




需要学习前置知识:聚类,可参考 sheng的学习笔记-AI-聚类(Clustering)-优快云博客
什么是学习向量量化
学习向量量化(Learning Vector Quantization,简称LVQ)是试图找到一组原型向量来刻画聚类结构,但与一般聚类算法不同的是,LVQ假设数据样本带有类别标记,学习过程利用样本的这些监督信息来辅助聚类。
大概流程

解释一下:
原型向量

训练样本
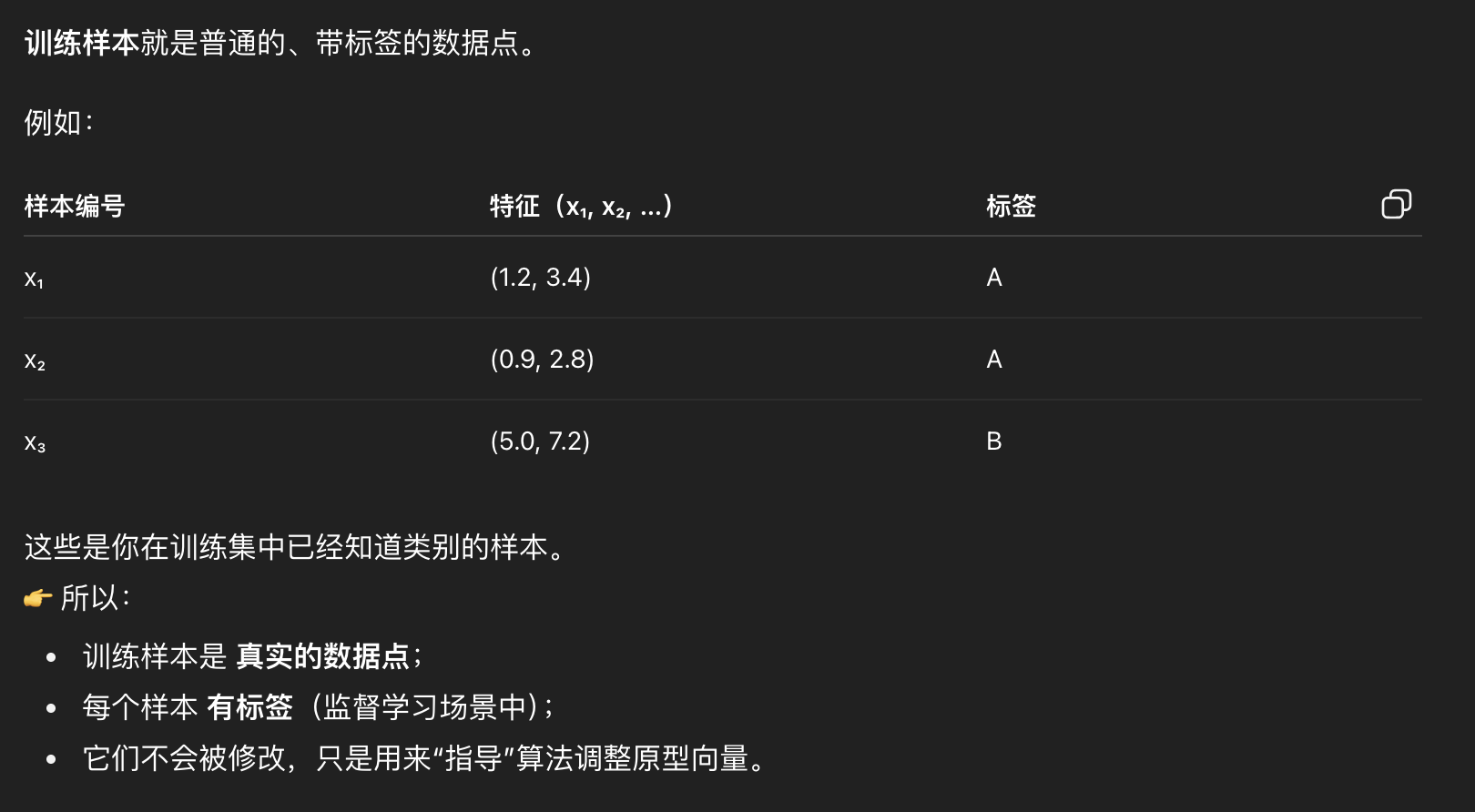
原型向量不是某个训练样本本身,而是可以“从训练样本中学习出来的、可移动的代表点”——它本质上就是一些“权重向量”。
算法代码
给定样本集D={(x1,y1),(x2,y2),…,(xm,ym)},每个样本xj是由n个属性描述的特征向量(xj1,xj2,…,xjn),yj∈Y是样本xj的类别标记。LVQ的目标是学得一组n维原型向量{P1,P2,…,Pq},每个原型向量代表一个聚类簇,簇标记ti∈Y

- 先对原型向量进行初始化,例如对第q个簇可从类别标记为tq的样本中随机选取一个作为原型向量。
- 在每一轮迭代中,算法随机选取一个有标记训练样本,找出与其距离最近的原型向量,并根据两者的类别标记是否一致来对原型向量进行相应的更新。对样本xj,若最近的原型向量pi*与xj的类别标记相同,则令pi*向xj的方向靠拢,此时新原型向量为
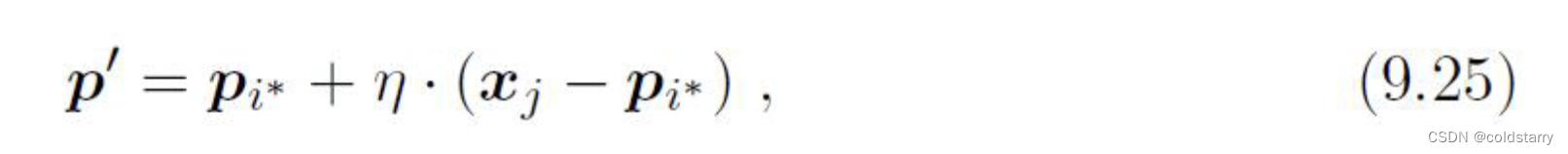 ,p'和xj的距离是:
,p'和xj的距离是: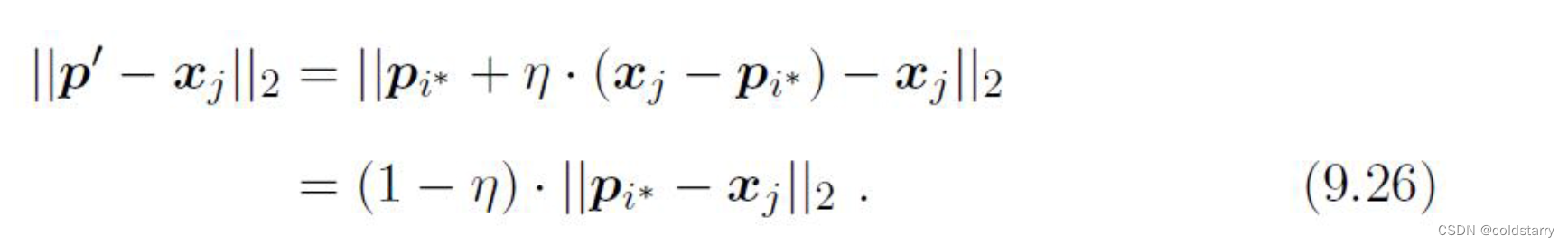 。令学习率η∈(0,1),则原型向量pi*在更新为p'之后将更接近xj。
。令学习率η∈(0,1),则原型向量pi*在更新为p'之后将更接近xj。 - 在第12行中,若算法的停止条件已满足(例如已达到最大迭代轮数,或原型向量更新很小甚至不再更新),则将当前原型向量作为最终结果返回。
示例
用以下数据集为例来演示LVQ的学习过程
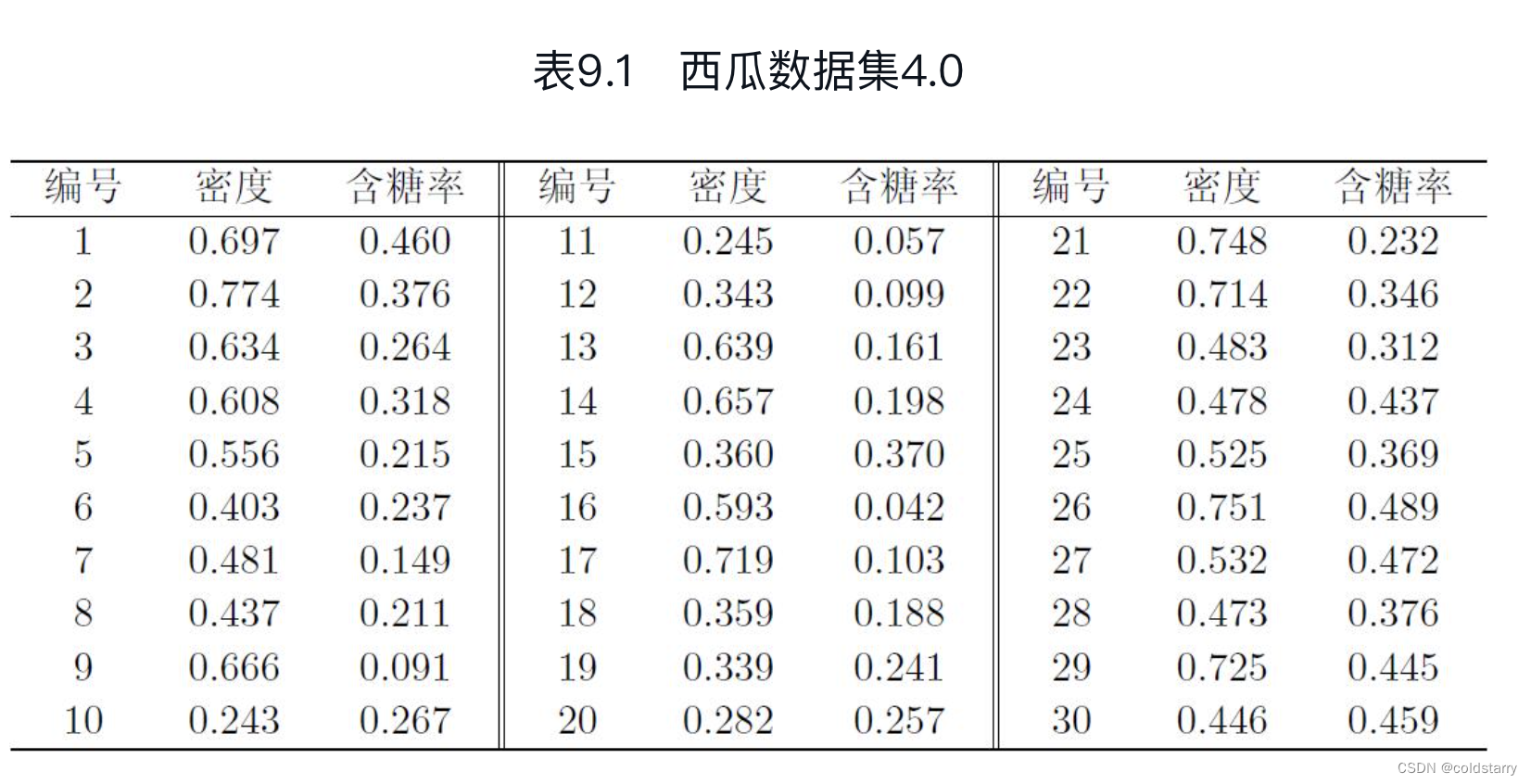
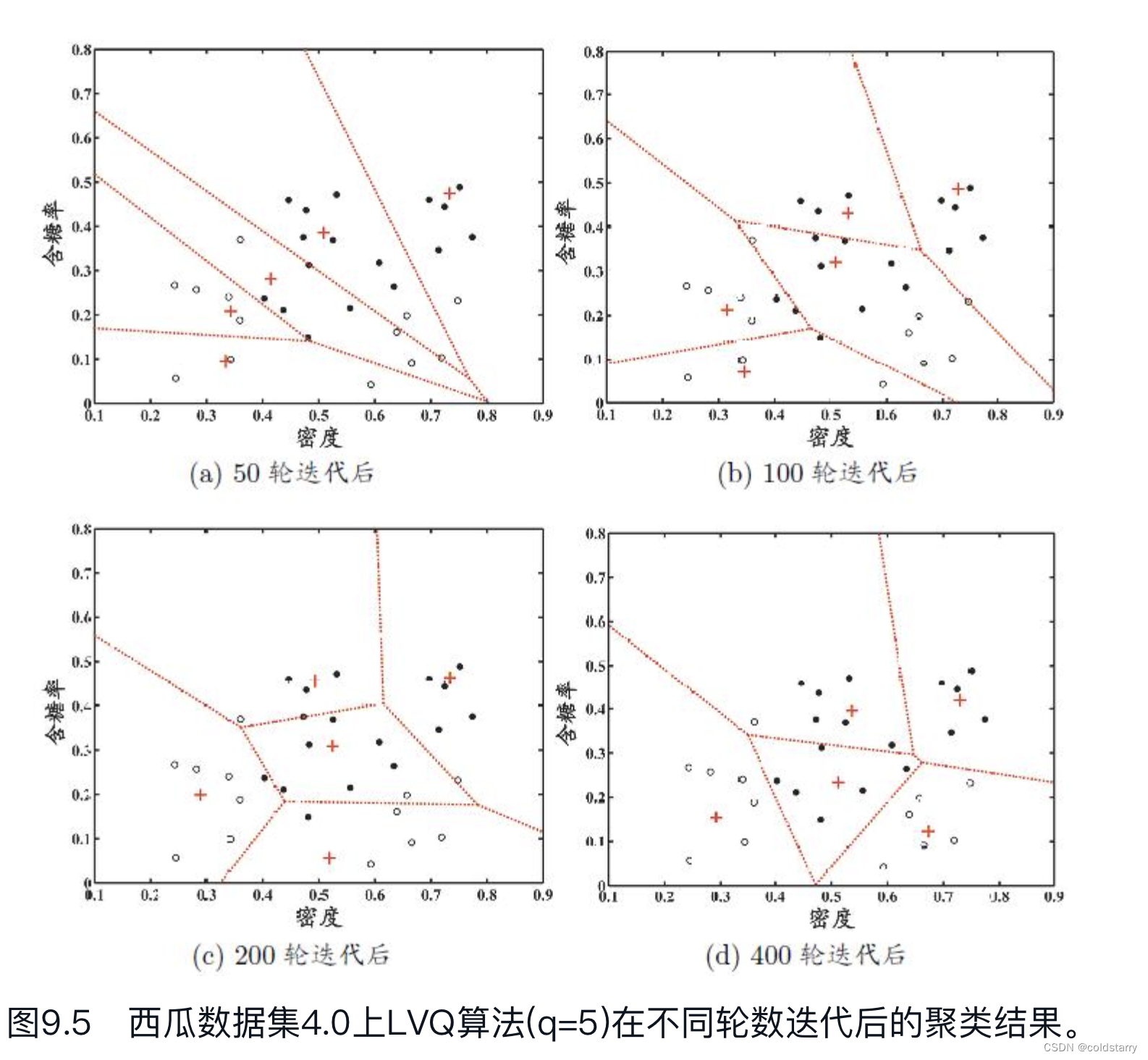
令9-21号样本的类别标记为c2,其他样本的类别标记为c1。假定q=5,即学习目标是找到5个原型向量p1,p2,p3,p4,p5,并假定其对应的类别标记分别为c1,c2,c2,c1,c1。
算法开始时,根据样本的类别标记和簇的预设类别标记对原型向量进行随机初始化,假定初始化为样本x5,x12,x18,x23,x29。
在第一轮迭代中,假定随机选取的样本为x1,该样本与当前原型向量p1,p2,p3,p4,p5的距离分别为0.283,0.506,0.434,0.260,0.032。由于p5与x1距离最近且两者具有相同的类别标记c1,假定学习率η=0.1,则LVQ更新p5得到新原型向量

将p5更新为p'后,不断重复上述过程,不同轮数之后的聚类结果如图9.5所示。

















 2632
2632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









