




 本文介绍了微软亚洲研究院提出的FastCorrect,一种基于编辑对齐的非自回归语音识别纠错模型,显著提升了实时语音识别的准确性和速度,尤其在减少延迟方面表现出色。模型针对语音识别任务的特性,有效解决稀疏错误挑战,通过预训练和伪配对数据增强,实现高效纠错。
本文介绍了微软亚洲研究院提出的FastCorrect,一种基于编辑对齐的非自回归语音识别纠错模型,显著提升了实时语音识别的准确性和速度,尤其在减少延迟方面表现出色。模型针对语音识别任务的特性,有效解决稀疏错误挑战,通过预训练和伪配对数据增强,实现高效纠错。
1. 引述
纠错是语音识别中的一个重要后处理方法,旨在检测并纠正语音识别结果中存在的错误,从而进一步提升语音识别的准确率。许多纠错模型采用的是延迟较高的自回归解码模型,但是语音识别服务对模型的延迟有着严格的要求,在一些实时语音识别场景中(如会议同步语音识别),纠错模型无法上线应用。为了加速语音识别中的纠错模型,微软亚洲研究院的研究员们提出了一种基于编辑对齐(Edit Alignment)的非自回归纠错模型——FastCorrect,FastCorrect 在几乎不损失纠错能力的情况下,将自回归模型加速了6-9倍。
2. 存在的问题
语音识别的纠错实际上是一个文本到文本的任务,模型训练的输入为语音识别结果文本,输出为真实文本。在自然语言处理领域(如机器翻译和文本编辑),已经有一些非自回归的快速模型被提出。但初步实验结果(如下图)显示,简单地将这些模型应用到语音识别的纠错任务中,并不能取得令人满意的结果。经过对语音识别的分析,研究员们发现语音识别中的错误比较稀疏,通常错误的单词数不到总单词数的10%,而模型必须精准地找到并修改这些错误,同时还要避免修改正确的单词,这是语音识别的纠错任务中最大的挑战。而机器翻译中非自回归模型的主要问题是修改了太多原本是正确的单词,模型修改了原有错误的同时又引入了较多新的错误,因此无法提升语音识别的精度
3. 编辑对齐( Edit Alignment)
考虑到语音识别的纠错输入输出的对应关系是单调的,所以如果可以在词的级别对齐输入和输出,就可以得到细粒度的错误信息:哪些词是错误的,这些错误的单词应该怎样修改。基于两个文本序列的编辑距离,研究员们设计了编辑对齐(Edit Alignment)算法(如下图)。给定输入(语音识别结果)和输出(真实文本),第一步是计算两个文本的编辑距离,然后可以得到数条编辑路径(Edit Path),路径中的元素为增加/删除/替换/不变四种操作之一。为了避免修改正确单词,包含“不变”操作最多的编辑路径会被选择。最终,基于编辑路径可以得到:对于每个输入的单词,哪些输出的单词与之对应。如果对应的输入输出单词不同,那么就表明输入单词是错误单词。

如上图所示,我们的源句子为“BBDEF”,目标句子为“ABCDF”,而我们在进行变换操作的时候是按照token粒度进行变换的,在这个例子中就是按照字母粒度进行变换的。
我们一共有三种变换的方式:token插入,token删除,token替换。从句子S=(s1,s2,⋅⋅⋅,sM)S = (s_1, s_2, ···,s_M)S=(s1,s2,⋅⋅⋅,sM)到句子T=(t1,t2,⋅⋅⋅,tN)T = (t_1, t_2, ···, t_N)T=(t1,t2,⋅⋅⋅,tN)之间需要进行多少次变换两个句子之间的编辑距离就是多少。
上图的左子图画出了两个句子之间的距离,距离是用递归的方式计算的。比如图中D行B列的2表示从源句子“BBD”到目标句子“AB”之间的编辑距离为2,变换过程可以是先去掉“D”再把左边的“B”换成“A”。
(1)计算编辑距离
计算编辑距离的公式为:
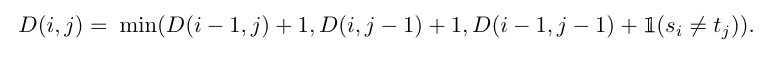
D(i,j)D(i, j)D(i,j)表示子句(s1,s2,⋅⋅⋅,sj)(s_1, s_2, ···, s_j)(s1,s2,⋅⋅⋅,sj)和子句(t1,t2,⋅⋅⋅,tj)(t_1, t_2, ···, t_j)(t1,t2,⋅⋅⋅,tj)之间的编辑距离。min(·)中的最后一项表示如果si=sjs_i=s_jsi=sj的话这一项为0,否则为1 。这个式子的边界条件为D(i,0)=iD(i, 0) = iD(i,0)=i,D(0,j)=jD(0, j) = jD(0,j)=j。
按照这个计算方法得到源句子“BBDEF”和目标句子“ABCDF”的编辑距离为3 ,并且有三条变换路径的编辑距离都是3。
(2)选择编辑对齐路径
在生成编辑距离矩阵之后就要从终点往起点寻找最优的路径,比如到终点的最小编辑距离为3,但只有从source为“BBDE”和target为“ABCD”到终点才是最优的,而到source为“BBDE”和target为“ABCD”有两条路径都是最优的,所以得把这两条路径都记下来,以此类推可以得到所有的最优路径。
现在我们有三条路径,接下来我门要根据两个条件来选取路径:
- 从源句子到目标句子之间没有变换的token数,没有变换的token数越多这条路径的match score越高。如上图中中间子图所述,path a的“B”,“D”, “F”都没变,所以match score为3,path b也是3, path c为2,所以把path c放弃。
- 通过统计语料库得到一个n-gram的频率词典,然后将源句子和目标句子按照下述对齐方式得到一个对齐集合E,对集合中每个元素查一下对应的频率,然后相加得到每条路径的Align Freq Score。选择分数最高的路径。
对齐方式:
- 对于删除,源token与空目标token Ø对齐。
- 对于替换或不变的,我们分别将源句子与目标句子中的替换标记或未更改标记对齐。
- 对于插入,目标token没有要对齐的源token(例如,path b中的token “C”),然后目标token将与其对应的左或右源token对齐,从而产生不同的编辑对齐(例如,path b可以通过将目标token“C”分别对齐源token “B”(左)或“D”(右),生成两种对齐方式:b1和b2)
4. FastCorrect模型
基于细粒度的输入输出对应关系,研究员们针对性地设计了快速纠错模型 FastCorrect。模型包含了三个主要部分——编码器、长度预测器和解码器(如下图):
- 编码器可以学习输入文本的特征,这些特征会被长度预测器和解码器利用。
- 长度预测器基于编码器的输出,预测每个输入单词有多少个输出单词与之对应,即 Duration。如果输入单词 Duration 为0,那么没有输出单词与之对应,它也将被删除,如果 Duration 大于1,那么有多个输出单词与之对应,意味着解码器需要插入数个单词。
- 解码器除了利用编码器的输出之外,还会基于长度预测器的结果,调整输入文本的长度,使之和输出文本长度一致。将长度调整一致后,解码器可以并行地同时解码出所有单词。从下图中也可以看到,Decoder的输入部分直接是经过调整之后的输入,而不像自回归模型的decoder部分是将前几步的输出作为输入来生成下一步的输出。
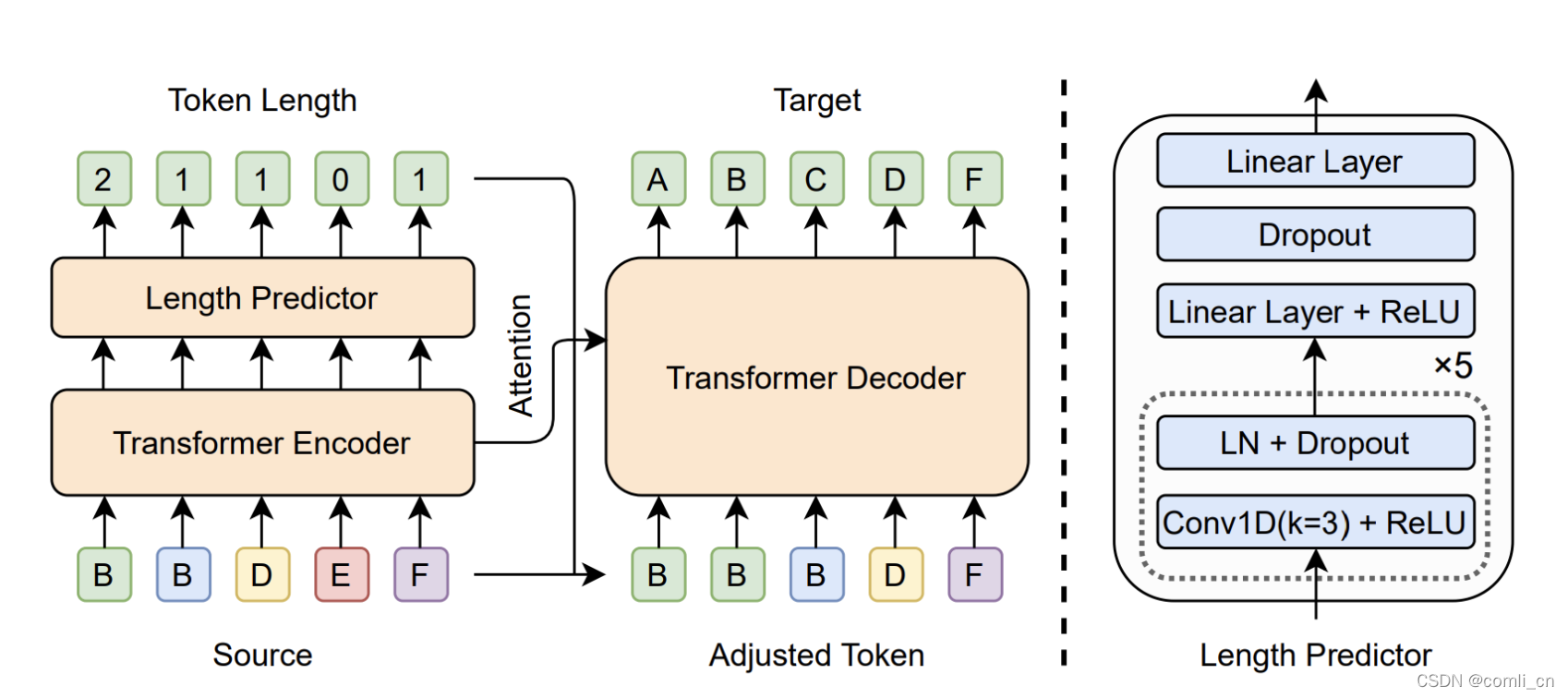
小注:这里长度预测模型使用的损失函数是MSE
6. 预训练
因为ASR模型的准确率比较高,所以输出正确的占比比较大,导致纠错模型的有效训练case是有限的。为了克服这个问题,我们构造大规模伪配对数据来预训练FastCorrect模型,然后对原始有限配对数据进行微调。我们对文本数据进行抓取,通过随机删除、插入和替换文本数据中的单词来构造一个伪校正数据集。
为了尽可能地模拟ASR错误,以利于模型训练,我们考虑了两个因素:
- 替换时,用同音词典中发音相似的另一个单词替换该单词,因为ASR中的替换错误通常来自同音词。
- 修改单词的概率设置为ASR模型的单词错误率。删除、插入和替换的概率分布设置为ASR模型的误差分布
7. 效果
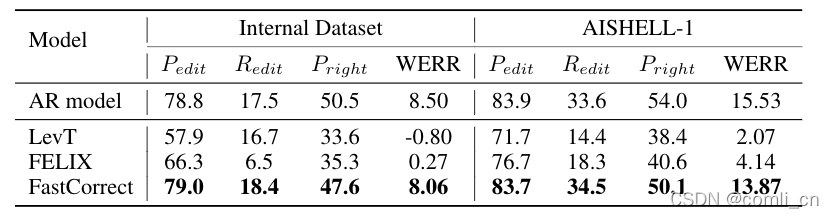
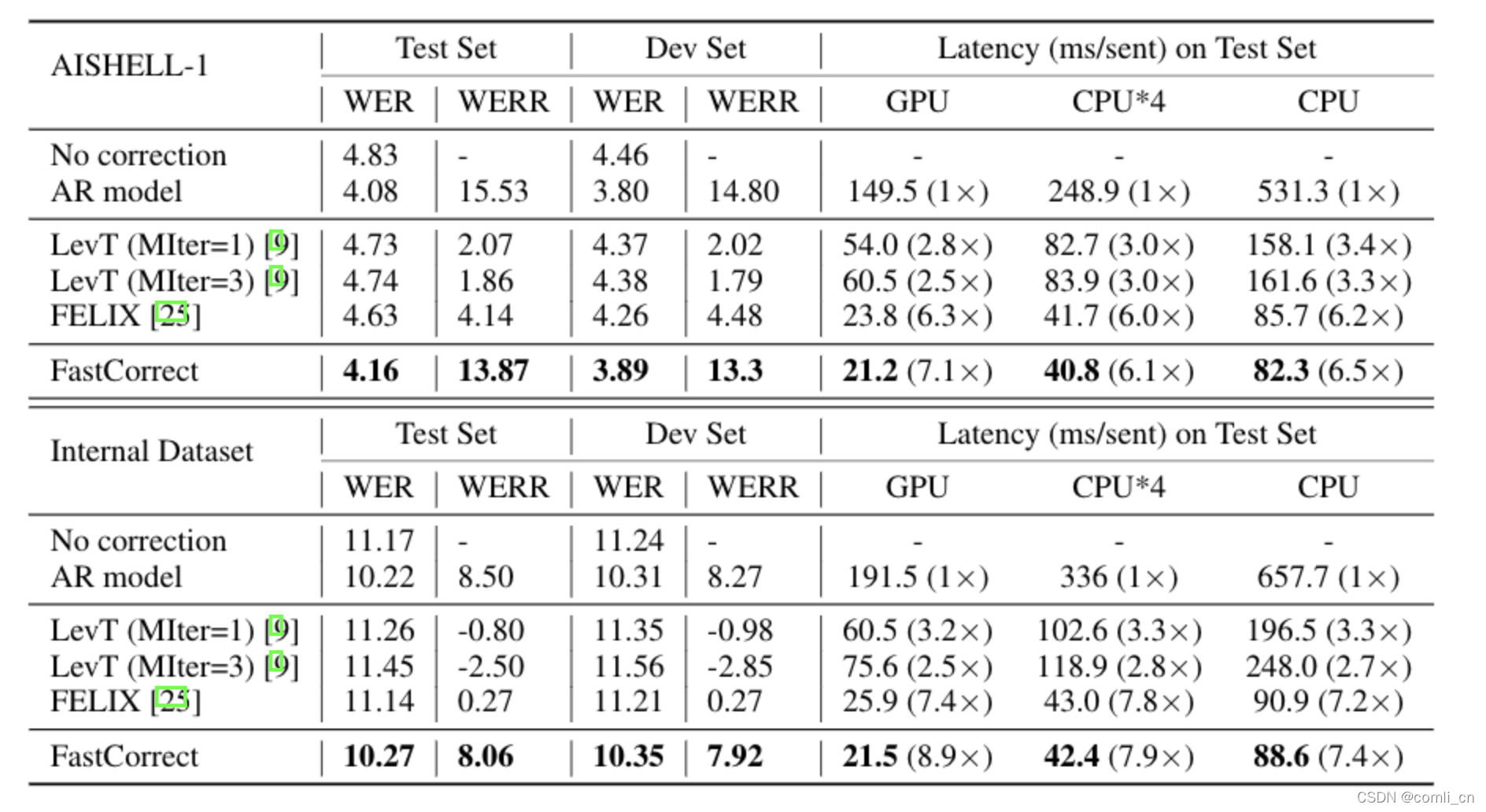
效果主要从准确率(accuracy)和延迟(Latency)两个两个指标来看,用于比较的baseline system包括两个非自回归模型(NAR model)和一个基于transformer的自回归模型(AR model),可以看到FastCorret的错误率比两个NAR model要低,只比AR model稍高,且延迟是最小的。
实验表明(如下图),在开源学术数据集 AISHELL-1 和微软内部的产品数据集上,FastCorrect 都取得了跟自回归模型几乎相同的纠错能力。模型的衡量准则为纠错后的词错误率(Word Error Rate,WER)和相对错误率下降(WER Reduction)。相比于自回归的模型,FastCorrect 的解码速度可以提升7-8倍。相比于其它非自回归的基线模型,FastCorrect 取得了更好的纠错精度。从实验结果可以看出,FastCorrect 很好地解决了语音识别模型中纠错模型的高延迟问题。
WER(词错误率,Word Error Rate)
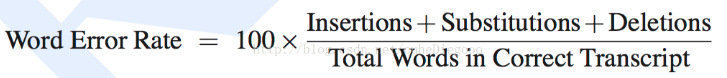
SER(句错误率,Sentence Error Rate)

WERR (相对容错率下降, WER Reduction)
注:这篇博文大部分的描述是直接引用微软公众号的,只是对一些没展开的点做了自己的解读,链接如下:https://mp.weixin.qq.com/s/5NqPMmpQjCOoyYHcz4luwA
论文链接:
https://arxiv.org/abs/2105.03842
开源代码:
https://github.com/microsoft/NeuralSpeech
https://github.com/microsoft/NeuralSpeech/tree/master/FastCorrect


















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











