




 超级会员免费看
超级会员免费看
什么是知识蒸馏?
根据维基百科的定义,知识蒸馏(knowledge distillation) 是人工智能领域的一项模型训练技术。该技术透过类似于教师—学生的方式,令规模较小、结构较为简单的人工智能模型从已经经过充足训练的大型、复杂模型身上学习其掌握的知识。该技术可以让小型简单模型快速有效学习到大型复杂模型透过漫长训练才能得到的结果,从而改善模型的效率、减少运算开销,因此亦被称为模型蒸馏(model distillation)。
知识蒸馏并不是什么新技术,早在 2006 年, Bucilua 等人最先提出将大模型的知识迁移到小模型的想法。2015 年,Hinton 正式提出广为人知的知识蒸馏的概念。其主要的想法是:学生模型通过模仿教师模型来获得和教师模型相当的精度,关键问题是如何将教师模型的知识迁移到学生模型。
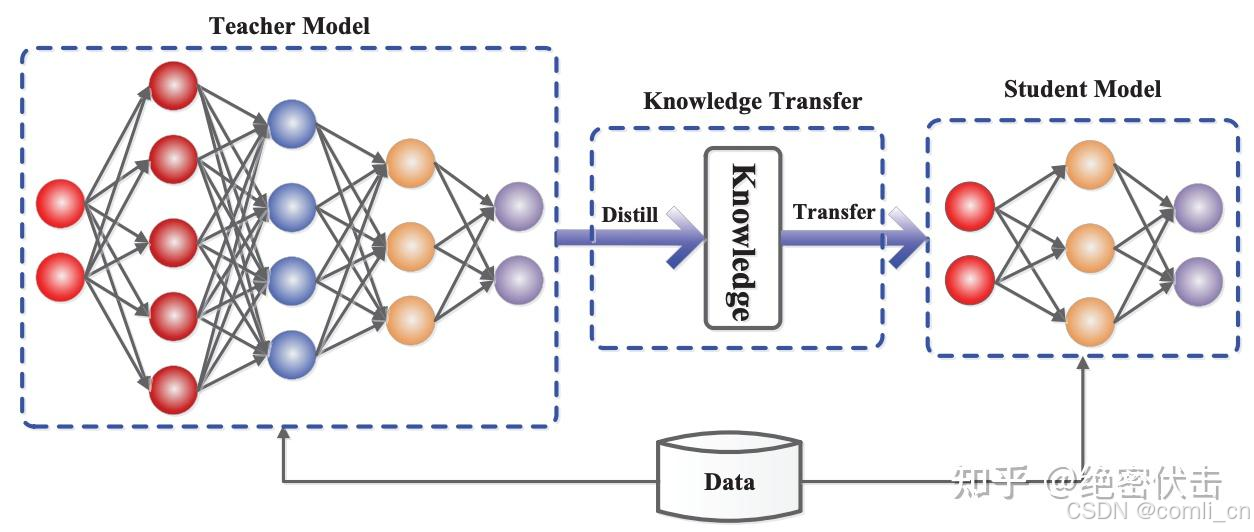
目前最常用的蒸馏方法有三种:数据蒸馏、Logits蒸馏、特征蒸馏。下面分别介绍下这三种蒸馏方法。
数据蒸馏
在数据蒸馏过程中,教师模型首先生成<问题, 答案> pair,这些 pair 随后被用来训练学生模型。例如,DeepSeekR1-Distill-Qwen-32B 模型就是通过使用 DeepSeek-r1 生成的80万条数据,在 Qwen2.5-32B 基

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











