示词包含以下几个要素:
- 目标:生成一个用户可以打断助手的对话文本。
- 助手行为说明:明确控制标记(control tokens)的含义及其对应的动作。
- 输出格式:对话格式如下:{第 X 轮(对话类型);用户:<用户的问题或插话>;系统:<助手的回答,带控制标记>}。
- 自定义指令:指定问答轮数、主题和说话风格。例如:“请生成 5 轮对话。用户以旅游相关话题发起对话,语气轻松随和。助手保持友好语调,并参考之前的对话内容。”
主题池包含 200 个常见对话主题(如天气、旅行、餐厅等),说话风格池则包括 10 种用户角色(personas)。系统会随机选择主题和风格,并调整概率以增强真实感。
3.4 数据准备与模型训练
数据准备分为四个阶段:数据生成、清洗、后处理和增强。我们使用 Yuanbao 生成了 2 万条全双工对话,但由于指令跟随能力有限,发现并非所有生成数据都能完全符合预期结构。为此,我们进行了严格的数据清洗,过滤格式错误和控制标记使用不当的样本,保留率约为 60%。
鉴于上述问题,我们还采用了一种替代策略:先生成标准的问答式对话(LLM 更擅长处理),再通过可控的后处理方式引入各种互动模式。最终训练数据集结合了这两种策略生成的对话内容。
为了更贴近真实 ASR 输出,我们进一步通过修改用户提问结尾的标点符号来增强数据。最终数据集中包含 11,990 条对话,共 80,338 个对话轮次,覆盖了多样化的互动场景(见图 1(e))。我们还分析了某些极端情况,例如真实或虚假打断或不完整提问比例超过 50% 的样本,发现这些样本会导致模型过拟合和性能下降,进一步验证了平衡训练数据的重要性。为防止基础 LLM 能力下降,我们在训练集中同时保留了与全双工样本配对的未被打断的普通对话。
在模型微调方面,我们使用了混元(Hunyuan)小模型版本(0.5B-dense-8k),在精心整理的数据集上进行训练。此次研究初步聚焦于中文对话,训练数据也全部为中文的全双工对话。训练采用标准的 LLM 微调方法,在词表中加入四个控制标记,训练总步数为 1500,批大小为 128,初始学习率为 0.001,并线性衰减至 0.0001 以实现稳定优化。
4. 实验结果
4.1 测试集
由于目前尚无用于全双工评估的基准数据集,我们为每种交互场景生成了 1,000 条测试样本。按照第 3.3 节的方法,我们重新构建了话题池和说话风格池,并生成了 2,000 条多轮对话。从中为每种场景随机选取 1,000 条样本,用于评估语义 VAD 在控制标记预测方面的表现。
4.2 评估结果
表 1 中的评估结果验证了所提出的语义 VAD 在各类场景下预测控制标记的有效性。值得注意的是,对于用户打断行为的检测(即判断系统应继续说话还是切换为开始聆听)表现尤为出色,这得益于同时说话过程中提供的上下文线索,使得该任务更具稳定性。相比之下,用户状态检测(即区分用户查询是否已完成)表现略逊一筹,因为该任务完全依赖语义完整性判断,而语义完整性会受到说话风格和语言细微差异的影响,从而引入模糊性,使得该任务本身更具挑战性。
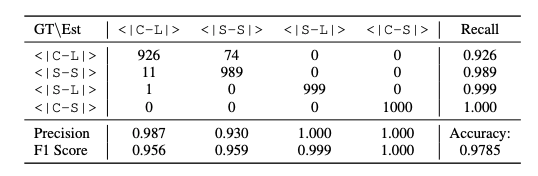
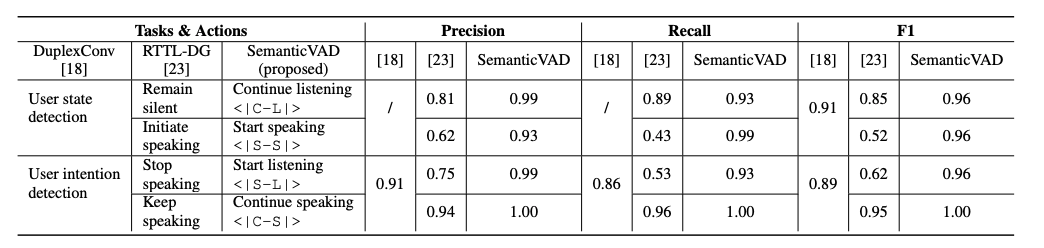
表 2 展示了我们的方法与近期提出的两种全双工 SDS 方法的对比结果。由于我们无法获取它们的模型checkpoint或测试数据集,因此仅引用其研究中直接报告的结果作为参考。上述两项研究均将用户状态检测和打断识别任务建模为基于声学和语言模式的分类问题,其语义理解能力较为有限。而我们的语义 VAD 依托大语言模型(LLM)驱动的语义理解能力,实现了更具上下文意识、更可靠的全双工交互,在性能上也取得了相对更优的表现。
4.3 真实录音评估
我们进一步使用用户与半双工语音对话系统(SDS)交互的内部录音对系统进行了测试,重点评估用户状态检测(如开始说话 <|Start-Speaking|> 和继续聆听 <|Continue-Listening|>)。我们指示用户在交互中自然地插入犹豫,以模拟不完整查询的真实场景。录音数据通过 VAD 技术和人工标注两种方式进行评估标注。结果如表 3 所示。
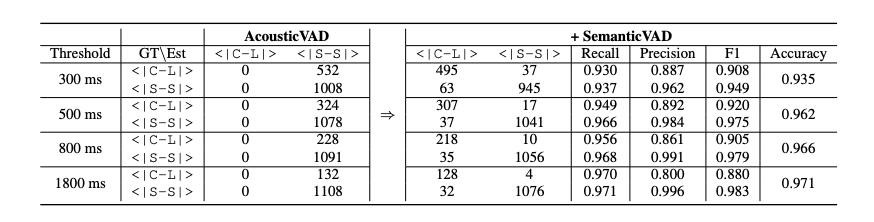
由于声学 VAD 仅依赖声学信息,并通过比较静音时长是否超过固定阈值(例如 300 毫秒)来判断查询是否结束,因此它只能预测 <|Start-Speaking|>,即假设用户已经说完。而语义 VAD 的引入显著提升了准确率,在所有测试场景中均达到 93.5% 以上。进一步的错误分析表明,一些错误预测实际上是由 ASR(自动语音识别)错误引起的,而非 VAD 模型本身的局限性。
5. 结论
本文提出了一种基于语义 VAD 的对话管理器(DM)用于全双工语音对话系统(SDS),通过微调后的 0.5B LLM 来利用控制标记实现轮次控制。该方法能够有效区分有意和无意的打断,检测用户查询是否完成,并通过有选择地调用核心对话引擎(CDE)来降低计算开销。实验结果表明,该方法在提升对话流畅性和意图识别方面具有明显优势。未来的工作将聚焦于减少系统延迟、增强鲁棒性,并进一步拓展以支持大型多模态模型。



















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











