





 超级会员免费看
超级会员免费看

0. 背景
当前的对齐方法(例如 RLHF(基于人类反馈的强化学习)和 DPO(直接偏好优化))依赖昂贵的偏好数据并且对数据不平衡和噪声较为敏感,而人类的决策过程往往受到损失厌恶和风险规避等认知偏差的影响。基于此,作者提出了 KTO(卡尼曼-特沃斯基优化),希望通过一种更符合人类心理的方式,简化对齐过程,并在极度不平衡的数据和噪声情况下仍能有效优化模型,推动大规模对齐任务的实践应用。
1. 前景理论中的效用函数
在前景理论中,人类的效用函数由两个部分组成:价值函数(value function)和加权函数(weighting function)。论文关注的主要是价值函数,它描述了相对某一参考点的结果对人类的主观价值的影响。
公式如下:
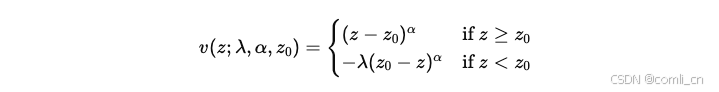
其中:
- zzz

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











