







论文概要
这篇论文提出了一个名为VSCode的通用模型,用于处理显著目标检测(SOD)和伪装目标检测(COD)任务。该模型采用了一种新颖的2D提示学习方法,通过在编码器-解码器架构中引入2D提示来学习领域和任务特定的知识,并通过提示区分损失来优化模型。VSCode在多个任务和数据集上超越了现有的最新方法,并展示了对未见任务的零样本泛化能力。
主要内容
-
引言:
- SOD和COD都是二元映射任务,涉及多种模式,具有共同性和独特线索。
- 现有研究通常使用复杂的任务特定模型,可能导致冗余和次优结果。
- VSCode是一个通用模型,利用VST作为基础模型,并在编码器-解码器架构中引入2D提示,学习领域和任务特定的知识。
-
方法:
- 基础模型:选用VST作为基础模型来捕获SOD和COD任务的共性。
- 领域特定提示:在编码器中引入四种领域特定提示(RGB、深度、热图和光流)来突出不同领域的差异。
- 任务特定提示:在编码器和解码器中引入任务特定提示,分别学习SOD和COD任务的特定特征。
- 提示区分损失:提出了一种提示区分损失,以有效分离领域和任务的特定知识。
-
实验:
- 进行了大量实验,验证了VSCode在多个任务和数据集上的性能优越性。
- 通过消融研究评估了不同设计组件的有效性,证明了2D提示和提示区分损失的有效性。
-
结果和讨论:
- VSCode在26个数据集上的表现优于现有的最新方法。
- 展示了VSCode对未见任务(如RGB-D COD)的零样本泛化能力。
动机、贡献、创新点
论文动机
现有的显著目标检测(SOD)和伪装目标检测(COD)方法通常采用复杂的、特定任务的模型,导致冗余和性能次优。此外,单独为每个任务设计模型需要大量的数据和时间,且可能导致模型过拟合,泛化能力差。因此,需要一种通用模型来同时处理多个SOD和COD任务,从而充分利用所有数据,减少过拟合风险,并提高模型的泛化能力。
论文贡献
- 通用模型VSCode:提出了第一个能够处理多模态SOD和COD任务的通用模型VSCode。
- 基础分割模型:使用基础分割模型来聚合不同任务的共性,并引入2D提示来学习领域和任务的特性。
- 提示区分损失:提出了提示区分损失,有效增强了2D提示和基础模型对特性的学习能力。
- 性能超越现有方法:VSCode在26个数据集上的六个任务中表现超越了所有现有的最新方法,并展示了对未见任务的零样本泛化能力。
创新点
- 2D提示学习:首次在SOD和COD任务中引入2D提示学习方法,通过在编码器-解码器架构中引入领域特定和任务特定的提示,分别捕获不同领域和任务的特性。
- 提示区分损失:提出了提示区分损失,旨在最小化同类型提示之间的相关性,确保每个提示获取独特的领域或任务知识。
- 通用模型架构:设计了一个简单而有效的架构,通过联合训练多个任务,显著降低了模型的复杂性、计算成本和参数量。
- 零样本泛化能力:VSCode展示了强大的零样本泛化能力,可以通过组合不同的领域和任务提示,处理未见任务。
通过这些创新,VSCode不仅提高了SOD和COD任务的性能,还展示了其在处理多模态任务方面的潜力。
Methodology 概要
方法论概要
这篇论文提出了一种名为VSCode的通用模型,用于处理显著目标检测(SOD)和伪装目标检测(COD)任务。下面是其方法论的通俗总结:
-
基础模型:
- 使用一种称为VST(视觉显著性转换器)的模型作为基础模型。这个模型通过编码器和解码器架构来处理图像,捕获图像中不同部分之间的关系。
- VST模型能够同时处理多个任务,并且通过共享参数,能够学习到不同任务之间的共性。
-
领域特定提示:
- 论文引入了四种领域特定的提示(RGB、深度、热图和光流),这些提示帮助模型理解来自不同领域(例如RGB图像、深度图像等)的特性。
- 在编码器的每一层中,这些提示都会被添加到图像特征中,帮助模型更好地分离不同领域的特性。
-
任务特定提示:
- 为了区分显著目标检测和伪装目标检测,模型在编码器和解码器中都引入了任务特定的提示。
- 这些提示帮助模型在编码阶段理解哪些特征与任务相关(如显著目标或伪装目标),在解码阶段精确地重建目标的边界和区域。
-
提示区分损失:
- 为了确保领域特定提示和任务特定提示能够分别学习到独特的知识,论文提出了一种提示区分损失。
- 这种损失函数通过减少提示之间的相似性,确保每个提示都能专注于学习特定的领域或任务信息。
-
2D提示学习架构:
- 在整个模型中,领域特定提示和任务特定提示在不同层次上被结合使用,以捕获低层次的特征(如边缘、颜色)和高层次的语义信息(如目标形状、位置)。
- 编码器通过逐层引入领域特定提示,解码器通过任务特定提示精确重建目标,确保模型能够处理不同的SOD和COD任务。
总结
VSCode模型通过引入领域特定提示和任务特定提示,结合提示区分损失,成功地在单一模型中处理多个显著目标检测和伪装目标检测任务。这种方法不仅提高了模型的性能,还展示了其对未见任务的泛化能力。
作者使用 Visual saliency transformer ICCV 2021 作为baseline model
模型配图
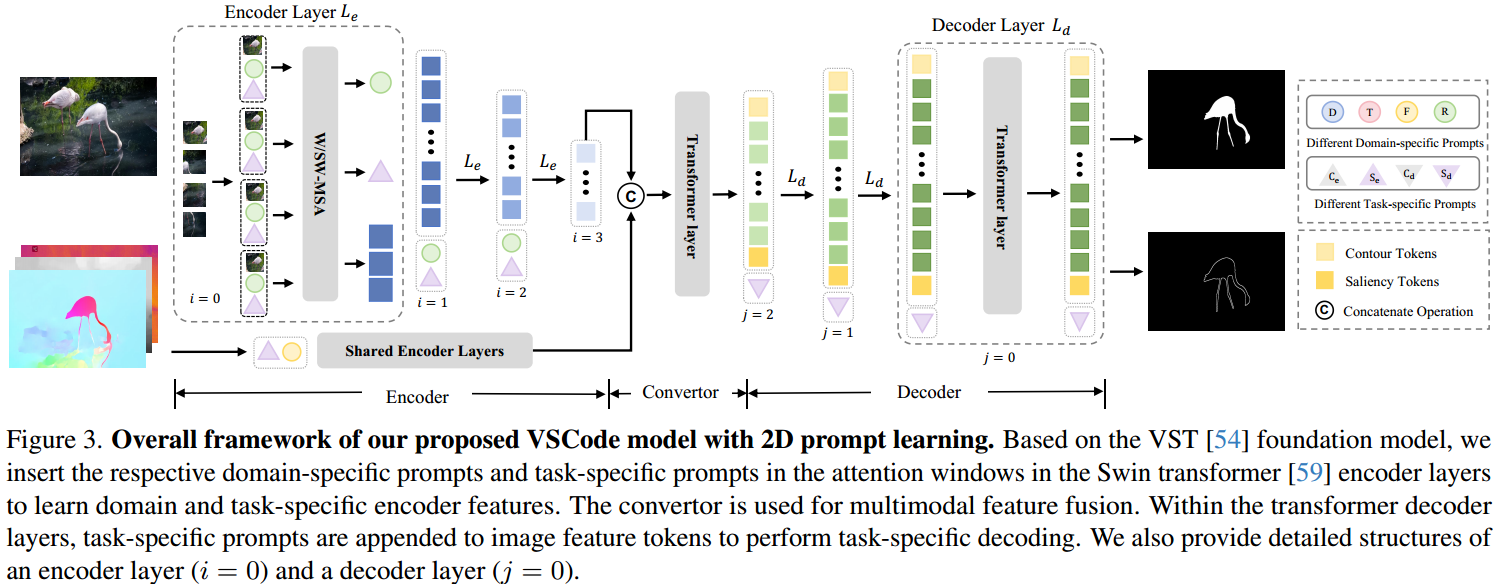
图3. VSCode模型的整体框架
概述
这张图展示了VSCode模型的整体框架,特别强调了2D提示学习方法。该模型基于VST(Visual Saliency Transformer)基础模型,采用Swin Transformer的编码器层进行领域和任务特定提示的学习。模型通过共享的编码器层、转换器和解码器层,最终实现显著目标检测和伪装目标检测的任务。
详细解释
编码器部分
-
输入图像:
- 输入的图像可以是RGB图像、深度图、热图或光流图,代表了不同的领域。
-
领域特定提示 (Domain-specific Prompts):
- 在Swin Transformer编码器层( L e L_e Le)的注意窗口中插入了领域特定提示。这些提示帮助模型学习领域特定的编码器特征。
- 图中用不同颜色和符号表示不同的领域提示,例如,D(深度)、T(热图)、F(光流)、R(RGB)。
-
任务特定提示 (Task-specific Prompts):
- 在编码器层中还插入了任务特定提示,这些提示帮助模型学习任务特定的特征。任务特定提示包括显著目标检测( S e S_e Se)和伪装目标检测( C e C_e Ce)。
- 在图中,这些提示分别用不同的符号表示。
-
共享编码器层:
- 经过领域特定提示和任务特定提示处理的特征通过共享的编码器层进行进一步的处理和融合。
转换器部分
- 转换器 (Convertor):
- 用于多模态特征融合,将来自不同领域的特征进行有效的整合。
- 图中用灰色方框表示,连接编码器和解码器。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









