



进入各节点的命令:
docker exec -it master /bin/bash
docker exec -it slave1 /bin/bash
docker exec -it slave2 /bin/bash
子任务一:Hadoop 完全分布式安装配置
1.复制并解压
从宿主机/opt目录下将文件hadoop-3.1.3.tar.gz、jdk-8u212-linux-x64.tar.gz复制到容器Master中的/opt/software路径中(若路径不存在,则需新建),将Master节点JDK安装包解压到/opt/module路径中(若路径不存在,则需新建),将JDK解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:将宿主机的文件复制到容器master中:
docker cp /opt/hadoop-3.1.3.tar.gz master:/opt/software
docker cp /opt/jdk-8u212-linux-x64.tar.gz master:/opt/software
第二步:解压JDK压缩包并改名:
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module
mv /opt/module/jdk1.8.0_241 /opt/module/java
2.JDK环境变量设置
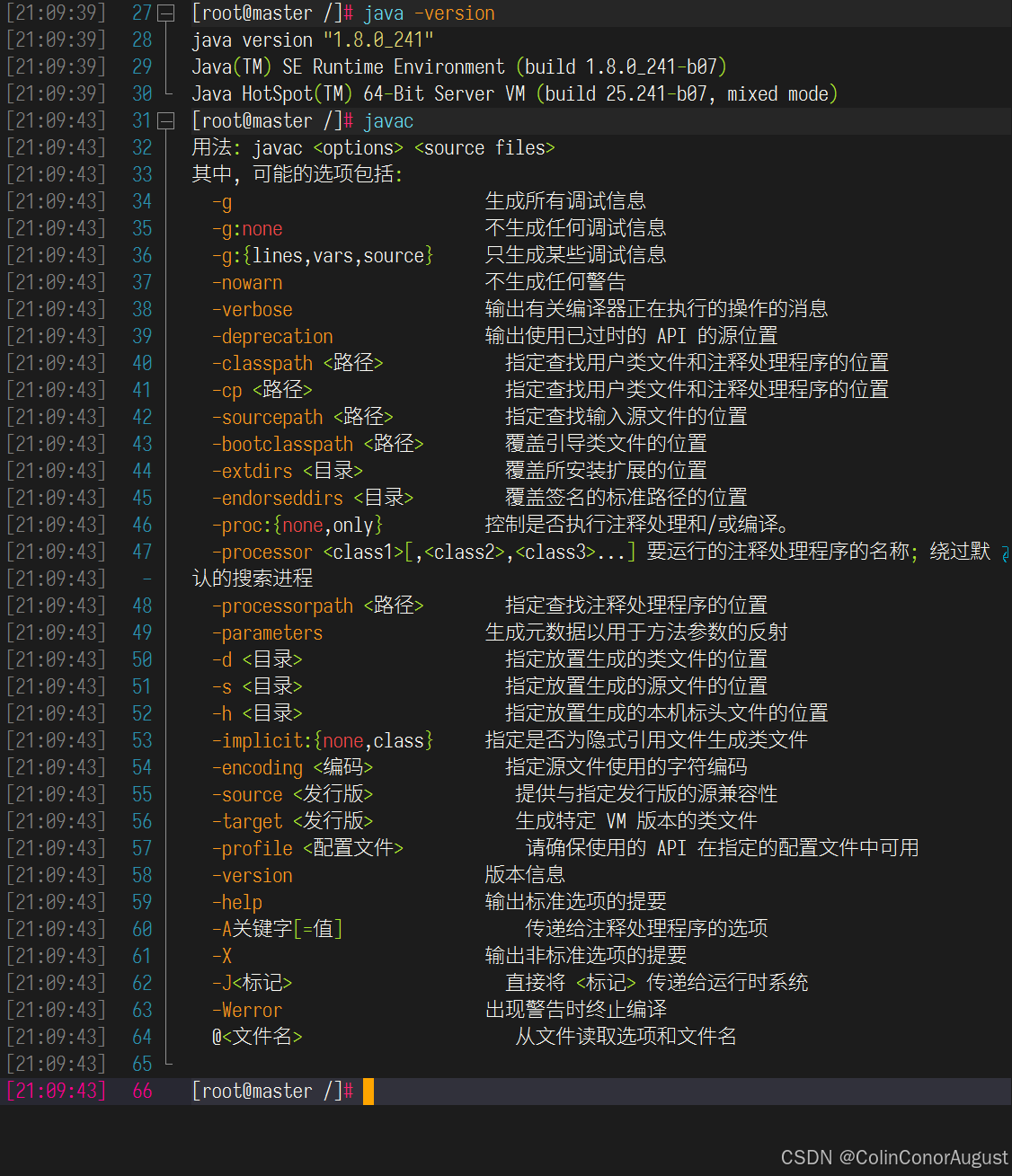
修改容器中/etc/profile文件,设置JDK环境变量并使其生效,配置完毕后在Master节点分别执行“java -version”和“javac”命令,将命令行执行结果分别截图并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:设置环境变量:
#修改/etc/profile文件,并将以下内容添加至文件末尾
export JAVA_HOME=/opt/module/java
export PATH=$PATH:$JAVA_HOME/bin
#初始化profile
source /etc/profile
第二布:验证环境变量设置:
3.环境配置
请完成host相关配置,将三个节点分别命名为master、slave1、slave2,并做免密登录,用scp命令并使用绝对路径从Master复制JDK解压后的安装文件到slave1、slave2节点(若路径不存在,则需新建),并配置slave1、slave2相关环境变量,将全部scp复制JDK的命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:配置hosts:
#修改/etc/hosts文件,并将以下内容添加至文件末尾
172.18.0.101 master
172.18.0.102 slave1
172.18.0.103 slave2
第二步:设置免密登录(三台机器都要执行):
#在主节点master中执行下条命令生成密钥
ssh-keygen -t rsa
#将主机生成的公钥文件复制到集群中的所有虚拟机上(包括自身)
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
第三步:分发JDK与环境变量配置文件
#分发hadoop与profile文件
scp -r /opt/module/java root@slave1:/opt/module
scp -r /opt/module/java root@slave1:/opt/module
scp /etc/profile root@slave1:/etc
scp /etc/profile root@slave1:/etc
#在所有容器集群中初始化profile
source /etc/profile
4.Hadoop配置
在Master将Hadoop解压到/opt/module(若路径不存在,则需新建)目录下,并将解压包分发至slave1、slave2中,其中master、slave1、slave2节点均作为datanode,配置好相关环境,初始化Hadoop环境namenode,将初始化命令及初始化结果截图(截取初始化结果日志最后20行即可)粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
第一步:解压并配置Hadoop:
tar -zxvf /opt/software/hadoop-3.3.0.tar.gz -C /opt/module
mv /opt/module/hadoop-3.3.0 /opt.module/hadoop
#修改/etc/profile文件,并将以下内容添加至文件末尾
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
#修改hadoop-3.3.0/etc/hadoop/core-site.xml
export JAVA_HOME=/opt/module/java
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#修改hadoop-3.3.0/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
</configuration>
#修改hadoop-3.3.0/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9868</value>
</property>
</configuration>
#修改hadoop-3.3.0/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
#修改hadoop-3.3.0/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,
HADOOP_YARN_HOME,HADOOP_MAPRED_HOME,HADOOP_CONF_DIR,
CLASSPATH_PREPEND_DISTCACHE</value>
</property>
</configuration>
第二步:修改workers,将master、slave1、slave2节点均作为datanode:
#修改hadoop-3.3.0/etc/hadoop/workers
master
slave1
slave2
第三步:分发hadoop,并初始化namenode
#分发hadoop与profile文件
scp -r /opt/module/hadoop-3.3.0 root@slave1:/opt/module
scp -r /opt/module/hadoop-3.3.0 root@slave1:/opt/module
scp /etc/profile root@slave1:/etc
scp /etc/profile root@slave1:/etc
#在集群中所有虚拟机中初始化profile
source /etc/profile
#在主节点master上执行下条命令,初始化namenode:
hdfs namenode -format

5.启动Hadoop集群
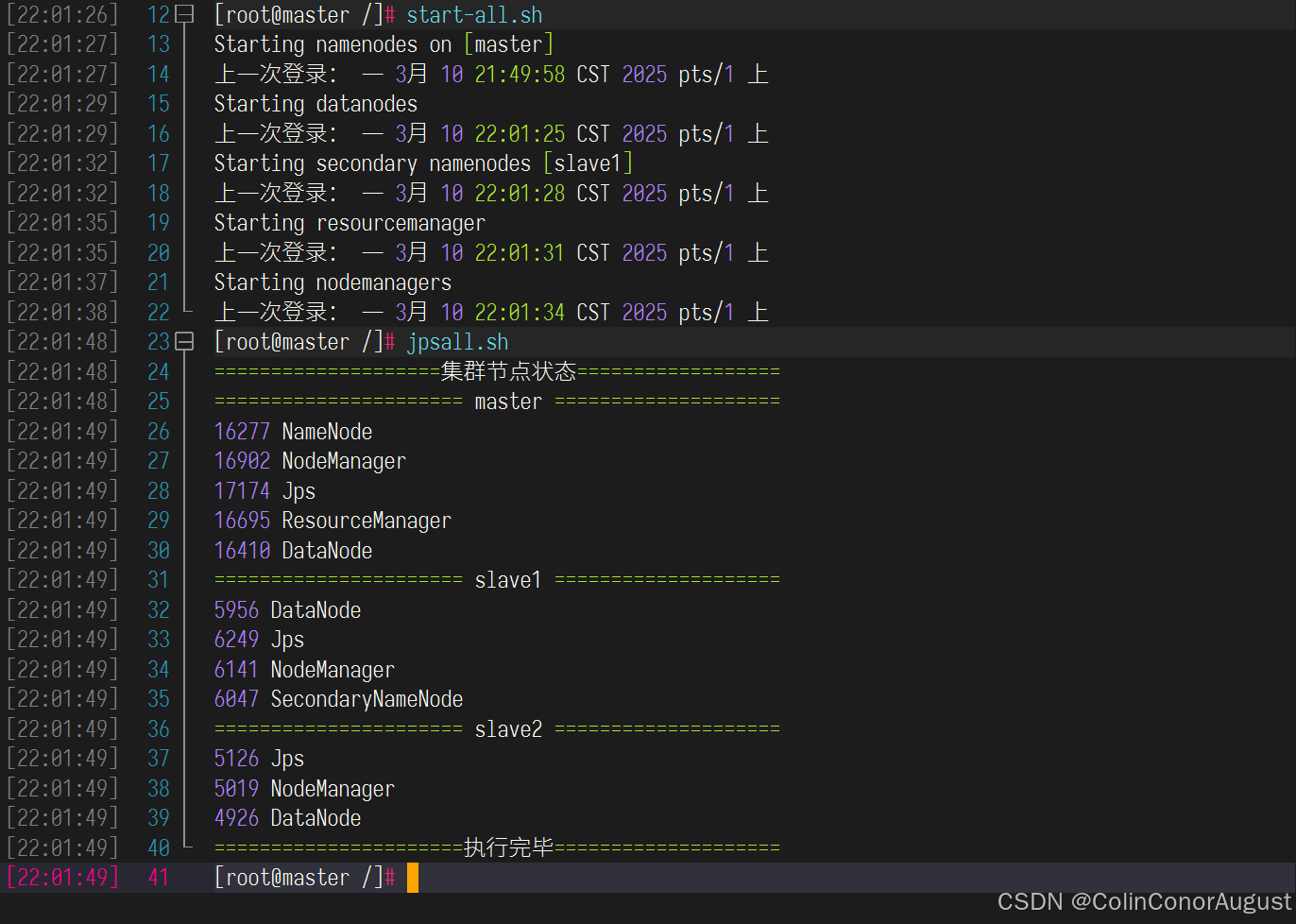
启动Hadoop集群(包括hdfs和yarn),使用jps命令查看Master节点与slave1节点的Java进程,将jps命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
启动hadoop集群,并查看进程:
子任务二:Flume安装配置
1.复制并解压
从宿主机/opt目录下将文件apache-flume-1.9.0-bin.tar.gz复制到容器Master中的/opt/software路径中(若路径不存在,则需新建),将Master节点Flume安装包解压到/opt/module目录下,将解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
将flume从宿主机复制到主节点master容器中:
docker cp /opt/apache-flume-1.9.0-bin.tar.gz master:/opt/software
解压flume压缩包:
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/module/
重命名:
mv /opt/module/apache-flume-1.9.0-bin/ /opt/module/flume
2.Flume环境配置
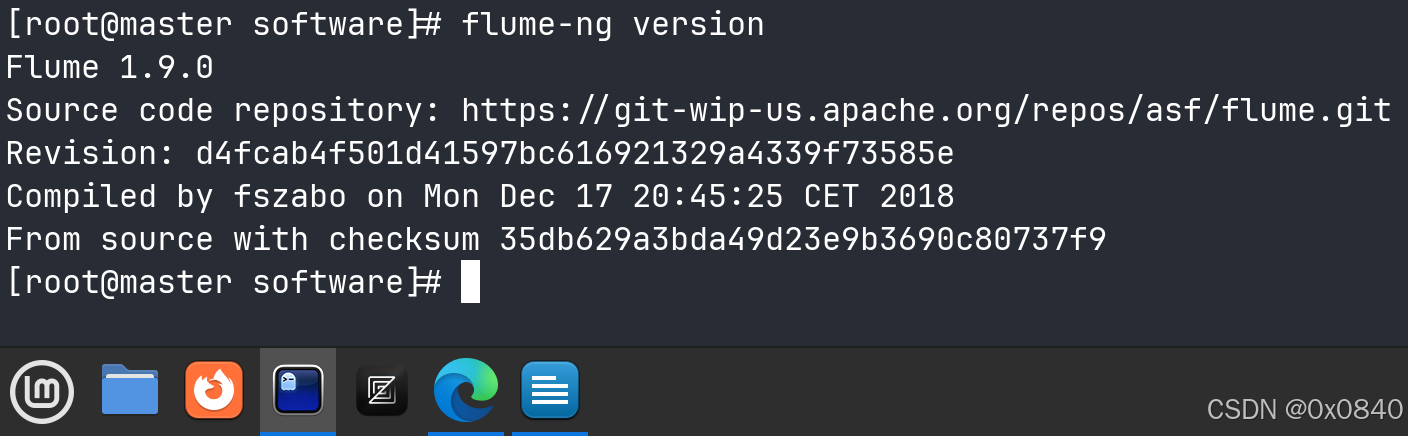
完善相关配置,设置Flume环境变量,并使环境变量生效,执行命令flume-ng version并将命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
环境变量设置
vim /etc/profile
# 将以下内容追加到文件尾部
export FLUME_HOME=/opt/module
export PATH=$PATH:$FLUME_HOME/bin
# 初始化环境变量
source /etc/profile
检查环境变量配置:
flume-ng version
3.将Hadoop日志采集到HDFS
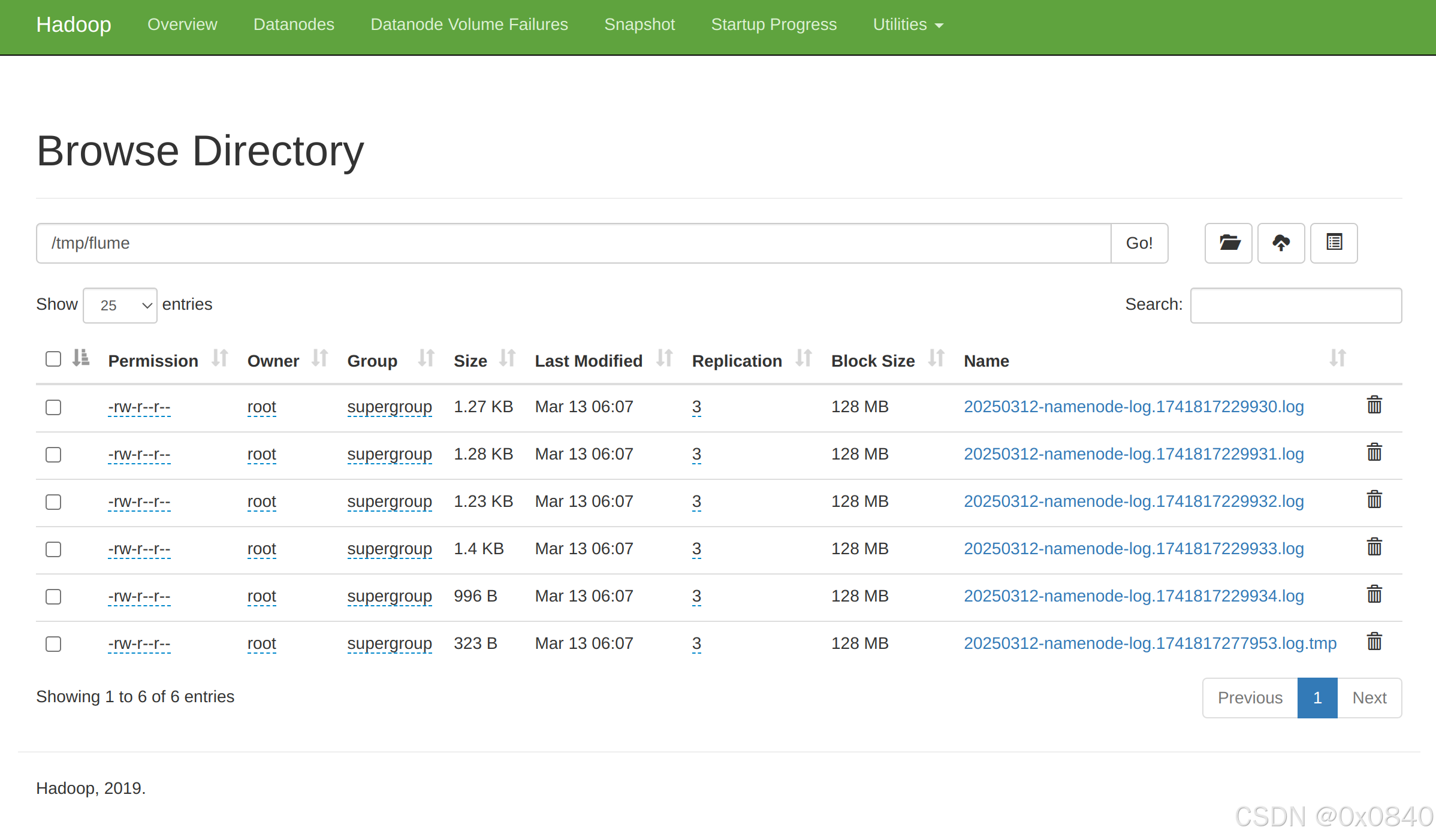
启动Flume传输Hadoop日志(namenode或datanode日志),查看HDFS中/tmp/flume目录下生成的内容,将查看命令及结果(至少5条结果)截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
同步 hadoop 与 flume 的 jar 包:
将 hadoop/share/hadoop/common/lib 目录下的 guava-27.0-jre.jar 复制到flume的lib目录下:
cp /opt/module/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/flume/lib/
删除 flume 原有旧版本的 guava 包 :
rm /opt/module/flume/lib/guava-11.0.2.jar
从 flume/conf 文件夹中复制一份配置文件模板,并设置 JAVA_HOME 变量:
cp /opt/module/flume/conf/flume-env.sh.template /opt/module/flume/conf/flume-env.sh
vim cp /opt/module/flume/conf/flume-env.sh
export JAVA_HOME=/opt/module/java
创建一个工作目录,用以存放采集方案:
mkdir /opt/module/flume/release
编写日志采集配置文件 hdfs-flume.conf :
vim /opt/module/release/hdfs-flume.conf
# 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Sourc
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hadoop/logs/hadoop-root-namenode-master.log
# Channel
a1.channels.c1.type = memory
# Sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://master:8020/tmp/flume
a1.sinks.k1.hdfs.filePrefix = %Y%m%d-namenode-log
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 连接绑定
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动Hadoop集群:
start-all.sh
开始日志采集:
flume-ng agent --conf /opt/module/flume/conf/ --conf-file /opt/module/flume/release/hdfs-flume.conf --name a1 -Dflume.root.logger=DEBUG,console
通过 HDFS WebUI (master:9870) 查看日志采集情况:
Ctrl + C 停止采集,在命令行查看采集结果:
hdfs dfs -ls /tmp/flume
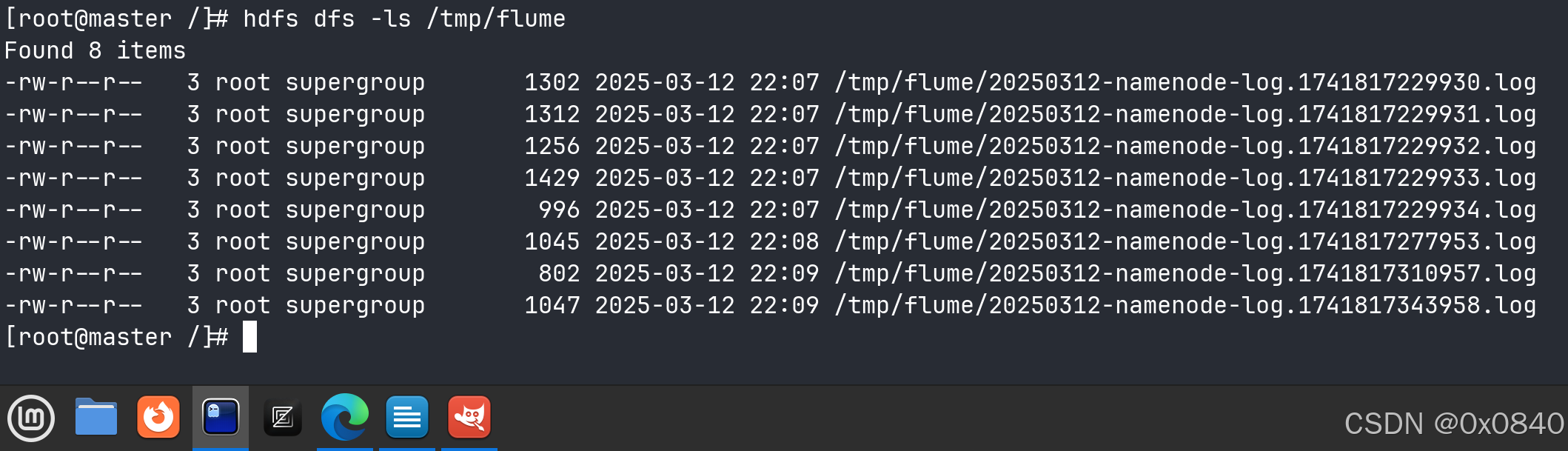
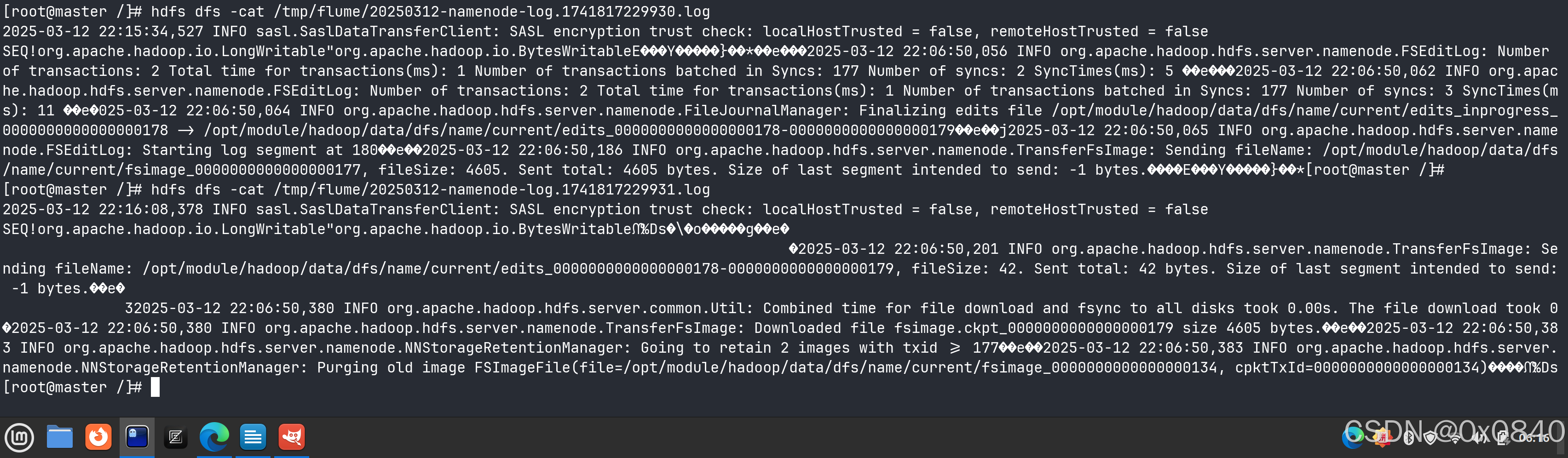
通过 cat 命令查看日志内容:
hdfs dfs -cat /tmp/flume/ *
子任务三:Flink on Yarn安装配置
1.复制并解压
从宿主机/opt目录下将文件flink-1.14.0-bin-scala_2.12.tgz复制到容器Master中的/opt/software(若路径不存在,则需新建)中,将Flink包解压到路径/opt/module中(若路径不存在,则需新建),将完整解压命令复制粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
复制、解压、改名:
docker cp /opt/flink-1.14.0-bin-scala_2.12.tgz master:/opt/software
tar -zxvf flink-1.14.0-bin-scala_2.12.tgz -C /opt/module/
mv /opt/module/flink-1.14.0/ /opt/module/flink
2.Flink环境配置
修改容器中/etc/profile文件,设置Flink环境变量并使环境变量生效。在容器中/opt目录下运行命令flink --version,将命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
环境变量配置:
vim /etc/profile
export FLINK_HOME=opt/module/flink
export PATH=$PATH:$FLINK_HOME/bin
source /etc/profile
检查环境变量配置:
flink --version
3.运行示例程序
开启Hadoop集群,在yarn上以per job模式(即Job分离模式,不采用Session模式)运行 $FLINK_HOME/examples/batch/WordCount.jar,将运行结果最后10行截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
运行命令为:
flink run -m yarn-cluster -p 2 -yjm 2G -ytm 2G $FLINK_HOME/examples/batch/WordCount.jar
在 flink/conf/flink-conf.yaml 配置文件的末尾追加:
classloader.check-leaked-classloader: false
启动Hadoop集群:
start-all.sh
运行示例程序:
flink run -m yarn-cluster -p 2 -yjm 2G -ytm 2G $FLINK_HOME/examples/batch/WordCount.jar
运行结果:
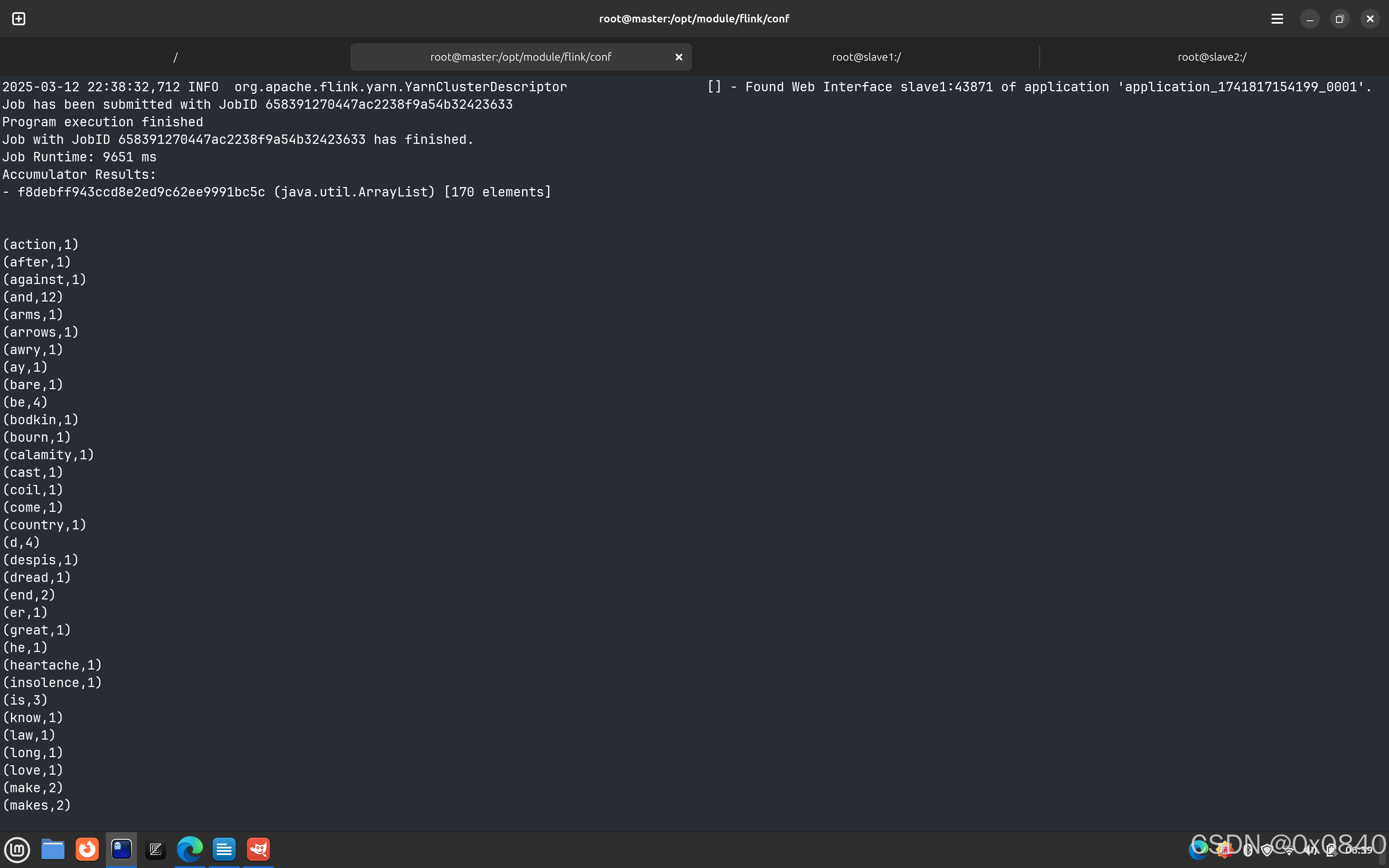

















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









