




目录
将winutils.exe和hadoop.dll放到C:\Windows\System32下,然后重启
hadoop官网
搭建hadoop
下载hadoop
下载后的目录作用

JAVA
需要安装java,并且保证路径没有空格
下载bin
windows要去 https://gitee.com/nkuhyx/winutils
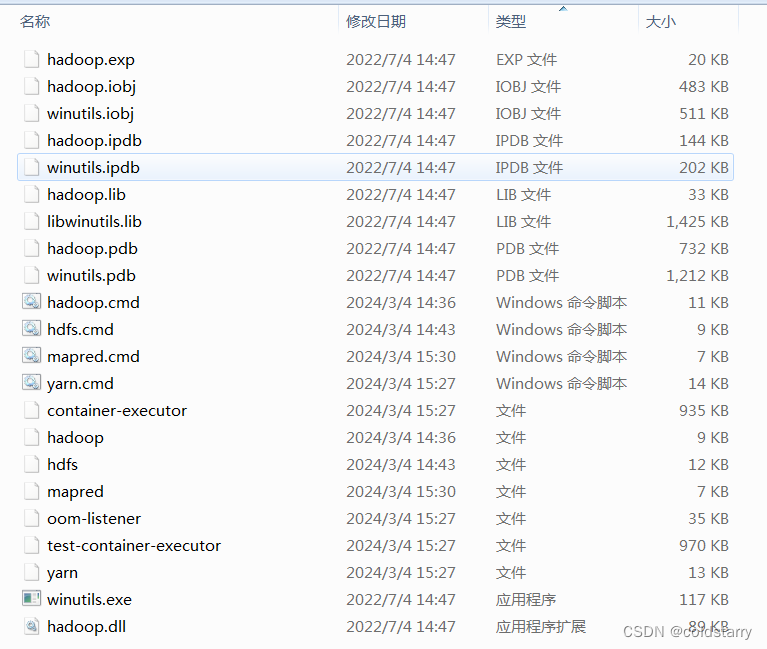
下载bin,并且将bin的内容拷贝到hadoop的bin文件夹中
windows
最好别用windows搭,贼坑,我都搭建完了,运行mapreduce的词频统计,还是失败(应该是权限问题,找了很多资料也解决不了),基于hadoop的hive也会失败(跟词频统计失败相同的报错),有空搭建个docker的
改环境变量
新增 HADOOP_HOME hadoop路径 xxx\hadoop-3.4.0
path后面新增 ;%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
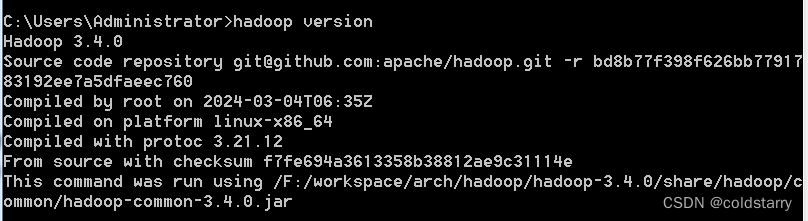
看一下安装完成
hadoop version
将winutils.exe和hadoop.dll放到C:\Windows\System32下,然后重启
F:\workspace\arch\hadoop\hadoop-3.4.0\share\hadoop\mapreduce>hadoop jar hadoop-m
apreduce-examples-3.4.0.jar pi 1 1
修改配置
vim core-site.xml
core-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9820</value>
</property><!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>F:/workspace/arch/hadoop/hadoop-3.4.0/data</value>
</property></configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:9870</value>
</property>
<!-- 2nn wen段访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>localhost:9868</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>${hadoop.tmp.dir}/dfs/data</value>
</property></configuration>
hadoop-env.sh

我的配置
export JAVA_HOME=F:\NoMoving\jdk8
hadoop-env.cmd
mapred-site.xml
<configuration>
<!--设置MR程序默认运行模式:YARN集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--MR程序历史服务地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
<!--MR程序历史服务器web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
</property>
<!---->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!---->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!---->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property></configuration>
yarn-site.xml
<configuration>
<!--设置YARN集群主角色运行机器位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!---->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否对容器实施物理内存限制-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--开启日志聚集-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--设置yare历史服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:1988/jobnistory/logs</value>
</property>
</configuration>
格式化命令
在hadoop\hadoop-3.4.0\bin中,运行命令
hdfs namenode -format
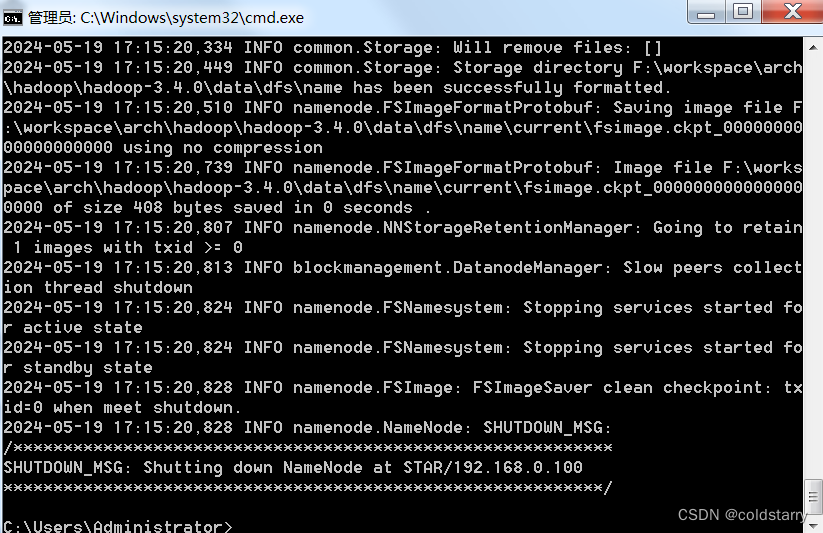
自动生成了这俩文件夹,注意,data文件夹不可以自己先创建好,要让程序自动创建
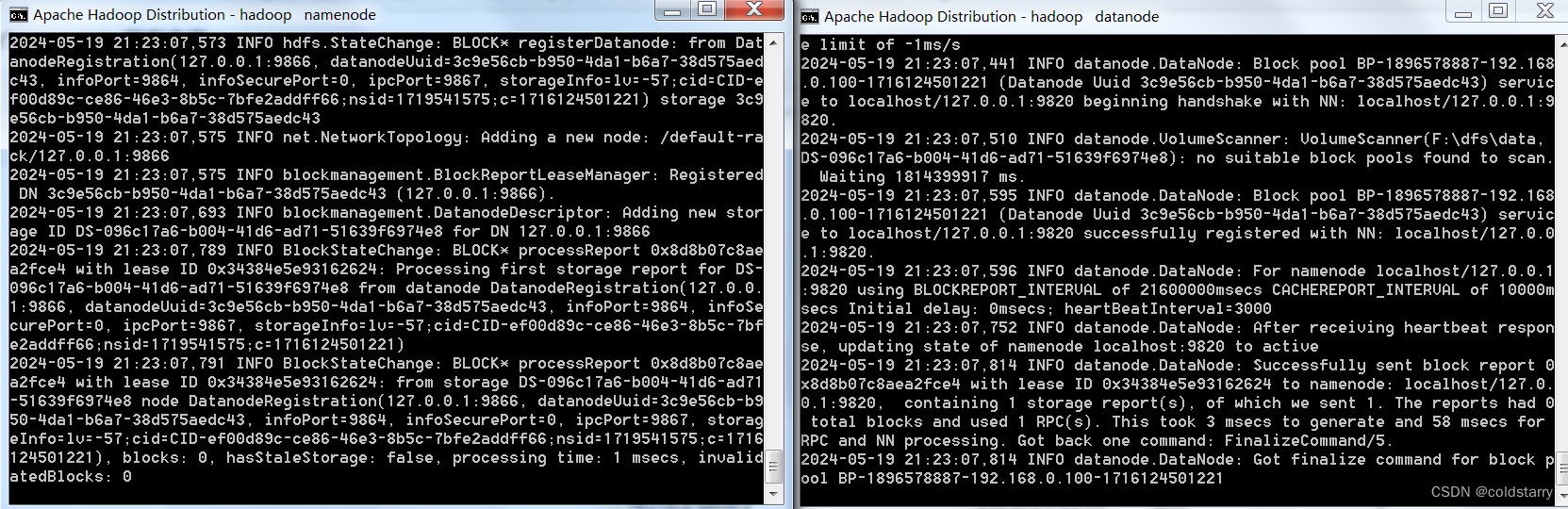
启动集群
启动命令
在hadoop\hadoop-3.4.0\sbin文件夹中运行命令
start-dfs.cmd
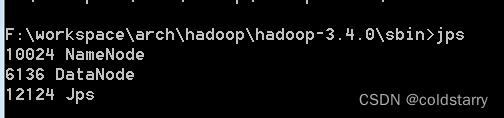
jps看看状态
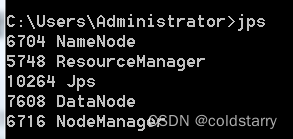
全部启动
start-all.sh
stop-all.sh
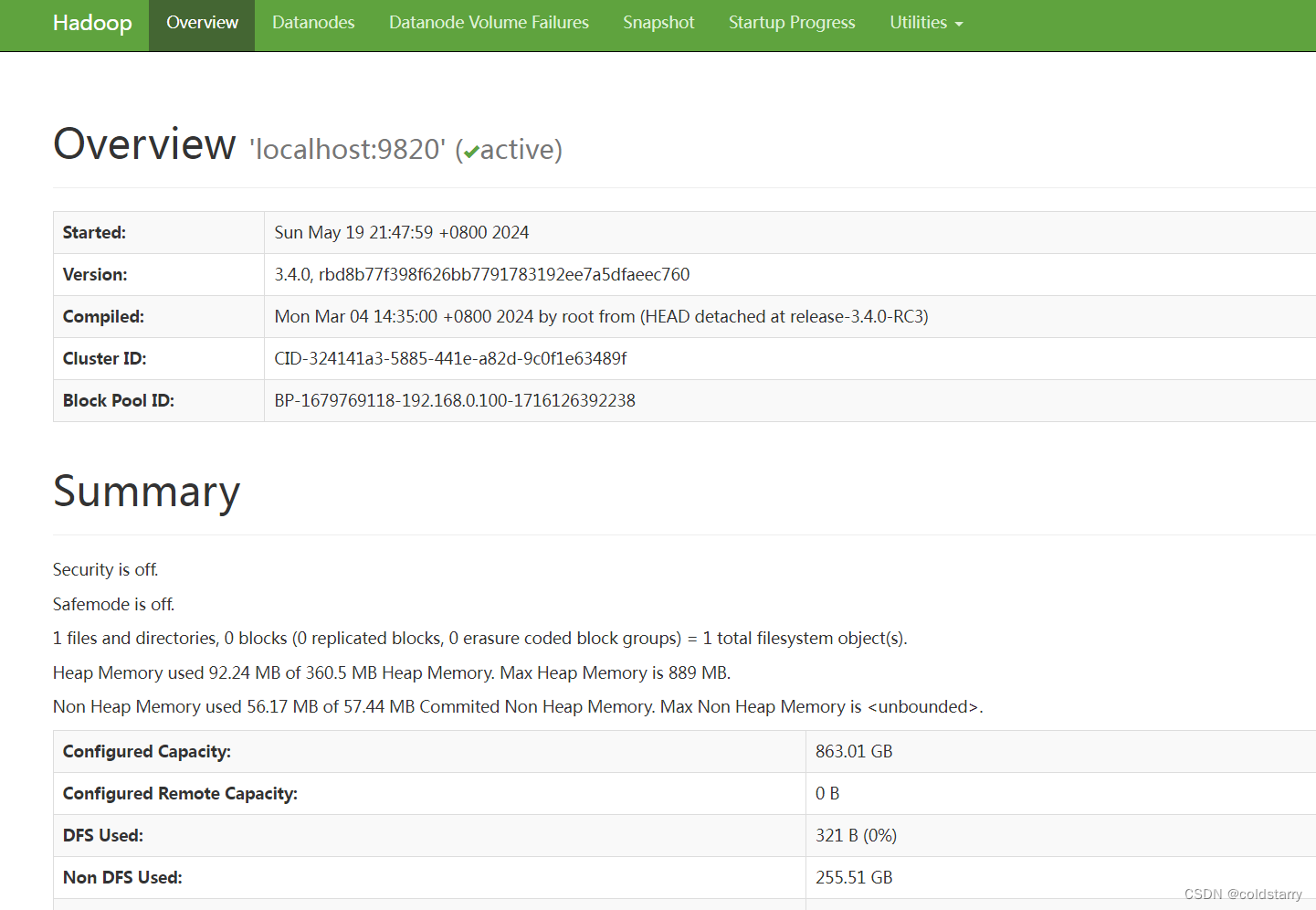
web管理页面
打开网页
yarn页面
http://localhost:8088/
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3292
3292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









