



进入各节点的命令:
docker exec -it master /bin/bash
docker exec -it slave1 /bin/bash
docker exec -it slave2 /bin/bash
子任务一:Hadoop 完全分布式安装配置
1.解压安装包
从宿主机/opt目录下将文件hadoop-3.1.3.tar.gz、jdk-8u212-linux-x64.tar.gz复制到容器Master中的/opt/software路径中(若路径不存在,则需新建),将Master节点JDK安装包解压到/opt/module路径中(若路径不存在,则需新建),将JDK解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:将宿主机的文件复制到容器master中:
docker cp /opt/hadoop-3.1.3.tar.gz master:/opt/software
docker cp /opt/jdk-8u212-linux-x64.tar.gz master:/opt/software
第二步:解压JDK压缩包并改名:
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module
mv /opt/module/jdk1.8.0_241 /opt/module/java
2.配置JDK
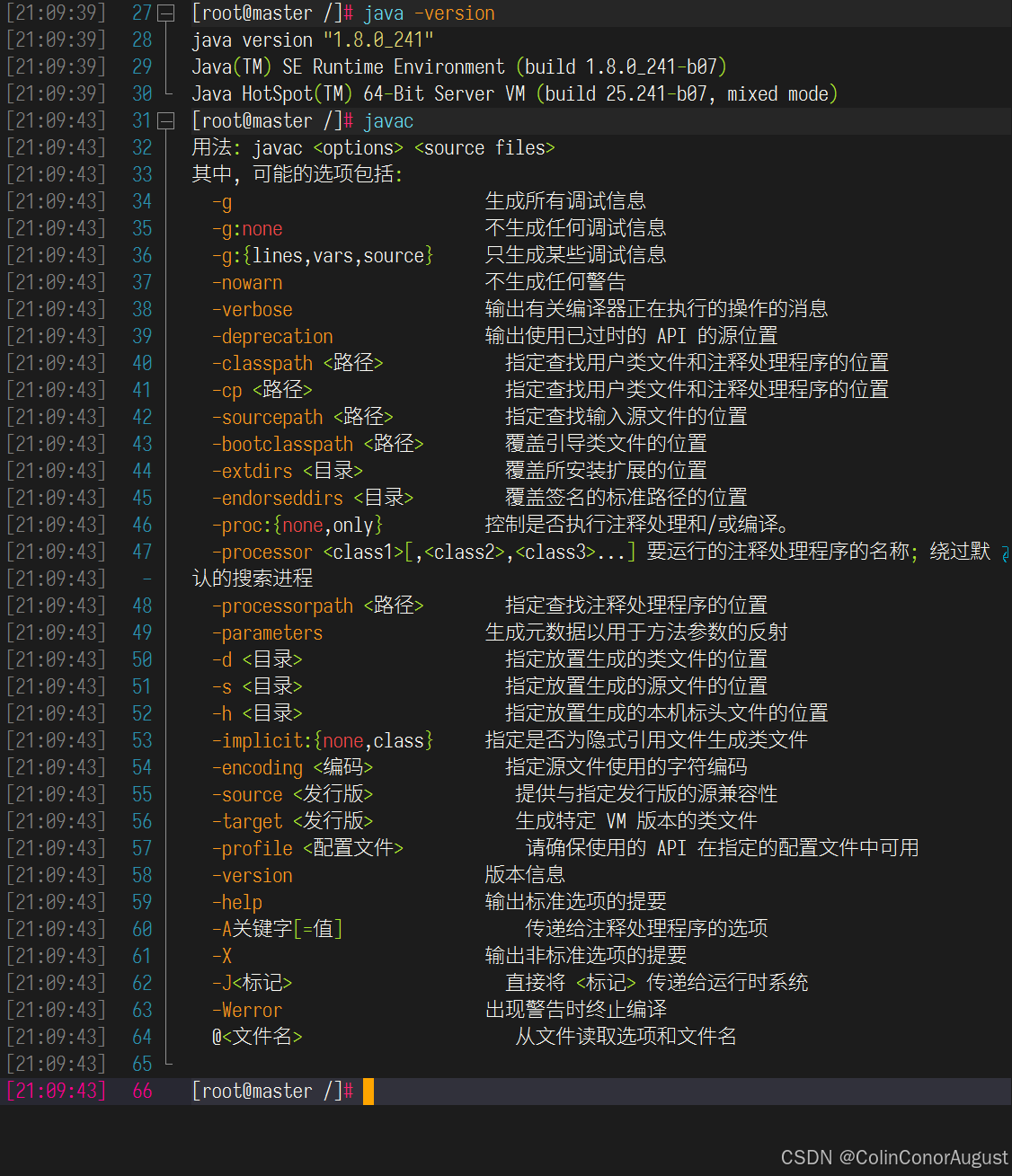
修改容器中/etc/profile文件,设置JDK环境变量并使其生效,配置完毕后在Master节点分别执行“java -version”和“javac”命令,将命令行执行结果分别截图并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:设置环境变量:
#修改/etc/profile文件,并将以下内容添加至文件末尾
export JAVA_HOME=/opt/module/java
export PATH=$PATH:$JAVA_HOME/bin
#初始化profile
source /etc/profile
第二布:验证环境变量设置:
3.配置hosts、免密登录、分发JDK
请完成host相关配置,将三个节点分别命名为master、slave1、slave2,并做免密登录,用scp命令并使用绝对路径从Master复制JDK解压后的安装文件到slave1、slave2节点(若路径不存在,则需新建),并配置slave1、slave2相关环境变量,将全部scp复制JDK的命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:配置hosts:
#修改/etc/hosts文件,并将以下内容添加至文件末尾
172.18.0.101 master
172.18.0.102 slave1
172.18.0.103 slave2
第二步:设置免密登录(三台机器都要执行):
#在主节点master中执行下条命令生成密钥
ssh-keygen -t rsa
#将主机生成的公钥文件复制到集群中的所有虚拟机上(包括自身)
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
第三步:分发JDK与环境变量配置文件
#分发hadoop与profile文件
scp -r /opt/module/java root@slave1:/opt/module
scp -r /opt/module/java root@slave1:/opt/module
scp /etc/profile root@slave1:/etc
scp /etc/profile root@slave1:/etc
#在所有容器集群中初始化profile
source /etc/profile
4.配置并分发Hadoop集群
在Master将Hadoop解压到/opt/module(若路径不存在,则需新建)目录下,并将解压包分发至slave1、slave2中,其中master、slave1、slave2节点均作为datanode,配置好相关环境,初始化Hadoop环境namenode,将初始化命令及初始化结果截图(截取初始化结果日志最后20行即可)粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:解压并配置Hadoop:
tar -zxvf /opt/software/hadoop-3.3.0.tar.gz -C /opt/module
mv /opt/module/hadoop-3.3.0 /opt.module/hadoop
#修改/etc/profile文件,并将以下内容添加至文件末尾
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
#修改hadoop-3.3.0/etc/hadoop/core-site.xml
export JAVA_HOME=/opt/module/java
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#修改hadoop-3.3.0/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
</configuration>
#修改hadoop-3.3.0/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9868</value>
</property>
</configuration>
#修改hadoop-3.3.0/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
#修改hadoop-3.3.0/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,
HADOOP_YARN_HOME,HADOOP_MAPRED_HOME,HADOOP_CONF_DIR,
CLASSPATH_PREPEND_DISTCACHE</value>
</property>
</configuration>
第二步:修改workers,将master、slave1、slave2节点均作为datanode:
#修改hadoop-3.3.0/etc/hadoop/workers
master
slave1
slave2
第三步:分发hadoop,并初始化namenode
#分发hadoop与profile文件
scp -r /opt/module/hadoop-3.3.0 root@slave1:/opt/module
scp -r /opt/module/hadoop-3.3.0 root@slave1:/opt/module
scp /etc/profile root@slave1:/etc
scp /etc/profile root@slave1:/etc
#在集群中所有虚拟机中初始化profile
source /etc/profile
#在主节点master上执行下条命令,初始化namenode:
hdfs namenode -format

5.启动Hadoop集群
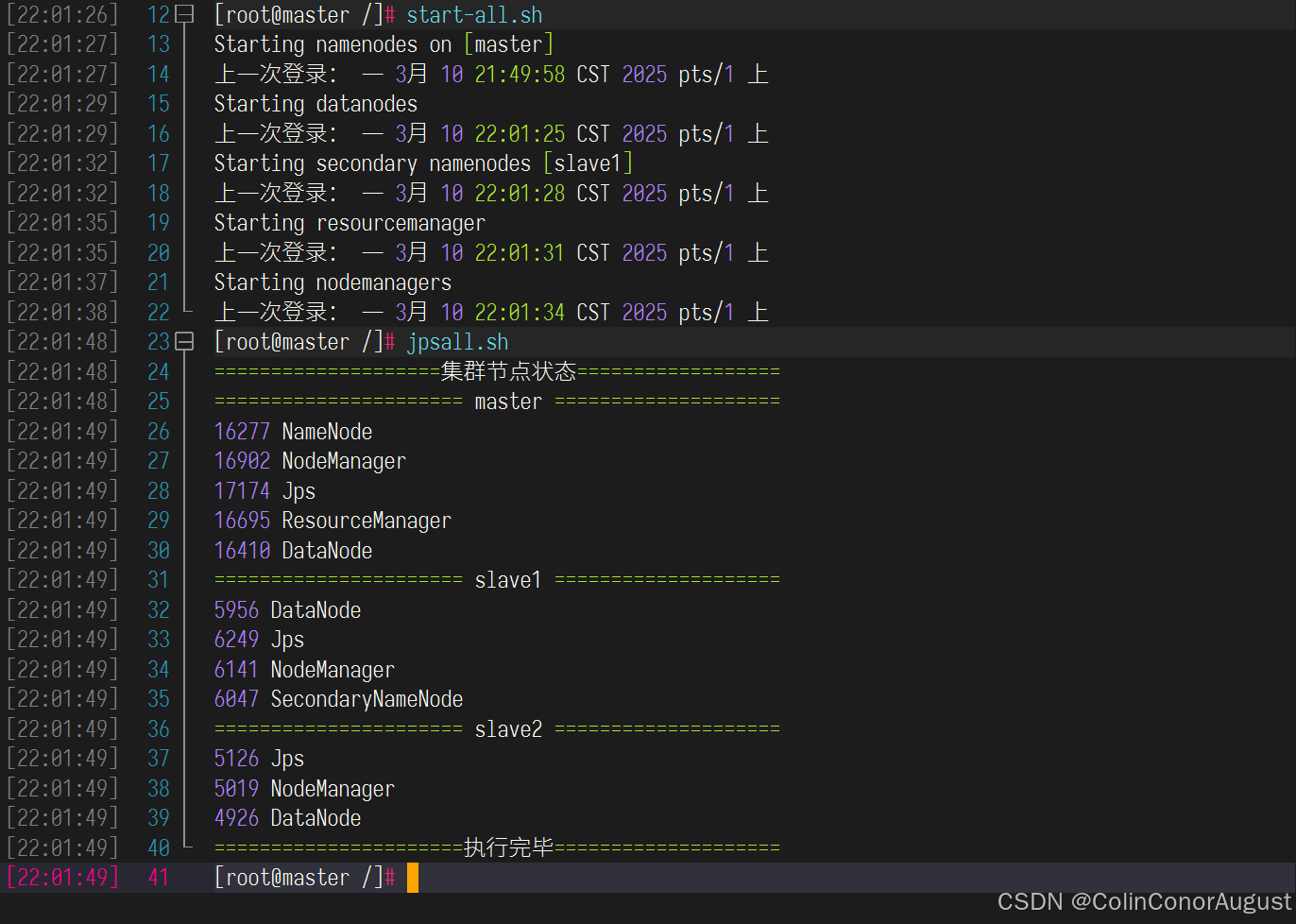
启动Hadoop集群(包括hdfs和yarn),使用jps命令查看Master节点与slave1节点的Java进程,将jps命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
启动hadoop集群,并查看进程:
子任务二:Spark on Yarn安装配置
1.解压安装包
从宿主机/opt目录下将文件spark-3.1.1-bin-hadoop3.2.tgz复制到容器Master中的/opt/software(若路径不存在,则需新建)中,将Spark包解压到/opt/module路径中(若路径不存在,则需新建),将完整解压命令复制粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
#复制并解压spark
docker cp spark-3.1.1-bin-hadoop3.2.tgz master:/opt/software
tar -zxvf /opt/software/spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module
mv /opt/module/spark-3.1.1-bin-hadoop3.2 /opt/module/spark
1.配置并检查Spark
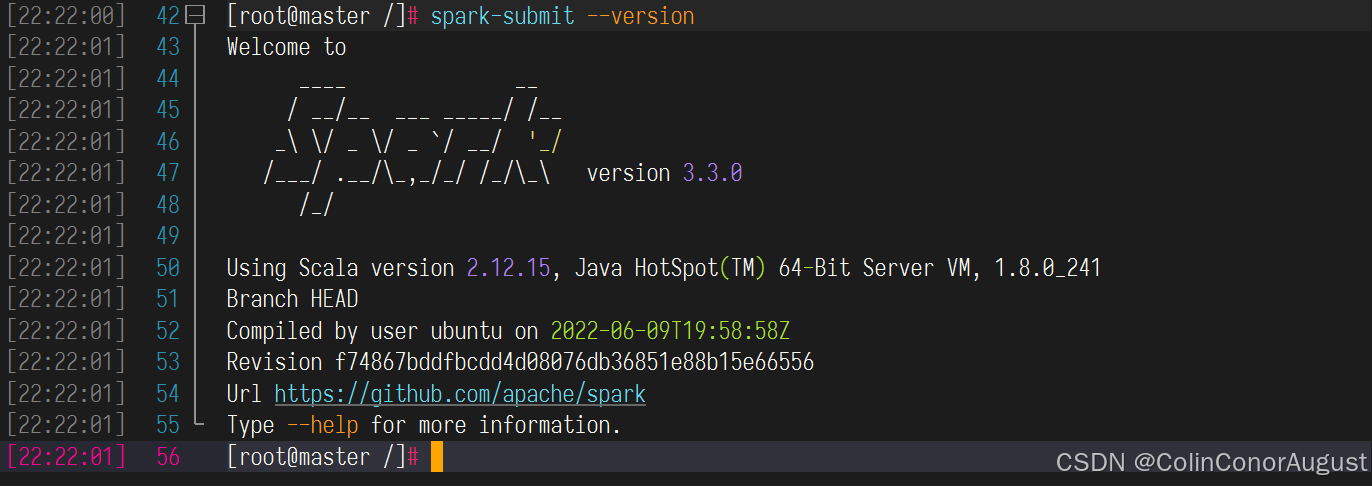
修改容器中/etc/profile文件,设置Spark环境变量并使环境变量生效,在/opt目录下运行命令spark-submit --version,将命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:环境变量设置:
#修改/etc/profile文件,并将以下内容添加至文件末尾
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
#初始化profile
source /etc/profile
第二步:检查Spark:
spark-submit --version
2.执行并提交示例程序
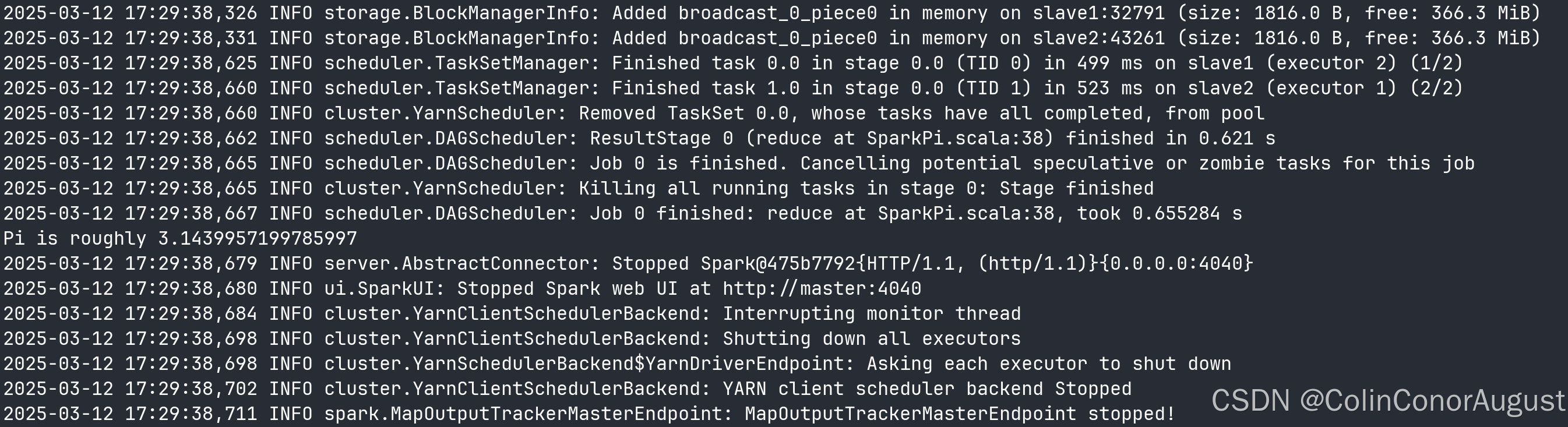
完成on yarn相关配置,使用spark on yarn 的模式提交$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar 运行的主类为org.apache.spark.examples.SparkPi,将运行结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下(截取Pi结果的前后各5行)。
运行命令为:
spark-submit --master yarn --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar
第一步:修改spark配置文件
#修改spark-3.3.0-bin-hadoop3/conf/spark-env.sh
JAVA_HOME=/opt/module/java
HADOOP_CONF_DIR=$HADOOP_HOME/hadoop-3.3.0/etc/hadoop
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
第二步:执行并提交任务:
执行题目所给定的示例程序:
子任务二:HBase分布式安装配置
1.复制、解压、重命名
从宿主机/opt目录下将文件apache-zookeeper-3.5.7-bin.tar.gz、hbase-2.2.3-bin.tar.gz复制到容器Master中的/opt/software路径中(若路径不存在,则需新建),将ZooKeeper、HBase安装包解压到/opt/moduleu目录下,将HBase的解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
复制、解压、重命名
docker cp /opt/apache-zookeeper-3.5.7-bin.tar.gz master:/opt/software
docker cp /opt/hbase-2.2.3-bin.tar.gz master:/opt/software
tar -zxvf /opt/software/apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
tar -zxvf /opt/software/hbase-2.2.3-bin.tar.gz -C /opt/module/
mv /opt/module/apache-zookeeper-3.5.7-bin/ /opt/module/zookeeper
mv /opt/module/hbase-2.2.3/ /opt/module/hbase
2.环境配置
完成ZooKeeper相关部署,用scp命令并使用绝对路径从容器master复制HBase解压后的包分发至slave1、slave2中,并修改相关配置,配置好环境变量,在容器Master节点中运行命令hbase version,将全部复制命令复制并将hbase version命令的结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
修改zookeeper配置文件:
cp /opt/module/zookeeper/conf/zoo_sample.cfg /opt/module/zookeeper/conf/zoo.cfg
vim /opt/module/zookeeper/conf/zoo.cfg
# 设置数据持久化目录与日志文件目录
dataDir=/opt/module/zookeeper/data
dataLogDir=/opt/module/zookeeper/logs
# 设置zookeeper服务端口号
clientPort=2181
# 设置集群中每个zookeeper服务的地址与端口号
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
创建数据持久化目录与日志文件目录:
mkdir -p /opt/module/zookeeper/data
mkdir -p /opt/module/zookeeper/logs
配置zookeeper环境变量:
export ZK_HOME=/opt/module/zookeeper
export PATH=$PATH:$ZK_HOME/bin
#执行 source /etc/profile 初始化环境变量
分发zookeeper与环境变量 :
scp -r /opt/module/zookeeper/ root@slave1:/opt/module/
scp -r /opt/module/zookeeper/ root@slave2:/opt/module/
scp /etc/profile root@slave1:/etc/
scp /etc/profile root@slave1:/etc/
# 在从节点 slave1、slave2 上初始化环境变量
为每个zookeeper服务指定编号:
echo 1 > /opt/module/zookeeper/data/myid
echo 2 > /opt/module/zookeeper/data/myid
echo 3 > /opt/module/zookeeper/data/myid
启动zookeeper集群:
# 在集群所有容器环境中执行:
zkServer.sh start
# 查看zookeeper集群运行状态
zkServer.sh status
# 在Mode后显示:leader或follower即为启动成功
# 停止zookeeper服务: zkServer.sh stop
配置Hbase:
vim /opt/module/hbase/conf/hbase-env.sh
# 在末尾追加
export JAVA_HOME=/opt/module/java
export HADOOP_HOME=/opt/module/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HBASE_MANAGES_ZK=false
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_PID_DIR=${HBASE_HOME}/pid
修改 hbase-site.xml 配置文件:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/module/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
修改 regionservers 文件:
vim /opt/module/hbase/conf/regionservers
# 内容如下:
master
slave1
slave2
解决 log4j 兼容性问题:
rm -rf /opt/module/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar
配置环境变量:
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
分发Hbase:
scp -r /opt/module/hbase/ root@slave1:/opt/module/
scp -r /opt/module/hbase/ root@slave2:/opt/module/
scp /etc/profile root@slave1:/etc/
scp /etc/profile root@slave1:/etc/
# 在从节点 slave1、slave2 上初始化环境变量
检查配置是否生效:
hbase version
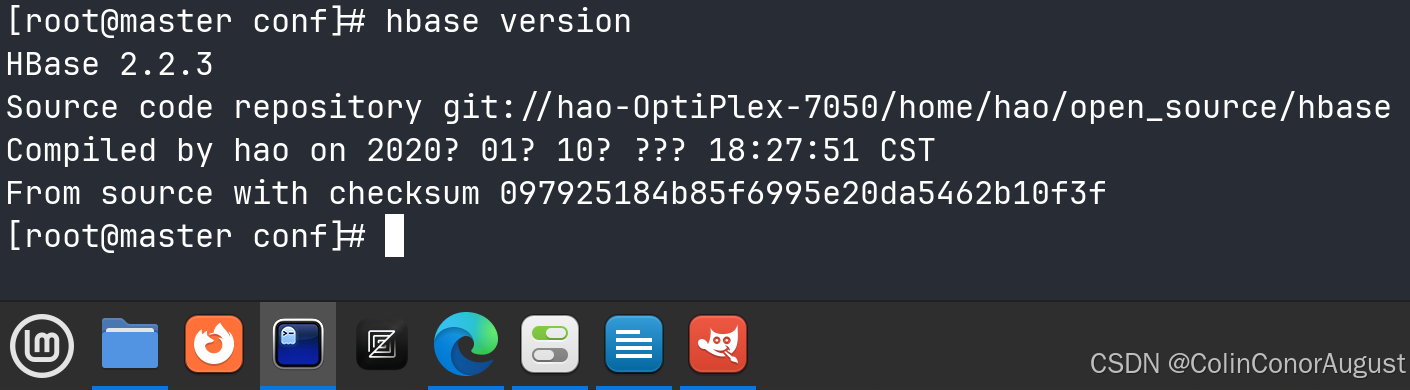
3.检查运行状态
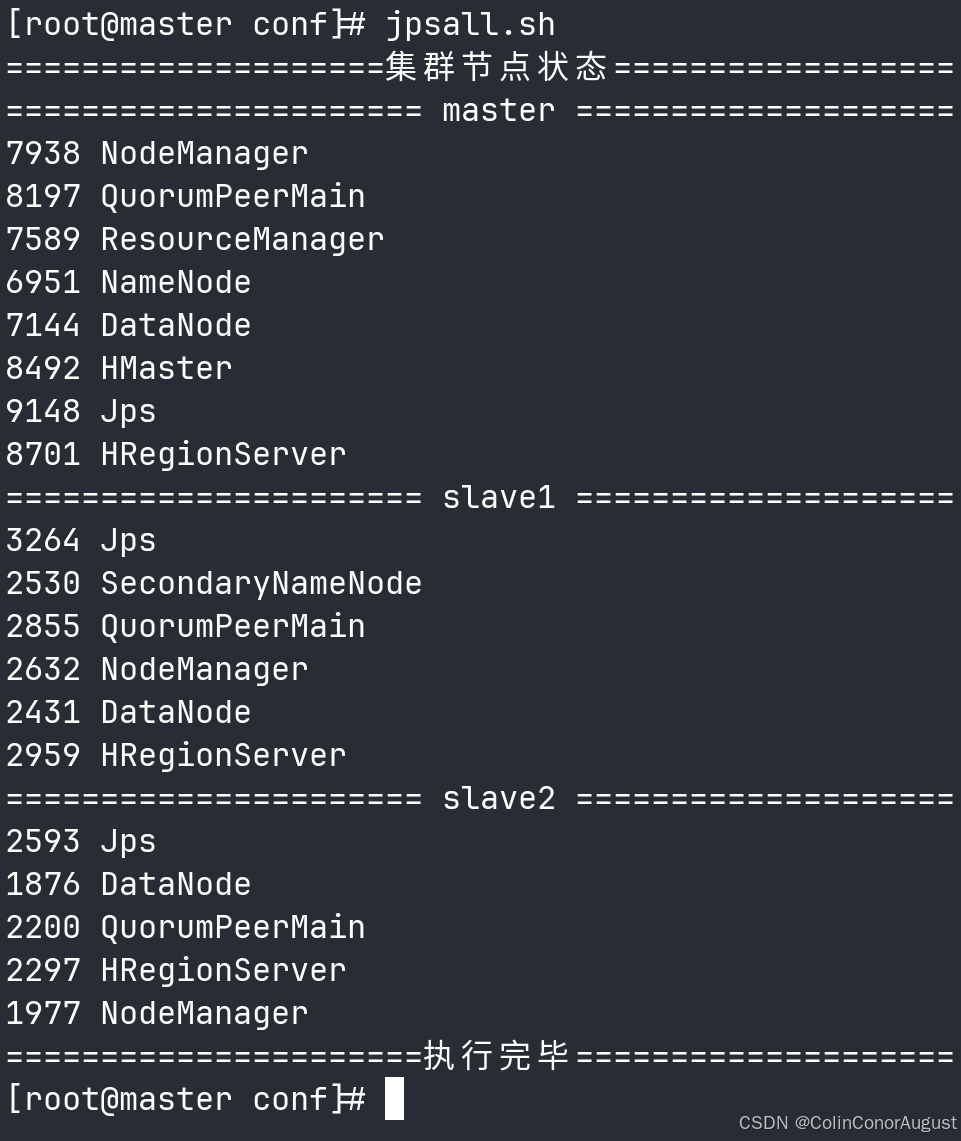
启动HBase后在三个节点分别使用jps命令查看,并将结果分别截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;正常启动后在hbase shell中查看命名空间,将查看命名空间的结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
按顺序启动:hadoop集群 ---> zookeeper集群 ---> hbase集群
start-all.sh
zkServer.sh start #所有容器环境都要执行
start-hbase.sh
查看集群运行状态:
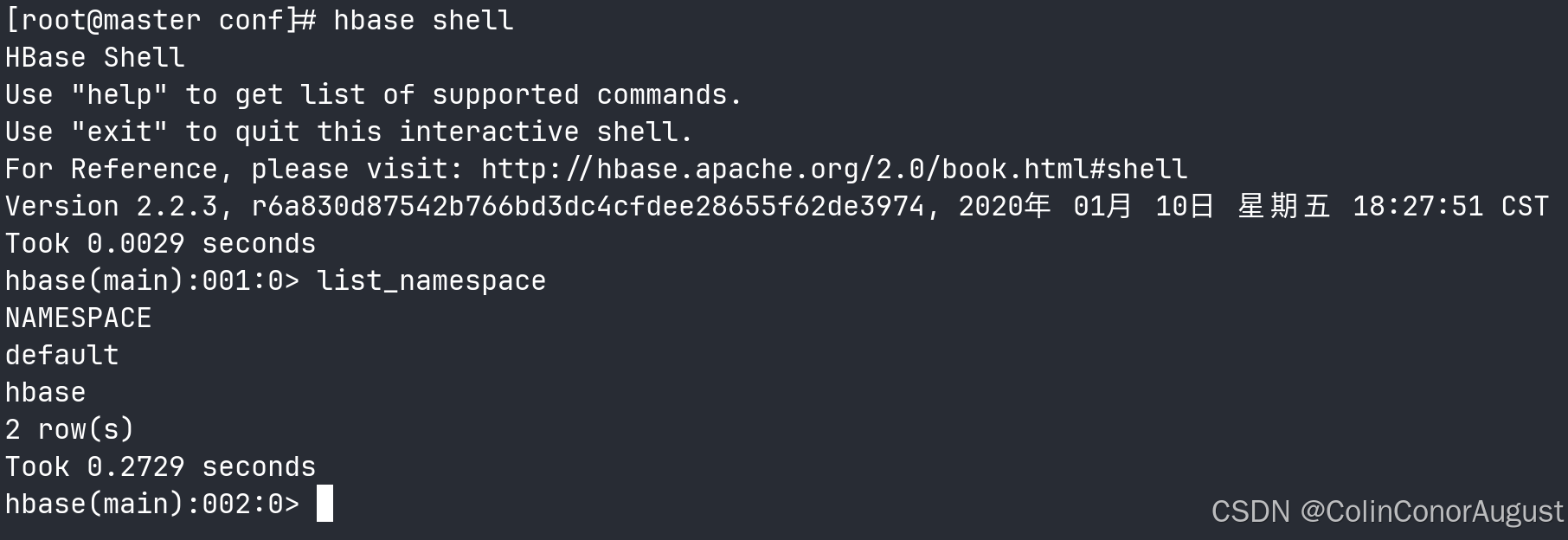
在 hbase shell 中查看命名空间:
hbase shell
list_namespace

















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









