



VuRLE:通过学习示例实现自动漏洞检测与修复
摘要
漏洞已成为许多系统安全的主要威胁。攻击者可以通过利用未修补的漏洞窃取私有信息并执行有害操作。由于漏洞可能不会影响系统的典型功能,因此它们往往长时间未被发现。此外,如果开发者不是安全专家,通常很难正确修复漏洞。为了帮助开发者应对多种类型的漏洞,我们提出了一种名为VuRLE的新工具,用于自动检测和修复漏洞。VuRLE(1)从易受攻击的代码及其对应的已修复代码示例中学习转换性编辑及其上下文(即表征编辑位置的代码);(2)对相似的转换性编辑进行聚类;(3)提取编辑模式和上下文模式,为每个聚类创建多个修复模板。VuRLE使用上下文模式来检测漏洞,并定制相应的编辑模式以修复这些漏洞。我们在来自48个真实应用程序的279个漏洞上评估了VuRLE。在10折交叉验证下,我们将VuRLE与另一种自动修复工具LASE进行了比较。实验结果表明,VuRLE成功检测出279个漏洞中的183个,并修复了其中的101个,而LASE仅能检测出58个漏洞并修复21个。
关键词
自动化模板生成 · Vulnerability检测 · 自动化程序修复
1 引言
漏洞对计算机系统构成严重威胁。然而,如果开发者不是安全专家,则很难检测和修复漏洞。已有多种漏洞检测工具被提出,以帮助开发者检测和修复不同类型的漏洞,例如密码学误用[17], 跨站脚本(XSS)[26], 组件劫持漏洞[28], 等。
先前关于自动漏洞修复的研究通常集中于一种类型的漏洞。这些研究需要为特定漏洞定制手动生成的模板或定制启发式方法。CDRep[17]是一种工具,用于修复加密漏洞。它检测并修复对加密算法的误用。通过手动总结正确原语实现中的修复模式,生成修复模板。类似于CDRep,王等人[26]提出了一种修复Web应用程序中字符串漏洞的方法。他们手动构建输入字符串模式和攻击模式。基于输入-攻击模式,该工具可以计算出安全的输入,并将恶意输入转换为安全输入。AppSealer[28]定义手动编写的规则,用于处理不同类型的数据,通过污点分析来修复组件劫持漏洞。通过应用数据流分析,它可以识别被污染的变量,并根据定义的规则进一步修复这些变量。
手动生成修复模板和定义修复规则是繁琐且耗时的工作。随着技术和计算机系统的进步,可能会出现不同类型的漏洞,而修复每种漏洞可能需要不同的修复模式。遗憾的是,为各种漏洞手动创建特定的模板或规则成本极高,甚至不切实际。上述事实凸显了开发能够自动生成修复模板的技术的重要性。
为了帮助开发者修复常见缺陷,孟等人[20]提出了LASE,该方法能够自动生成修复模板。LASE从两个或更多修复示例中自动学习编辑脚本。然而,LASE的推理过程存在两个主要局限性。首先,它只能为某一类型缺陷生成一个通用模板。但实际上,根据缺陷出现位置的上下文(即缺陷所在的前面代码),同一缺陷可能有多种不同的修复方式。其次,当一个修复示例涉及多个缺陷的修复时,LASE无法从中学习到多个修复模板。
为了解决上述局限性,我们设计并实现了一种名为VuRLE(通过示例学习进行漏洞修复)的新工具,该工具可帮助开发者自动检测和修复多种类型的漏洞。VuRLE的工作方式如下:
1. VuRLE分析一个包含修复示例的训练集,并识别编辑块——每个编辑块来自每个示例中的一系列相关编辑及其上下文。每个示例包含易受攻击的代码及其修复的代码。
2. VuRLE将相似的编辑块聚类为组。
3. 接着,VuRLE从高度相似的编辑对中为每组生成多个修复模板。
4. 然后,VuRLE使用这些修复模板来识别易受攻击的代码。
5. 最终,VuRLE选择一个合适的修复模板,并应用模板中的变换性编辑来修复易受攻击的代码。
VuRLE通过生成多个修复模板而非仅一个,解决了LASE的第一个局限性。这些模板被分组,并共同用于准确识别漏洞。VuRLE还采用了一种启发式方法,用于为检测到的漏洞识别最合适的模板。它通过将修复示例分解为多个代码段来解决第二个局限性,然后从每个代码段中提取一个编辑块。这些编辑块可能涵盖不同的缺陷,并可用于生成不同的修复模板。但这将导致产生大量编辑的块,其中许多可能对漏洞的识别和修复并无帮助。为解决此问题,VuRLE采用启发式方法来识别适合的编辑块,以便将其泛化为修复模板。
我们在48个真实世界应用中的279个漏洞上使用10折交叉验证设置对VuRLE进行评估。在该实验中,VuRLE成功检测出279个漏洞中的183个(65.59%),并修复了其中101个。与LASE相比这是一个显著的改进,因为LASE仅能检测出279个漏洞中的58个(20.79%),并修复21个。
本文其余部分组织如下。第2节概述我们的方法。第3节详细阐述我们方法的学习阶段,第4节介绍我们方法的修复阶段。实验结果在第5节中给出。相关工作在第6节中介绍。7节总结全文。
2 VuRLE概述
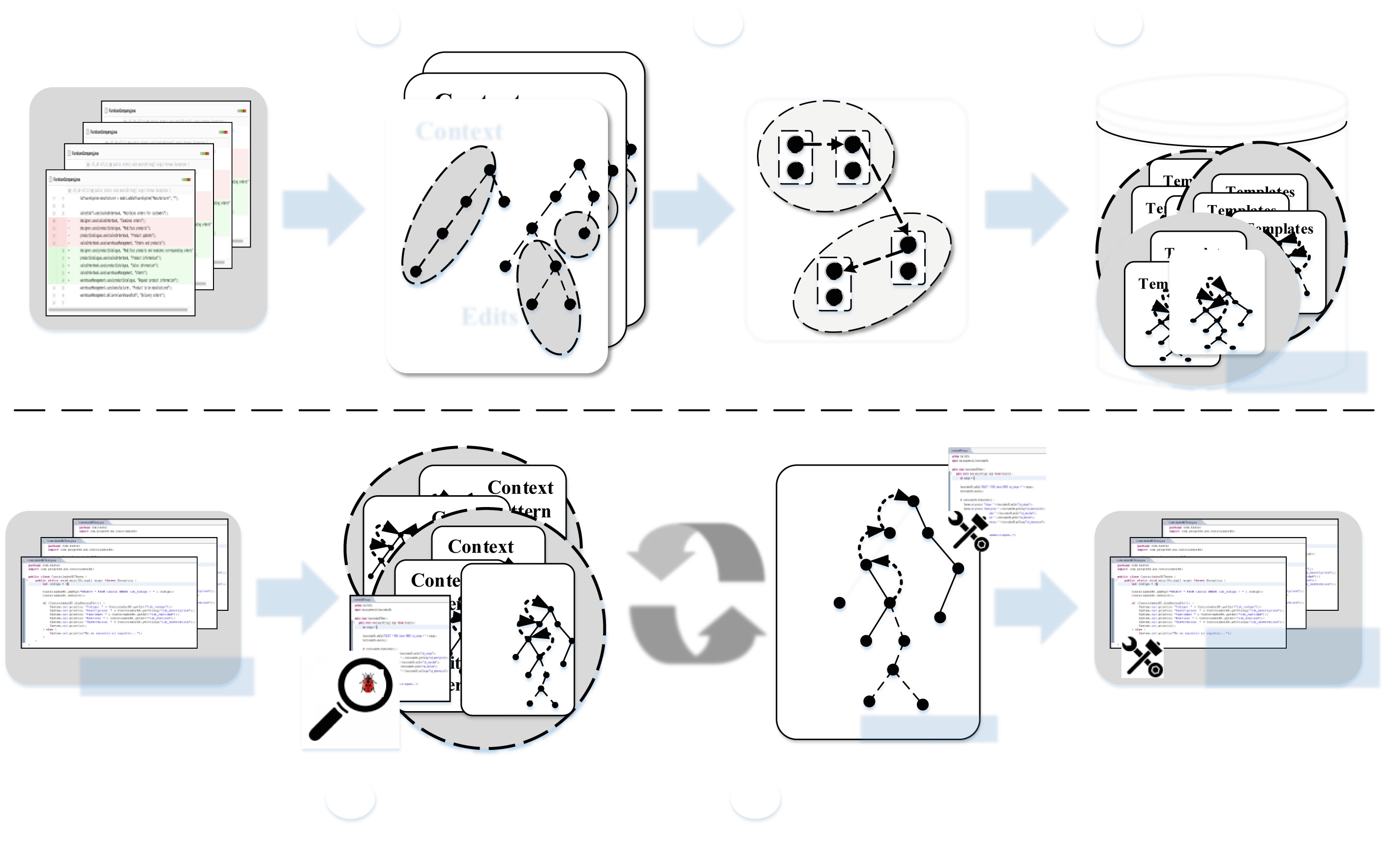
在本节中,我们介绍VuRLE如何修复漏洞。图1展示了VuRLE的工作流程。VuRLE包含两个阶段:学习阶段和修复阶段。下面我们简要概述每个阶段的工作细节。
学习阶段
VuRLE通过分析修复示例中的编辑,分三个步骤(步骤1–3)生成模板。
1. 编辑块提取
VuRLE首先通过对训练集中已知修复示例的每段易受攻击的代码及其修复的代码进行抽象语法树(AST)diff[8],来提取编辑块。易受攻击的代码与修复的代码之间的差异可能存在于多个代码片段(即连续的代码行)中。对于每一对易受攻击的和修复的代码段,VuRLE输出一个编辑块,该编辑块包含两部分:(1)编辑操作序列,以及(2)其上下文。前者指定一系列抽象语法树节点插入、删除、更新和移动操作,用于将易受攻击的代码段转换为修复的代码段;后者指定对应于这两个代码段之前出现的代码的公共抽象语法树子树。
2. 编辑组生成
VuRLE将每个编辑块与其他编辑块进行比较,并生成相似的编辑块组。VuRLE通过多个步骤创建这些edit groups。首先,它创建一个图,其中每个编辑块是一个节点,并且当两个编辑块共享一个较大规模的编辑操作的最长公共子串[11]时,在它们之间添加边。接着,它从这些图中提取连通分量[12]。最后,应用一种受DBSCAN[5]启发的聚类算法,将每个连通分量中的编辑块划分为编辑组。
3. 修复模板生成
在每个编辑组中,VuRLE为连通分量内相邻的每一对编辑块(作为步骤2的一部分生成)生成一个修复模板。每个修复模板都有一个编辑模式和一个上下文模式。编辑模式指定一系列转换性编辑,而上下文模式指定应应用转换性编辑的代码位置。为了创建编辑模式,VuRLE识别两个编辑块中编辑操作的最长公共子串。为了创建上下文模式,VuRLE比较两个编辑块上下文部分出现的代码。为了泛化这些模式,VuRLE将模式中出现的具体标识符名称和类型抽象为占位符。
上下文模式用于识别易受攻击的代码,而编辑模式用于在修复阶段修复已识别的漏洞。
修复阶段
VuRLE通过两个步骤(第4–5步)选择最合适的模板来检测和修复漏洞。这两个步骤将重复多次,直到不再检测到易受攻击的代码段为止。
4. 编辑组选择
给定输入代码和一组修复模板,VuRLE将输入代码的代码段与编辑组进行比较,并识别出与之最匹配的编辑组。
5. 模板选择与应用
最匹配的编辑组可能有多个模板与输入代码段匹配。VuRLE逐一枚举匹配的模板,并应用模板中编辑模式所指定的转换性编辑。如果应用转换性编辑导致产生冗余代码,VuRLE将继续尝试下一个模板;否则,它将标记该代码段为漏洞,并通过应用转换性编辑生成修复的代码段。
3 学习阶段:从修复示例中学习
在此阶段,VuRLE处理一组漏洞修复示例以生成相似的修复模板组。本阶段涉及的三个步骤(编辑块提取、编辑块组提取和修复模板生成)将在下文详细介绍。
3.1 编辑块提取
对于每个修复示例,VuRLE使用Falleri等人的GumTree[7]来比较易受攻击的代码及其修复的代码的抽象语法树。抽象语法树中对应于源代码文件的每个节点都可以表示为一个二元组:(类型, 值)。该二元组的第一部分表示节点的类型,例如VariableDeclarationStatement、简单类型、简单名称等。第二部分表示存储在节点中的具体值,例如字符串、读取行、“OziExplorer”等。
使用GumTree,VuRLE为每个修复示例生成一组编辑块,每个编辑块对应于易受攻击代码与其修复的代码之间抽象语法树差异中的特定代码段。每个编辑块包含一个编辑操作序列及其上下文。该序列可以包括以下编辑操作之一:
- Insert(Node u, Node p, int k):将节点u插入为父节点p的第kth个子节点。
- Delete(Node u, Node p, int k):删除父节点p的第kth个子节点u。
- Update(Node u, Value v):将节点u的旧值更新为新值v。
- Move(Node u, Node p, int k):移动节点u,使其成为父节点p的第kth个子节点。注意,u的所有子节点也会随之移动,因此这会移动整个子树。
对于每个编辑操作序列,VuRLE还会识别其上下文。为了识别该上下文,VuRLE使用GumTree提取在易受攻击的和已修复的抽象语法树中均出现且与编辑操作所影响的节点相关的抽象语法树子树。该子树是最大的公共子树,其每个叶节点均为SimpleName类型的节点,用于指定在编辑操作序列中使用的变量。我们利用GumTree的getParents方法来找到此子树。

为了说明上述情况,请参见图2。它展示了易受攻击的代码段及其对应的修复的代码段的抽象语法树。对这两个抽象语法树进行抽象语法树差异分析,生成一个编辑操作序列,该序列导致从V12到V17的节点被删除,并将R12到R21的节点插入到以V3为根节点的子树中。同时生成一个上下文,对应于灰色高亮显示的公共抽象语法树子树。
3.2 编辑组生成
VuRLE通过两个步骤生成编辑组:(1)编辑图构建;(2)编辑块聚类。我们将在下文详细描述这两个步骤。
编辑图构建
VuRLE创建一个图,其节点为上一步提取的编辑块。该图中的边连接相似的编辑块。当且仅当两个编辑块的编辑操作相似时,它们被视为相似。为了检查这种相似性,VuRLE从它们的编辑操作序列中提取最长公共子串(LCS)[11]。如果该LCS的长度大于某个阈值TSim,则认为这两个编辑块相似。每条边还通过对应LCS长度的倒数进行加权。该权重表示两个编辑块之间的距离。我们将两个编辑块e1和e2之间的距离记为dist(e1, e2)。
编辑块聚类
给定一个编辑图,VuRLE首先从中提取连通分量[12]。对于每个连通分量,VuRLE对其中出现的编辑块进行聚类。
为了在连通分量(CC)中对编辑块进行聚类,VuRLE采用了一种受DBSCAN启发的聚类算法。该算法接收两个参数:ε(最大聚类半径)和ρ(最小聚类大小)。基于这两个参数,VuRLE返回以下编辑组(EGS):
$$ EGS(CC) = {N_ε(e_i) | e_i ∈ CC ∧ |N_ε(e_i)| ≥ ρ} $$
在上述方程中,$N_ε(e_i)$表示CC中与$e_i$的距离不超过ε的一组编辑块。形式化定义如下:
$$ N_ε(e_i) = {e_j ∈ CC | dist(e_i, e_j) ≤ ε} $$
值ρ被设置为2,以避免生成仅包含一个编辑块的组。值ε通过遵循Kreutzer等人的代码聚类方法[14]确定。他们的启发式方法在其实验中已被证明效果良好。具体步骤如下:
1. 给定一个编辑图,VuRLE首先计算每个相连的编辑块之间的距离。在编辑图中未连接的两个编辑块之间的距离为无限距离。
2. VuRLE然后将这些距离按升序排列。设〈d1, d2,…, dn〉为这些距离的有序序列。
3. VuRLE最后通过在有序序列中找到两个连续距离d〈j+1〉和d〈j〉之间的最大间隔来确定ε的值。形式上,ε被设置为ε= d〈j∗〉,其中j∗= argmax1≤j≤n(d〈j+1〉−d〈j〉)。
为了说明上述过程,图3展示了两个连通分量(CCs),{E1, E2, E3, E5, E6}和{E0, E7}。VuRLE首先将距离排序为[0.12, 0.14, 0.17, 0.25]。然后计算连续值之间的最大间隔距离,并确定一个合适的ε值,即0.17。基于ε= 0.17和ρ= 2,VuRLE为第一个CC创建了两组编辑块:{E1,E2, E3}和{E5, E6}。对于第二个CC,未生成任何编辑块。
3.3 模板生成
对于每个编辑组,VuRLE会识别其中在编辑图中为相邻节点的编辑块对。对于每一对编辑对,它会创建一个修复模板。修复模板包含一个编辑模式(指定一系列转换性编辑)和一个上下文模式(指明应在哪里应用这些编辑)。
为了从一对编辑块创建编辑模式,VuRLE会比较这两个编辑块的编辑操作序列,并从中提取最长公共子串(LCS),该LCS即为编辑模式。
为了从一对编辑块创建上下文模式,VuRLE会处理每个编辑块的上下文。每个上下文都是一个子树。给定一对编辑块上下文(即一对抽象语法树子树ST1和ST2),VuRLE按以下步骤进行:
1. VuRLE对ST1和ST2执行前序遍历。
2. 对于每个子树,它从子树的根节点到其每个叶节点提取一个有序路径集。这两个有序路径集PS1和PS2分别表示ST1和ST2的上下文。我们将每条这样的路径称为一个具体上下文序列。
3. VuRLE随后比较PS1和PS2的对应元素。对于每一对路径,如果它们共享长度为TSim的最长公共子串(LCS),则使用该LCS表示这两条路径,并将这些路径从PS1和PS2中删除。我们将此LCS称为一个抽象上下文序列。
4. VuRLE将剩余的具体序列和已识别的抽象序列用作上下文模式。
最后一步,对于每个模板,VuRLE将所有具体的标识符类型和名称替换为占位符。同一标识符类型或名称的所有出现都将被相同的占位符替换。

图4说明了VuRLE如何通过比较两个上下文生成上下文模式。VuRLE对上下文1和上下文2的AST子树进行前序遍历,分别为每个上下文生成一个有序路径集。在比较这两个集合后,VuRLE找到以灰色高亮显示的匹配路径。对于每一对类型为简单名称或简单类型的匹配节点,VuRLE为其创建占位符。共有五对节点满足此条件,由虚线表示。因此,VuRLE从中创建了五个占位符,分别命名为$V0、$V1、$V2、$T0和$M0。
4 修复阶段:修复易受攻击的应用程序
在此阶段,VuRLE使用学习阶段生成的修复模板来检测输入代码是否存在漏洞,并同时应用适当的编辑以修复该漏洞。本阶段涉及的两个步骤(编辑组选择和模板选择)将在下方详细介绍。这些步骤将被迭代执行,直到VuRLE无法再检测到任何漏洞为止。
4.1 编辑组选择
为了检测输入代码是否易受攻击,VuRLE需要找到匹配得分最高的编辑组。VuRLE将输入代码(IC)与每个编辑组(EG)进行比较,并按如下方式计算匹配得分:
$$ S_{matching}(IC, EG) = ∑ {T ∈ templates(EG)} S {matching}(IC, T) $$
在上述方程中,templates(EG)是对应于编辑组EG的模板集合,而$S_{matching}(IC, T)$是模板T与输入代码之间的匹配得分。VuRLE计算模板T与输入代码IC之间的匹配得分如下:
1. VuRLE首先生成输入代码的抽象语法树。
2. VuRLE对该抽象语法树执行前序遍历,以生成一个有序路径集。每条路径是从抽象语法树的根节点到其某个叶节点的一系列抽象语法树节点。我们将此表示为IP。
3. VuRLE将IP与模板T的上下文进行比较。如果T中的序列能够与IP中的序列匹配,则返回匹配节点的数量作为匹配得分。抽象序列需要完全匹配,而具体序列只需部分匹配。否则,匹配得分为0。
4.2 模板选择
在最匹配的编辑组EG中,可能存在多个对应的模板(即templates(EG)包含多个成员)。在此最后一步中,我们需要选择最合适的模板。
为了找到一个合适的模板,VuRLE会根据匹配得分逐一尝试应用templates(EG)中的模板。要应用一个模板,VuRLE首先找到一个上下文与该模板上下文相匹配的代码段。然后将模板中的所有占位符替换为代码段上下文中出现的具体变量名和类型。接着,VuRLE将模板编辑操作序列中指定的每个转换性编辑应用于该代码段。
如果某个模板的应用导致了冗余代码,VuRLE将继续尝试下一个模板。当其中一个模板能够被应用且不产生冗余代码时,模板选择步骤结束。被应用模板的代码段被标记为易受攻击的,而应用模板中的转换性编辑后得到的结果代码即为相应的修复的代码。
5 评估
本节通过回答以下两个问题来评估VuRLE的性能:
研究问题1(漏洞检测) 。VuRLE在检测代码是否易受攻击方面的效果如何?
研究问题2(漏洞修复) 。VuRLE在修复已检测到的易受攻击的代码方面的效果如何?为什么某些易受攻击的代码无法被VuRLE修复?
以下部分首先描述我们实验的设置,然后介绍回答上述两个问题的实验结果。
5.1 实验设置
数据集 。我们从GitHub收集了48个用Java编写的应用程序¹,这些应用拥有超过400颗星。这些应用程序包括Android、网页、文字处理和多媒体应用。Android应用程序的大小范围为3–70MB,而其他应用程序的大小约为200MB。在这些应用程序中,我们通过手动分析每个应用程序仓库的提交来识别影响它们的漏洞。总共,我们发现了279个漏洞。这些漏洞属于表1中列出的几种易受攻击的类型。
表1. 我们数据集中漏洞的类型
| 漏洞类型 | 描述 |
|---|---|
| 未释放资源 | 未能在重新使用资源之前释放它[19]这会增加一个系统对拒绝服务(DoS)攻击的易感性 |
| 加密的漏洞 | 加密算法[4,17]使用不当或使用明文密码存储。它会增加系统的对选择明文攻击(CPA)、暴力破解攻击, etc. |
| 返未回检值查 | 忽略一个方法的返回值。可能导致意外的状态和程序逻辑,以及可能存在的权限提升漏洞 |
| 错误的错误处理处理 | 显示不适当的错误处理消息。它可能会导致隐私泄露,向潜在的攻击者泄露有用信息潜在的攻击者 |
| SSL漏洞 | 未检查的主机名或证书[6,10]。它会使系统容易受到窃听和中间人攻击[2] |
| SQL注入漏洞 | 未检查的SQL输入。它会使系统容易受到SQL注入攻击,允许攻击者注入或执行通过输入数据[16]的SQL命令 |
实验设计 。我们使用10折交叉验证来评估VuRLE的性能。首先,我们将数据分为10组(每组大约包含28个漏洞)。然后,将其中一组定义为测试组,其余9组作为训练组。测试组是修复阶段的输入,而训练组是学习阶段的输入。我们通过轮流选择不同的组作为测试组,重复该过程10次。我们通过将修复的代码与开发者提供的真实修复代码进行比较,手动检查修复结果。此外,我们将VuRLE与最先进的学习修复模板工具LASE[20]进行比较。在运行VuRLE时,默认将TSim设置为3。
¹ GitHub:https://github.com/
为了评估我们的方法的漏洞检测性能,我们使用精确率和召回率作为评估指标,其定义如下。
$$ Precision = \frac{TP}{TP + FP} $$
$$ Recall = \frac{TP}{TP + FN} $$
其中TP是正确检测到的漏洞数量,FP是错误检测到的漏洞数量,FN是我们的方法未检测到的漏洞数量。
为了评估我们方法的漏洞检测性能,我们使用成功率作为评估指标。成功率为可成功修复的正确检测到的漏洞所占的比例。
5.2 研究问题1:漏洞检测
为了回答这个问题,我们统计了VuRLE能够检测到的漏洞数量,并在整个数据集上计算了精确率和召回率。
表2. 检测结果:VuRLE与LASE对比
| 检测到的漏洞数量 | 精确率 | 召回率 | |
|---|---|---|---|
| VuRLE | 183 | 64.67% | 65.59% |
| LASE | 58 | 52.73% | 20.79% |
表2显示了VuRLE和LASE检测到的漏洞数量、精确率和召回率。VuRLE成功检测出279个漏洞中的183个,达到了65.59%的召回率。而LASE只能检测出279个漏洞中的58个,召回率仅为20.79%。因此,与LASE相比,VuRLE多检测出了215.52%的漏洞。在精确率方面,VuRLE比LASE提高了22.64%。这意味着VuRLE产生的误报比例少于LASE。
5.3 研究问题2: 漏洞修复
为了回答该研究问题,我们调查了能够成功修复的漏洞数量。我们还研究了VuRLE如何修复一些LASE无法修复的缺陷。我们也讨论了VuRLE无法修复某些缺陷的一些原因。
表3. 漏洞修复:VuRLE和LASE
| 已修复漏洞数量 | 成功率 | |
|---|---|---|
| VuRLE | 101 | 55.19% |
| LASE | 21 | 36.21% |
表格3展示了VuRLE和LASE的成功率。VuRLE的成功率远高于LASE的成功率。VuRLE成功地修复了101个漏洞(55.19%),而LASE仅能修复21个漏洞,成功率为36.21%。因此,与LASE相比,VuRLE可以多修复380.95%的漏洞。在成功率方面,比LASE提高了52.42%。
图5提供了一个由LASE和VuRLE在同一输入代码上生成的修复示例。该示例中的代码包含一个漏洞,允许任何主机名通过验证。LASE生成了一个过于泛化的修复模板,该模板仅包含对setHostnameVerifier的调用。它生成此类模板的原因是,每个修复示例都在定义了setHostNameVerifier方法之后调用了setDefaultHostnameVerifier方法,但验证器方法本身的定义各不相同。另一方面,VuRLE生成了两个可以修复此漏洞的修复模板。其中一个模板用于修改verify方法,另一个则是调用setDefaultHostnameVerifier方法。
在检测到的183个漏洞中,VuRLE无法修复其中一部分。我们讨论其主要原因如下:
占位符解析失败 。在将占位符替换为具体标识符名称和类型时,VuRLE可能会使用错误的类型或名称填充占位符。例如,所需的具体类型是“double”,但推断出的具体类型是“int”。此外,由于在匹配上下文中未找到某些占位符,VuRLE可能无法将其具体化。
修复示例缺乏 。在我们的数据集中,某些漏洞,例如密码学误用和未检查的返回值,具有许多示例。因此,可以为这类漏洞生成更全面的修复模板集合。然而,某些漏洞,例如SSL套接字漏洞,仅有少量示例。因此,VuRLE无法推导出用于修复此类漏洞的全面修复模板集合。
部分修复 。在某些情况下,VuRLE只能生成部分修复。这可能是由于缺乏类似修复,或因为VuRLE仅提取了部分修复模式所致。
6 相关工作
本节介绍有关漏洞检测和自动漏洞修复的相关工作。
漏洞检测
大量关于检测软件漏洞的研究工作。TaintScope[26]是一种校验和感知模糊测试工具,能够检测程序中的校验和检查点以及程序输入中的校验和字段。此外,它还能自动生成通过校验和检查的有效输入。TaintScope能够检测缓冲区溢出、整数溢出、双重释放、空指针解引用和无限循环。
Sotirov[25]提出了一种静态源代码分析技术,用于检测缓冲区溢出、格式化字符串漏洞和整数溢出等漏洞。他们对漏洞进行分类,并为每种类型的漏洞提取常见模式。Mohammadi等人[21]专注于跨站脚本(XSS)漏洞的检测。他们不分析源代码,而是检测由不正确的编码导致的不可信输入数据所引发的跨站脚本(XSS)漏洞。
Medeiros等人[18]提出一种组合方法来检测Web应用程序中的漏洞。他们结合了污点分析和静态分析。污点分析用于收集关于漏洞的人工编码知识。此外,他们生成多个分类器来标记易受攻击的数据。这些分类器实现了较低的误报率。Fu等人[9]提出一种静态分析方法,在编译时检测SQL注入漏洞。他们的方法对使用ASP.NET框架编写的Web应用程序进行符号执行,并在能够生成匹配特定攻击模式的输入字符串时检测出SQL注入漏洞。Kals等人[13]提出SecuBat,一种可检测Web应用程序中漏洞的扫描器。SecuBat提供了一个框架,允许用户添加另一个可检测特定漏洞的过程。
类似于SecuBat,Doupé等人[3]提出一种感知Web应用状态的Web漏洞扫描器。它推断Web应用程序的状态机通过观察用户操作对Web应用程序输出的影响。该状态机被遍历来发现漏洞。巴尔杜齐等人[1]提出一种自动技术,用于发现Web应用程序中的HTTP参数污染漏洞。它通过将编码后的参数注入已知参数之一来自动发起攻击,并在攻击成功时发现漏洞。
与上述工作类似,我们的工作也用于检测漏洞。然而,那些工作专门用于检测特定类型的漏洞。相比之下,在能够提供相应漏洞修复示例的条件下,我们的工作可以检测多种类型的漏洞。
漏洞修复
为了自动修复漏洞,通常需要为特定漏洞生成一个修复模式。FixMeUp[24]被提出用于修复Web应用程序中的访问控制缺陷。它能够自动计算过程间访问控制模板(ACT),该模板包含低级策略规范和程序转换模板。FixMeUp利用ACT识别存在缺陷的访问控制逻辑并执行修复。CDRep[17]用于检测安卓应用程序中的密码学误用,并通过应用人工制作的修复模板自动修复漏洞。它使用了七个修复模板,每个模板对应一种特定类型的密码学误用。
余等人[27]提出了一种在Web应用程序中净化用户输入的方法。给定一个手动定义的输入模式及其对应的攻击模式,该方法检查输入是否具有与输入模式相同的模式,并判断该输入是否能免受相应攻击。如果不能,则将恶意输入转换为良性输入。斯米尔诺夫和邱[23]提出了DIRA,这是一种可以转换程序源代码以防御缓冲区溢出攻击的工具。在运行时,经过转换的程序能够检测、识别并修复自身,而无需终止执行。修复通过将程序状态恢复到攻击发生之前的状态来实现,这是通过手动预定义的过程完成的。西迪罗格卢和克里奥米蒂斯[22]提出了一种自动化技术,使用人工制作的代码转换启发式方法修复缓冲区溢出漏洞,并在沙箱环境中测试修复效果。林等人[15]提出了AutoPAG,一种可自动修复越界漏洞的工具。它通过使用预定义规则为特定类型的越界漏洞生成程序补丁。
与上述工作不同,我们的工作旨在通过从示例中学习来自动修复各种类型的漏洞。与我们工作最接近的是LASE[20],它从修复示例中生成修复模板。与我们的方法不同,它无法从修复示例中生成多个修复模板,而这些示例可能包含针对不同漏洞的修复。此外,当给定一个修复示例时,它也无法生成多个编辑序列,每个编辑序列对应示例中的某个代码段。
7 结论与未来工作
总之,我们提出了一种名为VuRLE的工具,用于自动检测和修复漏洞。该工具通过从已知的修复示例中学习修复模板,并将这些模板应用于输入代码来实现漏洞的检测与修复。给定修复示例后,VuRLE会提取编辑块,并将相似的编辑块聚类为一个编辑组。随后,从每个编辑组中学习多个修复模板。为了检测和修复漏洞,VuRLE会查找与输入代码匹配度最高的编辑组。在该组中,它按匹配得分的顺序依次应用修复模板,直到未发现冗余代码(此时即检测并修复了漏洞),或直到该编辑组中的所有修复模板均已应用(此时认为未检测到漏洞)。
VuRLE重复此检测和修复过程,直至不再发现新的漏洞。
我们在48个应用程序中进行了实验,共包含279个真实世界漏洞,并采用10折交叉验证来评估VuRLE。平均而言,VuRLE能够自动检测出183个(65.59%)漏洞,并修复其中的101个(55.19%)。相比之下,最先进的方法LASE仅能检测出58个(20.79%)漏洞,并修复其中的21个(36.21%)。因此,与LASE相比,VuRLE分别可以多检测和修复215.52%和380.95%的漏洞。
未来,我们计划使用更多用不同编程语言编写的应用程序和漏洞来进一步评估VuRLE。我们还计划进一步提升VuRLE的有效性,使其能够检测和修复更多的漏洞。此外,我们计划设计一种无需示例即可检测和修复漏洞的新方法。

















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









