



性能测试软件的引入(为啥要有性能测试软件?)
前面我们说了,要进行性能测试,无论是具体哪种,都需要测试人员为系统提供很高的并发数。假如我们的并发数比较小,比如10以内,我们可以用一个手指头控制一台手机,十个手指头同时按请求,这样就能模拟并发数为10的测试环境,但是实际业务中,比如淘宝双十一期间,同一时刻可能有千万级别的用户同时发起请求,请问这时候你还能用手机模拟吗?肯定不行,那你作为一个测试人员,老板给你布置任务,在软件上线之前,要你对系统进行百万并发量的压力测试,你该怎么办呢?答案就是用专业测试软件来模拟
本节我们就来学习如何用JMeter这款测试软件对系统进行性能测试
JMeter的安装与配置
-
首先我们先去官网把这软件下载下来,然后解压到本地
-
然后打开JMeter
-
打开方式有两种
-
一种是直接点击bat文件
-
另一种就是将JMeter的目录添加到环境变量中,然后直接在命令行中输入jmeter指令打开
-
-
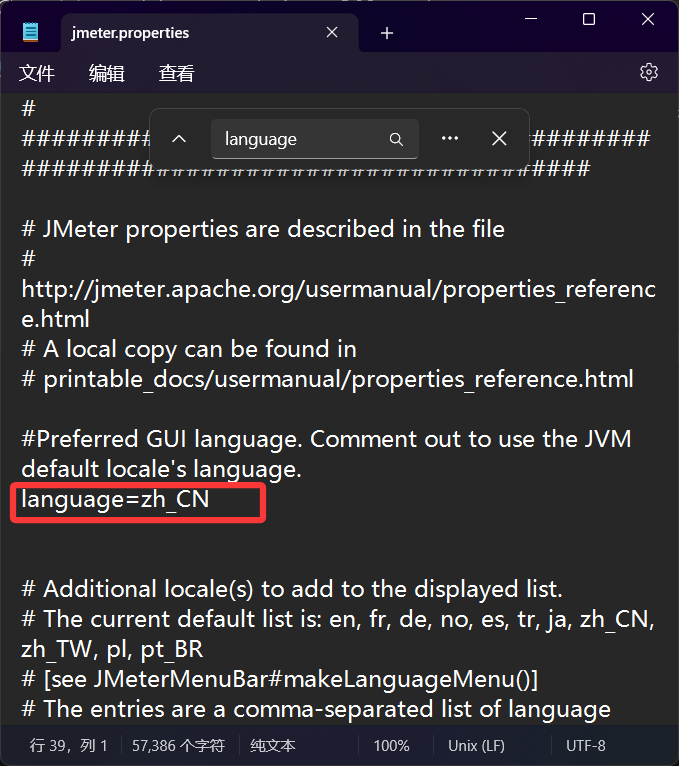
通过修改配置文件,将JMeter的默认字体修改为中文
JMeter使用基本流程
1. 首先我们先按照上面的做法打开JMeter
2. 然后添加一个线程组
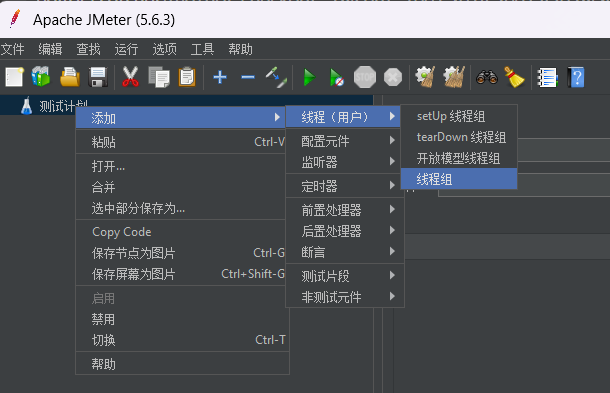
配置线程组的参数
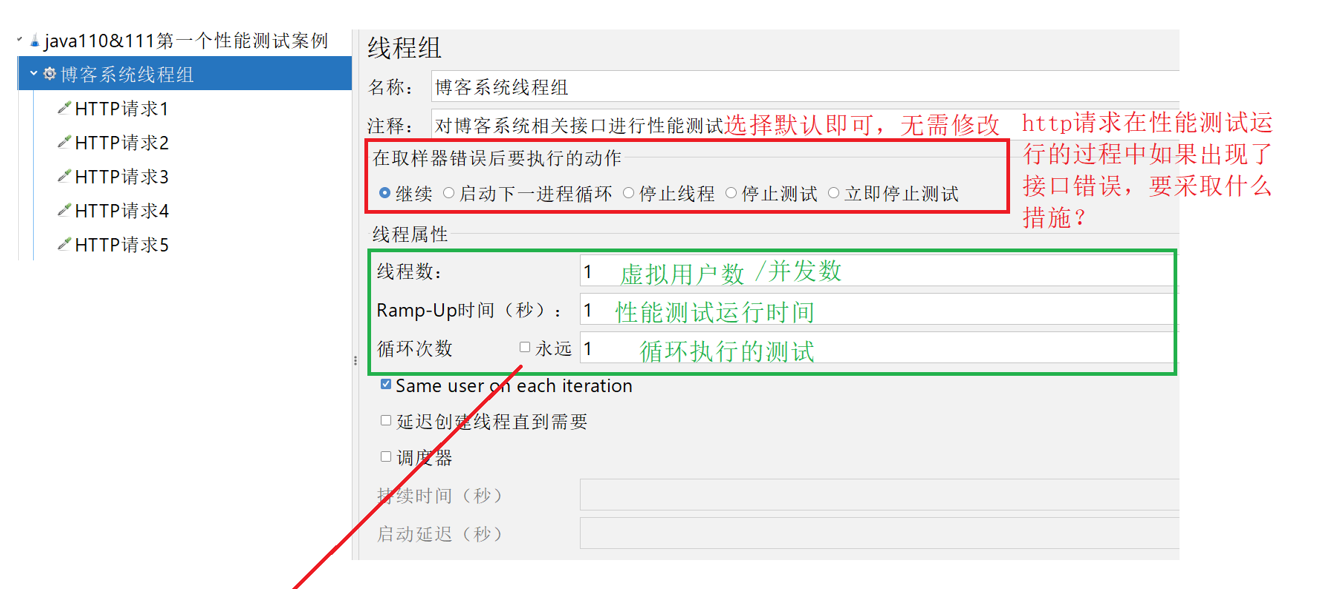
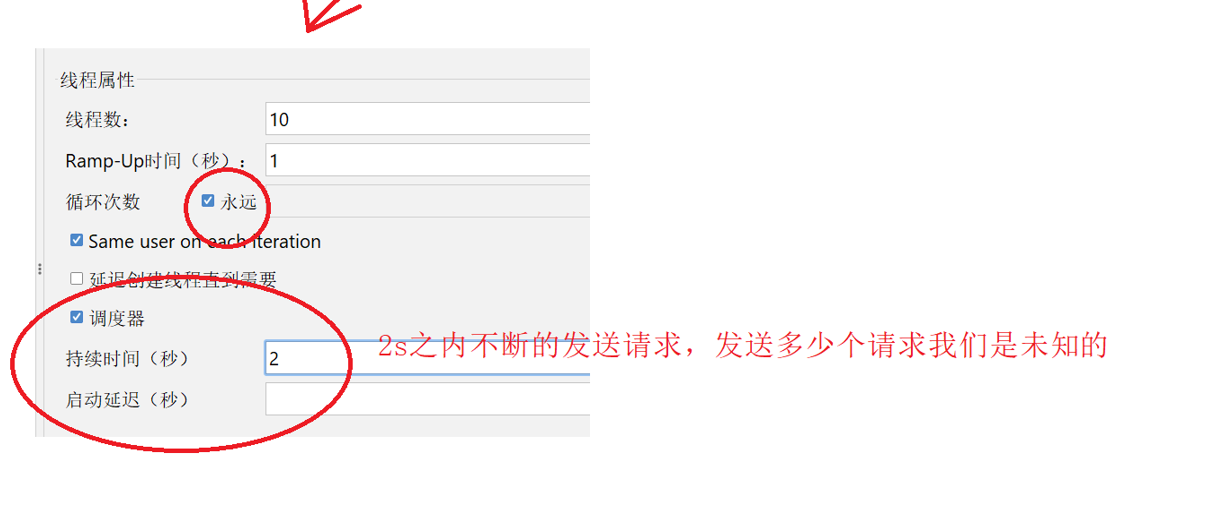
如果不想指定循环次数,就像让程序在给定时间内一直跑,就去配置调度器
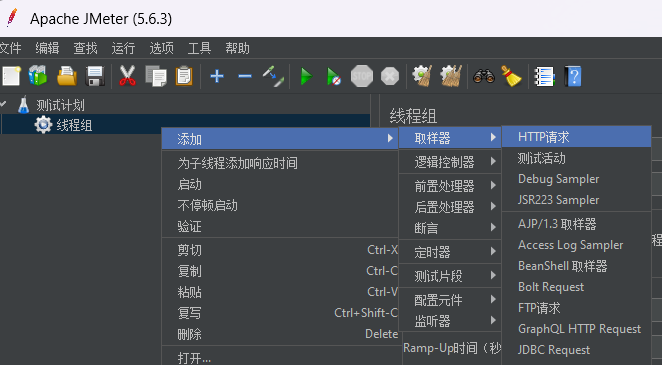
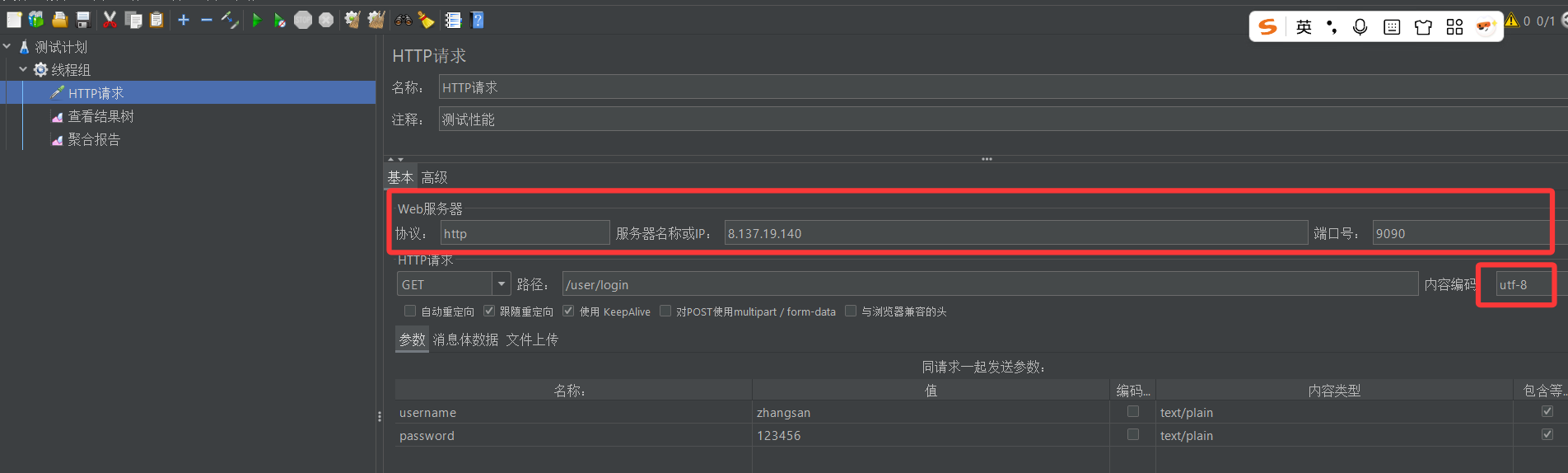
3. 在线程组下创建HTTP取样器
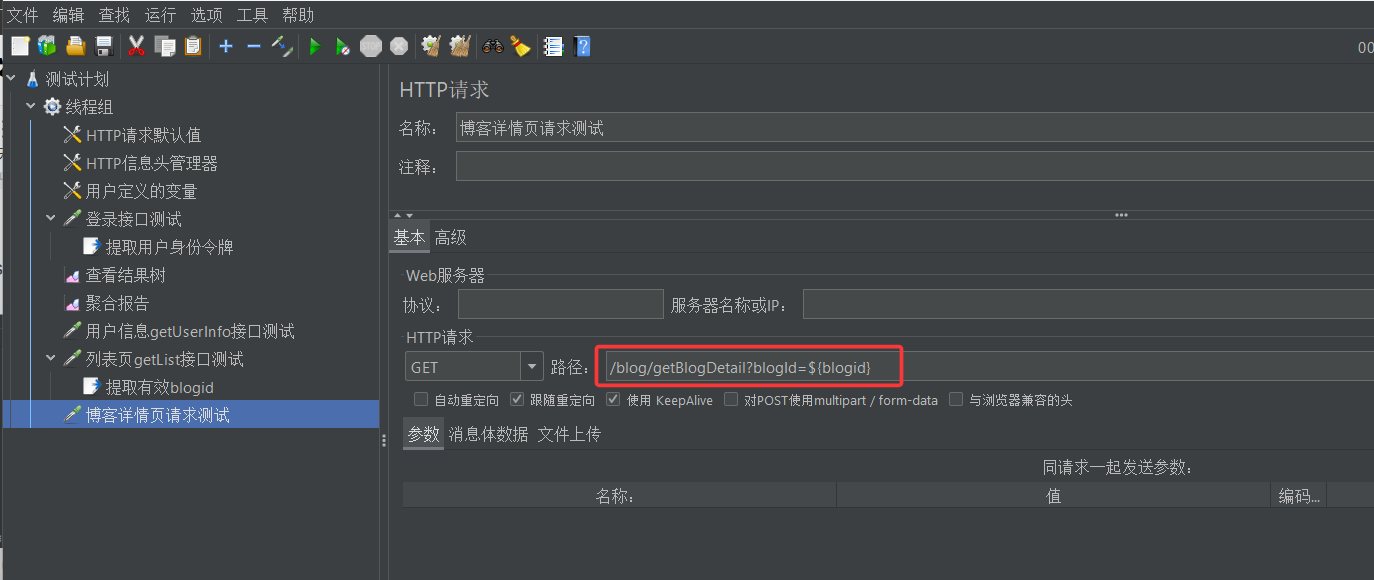
4. 填写HTTP请求的相关数据
我们此次测试的目的是检测登录接口的功能是否能够正常运行。因此我们要先找到登录接口的url以及套接字
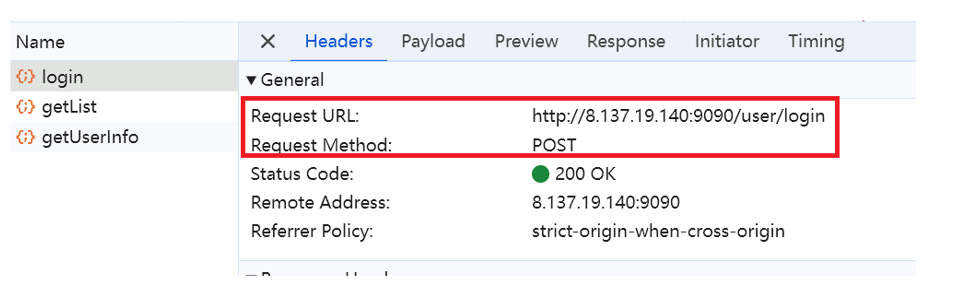
然后我们再将接口信息填入我们刚刚创建的HTTP取样器中
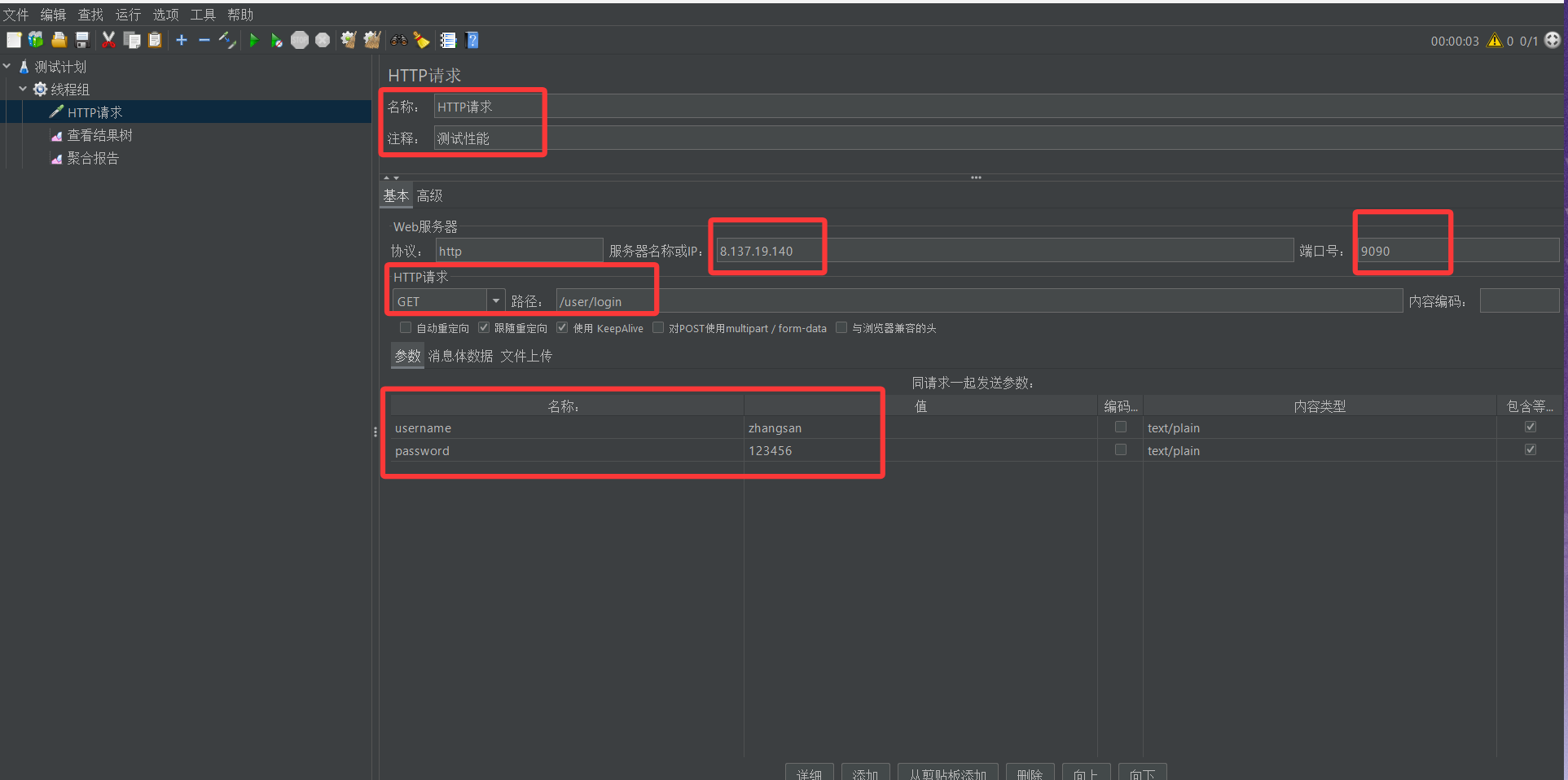
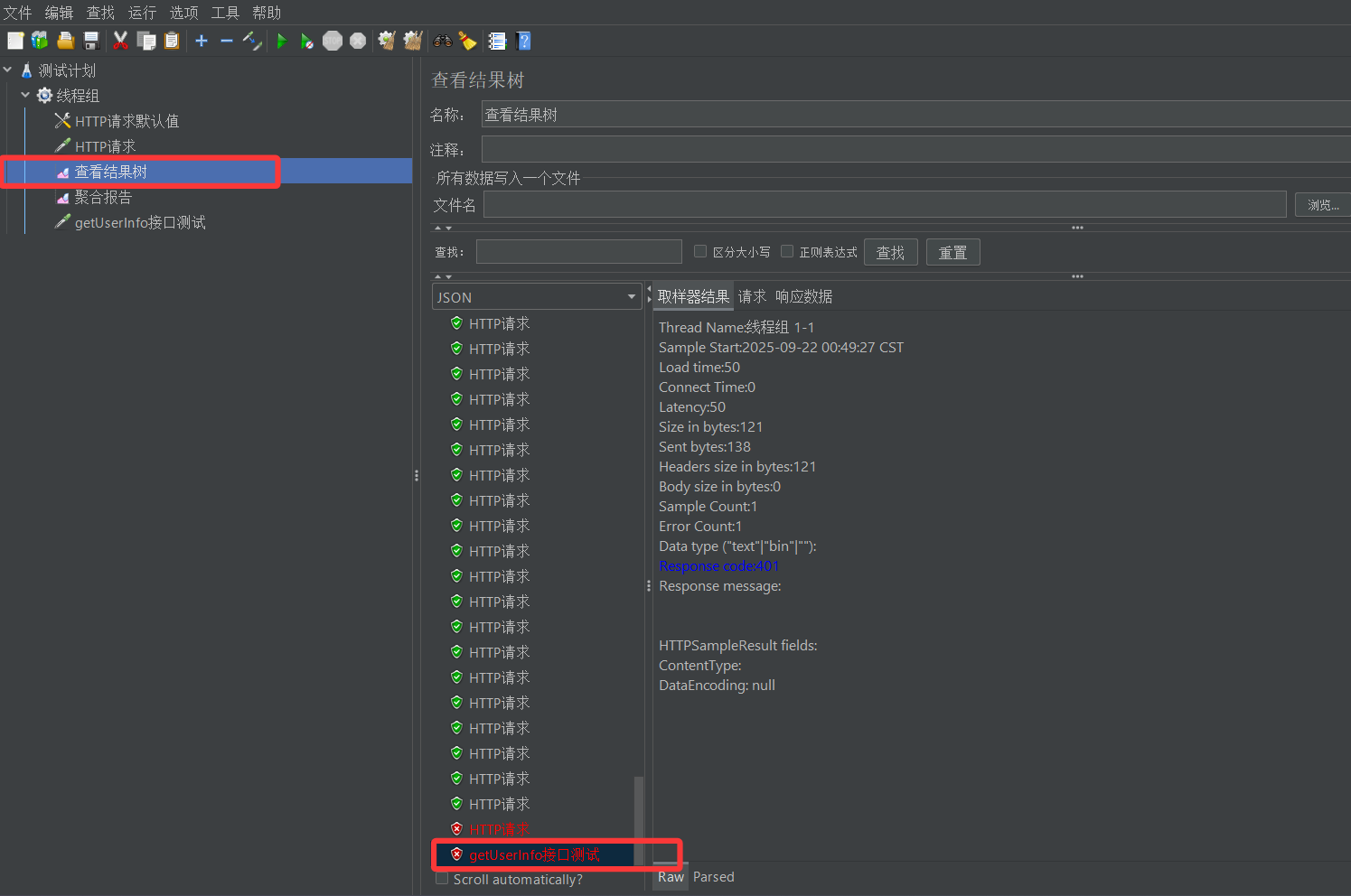
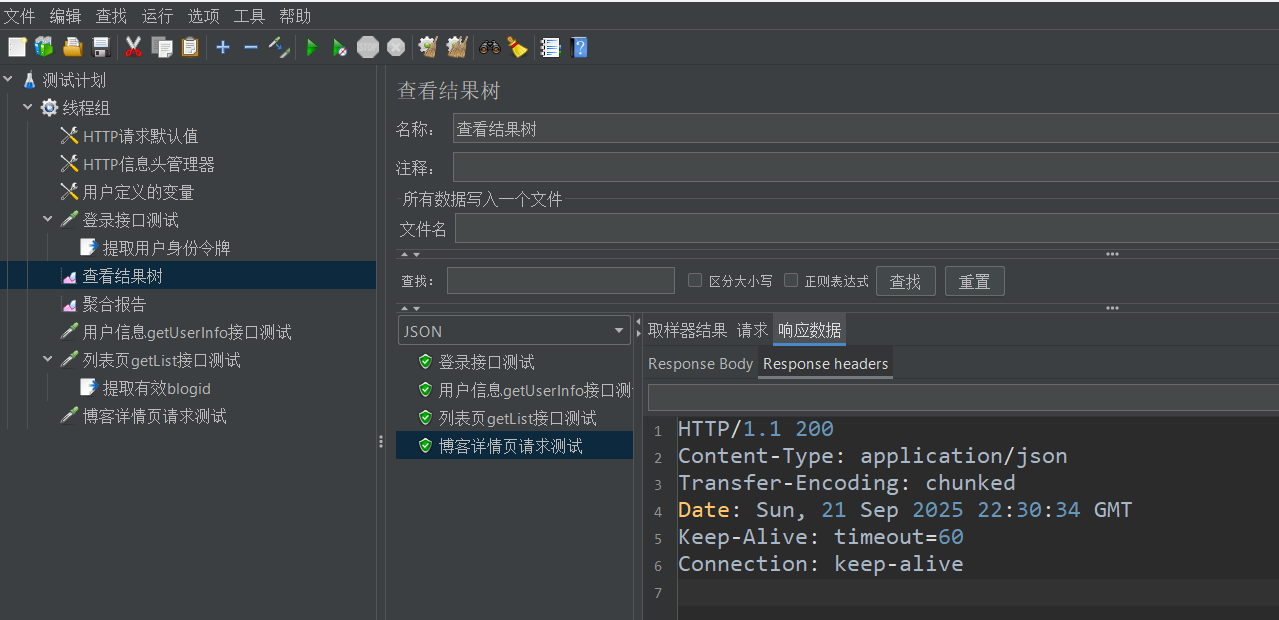
5. 在线程组下添加查看结果树监听器
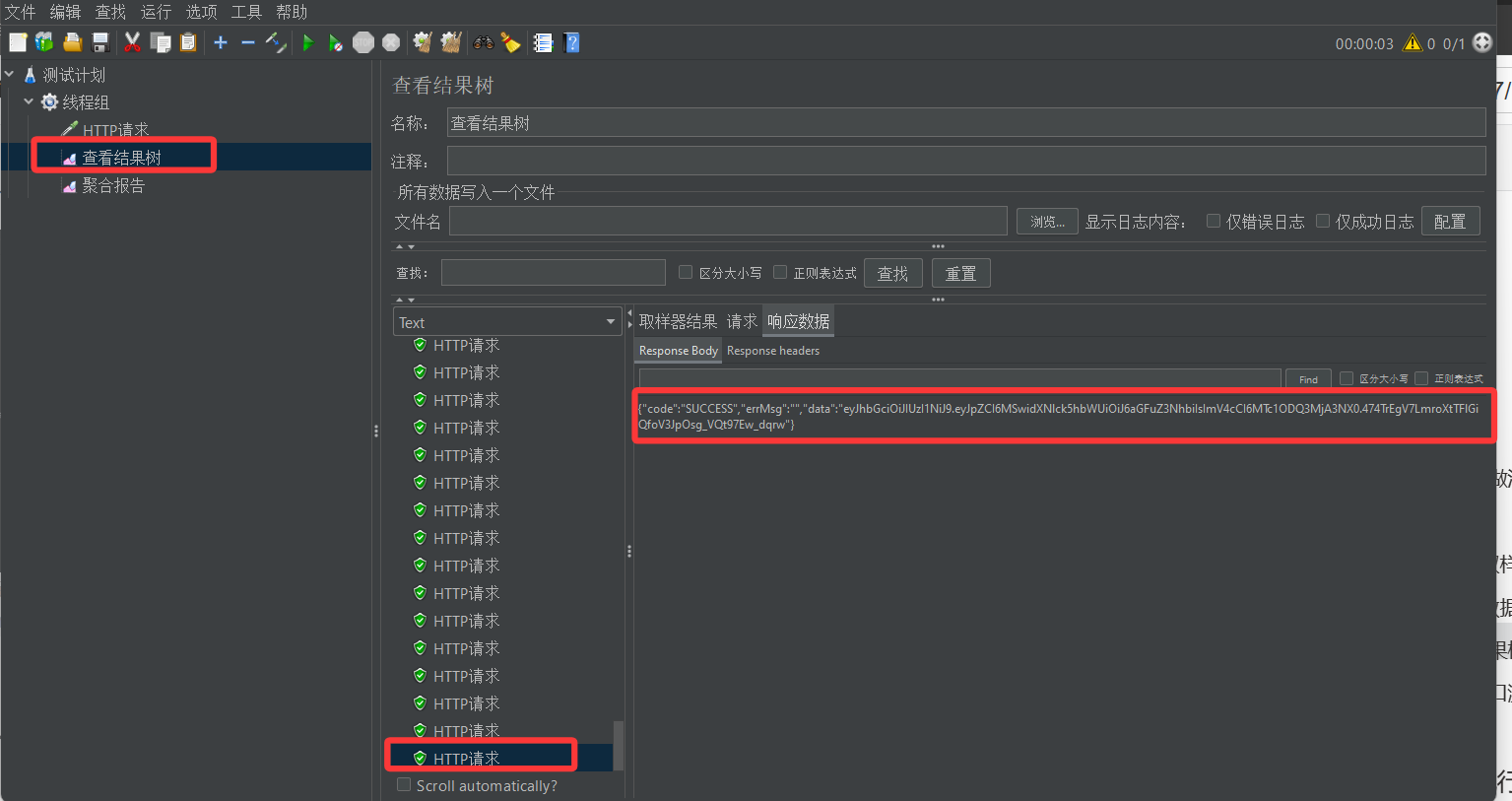
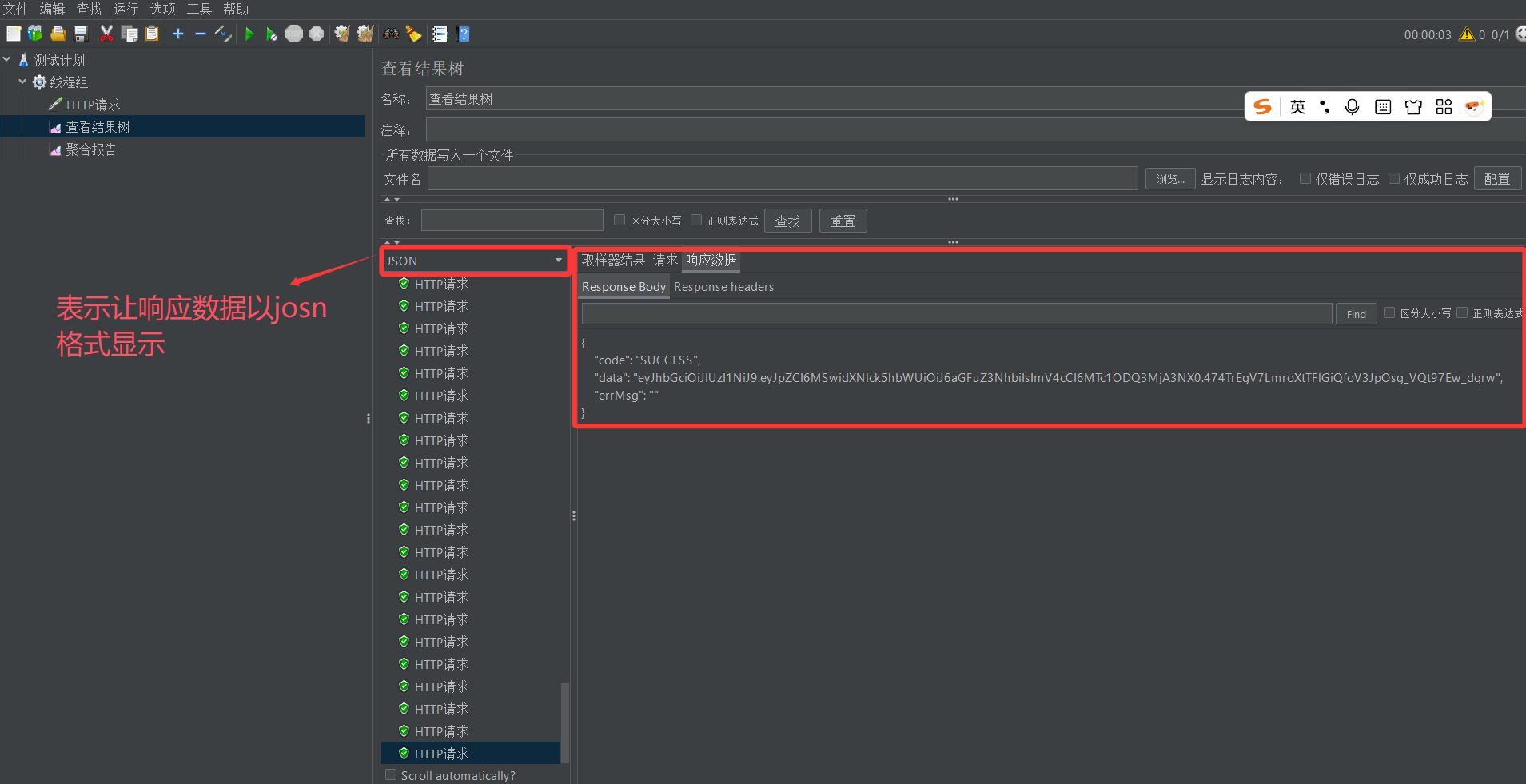
6. 点击启动按钮,查看接口测试结果
7. 查看聚合报告
如果我们前面测试发起的请求很多,在结果数中一个一个地看也比较麻烦,没法从整体上看测试结果,此时我们就可以通过查看聚合报告的方法来查看
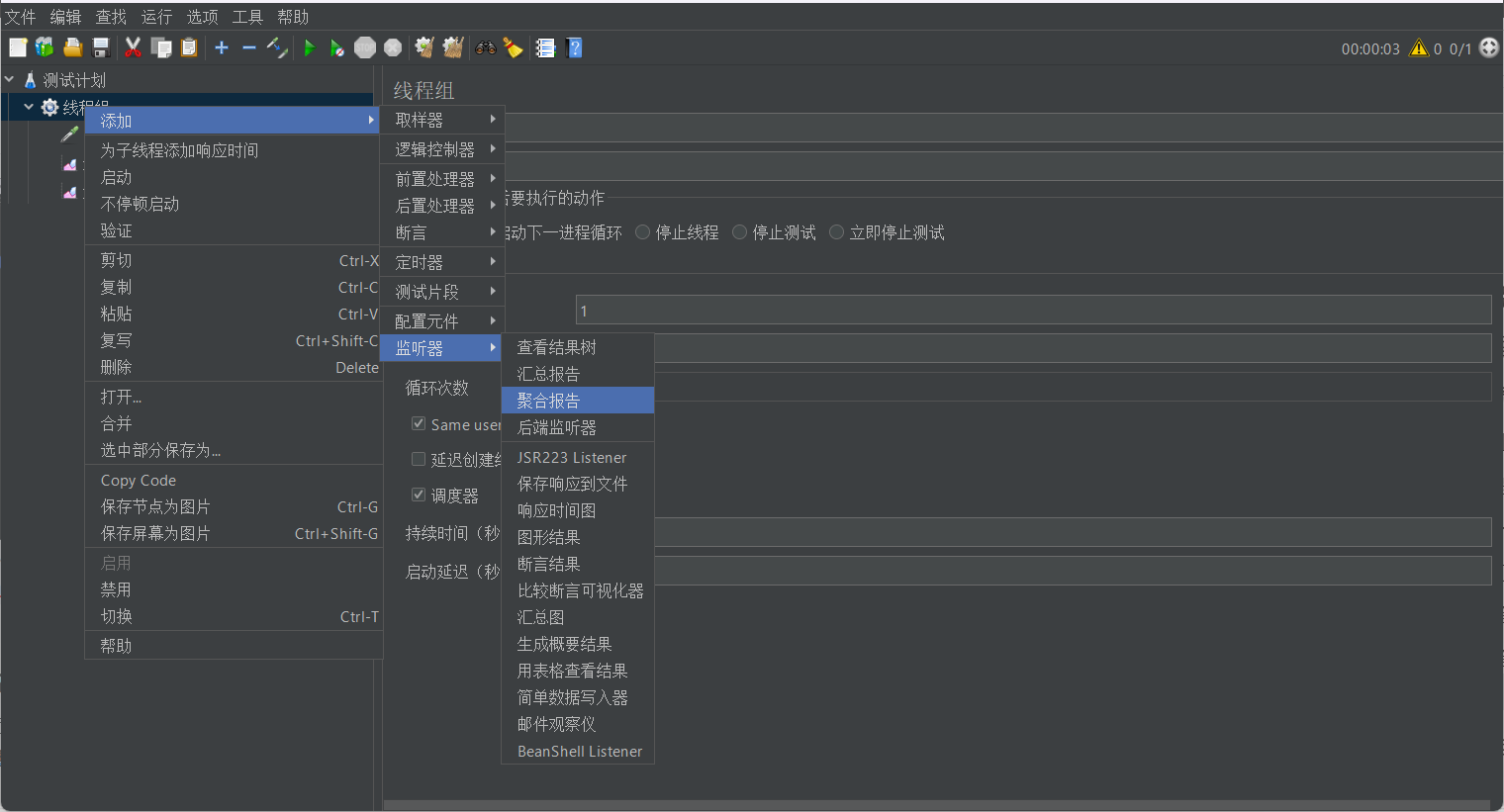
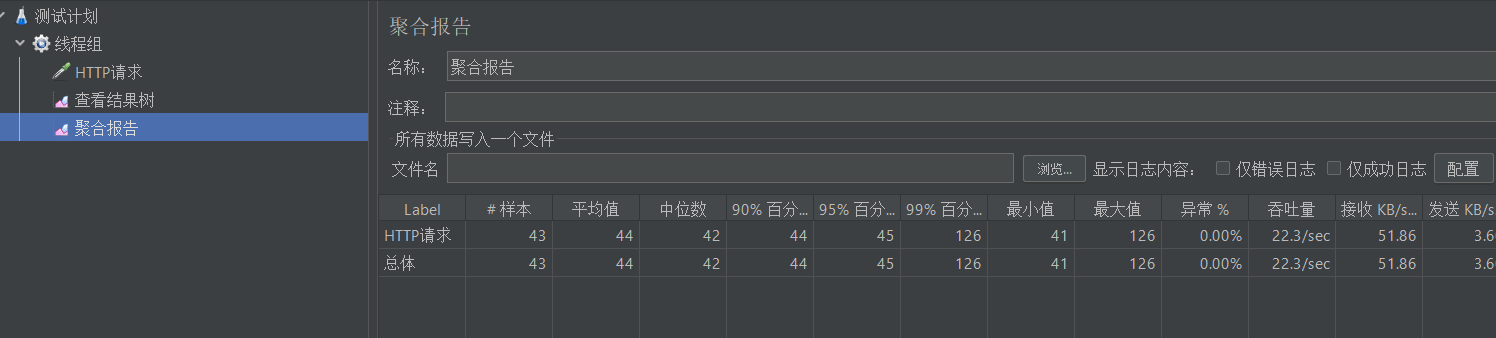
聚合报告中每一列属性分别是啥意思?这个我们在下一章的事务控制器小节中会详细介绍
JMeter重要组件
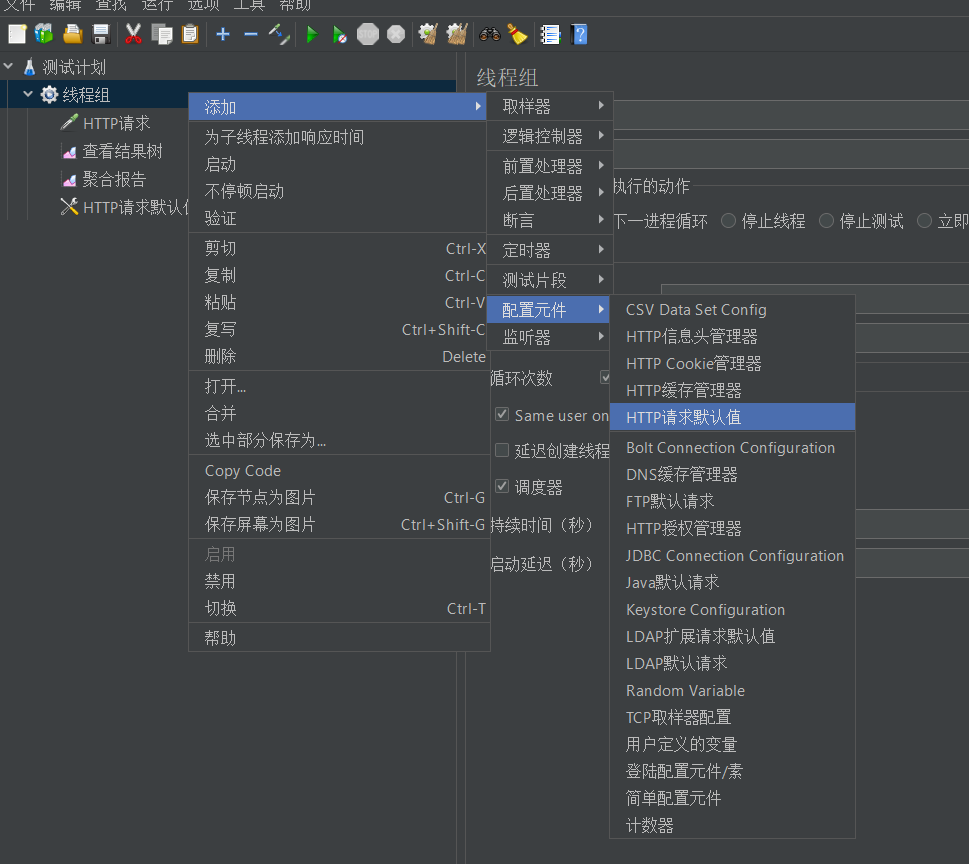
HTTP请求默认值
由于我们在测试一个网站的时候,往往需要测多个接口,那相应地就应该创建多个HTTP取样器,这么多HTTP取样器,其实它们很多配置是一样的。比如IP地址、端口号、协议等等
既然如此,那我们每创建一个新的取样器,就重复输入一次,这显然是低效的,为了高效创建取样器,我们就可以使用HTTP请求默认值这一组件,为HTTP取样器的一些选项创建缺省值,这样就省的我们每次都输入了。
下面是HTTP请求默认值的使用演示
首先在线程组目录下创建一个HTTP请求默认值的配置元件
然后进行一些选项的默认配置,保存即可
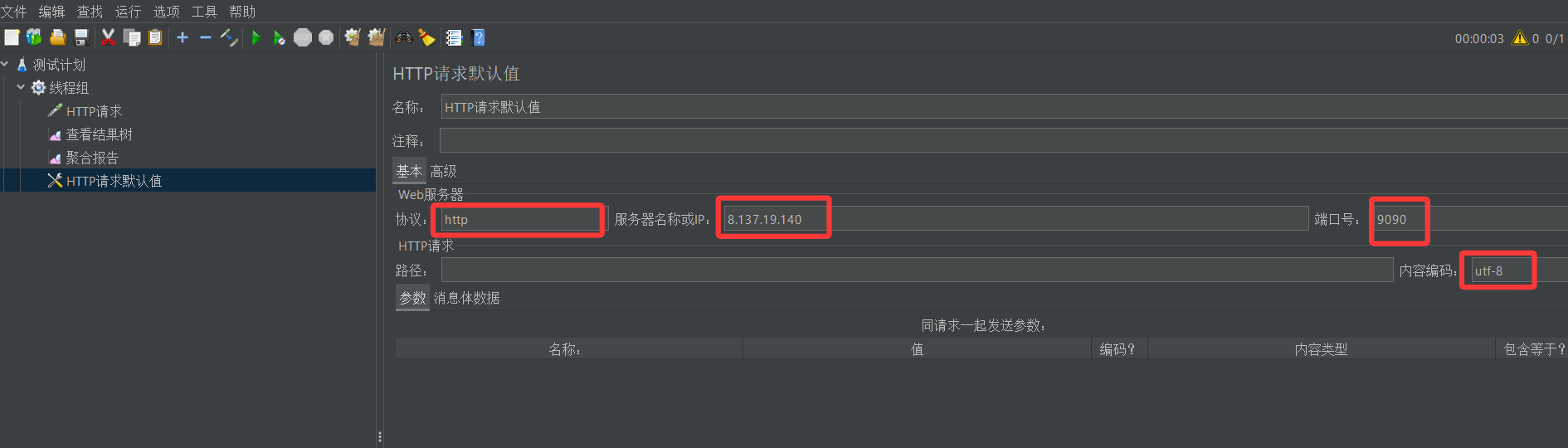
配置完成之后,下次我们再创建新的HTTP取样器时,里面默认配置过的选项就不用再填了,直接空着就行,测试照样正常进行(不信自己试试)
当然,如果你取样器里面写的值与默认值不一样,那就以取样器里面的值为准(和缺省的道理一样)
JMeter元件优先级
这个我们举个例子就很好理解。我们前面说了默认值组件,请看下面俩图,默认值组件放最下边和放最上边,效果一不一样呢?
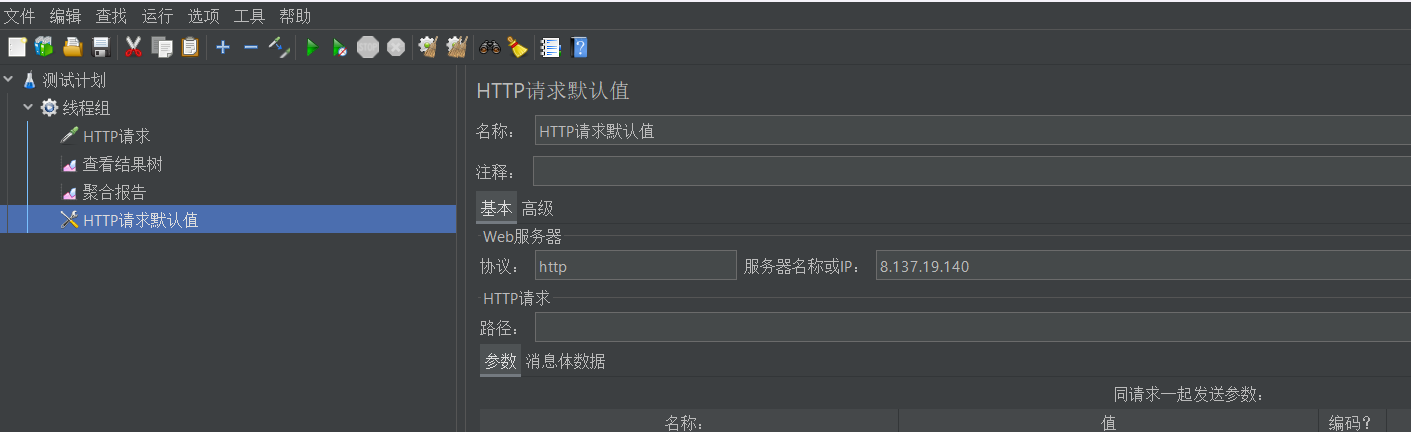
答案是效果一模一样。只要该默认值配置组件在线程组目录下,那它的作用域就是该线程组目录下的所有组件。你可以把一个线程组看做是一个main.cpp文件,一个组件就可以看做是一个函数,只要函数实现声明了,这函数具体实现放main函数前面或者后面,都行
总结来说,元件的优先级就是一个二叉树结构,在上面的例子中,默认值配置组件是线程组的子节点,那它的作用域就是其父节点的所有子节点(也就是它的所有兄弟节点)
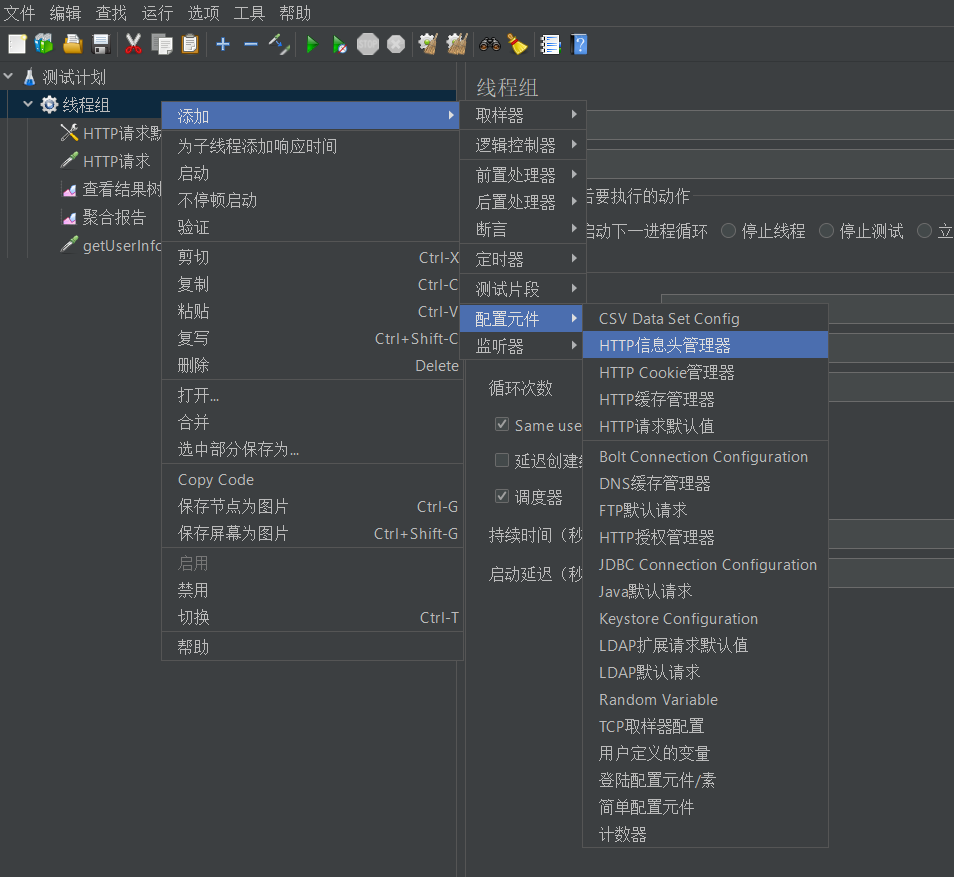
HTTP信息头管理器
我们可以通过HTTP信息头管理器给取样器发送的请求报头中添加一些字段
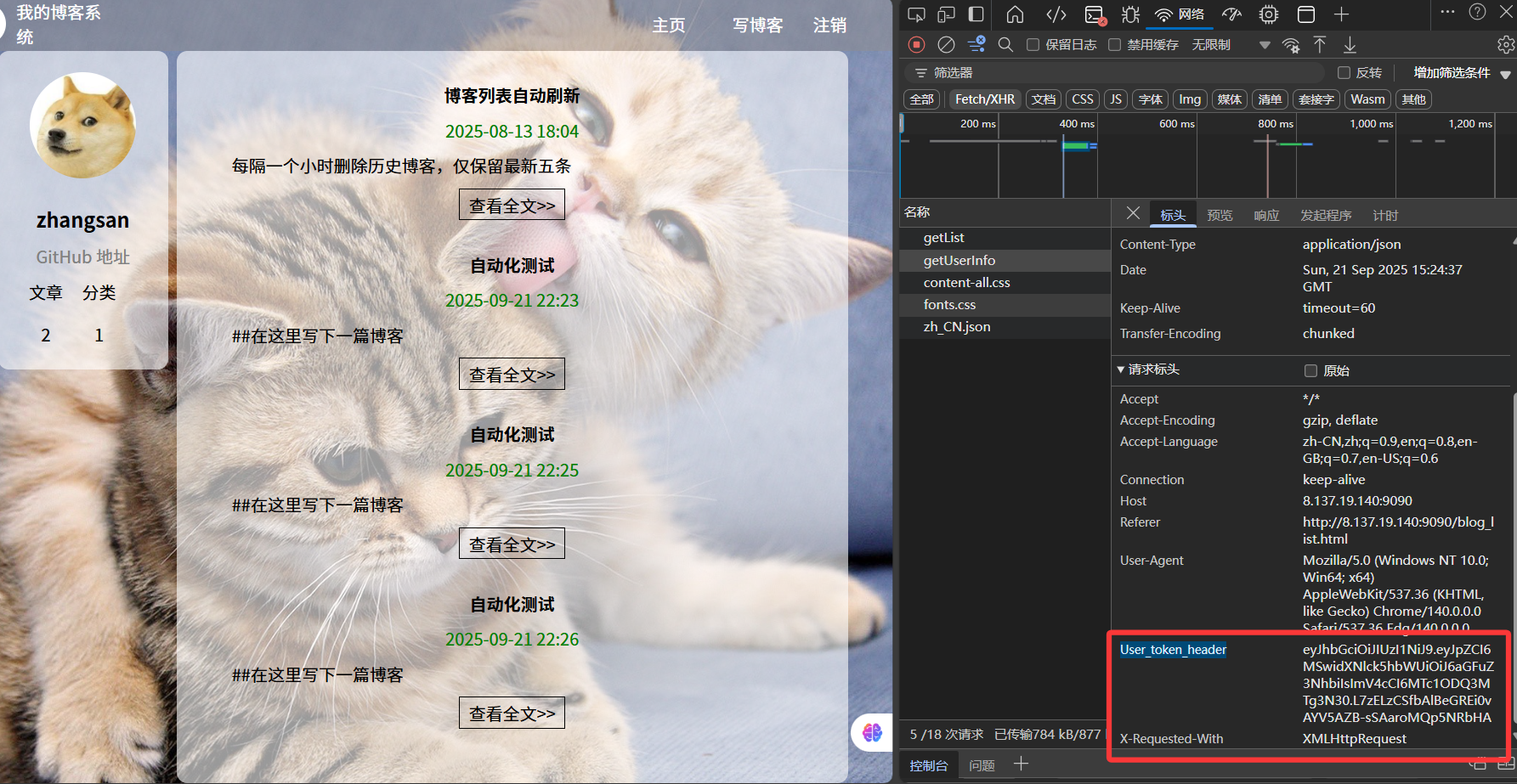
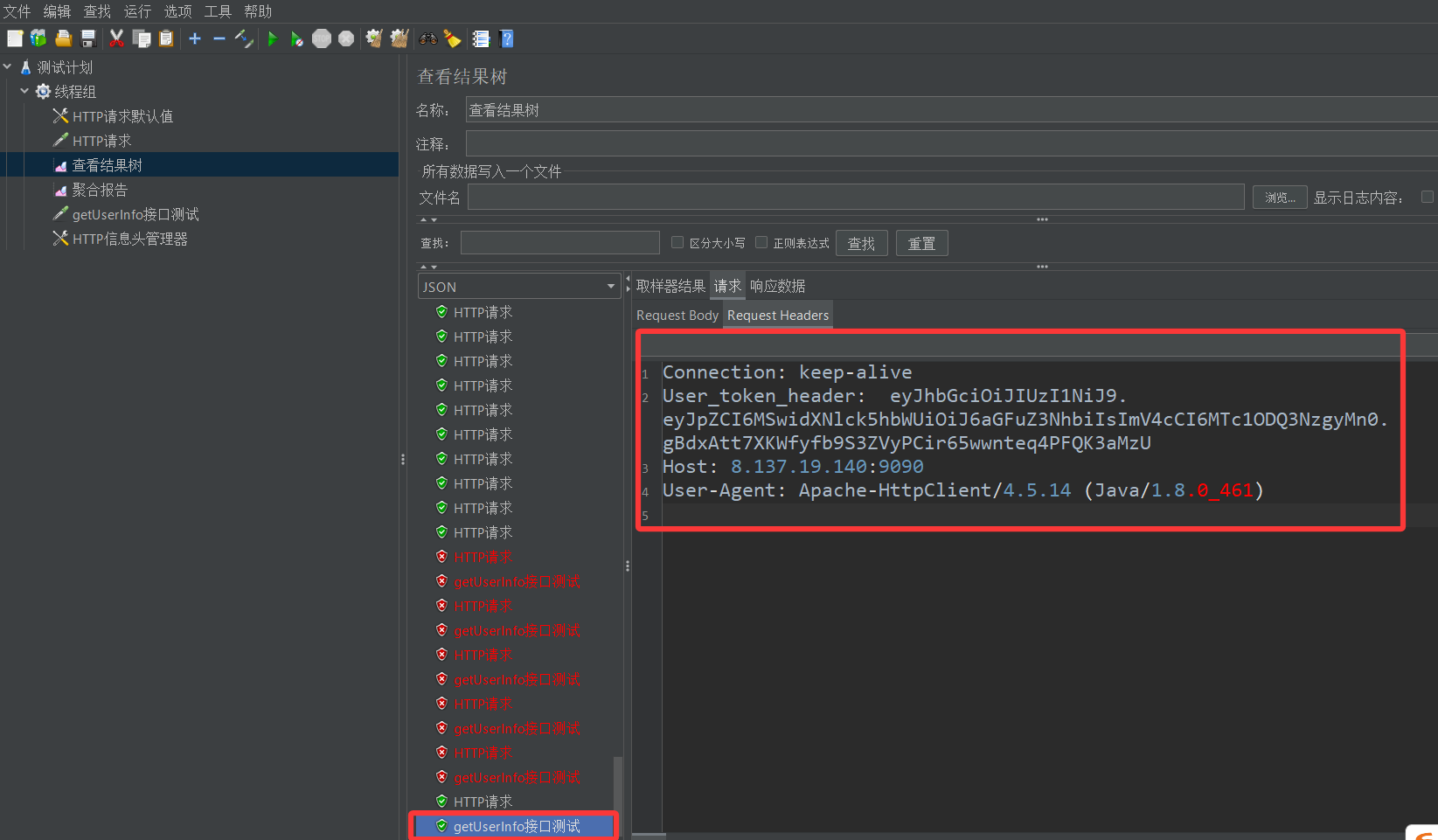
先看一个例子,下面我想测试一下博客主界面中getUserInfo这个接口,我首先通过web的开发者模式,查看一下这个接口的基本信息
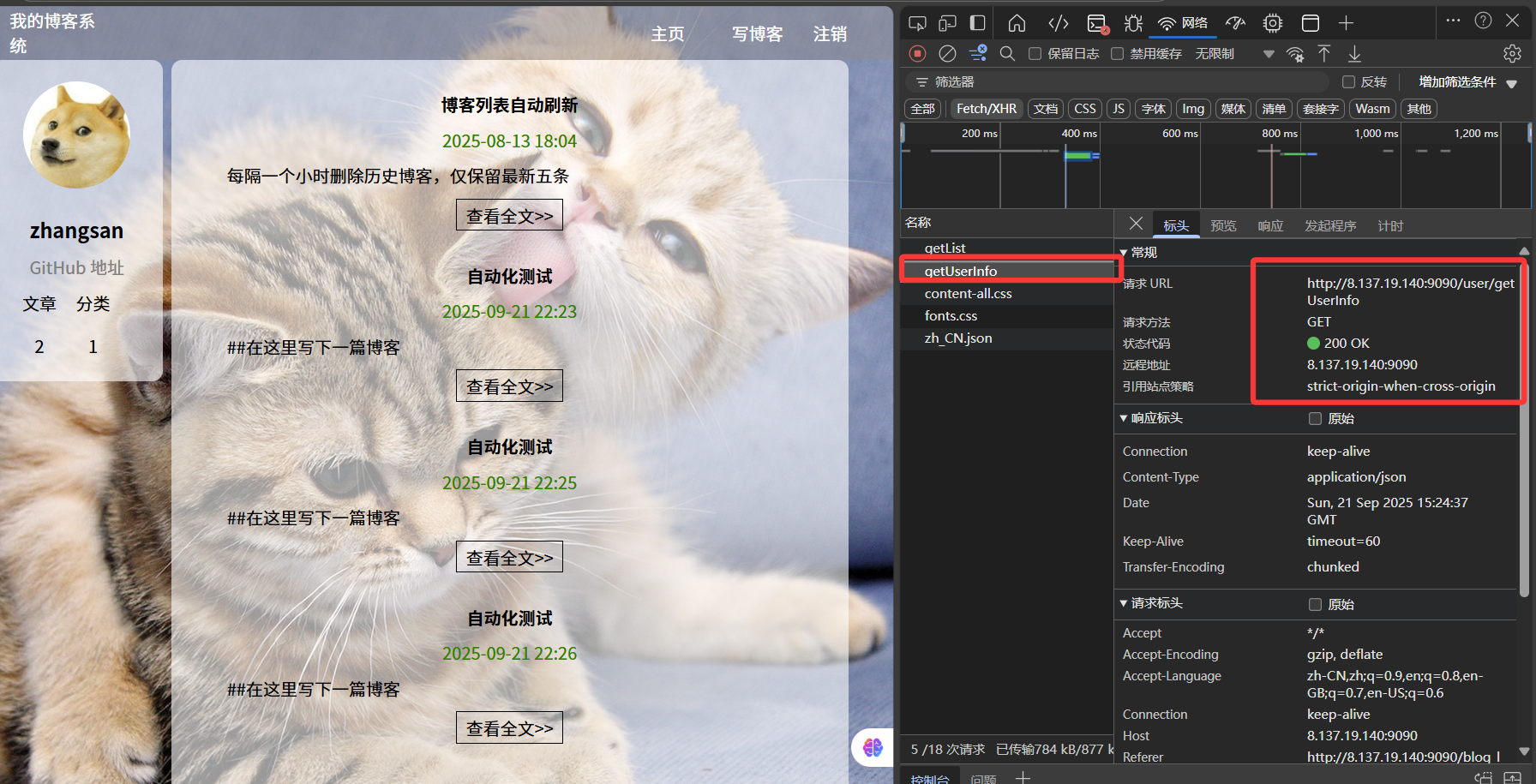
然后在JMeter中创建对应的HTTP取样器,填写基本配置信息(由于我们已经在默认配置文件中填写好了一部分信息,所以在这里就不用写了)
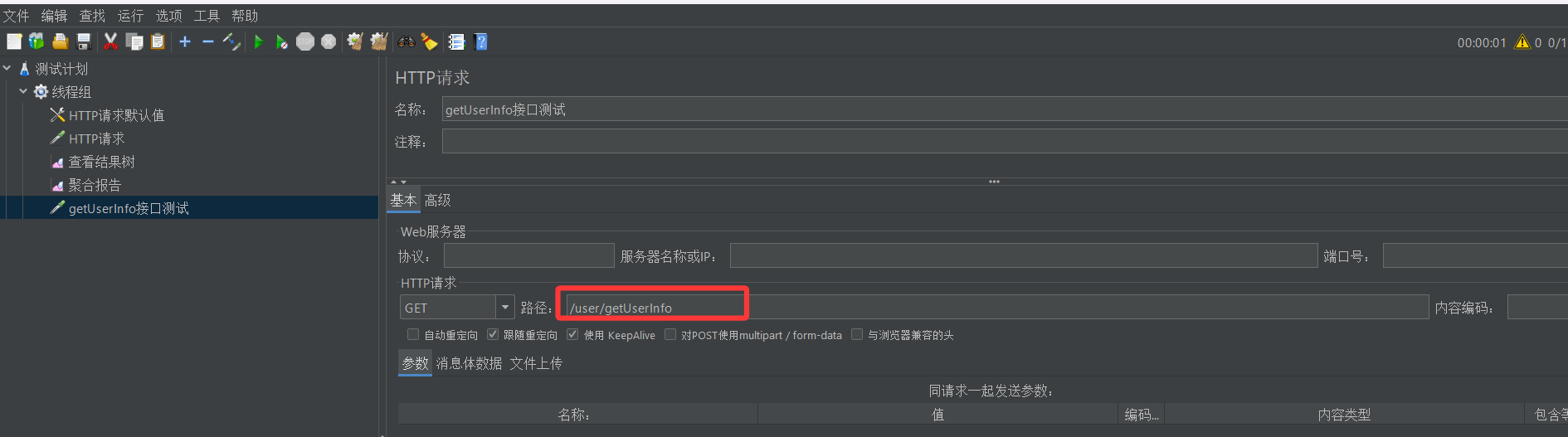
然后直接点击运行,结果如下
然后我们略作修改,先创建一个信息头管理器
复制getUserInfo接口中的user_token_header信息
将其添加到刚刚创建好的信息头管理器中,并保存配置

然后我们再运行测试,发现这次居然能连上了
看完了上面的实验,思考问题:第一次与第二次测试有什么区别?为什么第一次连不上?第二次就连上了?
区别主要就在于:第二次我们通过信息头管理器,向线程组下所有HTTP取样器发出的请求报文中,都添加了一个请求报头
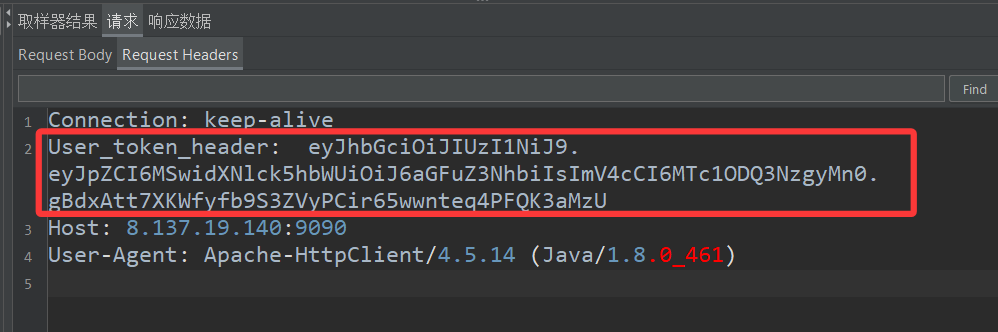
user_token_header报头用于记录某个用户的身份令牌。古时候的信使在传信时需要经过多个城池,每座城池都有看门的士兵,他们的职责就是不让陌生人随便进城。当信使到城下时,给士兵展示他手里的令牌,士兵一看,就会放信使进城了。
类似地,当携带着user_token_header报头的请求报文被服务器接收时,服务器通过解析报文,将user_token_header报头从报文中提取出来,然后通过比对,发现这个令牌是真的,那就会接受这个请求,并做出响应,否则拒绝这个请求
信息头管理器的作用域问题
下面有一个问题:你这个user_token_header报头是用来记录用户身份令牌的,但是我登录接口的测试中,请求报文就不需要添加这个报头,你给我添加了,反而会影响我的测试,这种情况应该怎么处理呢?
很简单,将这个信息头管理器拽进接口测试的取样器里面就行
Json提取器
令牌的实时更新问题
到现在为止还是有一个问题:同一个用户的身份令牌不是一直不变的,每次登录都不一样,即使是同一次登录,隔一段时间还会变一次。因此你将user_token_header写死在信息头管理器中,过一段时间就没法用了。这个问题应该怎么解决呢?
我们每次测试时,都可以先进行一个登录接口测试
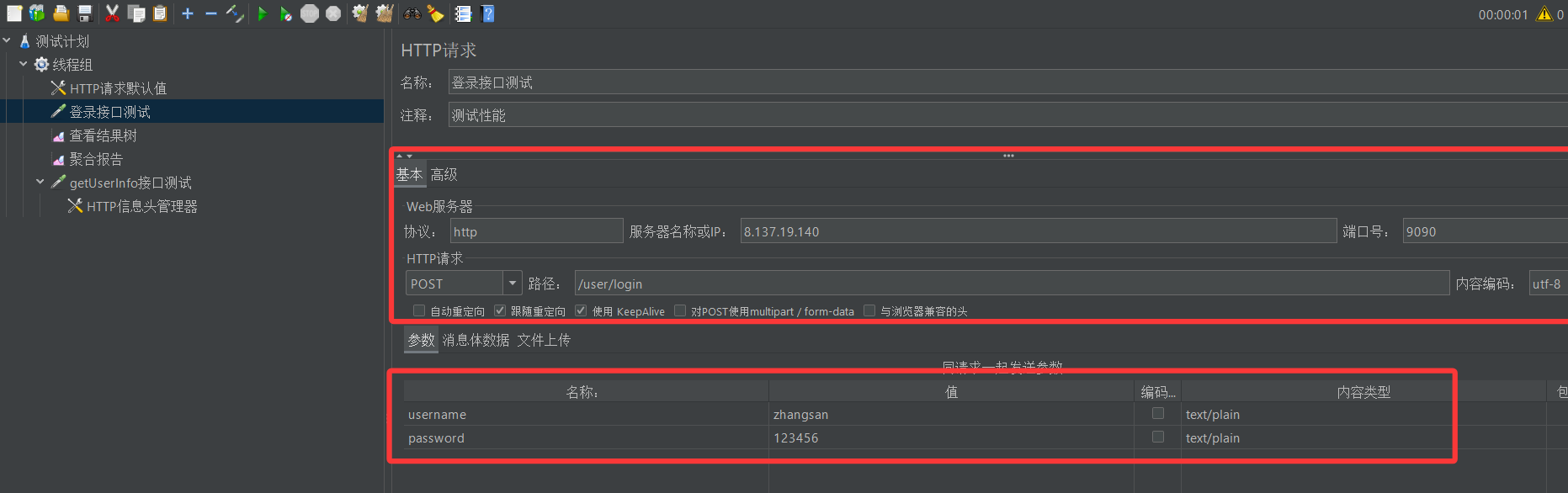
只要登录请求的密码正确,服务器就会实时为当前登录的用户创建身份令牌,并将该用户的身份令牌写入登录请求的回送报文中
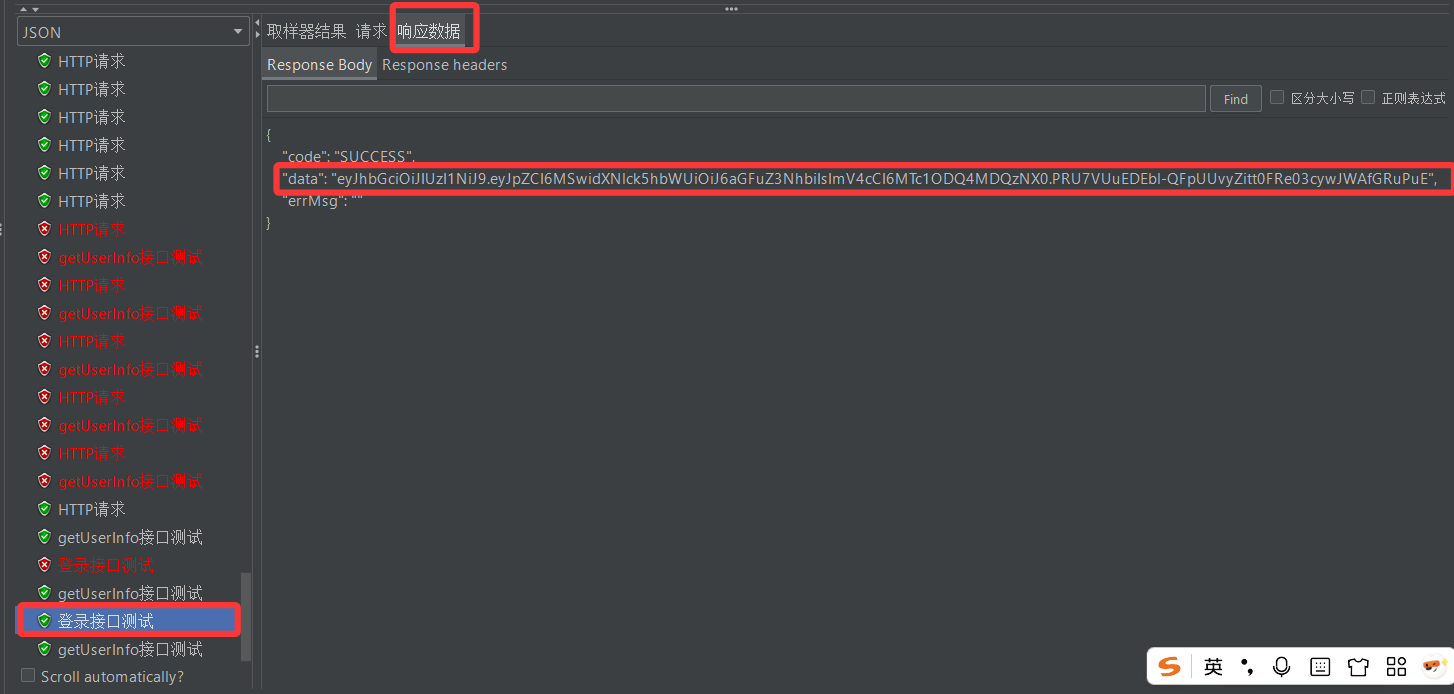
因此我们只需要获取登录测试回送报文中的用户身份令牌,然后将这个令牌写入头信息管理器中。这样即使令牌实时更新,我们也可以通过登录测试实时获取当前的身份令牌,就不会出现令牌过期的问题了
前面说的只是问题的解决思路,具体该怎么做呢?
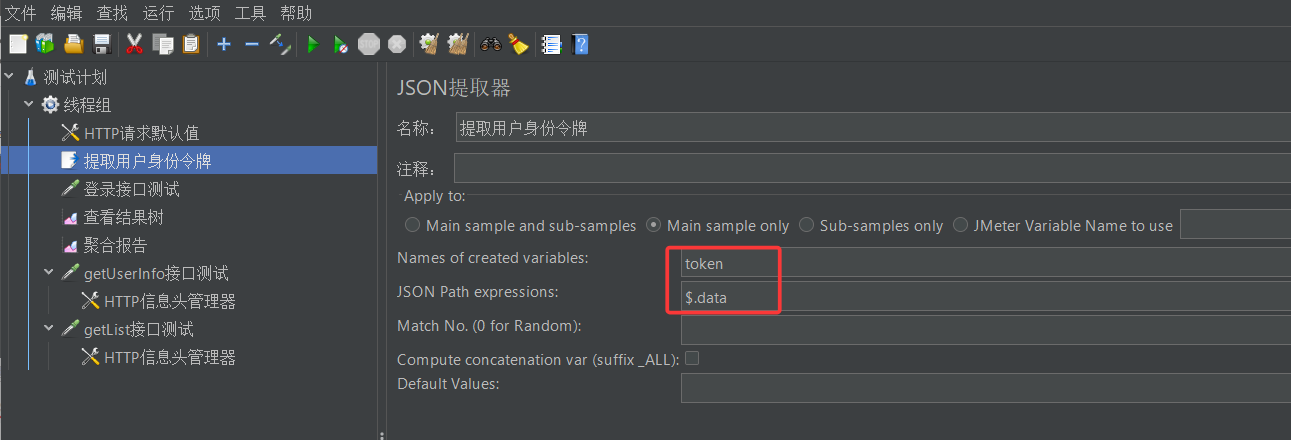
首先我们先添加一个json提取器
然后我们要对json提取器做一定的配置
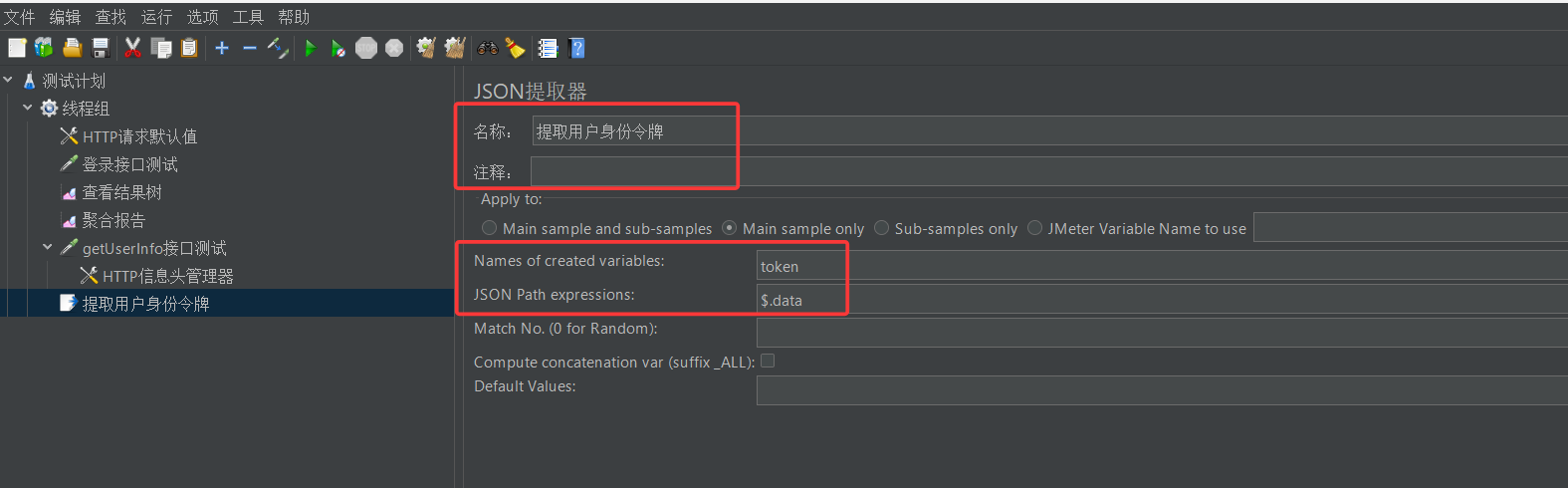
其中第一个参数很好理解,我们提取出来数据之后,要把它存放到一个变量中,第一个参数就是给这个变量起个名字
第二个参数就是用来告诉软件这个数据究竟是从哪提取的,比如在这个例子中json表达式为$.data,其中
$表示 JSON 数据的根节点(整个 JSON 对象).data表示取根节点下名为data的属性值
然后我们再修改一下getUserInfo接口取样器的信息头管理器配置,用变量token的值作为user_token_header报头的value

然后我们再运行,就成功完成了我们的优化
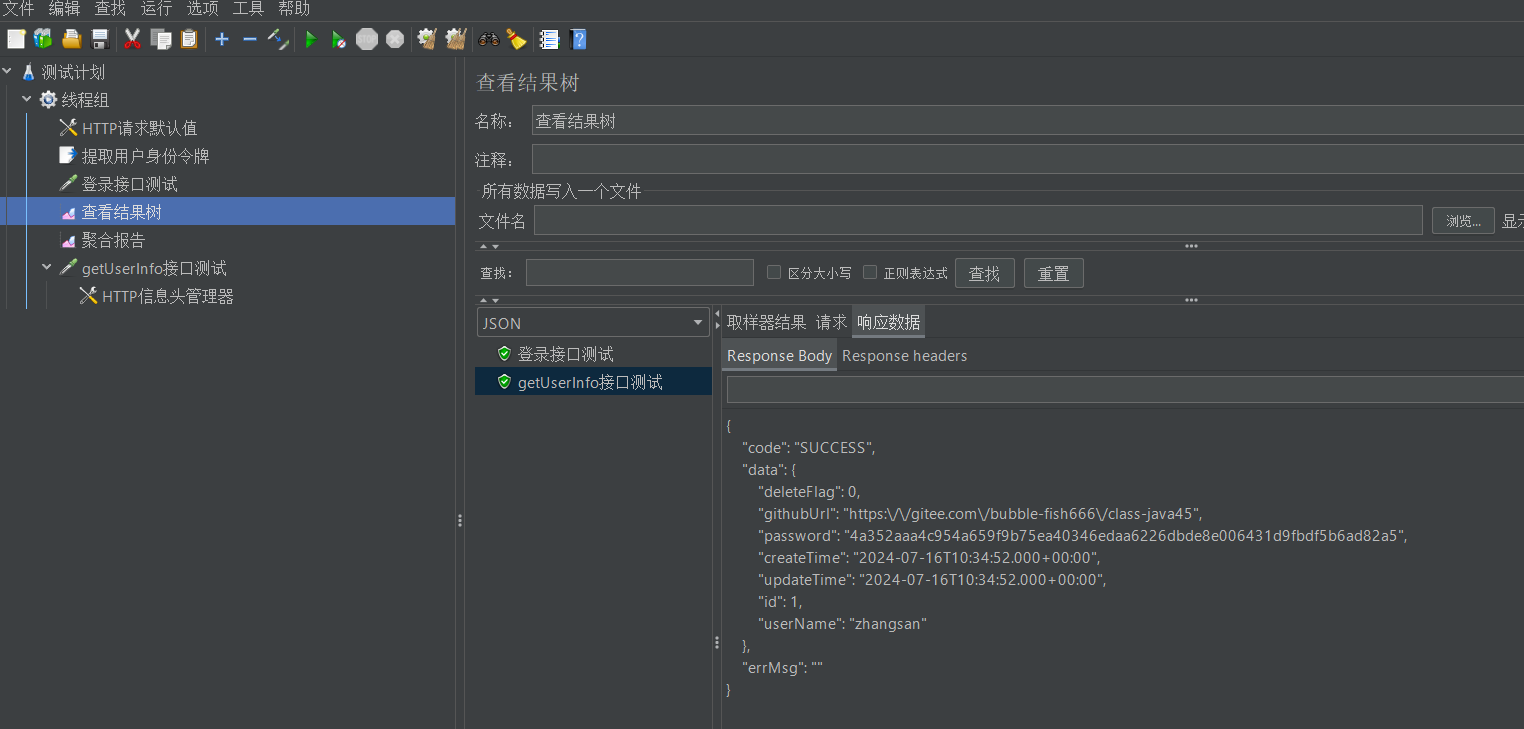
说到这里很多人可能还是不明白为啥那个$.data就能把令牌从登录接口的响应报文中提取出来,这里我们再多说说:首先$指的一定是当前线程组下的某个json字符串。我们每次运行测试的时候,都可以在结果树中找到两个json字符串,一个来自登录接口取样器,另一个来自getUserInfo取样器

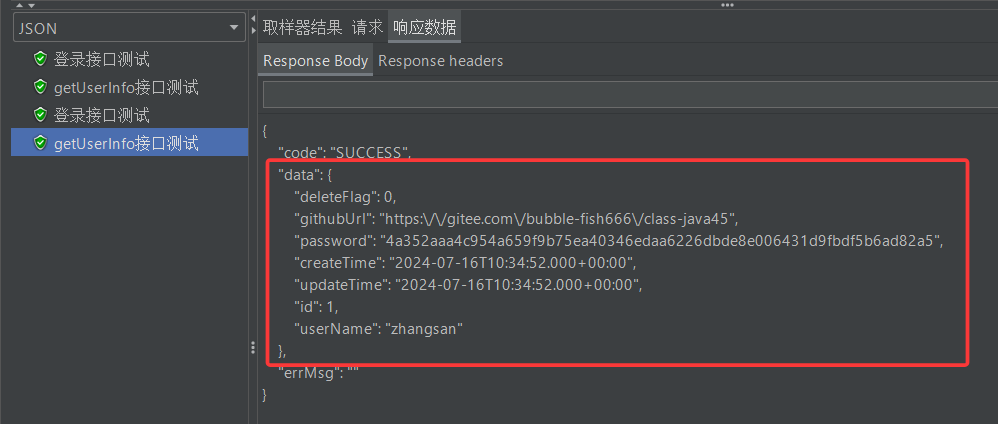
那为啥$指的就一定是登录接口取样器对应的字符串呢?原因很简单,token变量形成时,只有一个json字符串,它来自登录接口取样器收到的回送报文
因为getUserInfo接口取样器需要先读取请求头管理器中的配置,然后再形成报头,请求管理器中的配置就是user_token_header=${token},token变量赋值时,第二个取样器请求报文都没构建好呢,更别说从回送报文中提取json字符串了。
附:json表达式中常见操作符的含义如下表所示
| Operator | Description |
|---|---|
$ | 表示根元素 |
@ | 当前元素 |
* | 通配符。所有节点 |
.. | 选择所有符合条件的节点 |
. <name> | 子元素 |
['<name>' (, '<name>')] | 括号表示子元素或子元素列表 |
[<number> (, <number>)] | 数组索引或索引列表 |
[start:end] | 数组切片操作符 |
[?(<expression>)] | 过滤器表达式。表达式必须评估为布尔值。 |
到这里肯定有人还有问题,假如说我token在赋值时,线程组下的json字符串确实不止一个,那我的$指的到底是哪个字符串呢?
指的就是最新生成的那个json字符串。下面我们来实验验证一下
我们再创建一个新的取样器,用来测试getList接口,其基本配置如下。同时将getUserInfo取样器下的信息头管理器原封不动拷到getList取样器下。也就是说getList接口测试的请求报头中也会有user_token_header=${token}的配置
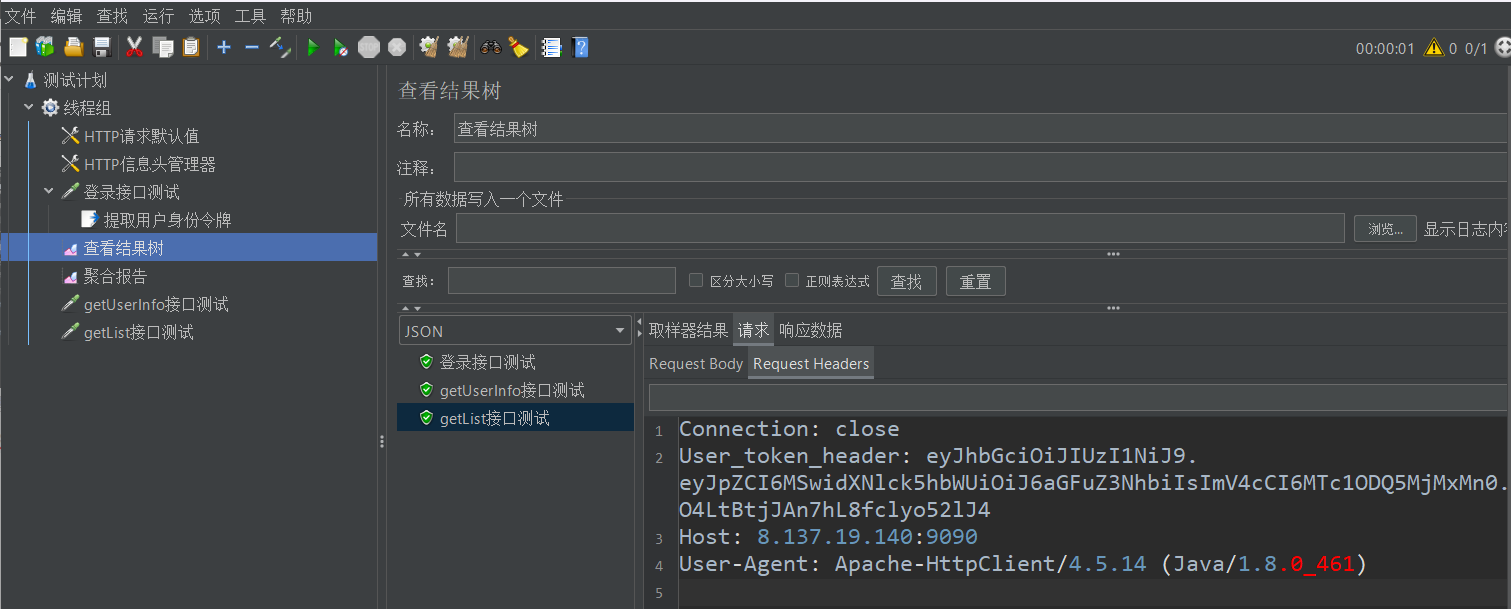
下面我们运行测试,结果如下
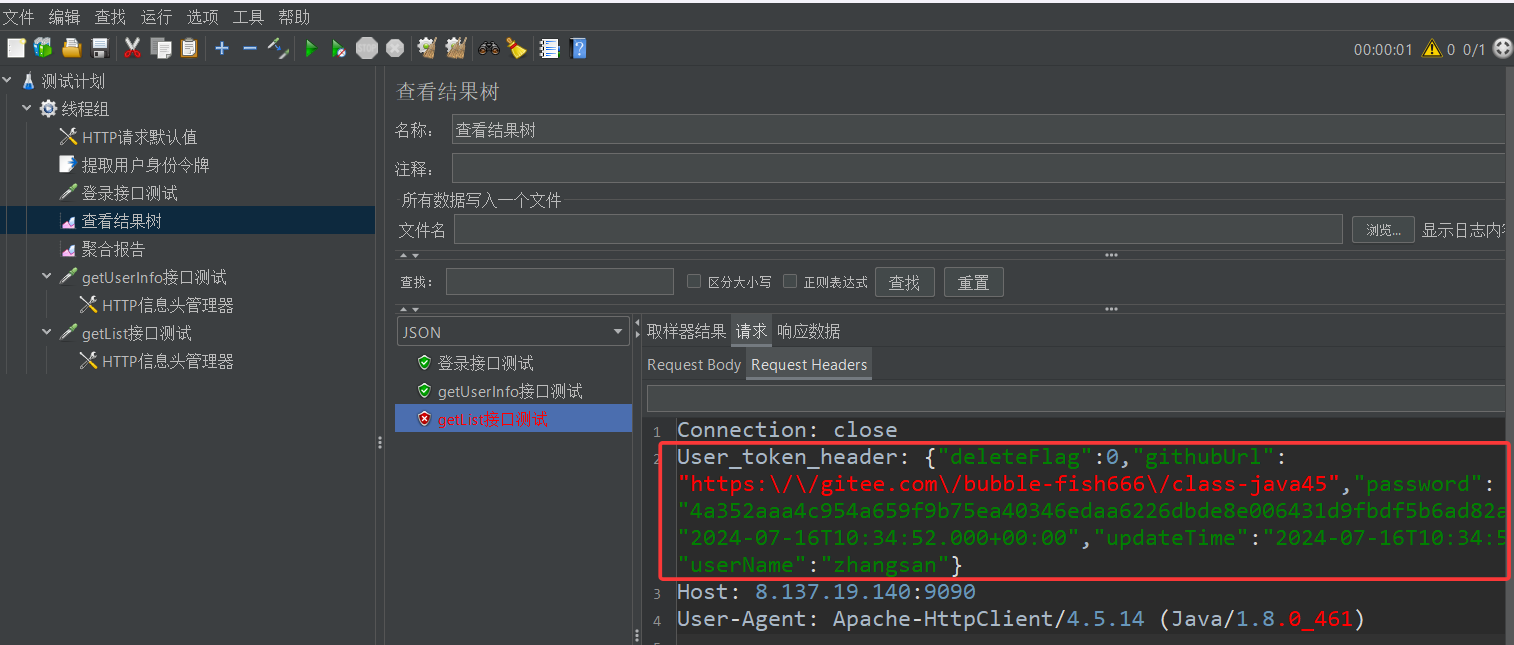
可以看到前两个测试正常,刚刚添加的getList接口测试出错了,其user_token_header并不是我们最开始期望的登录接口返回的用户身份令牌。那这玩意是啥呢?
它其实是getUserInfo接口测试返回的json字符串中的data
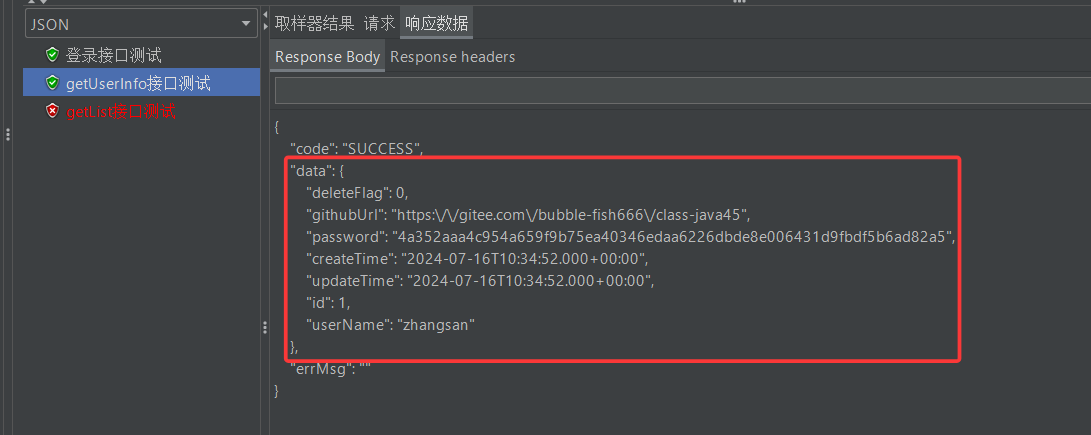
我token表达式又没变,一直是json提取器中的$.data,为什么前后token值却不一样呢?
这主要就是因为$指定的字符串有一个就近原则,当同一线程组下有多个json字符串时,$指定的是最新生成的json字符串(可以理解成新json字符串生成之后,就把老字符串覆盖掉了)
这时候我们再更改一下测试项目的架构,重新测试发现就没问题了,这又是为什么呢?
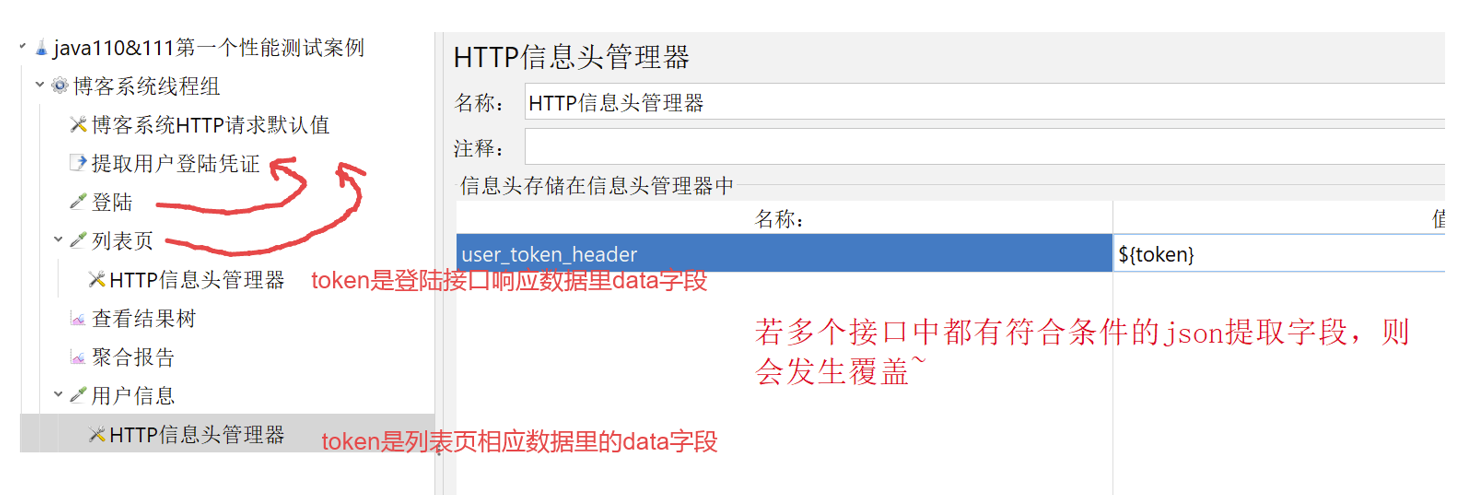
主要就是因为在之前的架构中,“提取用户身份令牌” 这个 JSON 提取器位于线程组的根层级,它的作用域是线程组下的所有取样器(包括 getUserInfo接口测试 和 getList接口测试),因此每执行一个新的取样器,json提取器都需要对token变量重新进行一次提取,虽然token始终等于$.data,但由于$一直在变,所以token也跟着一直在变
而如果我们将JSON 提取器放到登录接口提取器目录下,那它的作用域就只有登录接口这一个提取器了,当登录接口提取器测试结束之后,token更新一次,从此就不会再更新了,这就符合我们的要求了
用户定义的变量
我们同样还是以一个场景来引入。接着上面的说,检测完博客的主页和登录页面之后,我们还需要测试博客的具体浏览页面。
首先我们先进入一篇博客的详情页,找到可以测试的接口,将其信息复制下来,方便做后续详情页取样器的配置
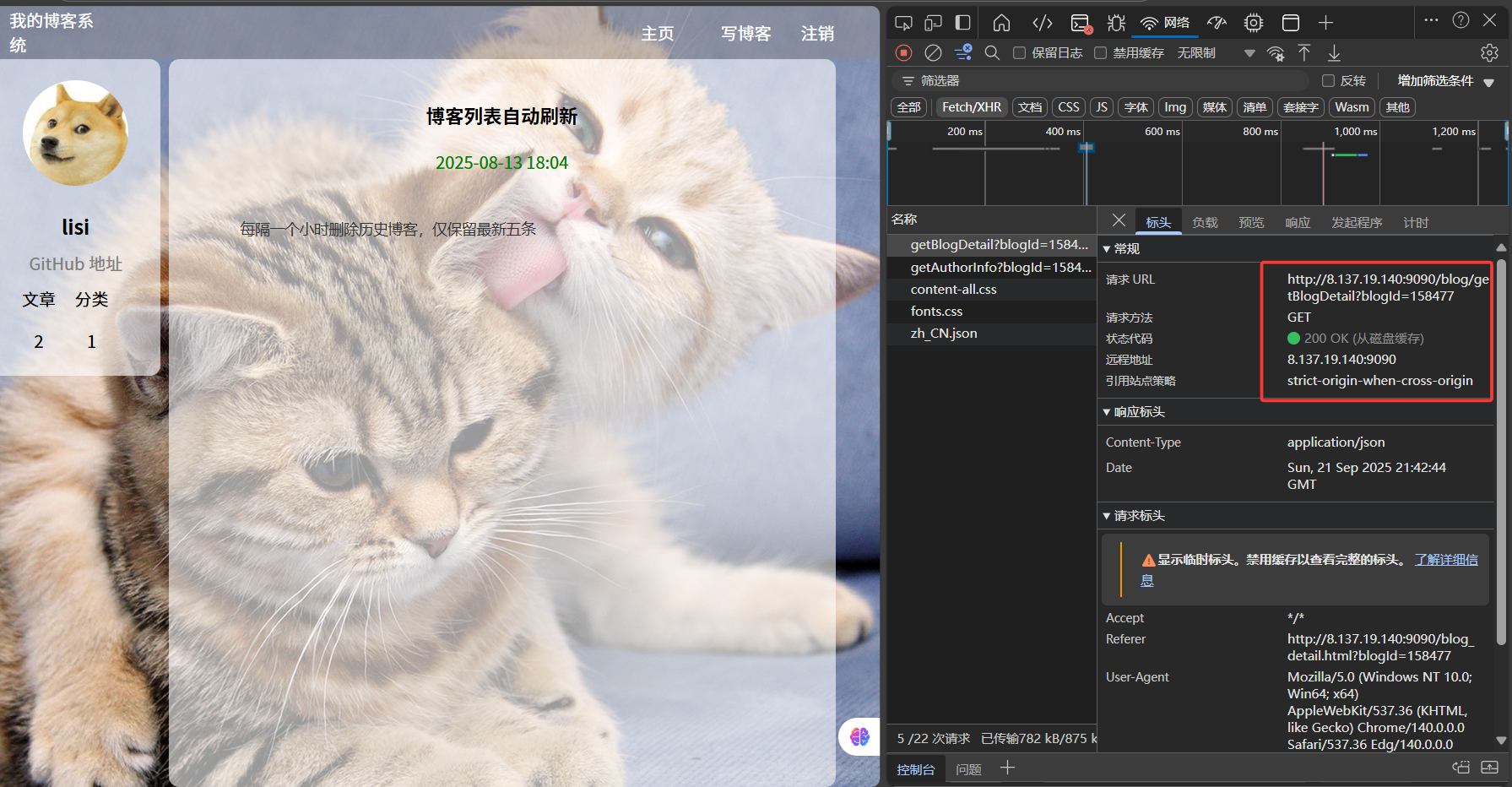
然后在JMeter的线程组中再添加一个取样器,配置如下
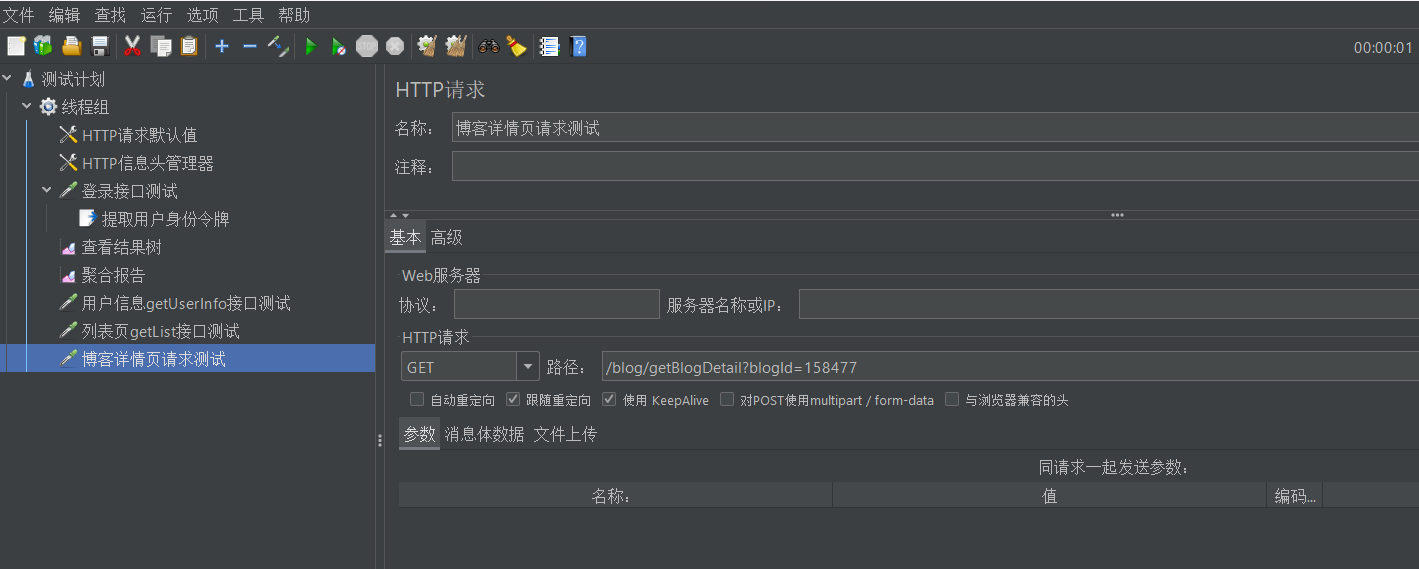
配置完毕之后,我们运行测试,结果如下
目前看来没啥问题,那假如说有一天,张三发现blogId=158477的这篇博客写的不好,把它删了。此后我再运行我的测试代码一定会报错,因为取样器配置中url写的blogId=158477,这博客删了之后,就找不到对应的资源了
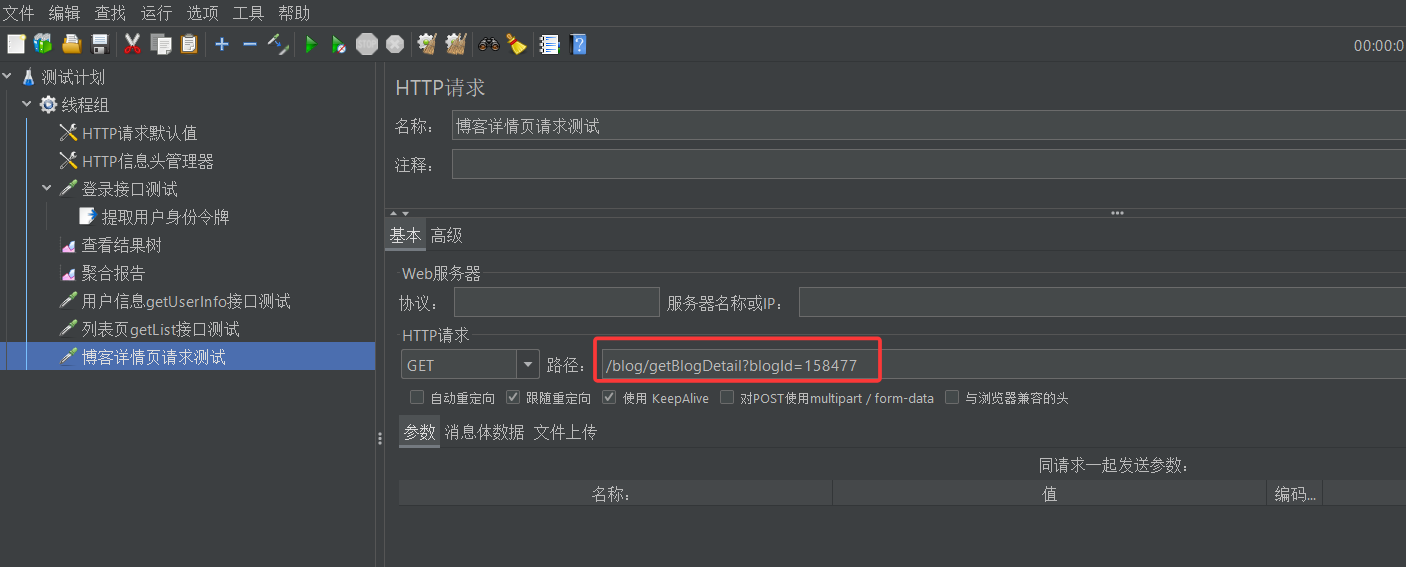
那现在你作为一个测试人员,发现测试出错的原因了,现在应该怎么修改呢?
你可能会说,很简单啊,我找一个有效的blogid换上去不就行了吗。没错,确实可以,但这只是缓兵之计,治标不治本,你无法保证某个博客永远不会被删除,没有在任何时刻都一定有效的blogid。下次它失效了,你还得重新找另一个有效的id换上去
这种做法虽然简单,但却不高效,那有没有高效的做法推荐一下呢?当然有,我们的思路就是,每次测完博客列表页之后,都动态从博客列表中取出一个博客的blogid,然后将这个blogid写入详情页的url中就行
那具体咋做呢?请看我操作
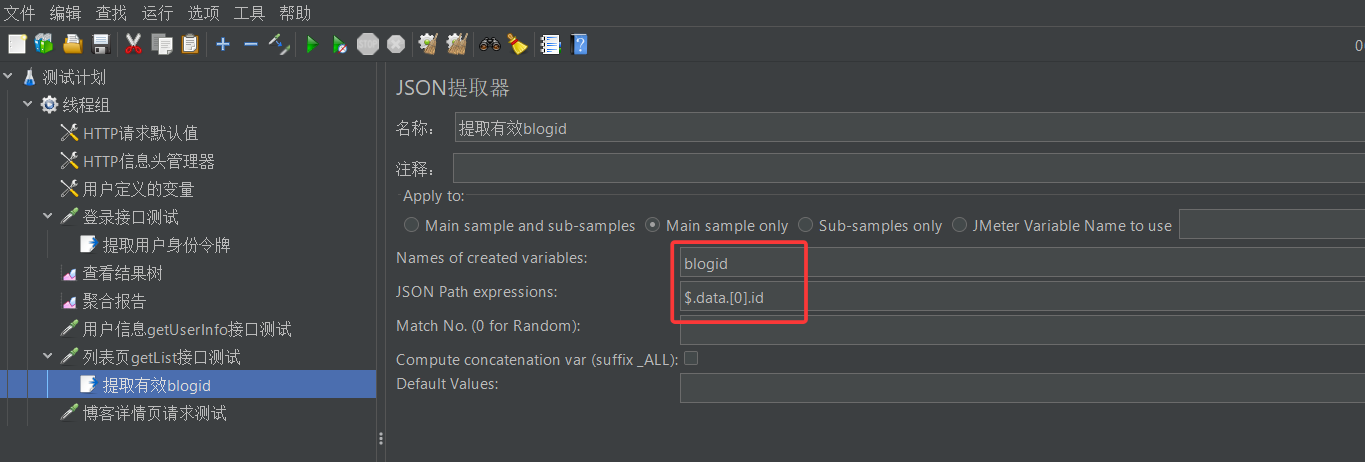
首先我们在getList取样器下用Json提取器将有效的blogid提取出来
然后修改博客详情页的url
改完之后再运行测试,就可以实现我们的优化了
有人看到这里肯定要说了,你前面讲的不全是Json提取器的老东西吗,
用户自定义变量你是一点没提啊,别急别急。请看下面的问题
假如说我这个人比较有版权意识,在每个测试的过程中都会添加一条备注,比如说I am Bill,后来我改名字了,假如说改成了Madala,那我想同步更新测试用例中的备注,改成I am madala,假如说有200个测试,那按正常情况来说,我得手动改200下,但是有了用户自定义变量,我只需要改一下就行(看到这大家肯定理解了,用户自定义变量的作用有点类似于C语言中的const 全局变量,定义的地方改一下,就可以轻易地实现全局替换)
首先我们先在线程组目录下创建一个用户自定义变量
创建完成之后,后面就可以把它当一个全局变量一直用了
想象场景:有两百个详情页接口,每个接口都要用到写死的id值,而这个id值后续可能需要修改,最好的方式用批量修改的方式——一次修改,终身收益
测试编辑页面的add接口
接着看下面的例子,当我们写完一篇博客之后,点击提交博客
之后主页就会出现一个add接口,我们刚刚点击按钮之后,就是通过这个接口向数据库中添加了一篇博客
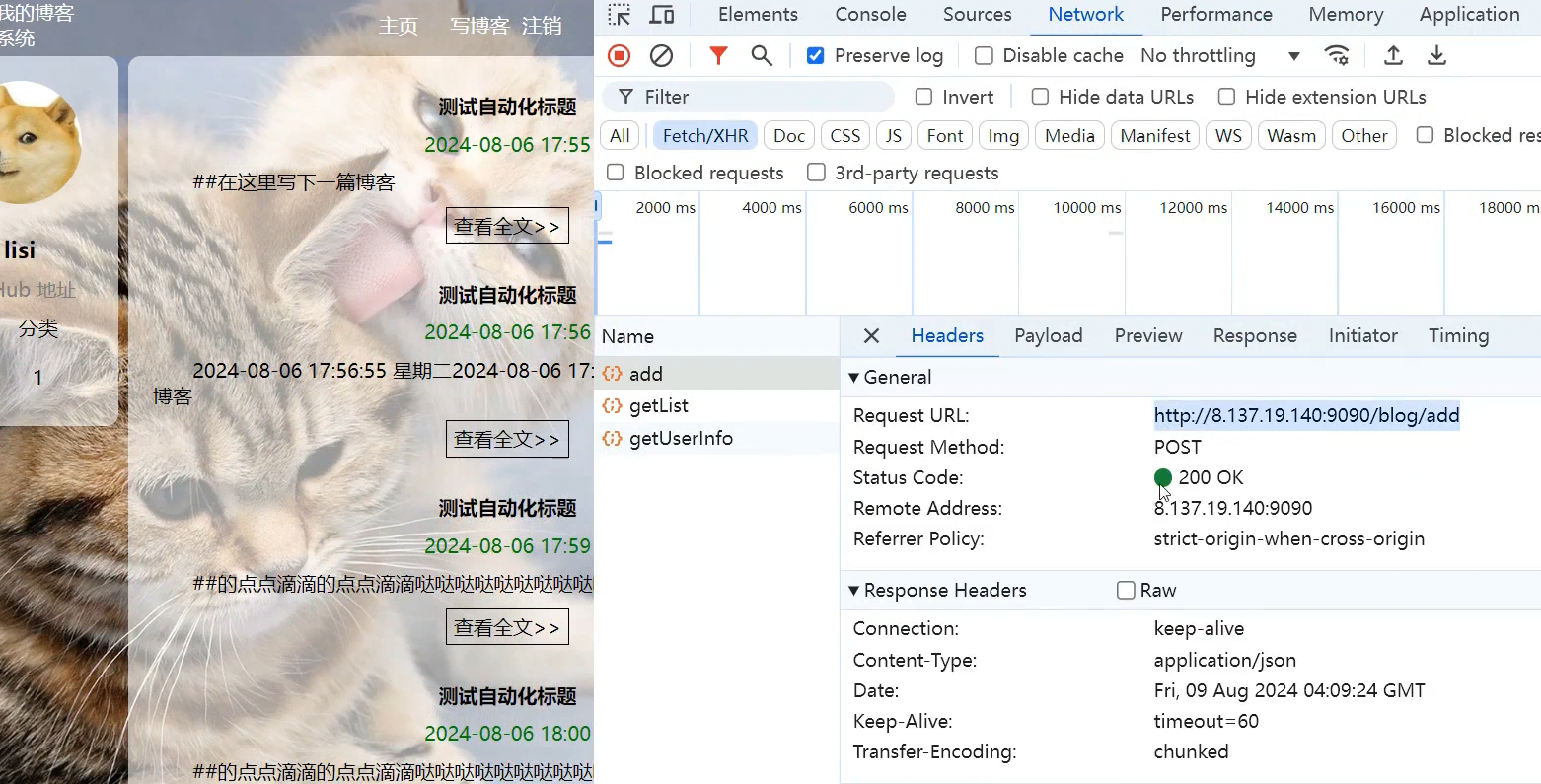
下面我们就通过web的控制台读取add接口的相关信息,然后通过jmeter模拟发送这个接口的请求报文
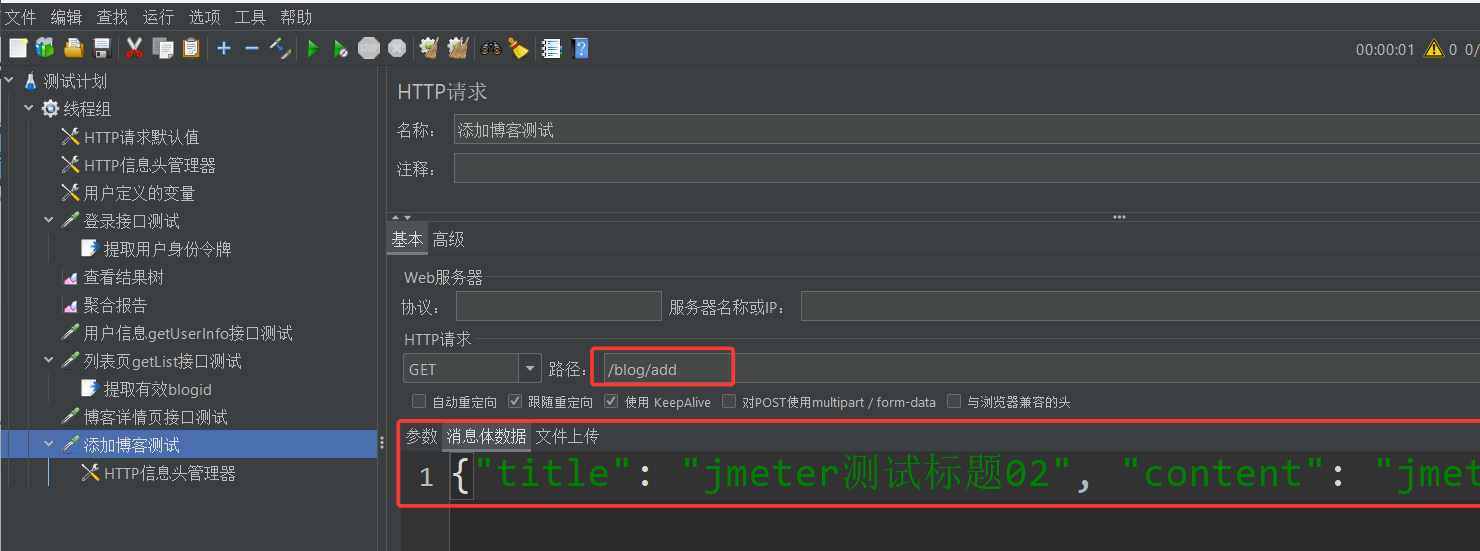
需要特别注意的是,add的请求报文中,需要添加一个报头字段:Content-Type: application/json,用来告诉服务器,以json字符串的内容解析我请求报文的正文,因为如果你不加,JMeter发送的请求报文Content-Type字段默认就是text/plain,请求就会失败
Json断言
前面我们测试都是通过一个个挨着查看结果树中的返回信息,来判断这次测试是否成功。
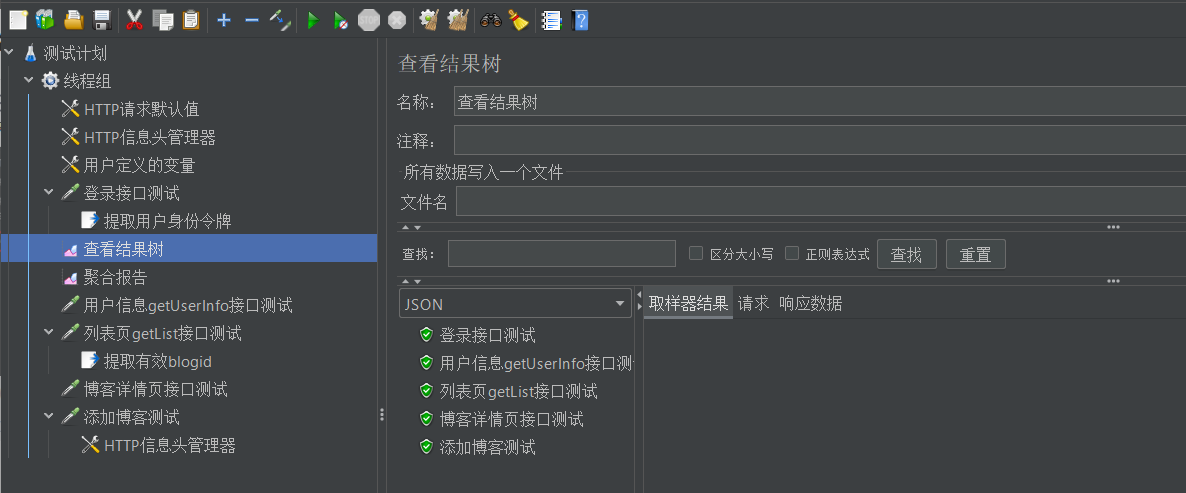
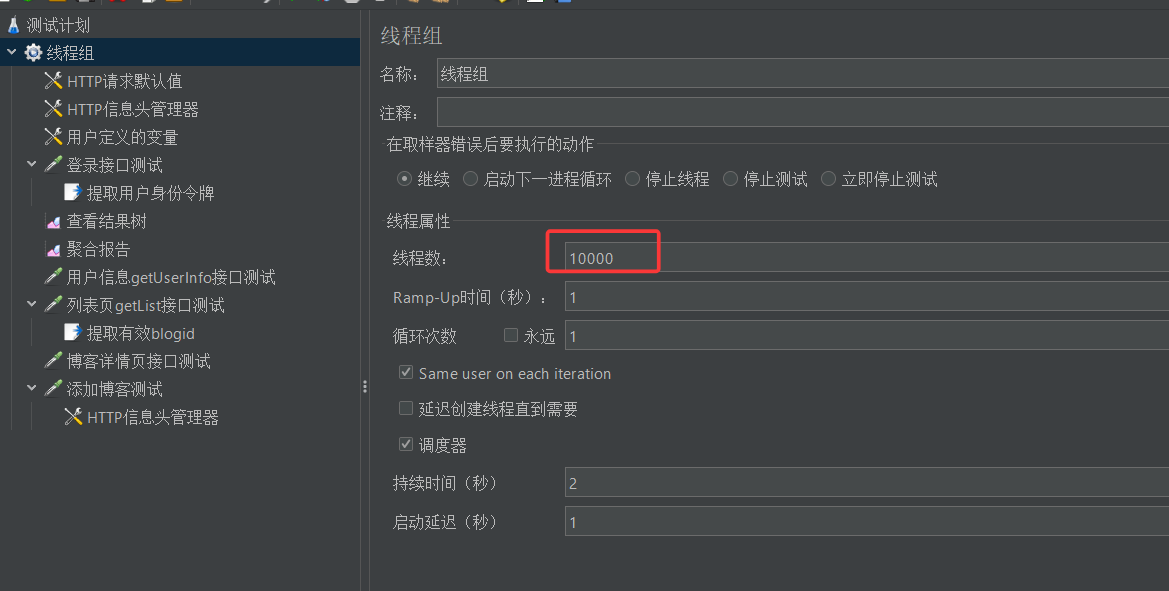
这里因为我们一次测试中每个取样器仅发送一个请求报文,所以响应报文也很少,一个个对比也是可以的,但如果你一次测试的并发量很大,比如
下图中10000的并发量,这时候你再一个个对比就是不现实的
此时我们只能将标准答案实现告诉计算机,让计算机来帮我们判断。具体咋让计算机帮我们判断呢?就是用Json断言来实现,具体看下面的例子
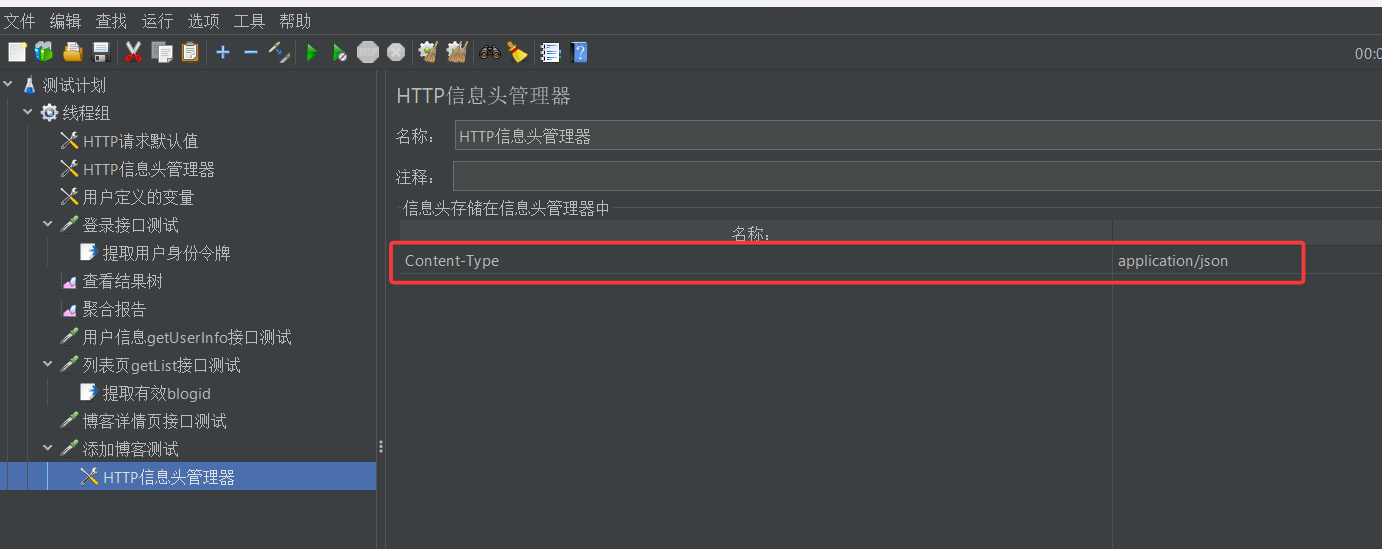
首先我们需要在线程组的每个取样器下为其创建一个专属的Json断言
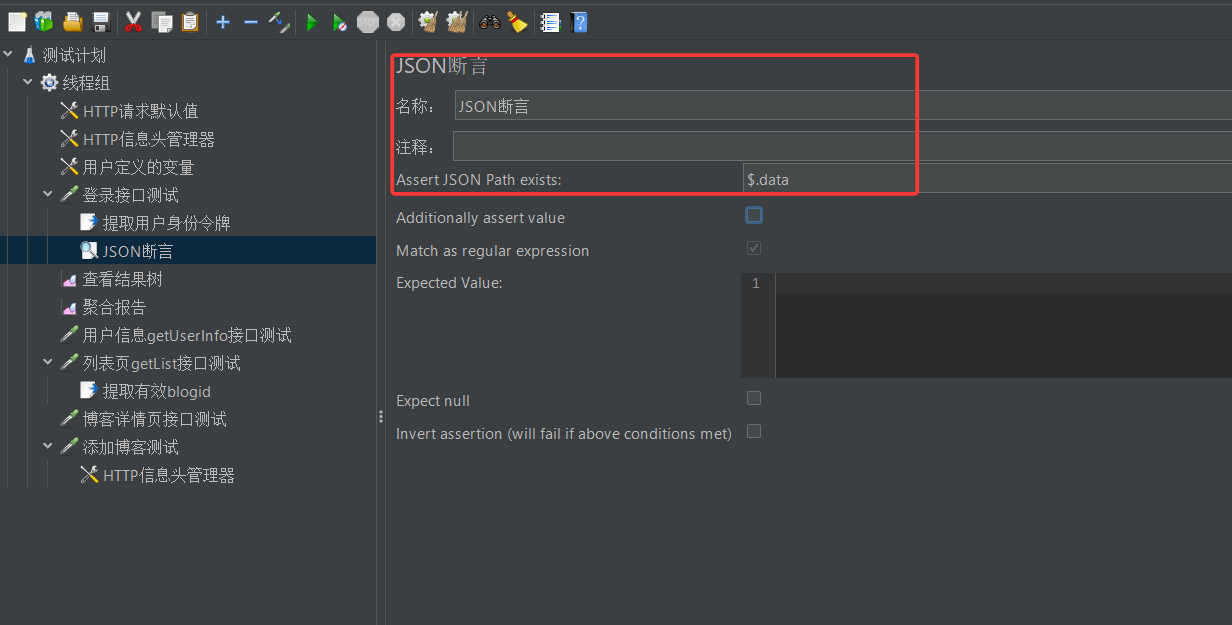
如果做下图一样的配置,那这个断言只能用来检测接口测试返回的json字符串中data这个字段是否存在
要想判断data字段的值是否等于我们实现给好的标准答案,我们还需要进一步进行配置
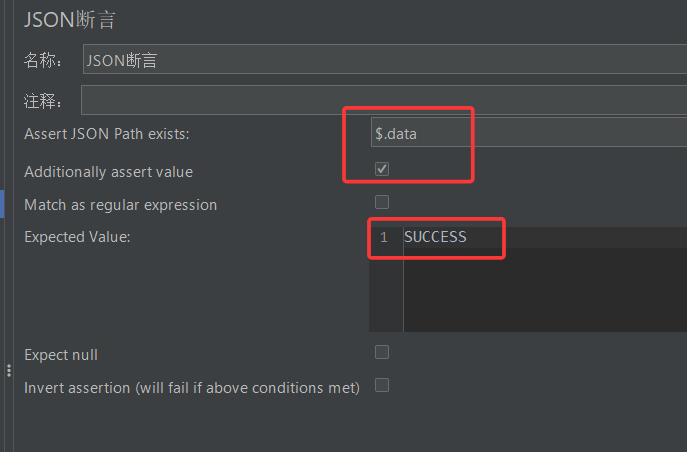
比如下面的配置中,我们勾选了 Additionally assert value,那我们就必须在Expected Value 中添加我们期望的断言值(注意这里的匹配是精准匹配,大小写不一样都会报错)
再比如在下面的配置中,我们勾选了 Match as regular expression ,表示Expected Value 支持正则匹配,那么我们就可以在其中输入一个正则表达式,如果匹配上了,就不会报错,匹配不上才会报错。比如下图中,正则表达式\s+就用来匹配一个或多个连续的非空字符
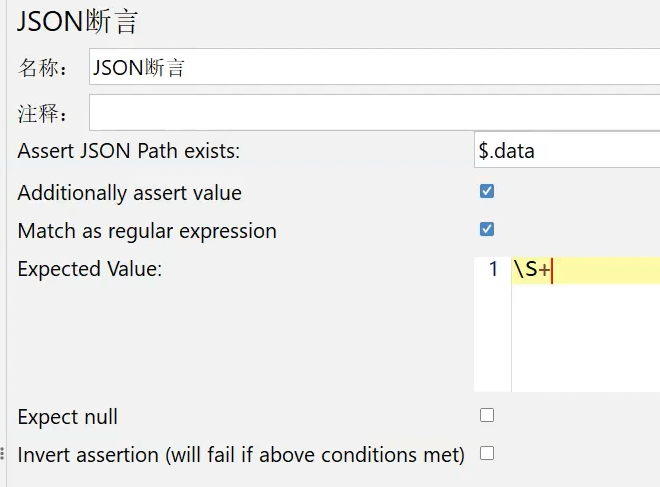
最后俩选项用的不多,直接说明一下意思
同步定时器
首先我们还是通过一个例子来引入。点击JMeter界面右上角的感叹号,我们就可以查看线程组执行状态
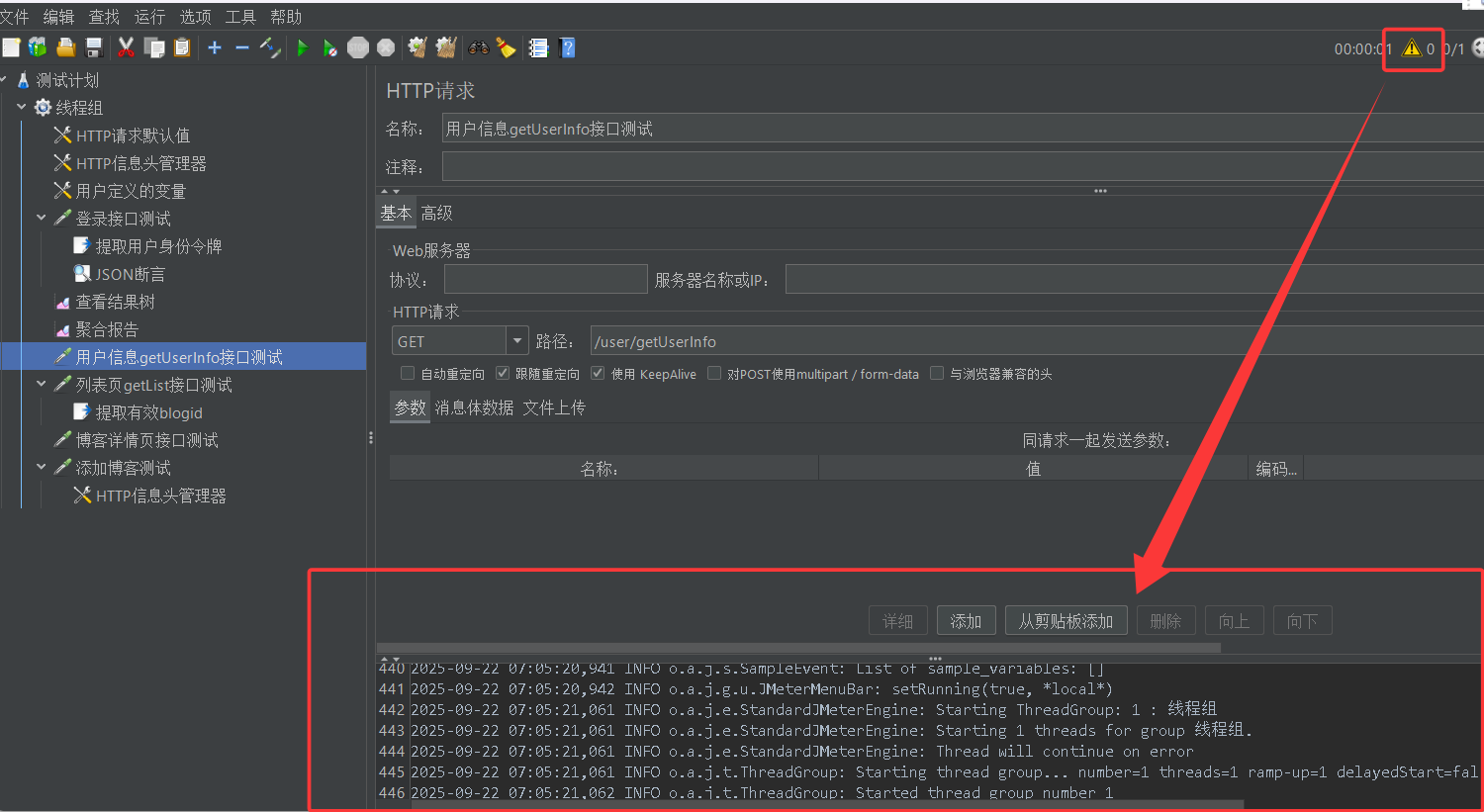
我们将线程组中线程的个数设置为5,然后运行测试,本次测试线程组执行状态如下图所示
通过观察我们可以发现,线程组中1号线程执行完毕以后,5号线程还没开始执行呢,这说明此时线程组中的5个线程并没有严格并发执行,并不能很好地模拟实际场景。那我们如何才能更好地模拟并发场景呢?其实就是通过同步定时器来完成:
首先我们在线程组中添加一个同步定时器
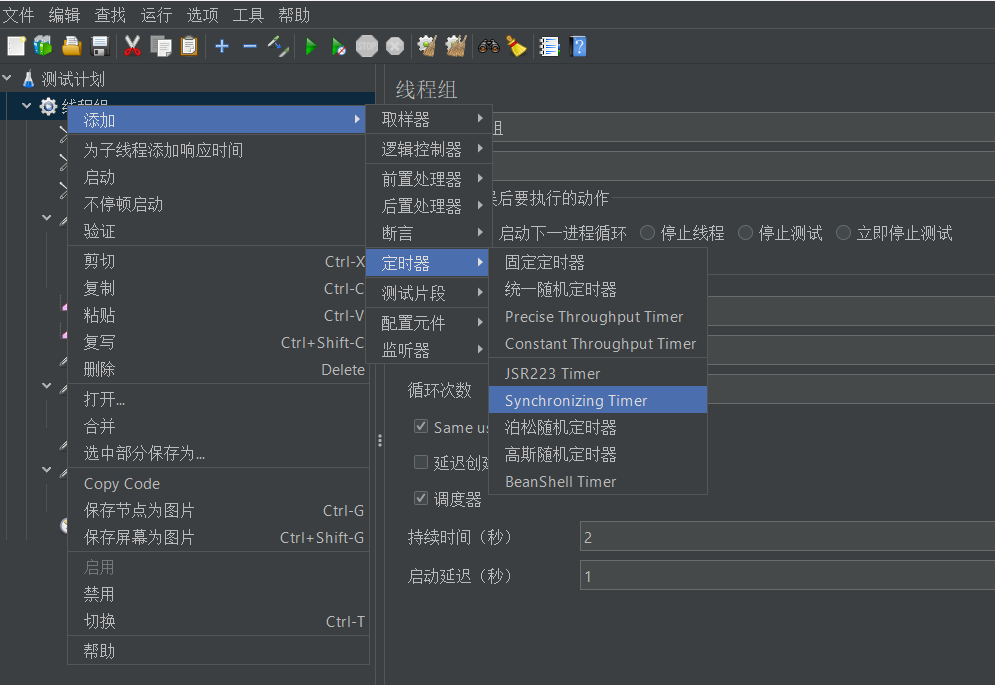
对定时器做如下的配置
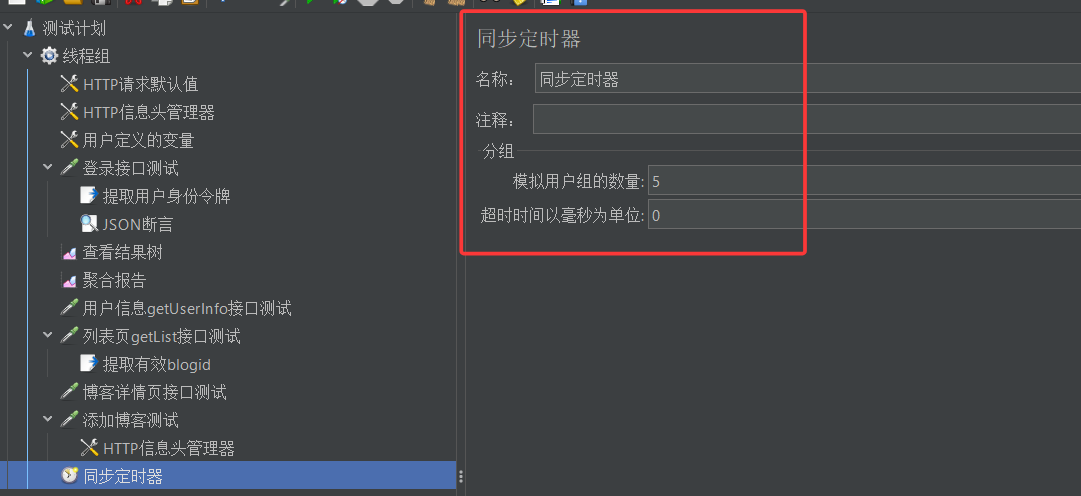
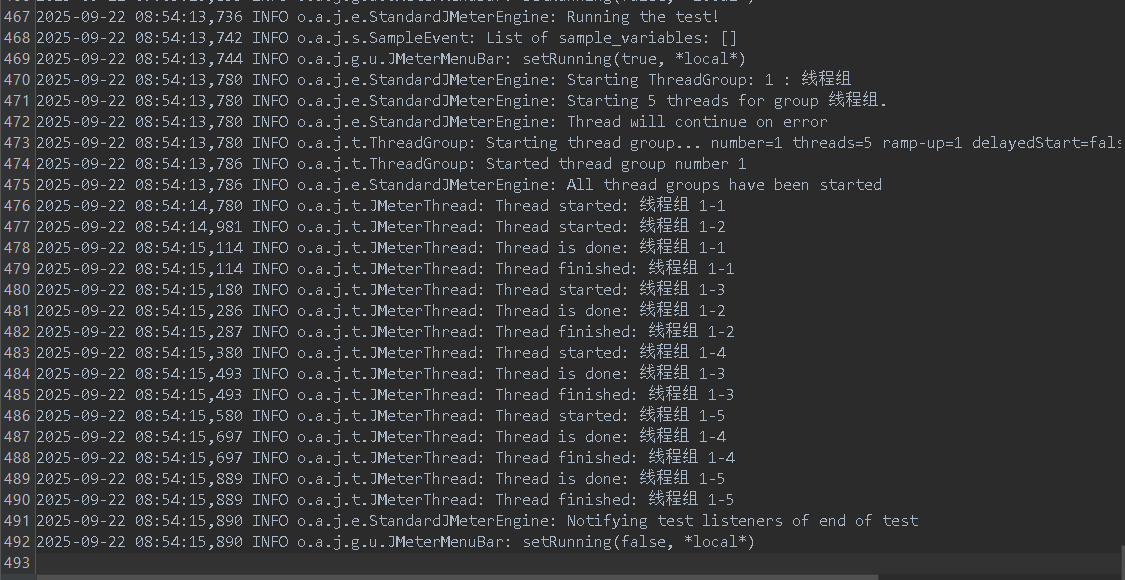
然后重新运行测试,查看此时测试的线程组运行状态
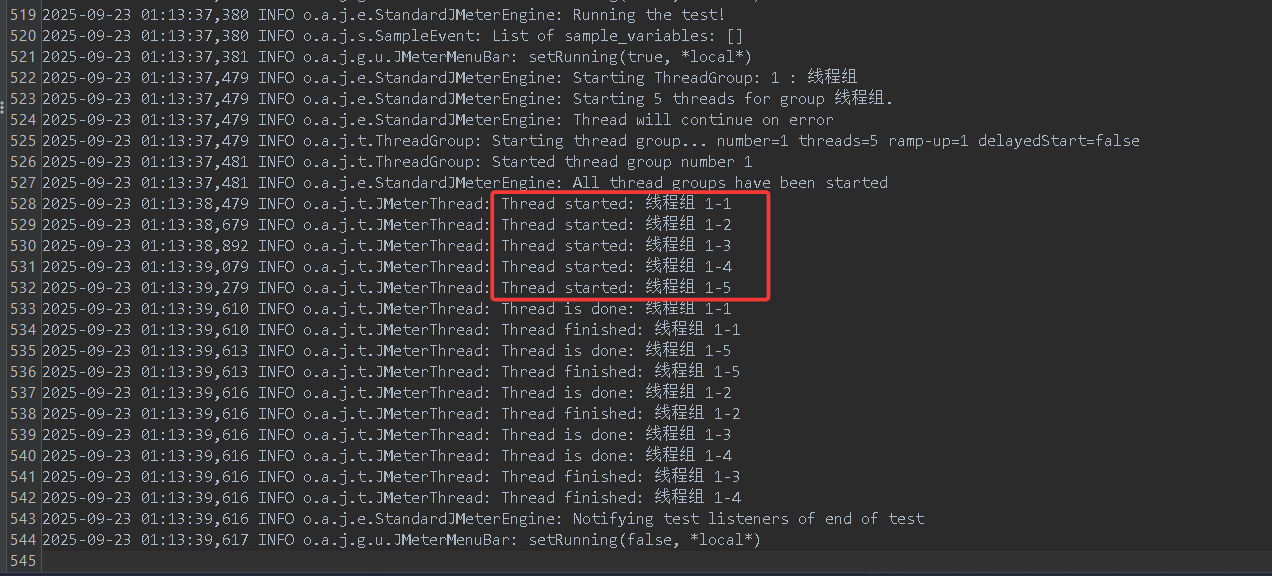
我们再把前面没引入计时器之前测试线程组运行状态拿过来,对比一下用红框框出来的内容,我们可以非常明显地看到,引入定时器之后,5个线程启动的时间挨得更近了,并发程度更高了,更贴合我们的模拟要求了
同步定时器中模拟用户数量应该如何配置呢?
我们前面的实验中,线程组中线程数量是5,定时器中用户数量设置的也是5。那用户数量可以设置超过5吗?可以小于5吗?
现在我们将定时器中的模拟用户数量改成50个,再次运行测试,会发生怎么样的结果呢?
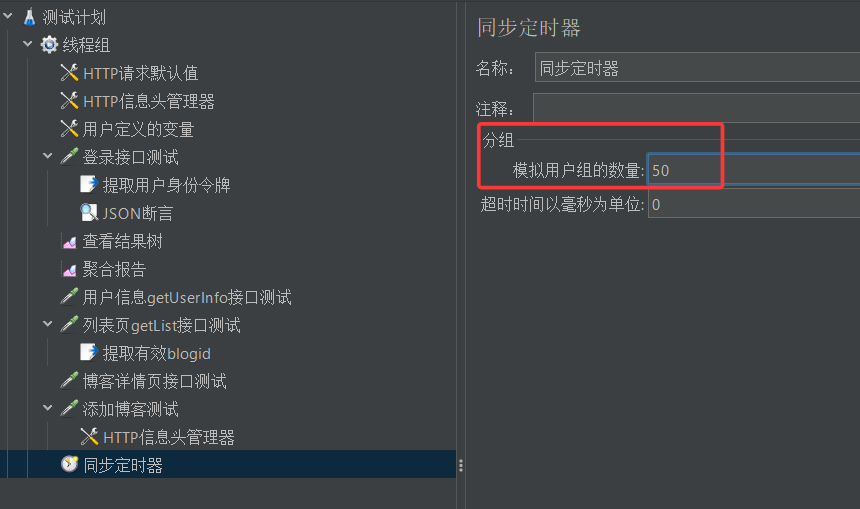
结果如下,依然是会先创建5个线程,与前面稍有不同的是,前面是任务完成之后正常退出,而这里貌似是因为等待事件超时而异常退出,这是为啥呢?
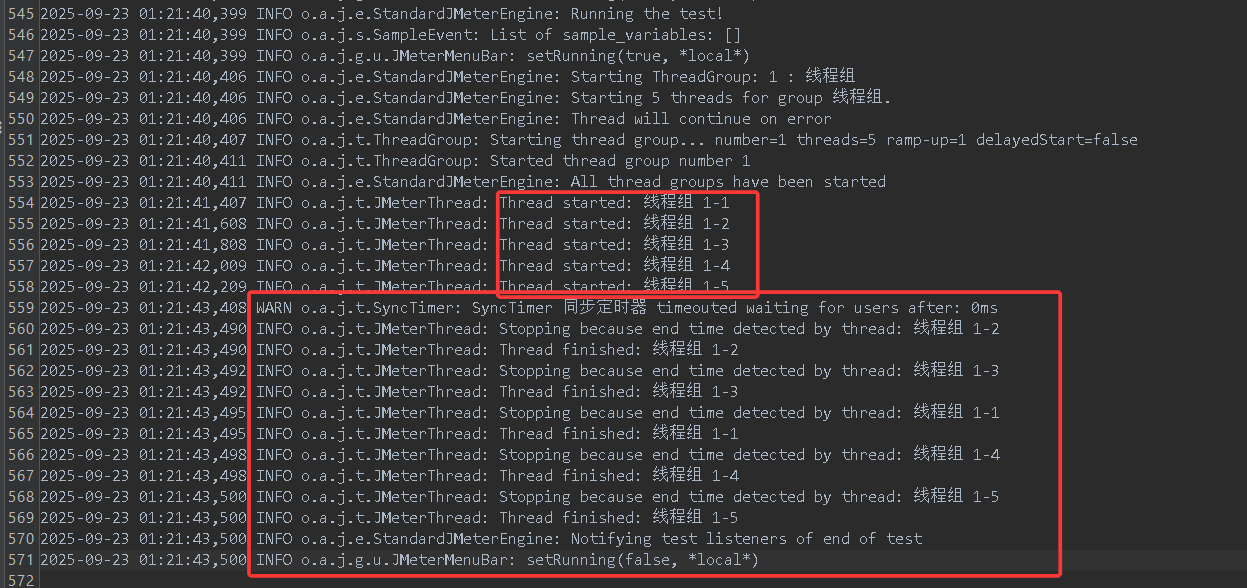
答案很简单,主要原因就是你定时器中模拟的用户数设置为50,那就需要同时启动50个线程,只有50个线程同时启动之后,才会让他们开始测试。但而我们线程组中仅仅定义了5个线程,当这5个线程启动之后,就会等待其余45个线程启动,然后才开始执行。但是我们知道,他们永远等不到了,等待超时之后,线程不执行具体测试,直接退出
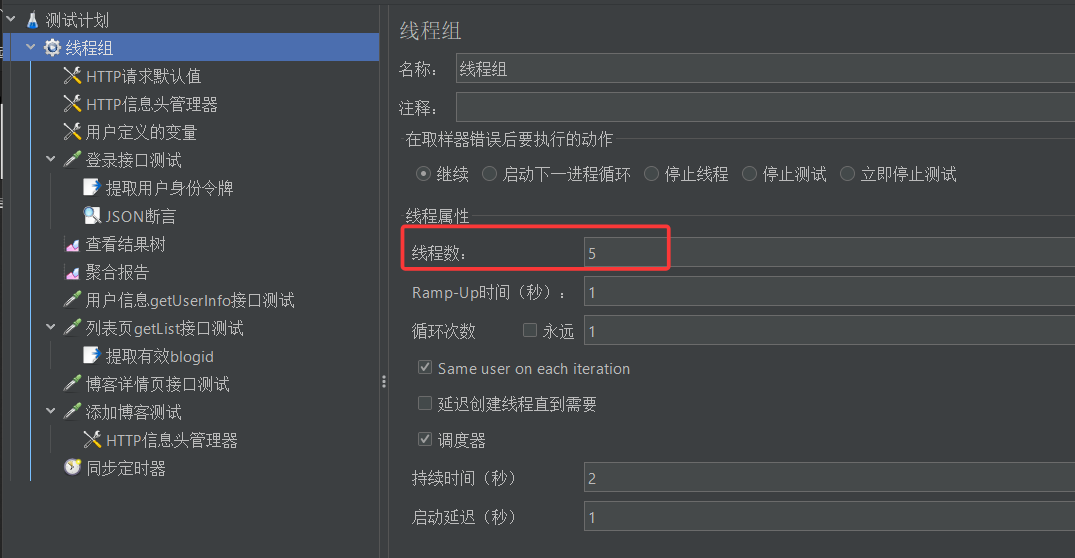
好的,现在我们再做一个实验,保持线程组中线程数量不变(依旧是5个),我把定时器中的模拟用户数量改成3个,结果会有什么不同呢?
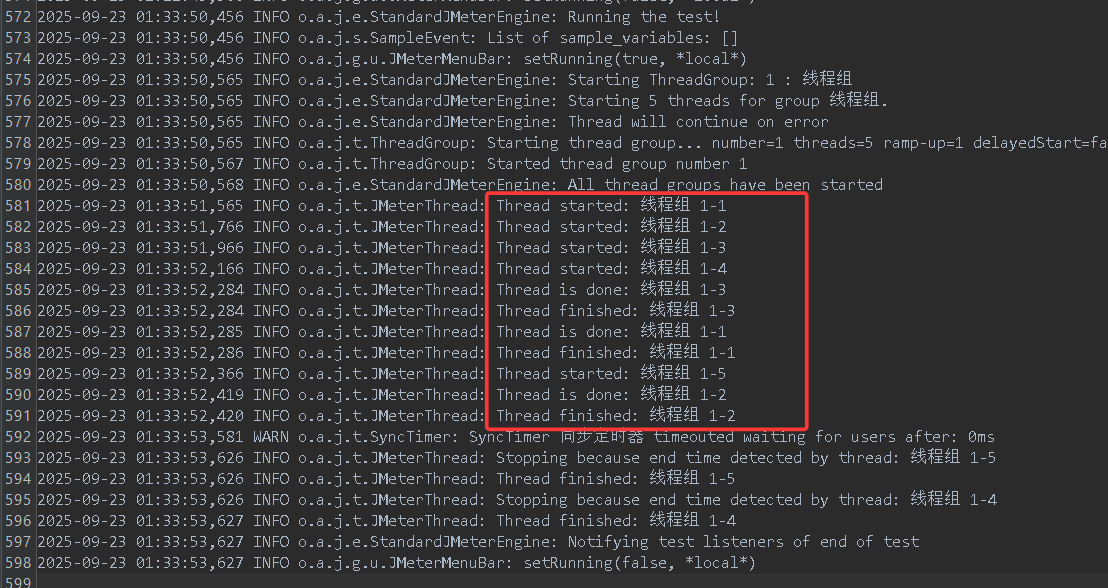
我们可以看到,在本次测试中123号线程成功完成了测试,但是4和5号线程在启动之后一直在等待(因为是三个线程一组,4号5号目前就俩线程,还差一个),等待超时之后不执行测试,直接退出
综上我们可以得出结论:
- 定时器中用户数量不能超过线程组中线程的数量,如果超过,测试时所有的线程都会因为等待超时,不会执行测试直接退出。
- 定时器中用户数量可以小于线程组中线程的数量,多余没用上的线程不会执行测试,会因超时等待直接退出。
事务控制器
事务控制器又是干啥的呢?主要是用来方便做统计的。在我们前面的例子中,我们一共是做了五个测试,分别是:
- 登录接口测试
- 用户信息接口测试
- 列表页接口测试
- 博客详情页接口测试
- 添加博客接口测试
在实际的工作场景中,很可能会出现一种情况,就是几个接口共同协作,完成一个功能,比如在电商平台中,我们将 “成功达成一笔交易” 看做一个事务,该事务往往需要很多请求接口协作完成,比如
-
商品相关请求
-
购物车/订单创建请求
-
支付相关请求
-
订单状态更新请求
这些请求环环相扣,从商品选择、订单创建到支付完成、订单履约,共同构成“达成一笔交易”的完整事务。
那我在给上级汇报的时候,人家肯定不会管你具体每个接口的情况,人家只想要的是基于 “达成一笔交易” 这一事务的统计数据。这就需要你对这一事务下的各个接口的测试数据进行分析整合,得出上级要看到的数据
那怎么分析整合呢?有人说瞪眼法观察,这显然是比较低效的,为了方便测试人员整合数据,JMeter就提供了事物控制器的功能,利用它,我们可能将若干个接口测试合并成一个事务,然后在测试结束生成的聚合报告中,我们也能够看到合并后事务的统计信息
下面的实验中,我们的目的是将登录接口测试和用户信息接口测试合并成一个事务,叫做登录事务,运行结束之后通过聚合报告查看合并后的事务信息。以下是具体流程
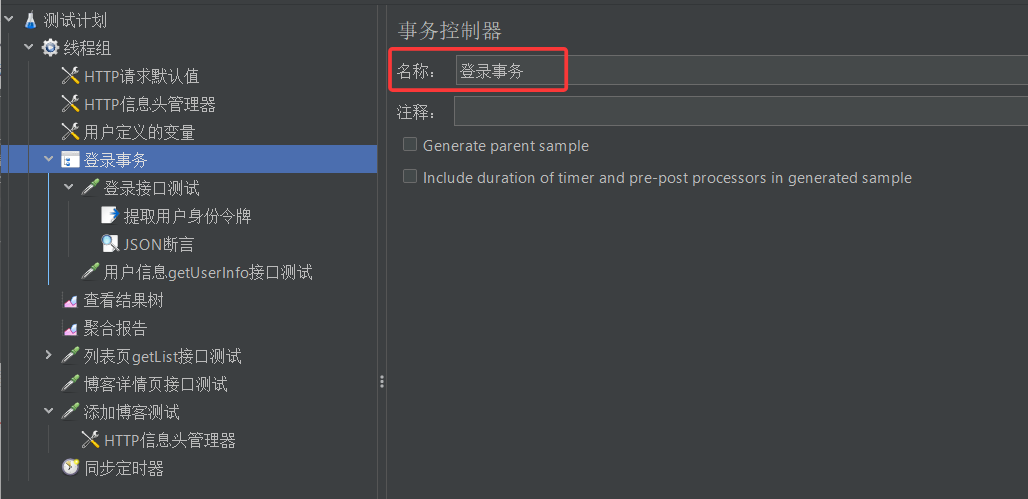
创建一个事务控制器
取名字为登录事务,然后把登录接口测试与用户信息测试两个取样器放到登录事务下
线程组配置如下
定时器配置如下
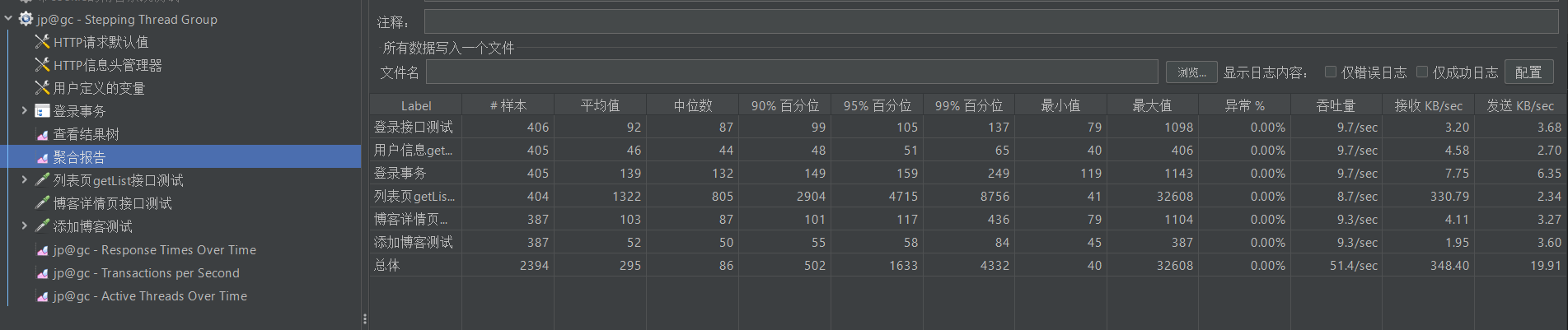
下面我们运行测试,完成之后查看聚合报告,可以看到报告的表项中不仅有我们线程组下的所有取样器,还多了一个登录事务的表项
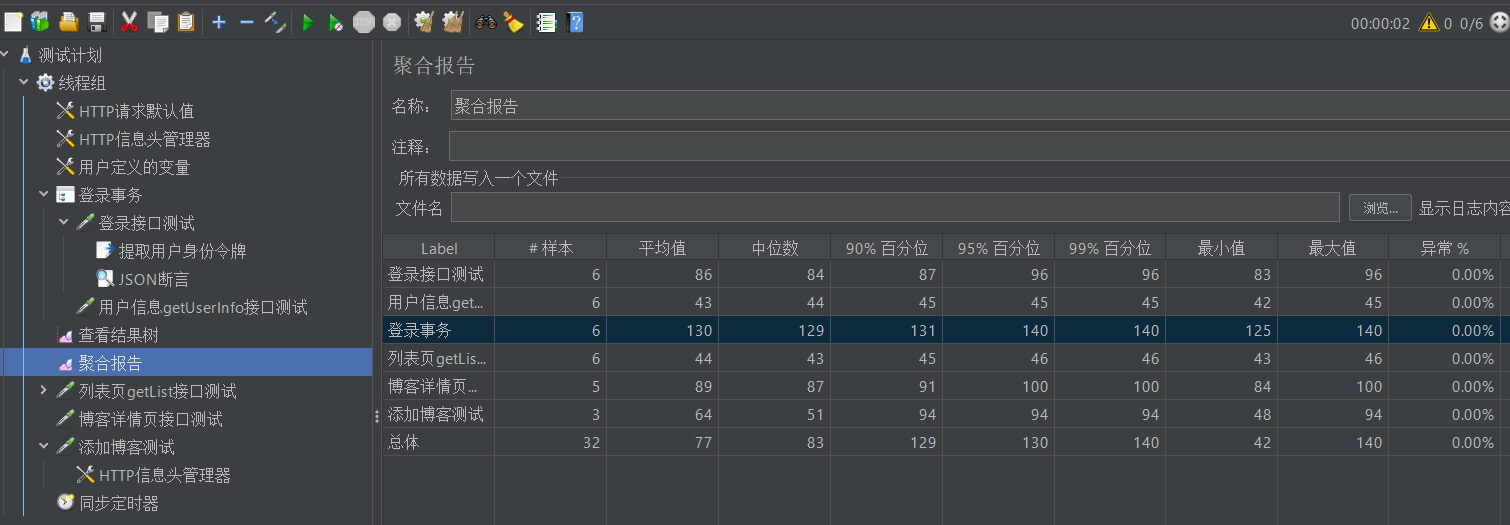
图中聚合报告表格提取出来就是下表,请问表中各列属性都是啥意思呢?
下表第一行中的所有统计量都是围绕响应时间来做的,即平均值的含义就是样本响应时间的平均值
| Label | #样本 | 平均值(ms) | 中位数(ms) | 90%百分位(ms) | 95%百分位(ms) | 99%百分位(ms) | 最小值(ms) | 最大值(ms) | 异常% | 吞吐量 | 接收 KB/sec | 发送 KB/sec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 登录接口测试 | 6 | 86 | 84 | 87 | 96 | 96 | 83 | 96 | 0.00% | 10.3/sec | 3.43 | 2.80 |
| 用户信息getUser… | 6 | 43 | 44 | 45 | 45 | 45 | 42 | 45 | 0.00% | 11.1/sec | 5.25 | 3.11 |
| 登录事务 | 6 | 130 | 129 | 131 | 140 | 140 | 125 | 140 | 0.00% | 6.3/sec | 5.06 | 3.47 |
| 列表页getList接… | 6 | 44 | 43 | 45 | 46 | 46 | 43 | 46 | 0.00% | 10.3/sec | 33.41 | 2.80 |
| 博客详情页接口… | 5 | 89 | 87 | 91 | 100 | 100 | 84 | 100 | 0.00% | 8.6/sec | 3.82 | 3.06 |
| 添加博客测试 | 3 | 64 | 51 | 94 | 94 | 94 | 48 | 94 | 0.00% | 15.4/sec | 3.23 | 5.99 |
| 总体 | 32 | 77 | 83 | 129 | 130 | 140 | 42 | 140 | 0.00% | 29.5/sec | 29.41 | 10.32 |
- Label:取样器或事务的名称,标识被测试的接口、操作或业务流程(如“登录接口测试”“用户信息查询接口”等)。
- #样本:该接口/事务被执行的总次数。
- 平均值:所有样本响应时间的算术平均值(单位:毫秒),反映整体响应速度的平均水平。
- 中位数:样本响应时间的中位数
- 90%百分位:样本响应时间的90%分位数,表示样本中有90%的个体响应时间小于等于该值(单位:毫秒),10%的个体响应时间大于该值
- 95%百分位:样本响应时间的95%分位数,表示样本中有95%的个体响应时间小于等于该值(单位:毫秒),5%的个体响应时间大于该值
- 99%百分位:样本响应时间的99%分位数,表示样本中有99%的个体响应时间小于等于该值(单位:毫秒),1%的个体响应时间大于该值(可以用来估计极限响应时间)
- 最小值:样本响应时间的最小值(单位:毫秒)。
- 最大值:样本响应时间的最大值(单位:毫秒)。
- 异常%:发生错误的样本数占总样本数的百分比,体现接口/系统的稳定性。
- 吞吐量:每秒处理的请求数(单位:requests/sec),反映系统的处理能力,数值越高承载能力越强。
- 接收 KB/sec:每秒从服务器接收的数据量(单位:KB/秒),体现下行数据的传输效率。
- 发送 KB/sec:每秒向服务器发送的数据量(单位:KB/秒),体现上行数据的传输效率。
由于登录事务包含登录接口测试和用户信息测试,那么一次登录事务的响应时间应该等于登录接口测试和用户信息测试的响应时间之后,你仔细观察会发现,从各个统计量中都能近似看出这一特点
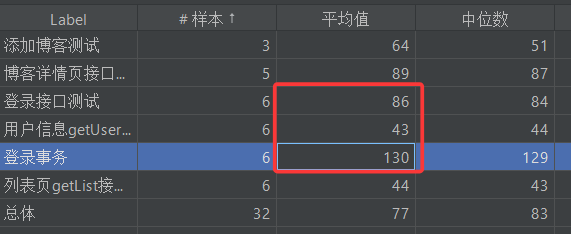
但是值得注意的是,我们实际看表的时候,往往不能先看平均值,因为它有一定的迷惑性,比如——我和科比合砍83分。因此我们往往更倾向于看中位数和90%分位数
CSV数据文件设置
我们要模拟多用户并发请求的场景,你首先得有多个账号吧,然后你得保证每个线程登的账号不一样吧。在前面的实验中,我们并发执行的多个线程用的都是张三这个用户的账号和密码,这显然是不符合实际情况的。那怎么解决这个问题呢?我们的解决思路就是,将测试用的多个用户的账号和密码都写入到一个csv文件中,像这样:
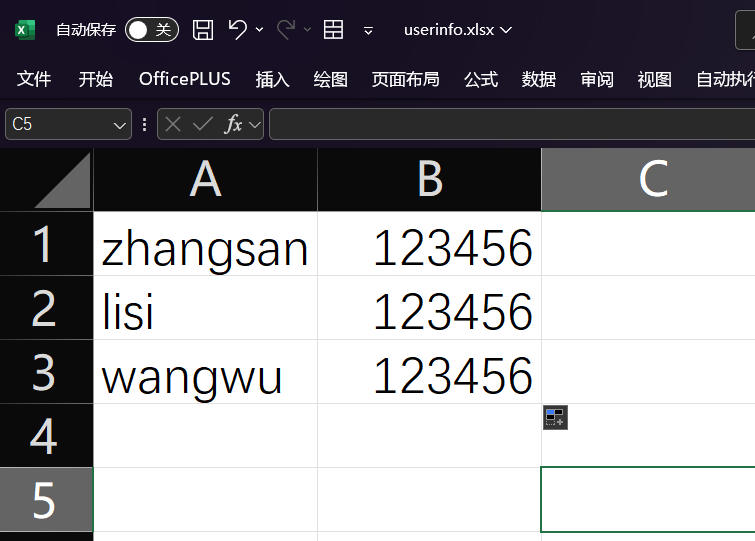
写完保存之后,我让线程每次登录之前,都动态地从这个csv文件中读入一个用户名和密码,这样不就能实现不同的线程登录不同用户了嘛
前面说的是我们解决问题的思路,那具体应该怎么实现呢?请接着往下看
(1)首先我们在线程组下创建一个csv数据文件设置元件
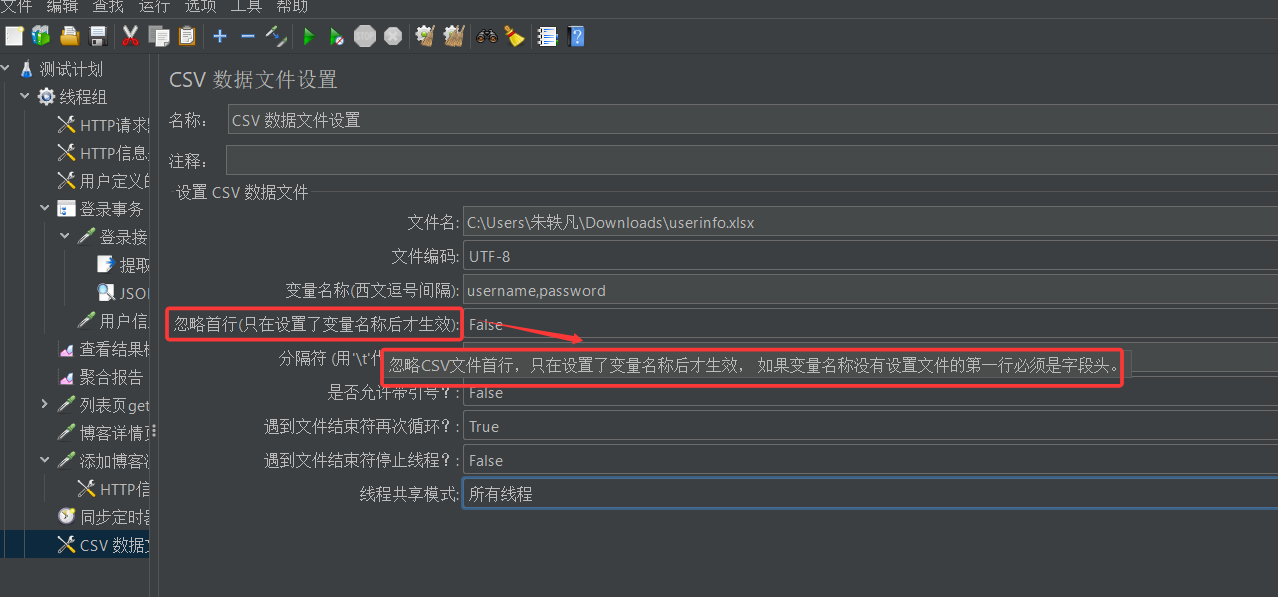
(3)配置csv数据文件设置元件
软件从我们指定的csv表格中读取用户的账号和密码之后,需要将其存储到对应变量中,我们将这俩变量的名字分别取作username和password(方便后续将其填充到请求报头中)
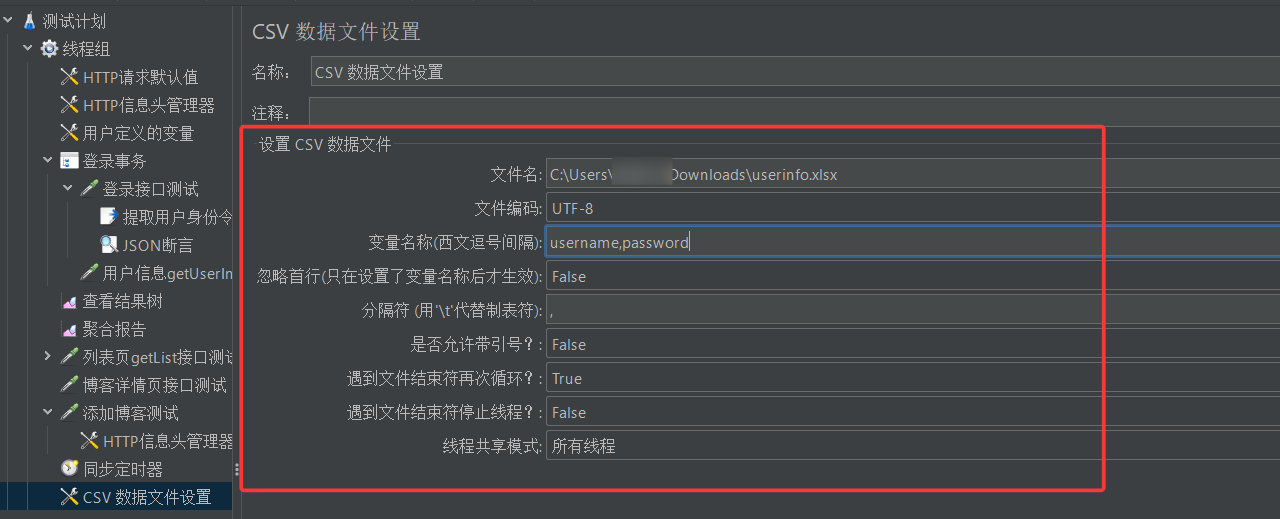
上面的配置都是啥意思?
- 文件名:填写要导入的csv文件的路径
- 文件编码:UTF-8
- 变量名称:从csv数据文件中读起的数据需要保存到的变量名。有多个变量时用逗号分隔
- 是否忽略首行:是否从csv数据文件第一行开始读取(有的表格中第一行写的是表头,不是有效数据,这种情况我们就可以忽略首行,从第二行开始读)
- 分隔符:输入的分隔符必须与csv数据文件中多列的分隔符保持一致
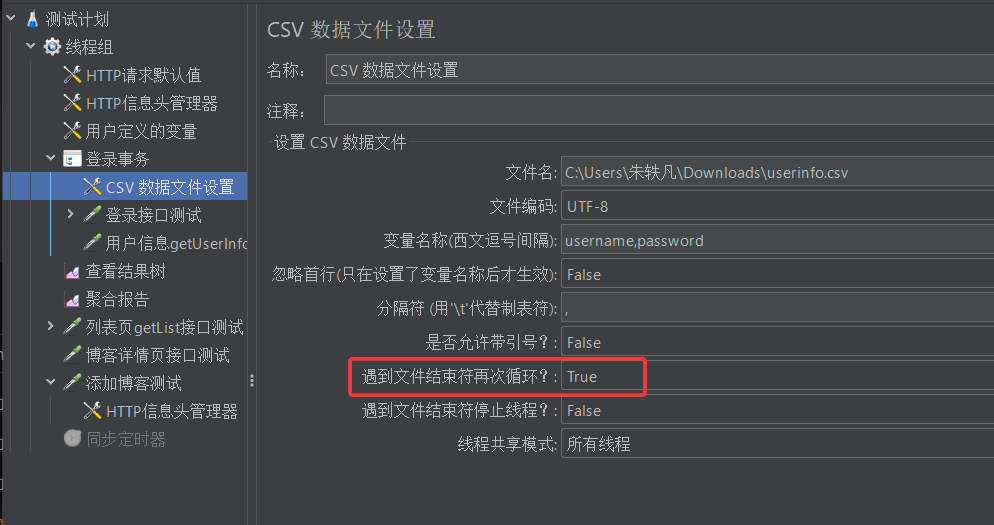
- 遇到文件结束符再次循环:
- 若选择为True,当数据不够的时候会从头取。
当然,如果你使用时突然忘了,也可用鼠标悬停在左侧属性上,他会给你跳出来一个弹窗,里面写的就是属性的含义
看完了属性说明,我们再来理解上图中的配置就不难了
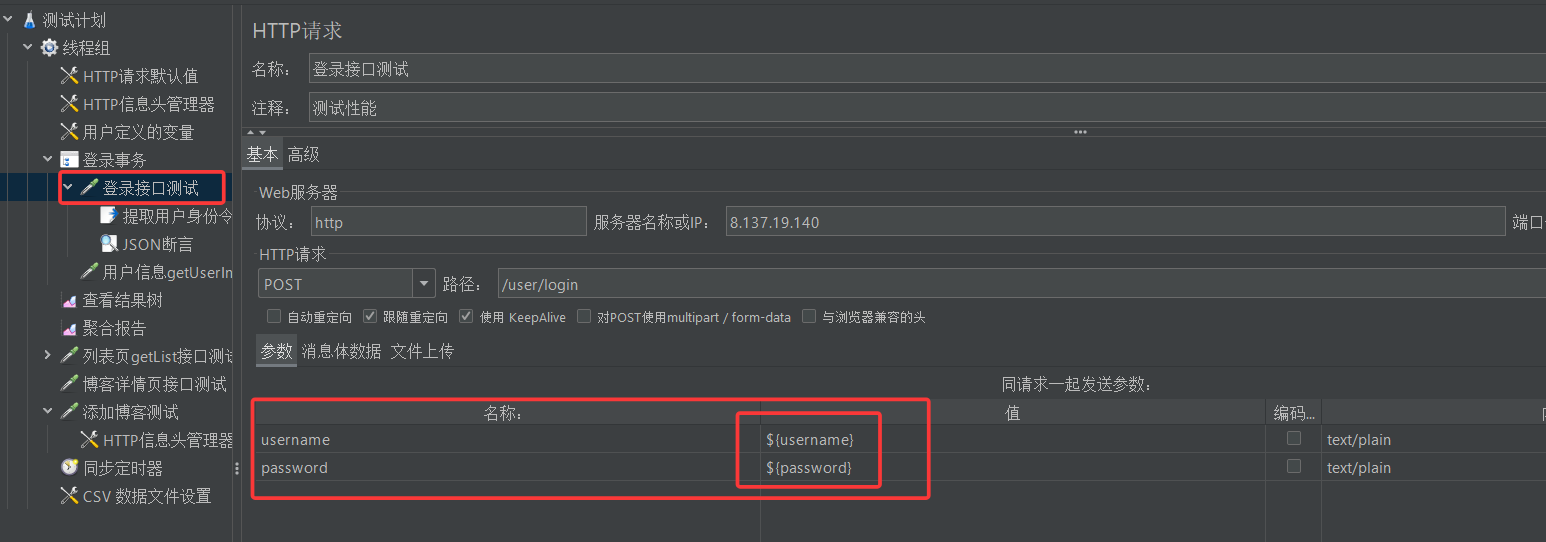
(3)更改登录接口取样器的配置
现在软件已经从我们指定的csv表格中读到了用户的账号和密码,保存在变量username和password中,现在我们要做的,就是将这俩变量的值填充到登录请求报头中的username和password字段中。
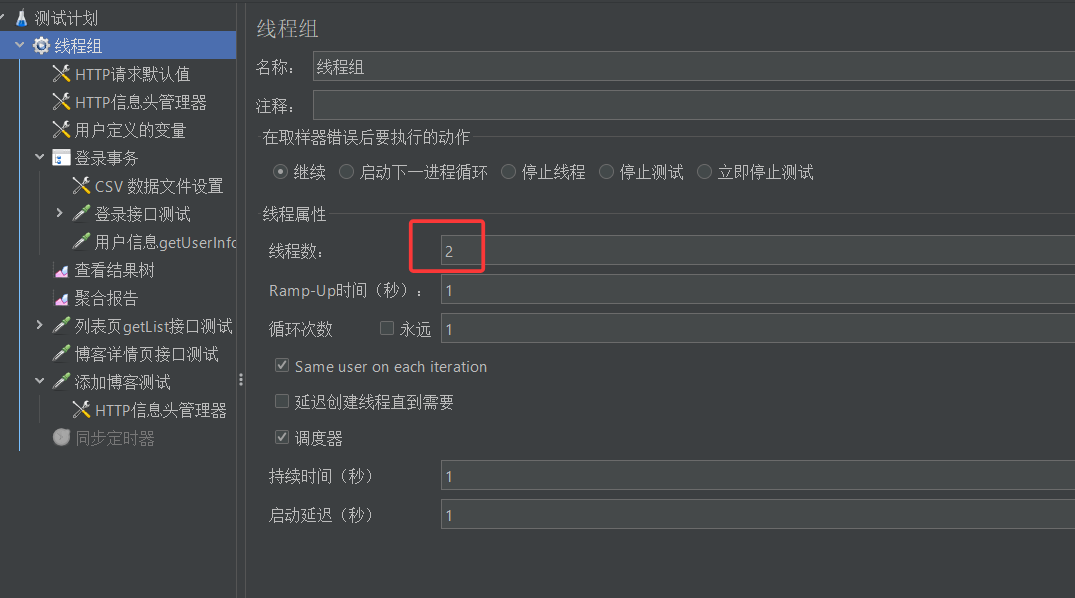
(4)将线程组中的线程数量设置为2
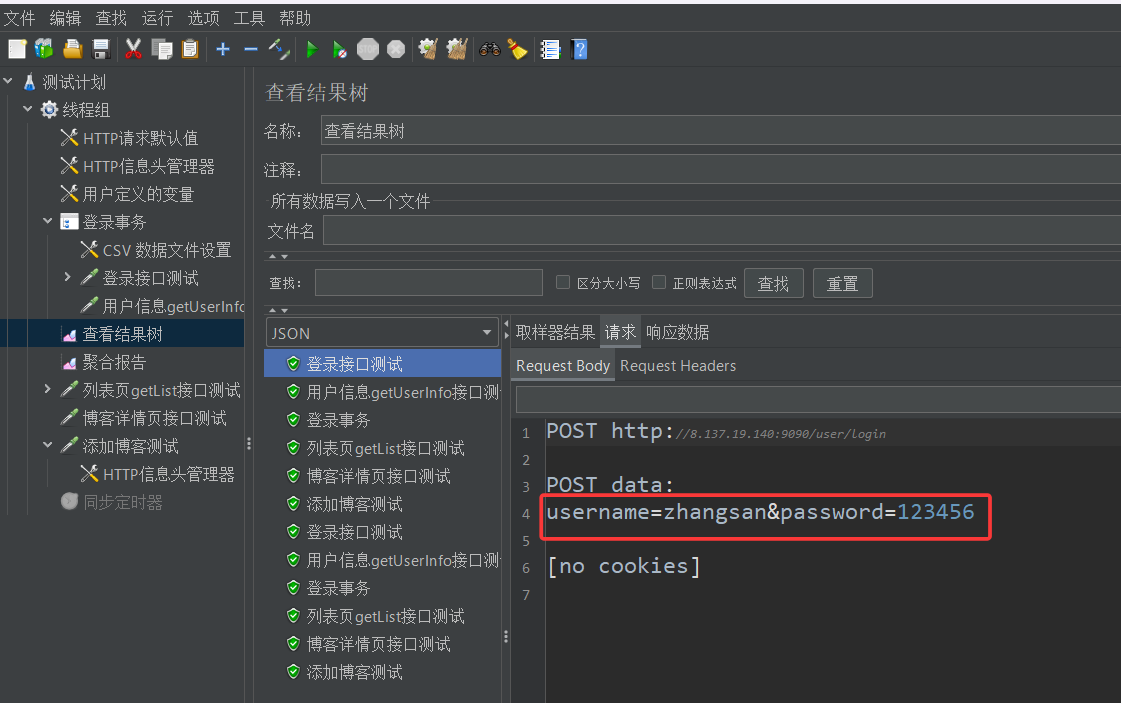
完成前面的设置之后,我们运行测试,然后测试完毕之后查看结果树,可以看到第一次登录测试,我们登录的是张三的账号,第二次就是李四的了
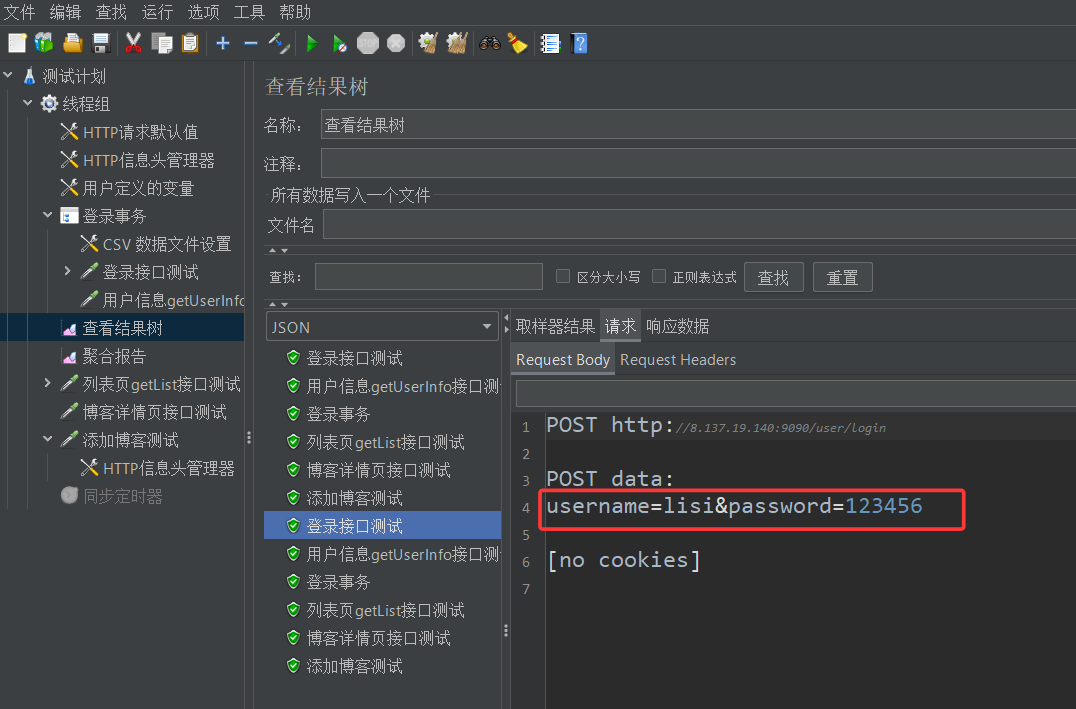
现在我有一个问题,假如说我表格中就俩账号,但是我测试的线程有4个,那运行的时候,前面俩线程肯定有号登,后面俩线程咋办呢?我们来实验看看结果
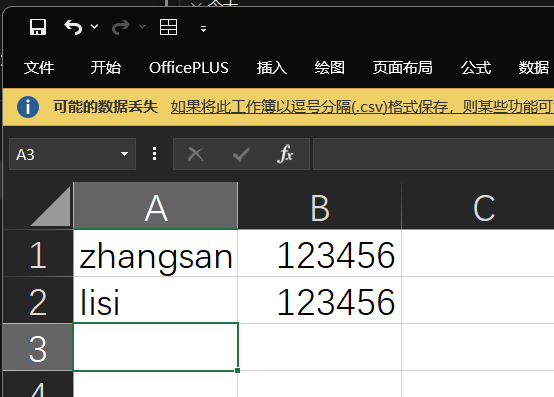
首先修改csv文件中的账号数量
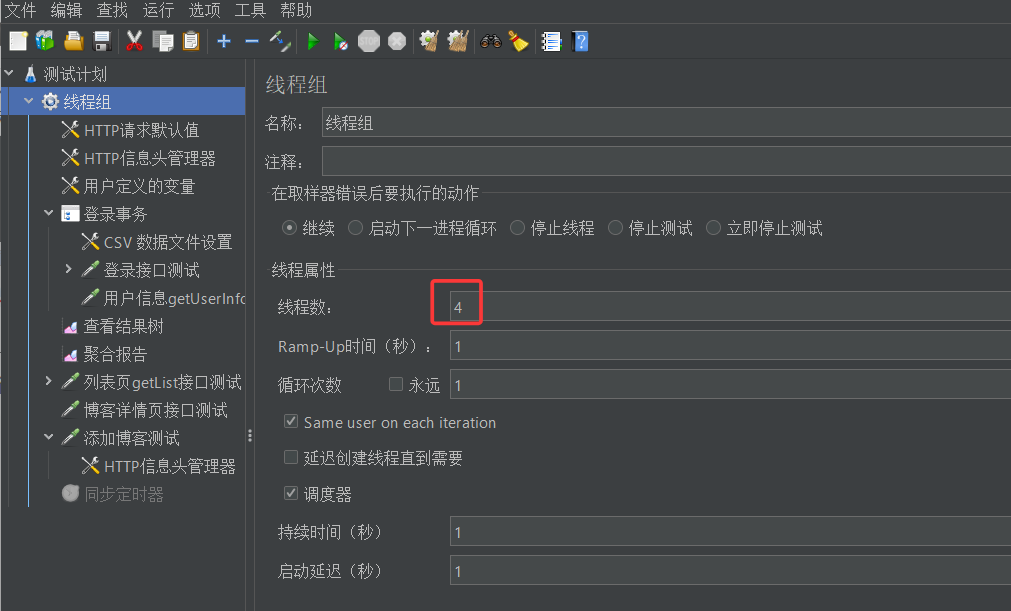
然后修改线程组中的线程数量
然后直接开始测试,结束之后查看结果树中的四个登录接口测试
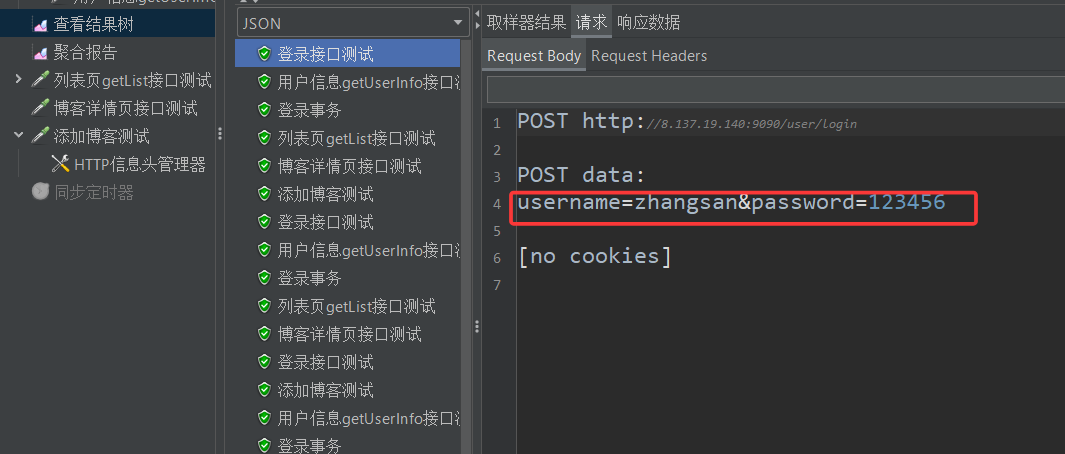
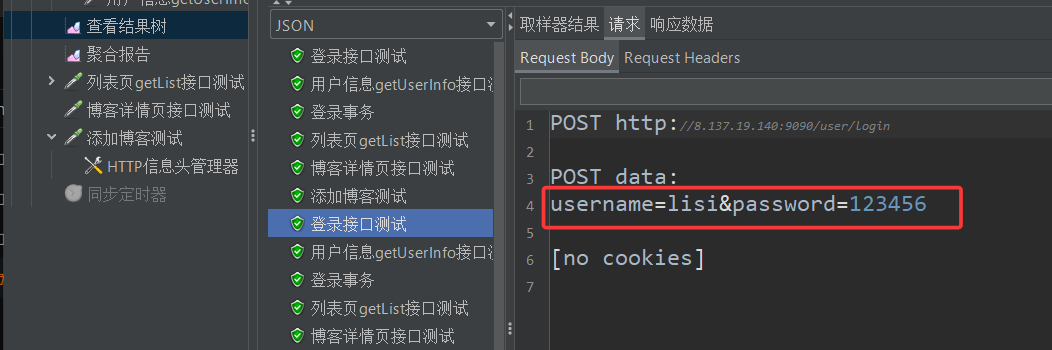
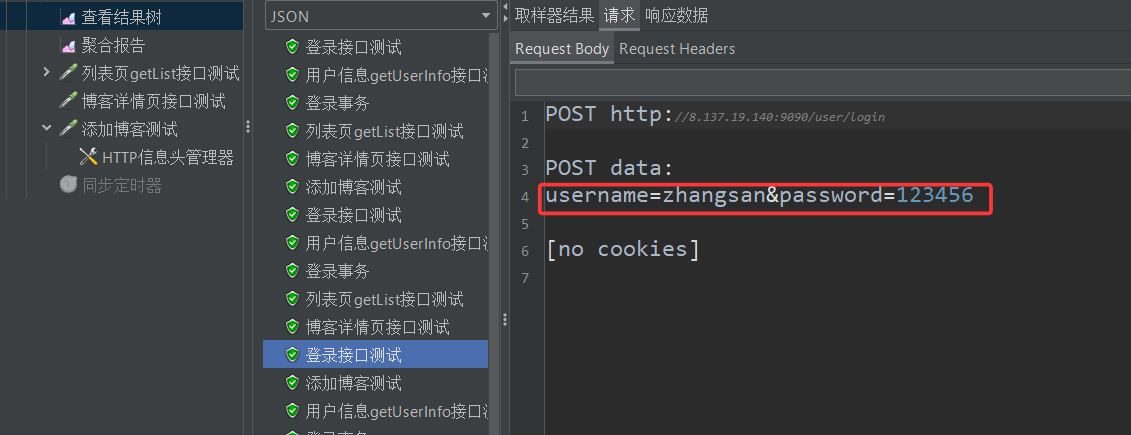
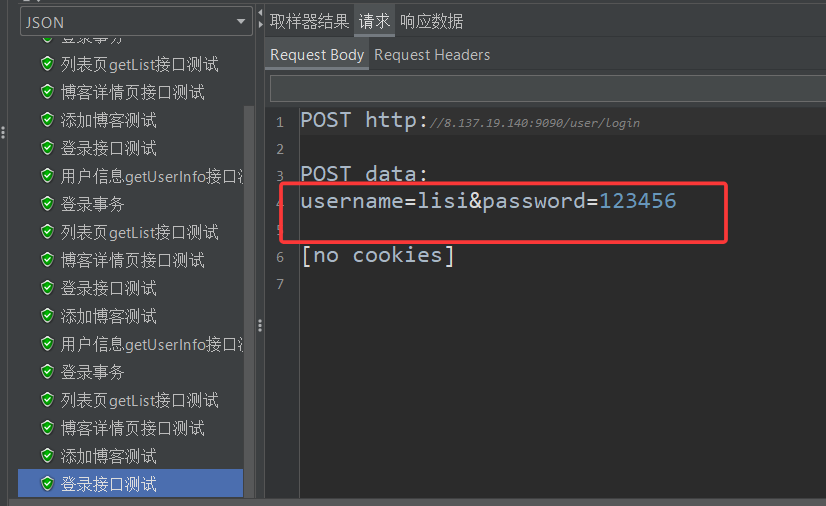
我们发现后面俩用的还是张三和李四这俩账号,为啥会这样呢?
主要是因为我们在配置csv数据文件设置时,启用了下面的选项
HTTP Cookie管理器
这玩意其实也是用来解决登录状态下的测试问题的。大家学过计网,肯定对cookie这玩意是不陌生的,它里面记录的是用户的个性化信息,也可以用来维持登录状态。
Cookie 和 token 的区别
看到这肯定有人会说,前面不是还说过一个 user_token_header 字段,这玩意不也是用来维持登录状态的吗?这俩有啥区别?
Cookie 和 user_token_header 都可以用来在客户端和服务器之间传递认证信息,下面是它们的区别与联系
共同点:
- 都用于身份验证和会话保持
- 都是通过 HTTP 头部传递信息
- 都能让服务器识别请求来自哪个用户
主要区别:
- Cookie:浏览器自动管理,服务器通过 Set-Cookie 设置
- token 头:需要手动在代码或测试工具中添加和管理
简单来说:
Cookie 和 token 解决的问题相似(认证),但实现方式不同。Cookie 更适合web环境,而 token 头更灵活,适合 API 和移动端应用。
如何通过HTTP Cookie管理器实现登录状态的保持?
首先我们创建一个新线程组,取名字为:带cookie的博客系统测试,然后我们在这个线程组下创建一个HTTP Cookie管理器
创建好之后,我们采用cookie管理器的默认配置,你啥都不用改
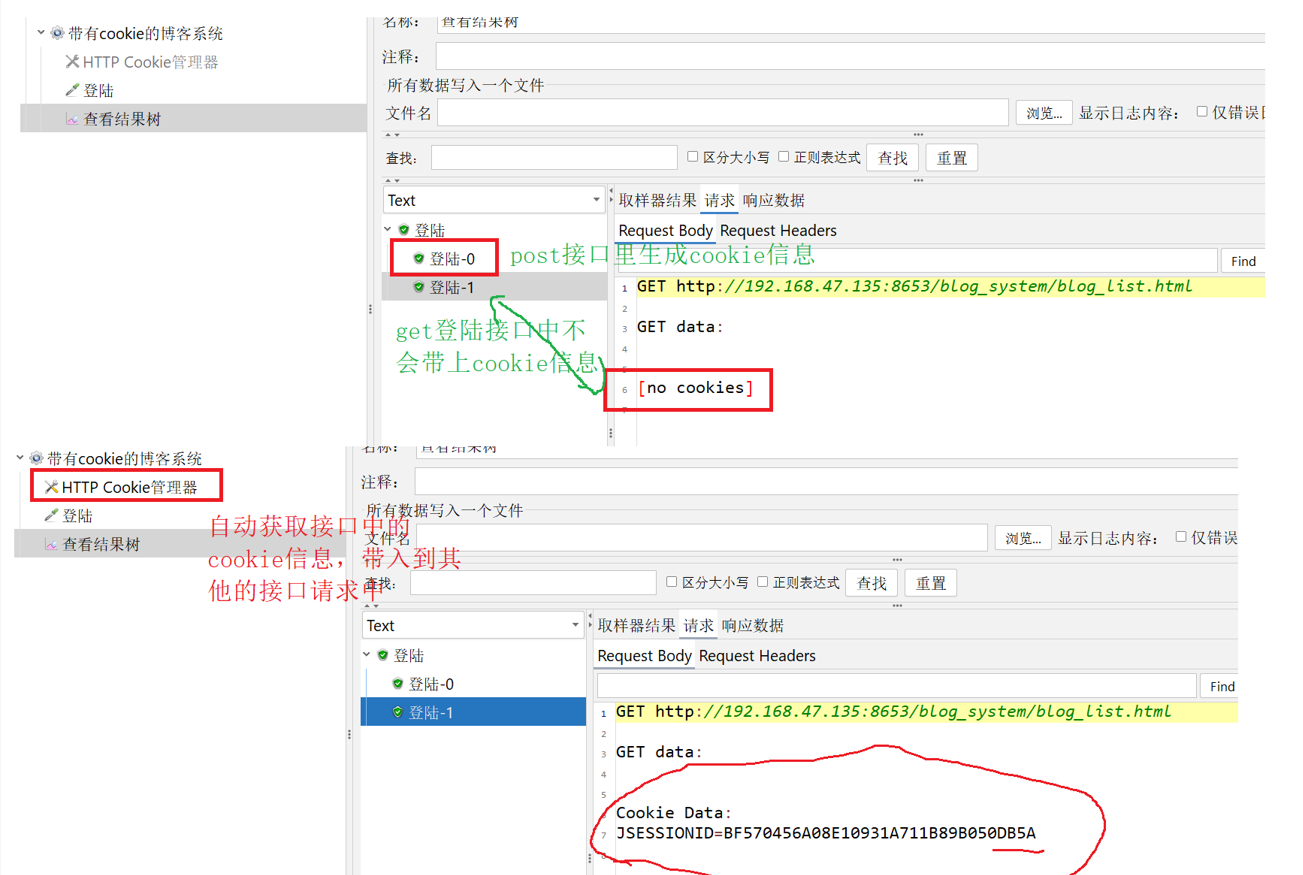
只要线程组下有这个HTTP Cookie管理器,线程组测试跑起来之后,JMeter就会自动存储服务器回送报文中的 Set-Cookie字段, 并自动添加到后续请求中
下图是一个简单的对照试验,图中第一个线程组没有HTTP Cookie管理器,第二个有。运行起来之后我们可以观察到,第二个线程组的第二次请求报头中,有cookie字段的信息,但是第一个线程组没有
JMeter插件
如何安装JMeter插件?
先去官网点击下载
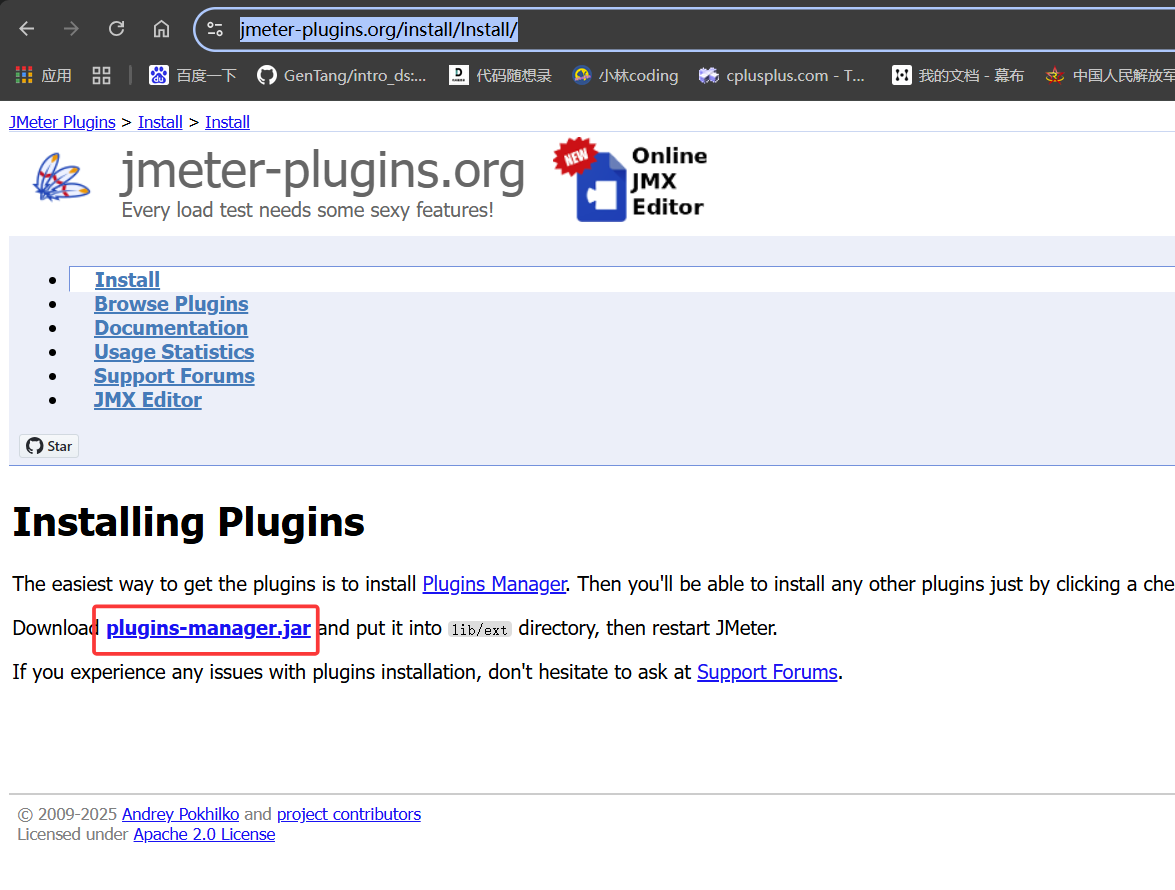
将下载的jar文件放到下图中的路径下
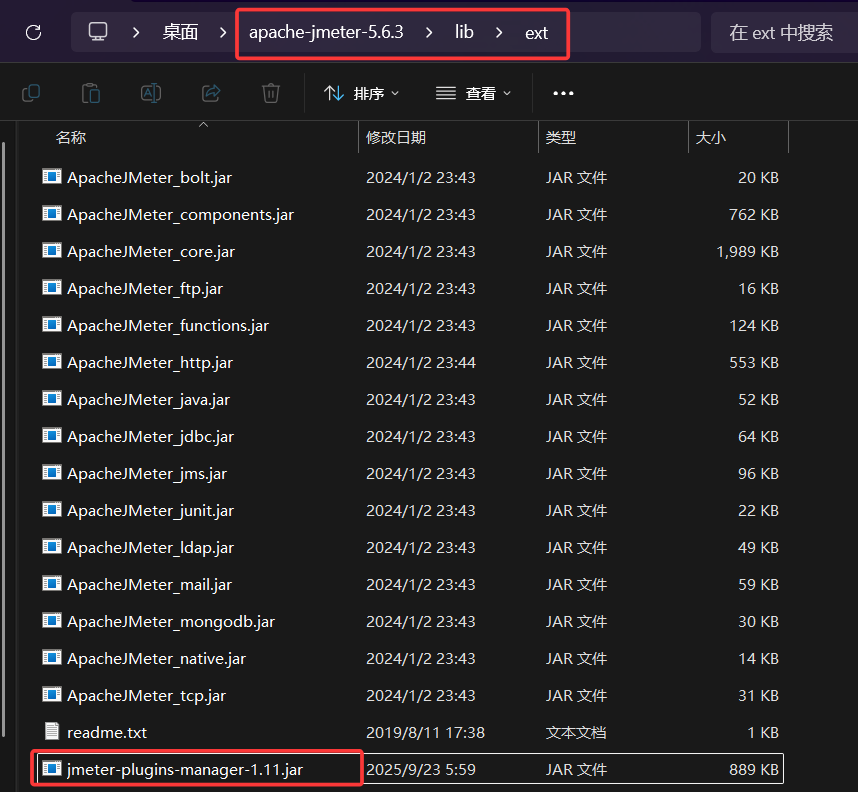
做完上面的操作之后,重启JMeter,我们就能看到JMeter的右上角出现了一个小蝴蝶
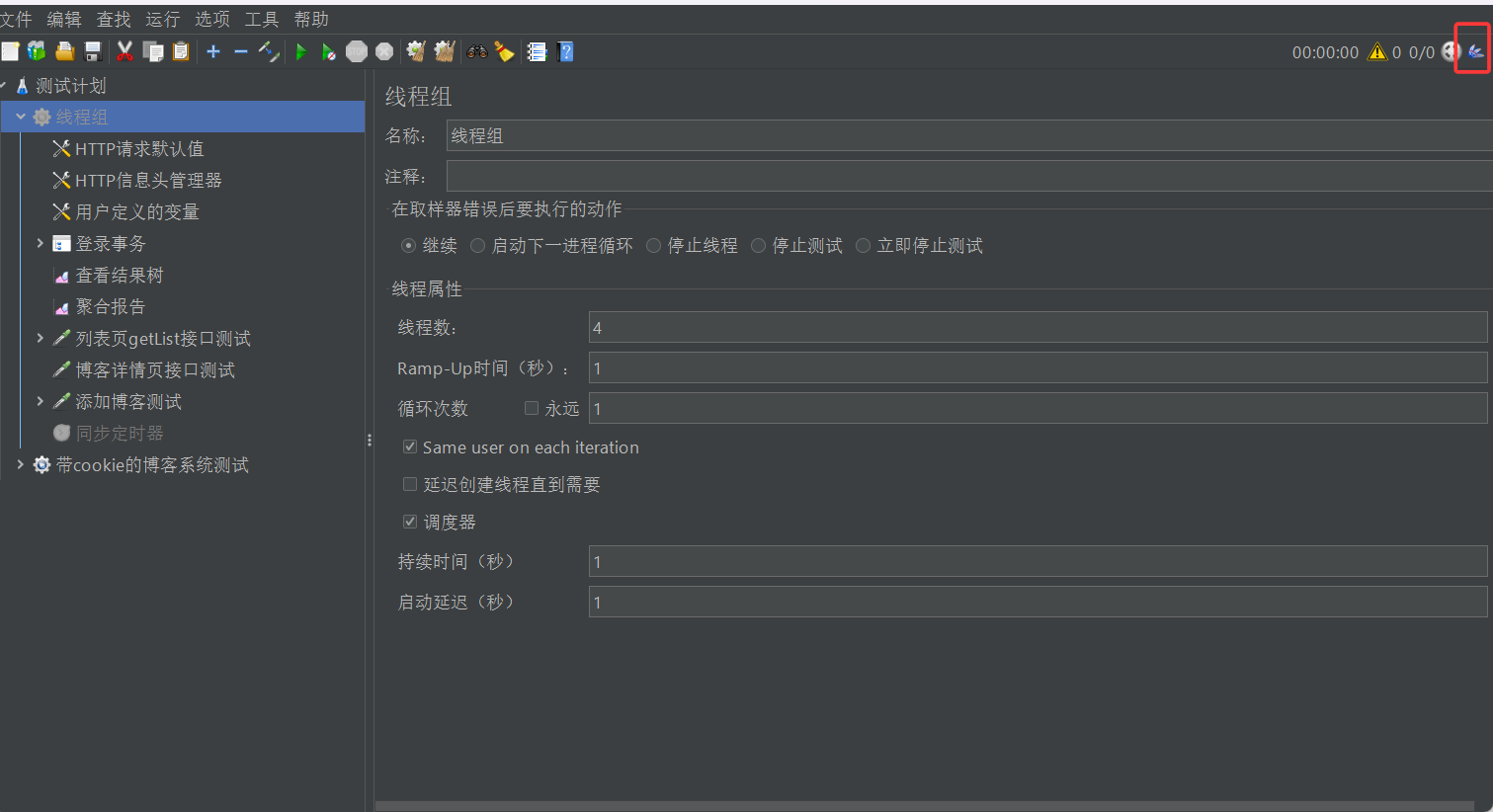
我们点击一下,就能进入到插件下载界面了,然后我们可以在available plugins栏的搜索框中输入我们要下载的插件关键字,找到之后再前面打勾,然后点击右下角的apply 按钮安装插件
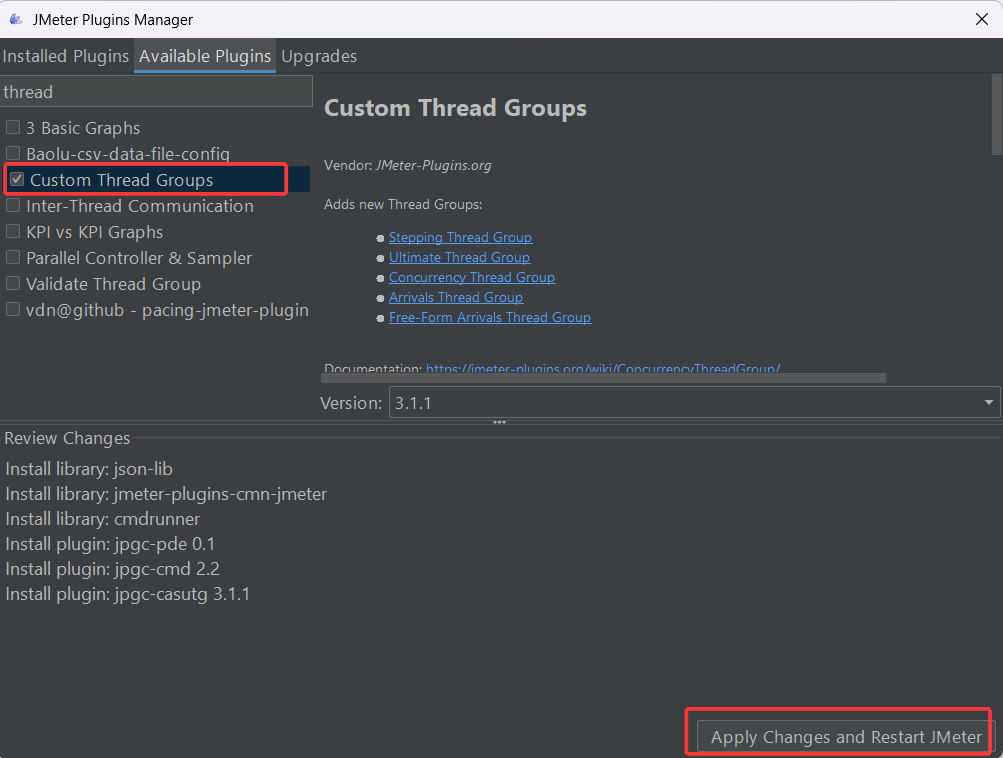
重启之后再次查看,发现我们的插件已经成功安装上了(我们要安装俩常用的插件,一个是线程组,一个是监听器)
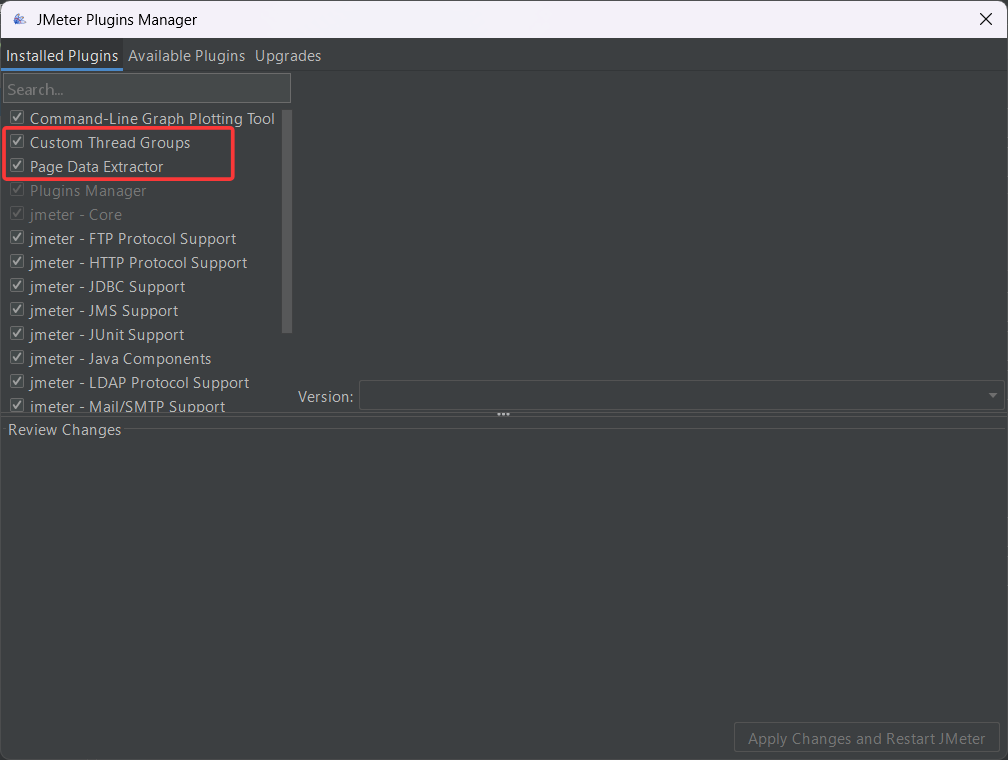
按照上面的步骤,请你依次下载这5个插件(方便我们后续进行压测)
梯度压测实验
梯度压测介绍
实际工作当中,领导给你布置的性能测试任务往往是梯度压测,。啥叫梯度压测呢?
比如领导要求测试的并发量是10000,这时候你直接上来给你的线程组设置线程数量为10000,然后运行,此时你的系统很有可能会直接崩掉,道理很简单,步子迈得太大,容易扯着蛋。
这时候我们就可以采用梯度压测的方法,第一次测试,我们的并发量设置为100,第二次加到200,第三次加到500,第四次加到1000,以此类推,通过多轮测试,逐步增加每次测试的并发量,将并发量逐步增加到10000。这么干,系统就不容易崩。这个也很好理解,你豪车在2s内就能将速度加到100公里,五菱宏光就没法做到这一点,你起步时猛踩油门,很有可能直接把车干冒烟了。但是如果我一步一步挂挡,花的时间多一点,但是我总能给我的小破车平缓地加速到100公里。
同时梯度压测还有一个很重要的好处——它可以更精准地定位性能拐点。为啥呢,你梯度压测是多轮测试,这就相当于我坐标轴中的采样点更多,那我就能够对性能曲线做更好的拟合
还有可能,你老板它自己都不知道这个系统的性能拐点和极限在哪,告诉你的并发量只是大概估计一下得到的结果,那这时候你盲目地直接上,就更容易把系统干废了。而如果使用梯度压测,你自己就能逐步探索出这个系统的性能拐点和极限。属于是除了麻烦之外啥都好
梯度压测的实现
JMeter并没有给我们提供梯度压测的选项,如果我们想要进行梯度压测,就必须要安装一个JMeter插件:Custom Thread Groups
按照前面所说的步骤安装好之后,我们就可以在测试计划中,添加一个梯度压测线程组了
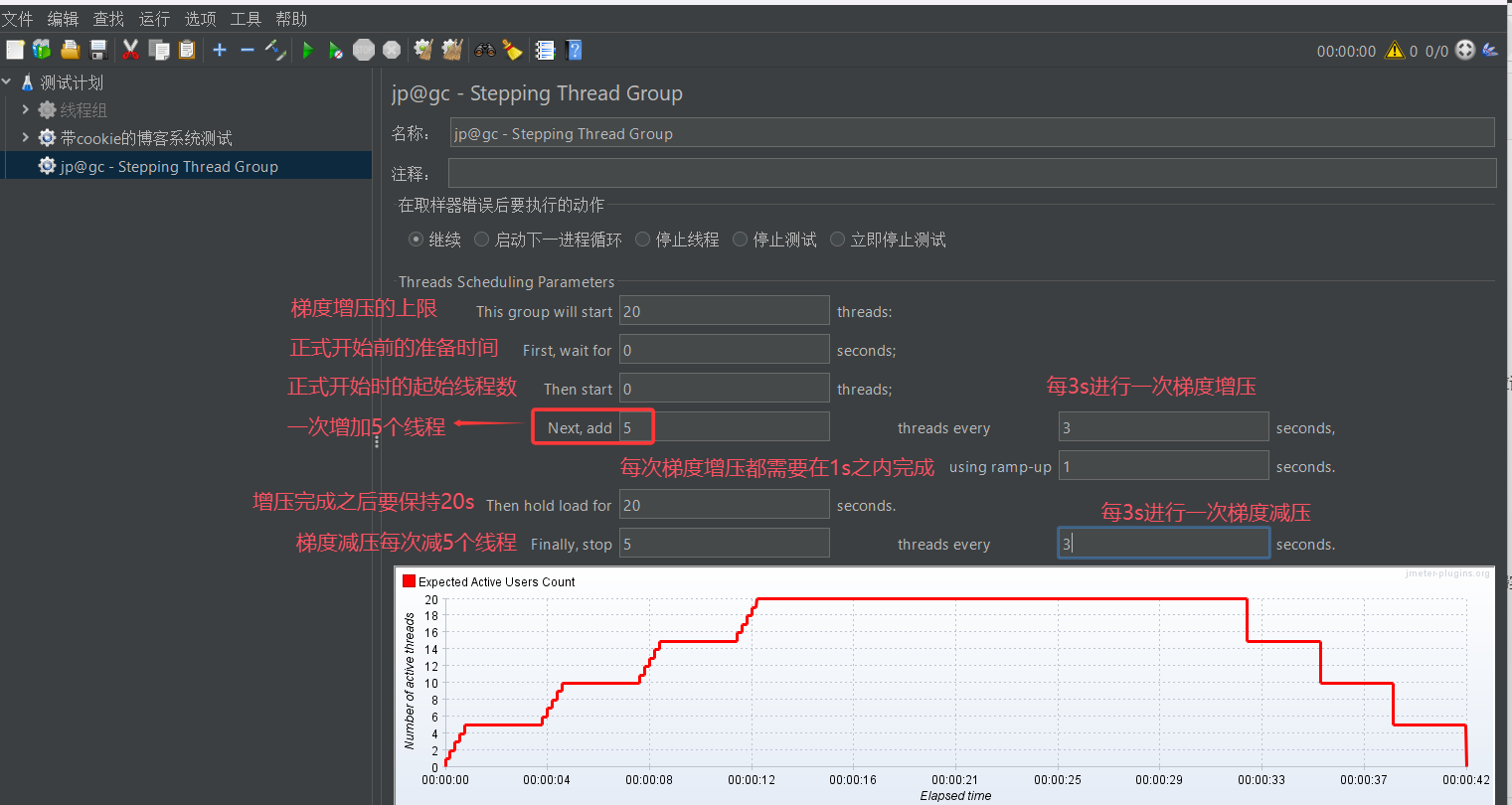
如何配置一个梯度压测线程组呢?可以看看下图中的解释
然后我们要向这个梯度压测线程组中添加三个监听器(图的最左下角那三个)
添加完之后,我们运行测试。测完之后,依次查看各个监听器
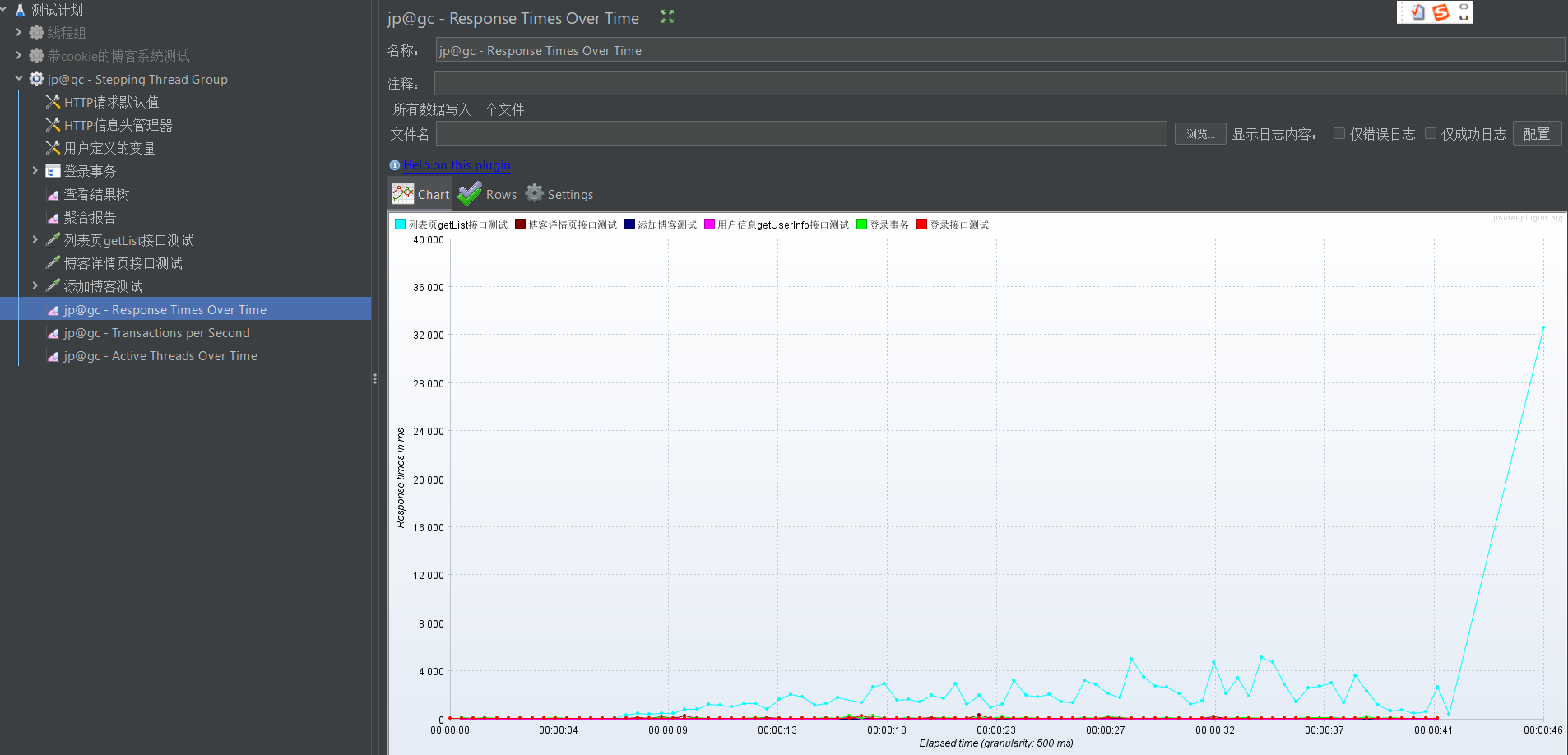
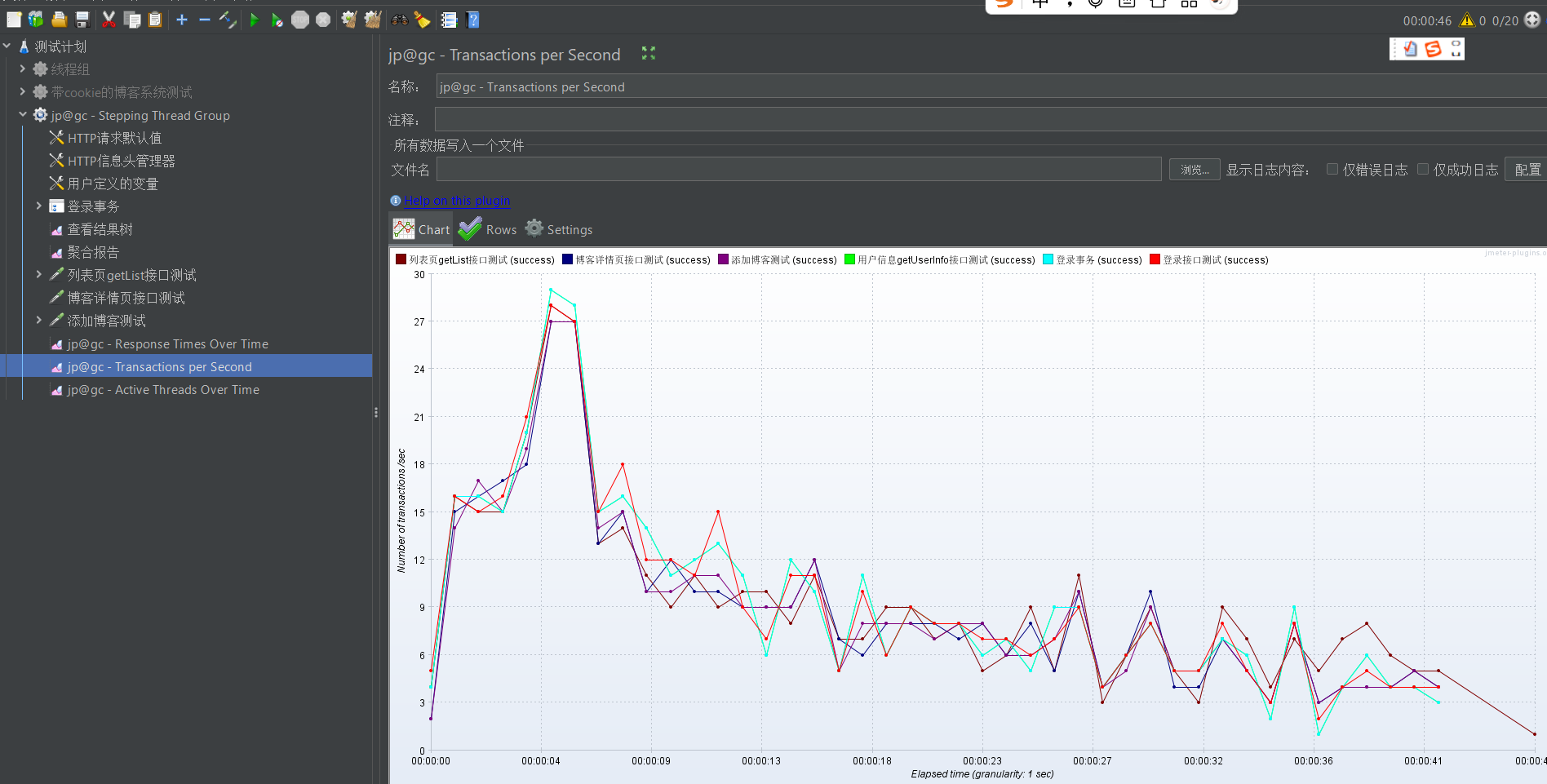
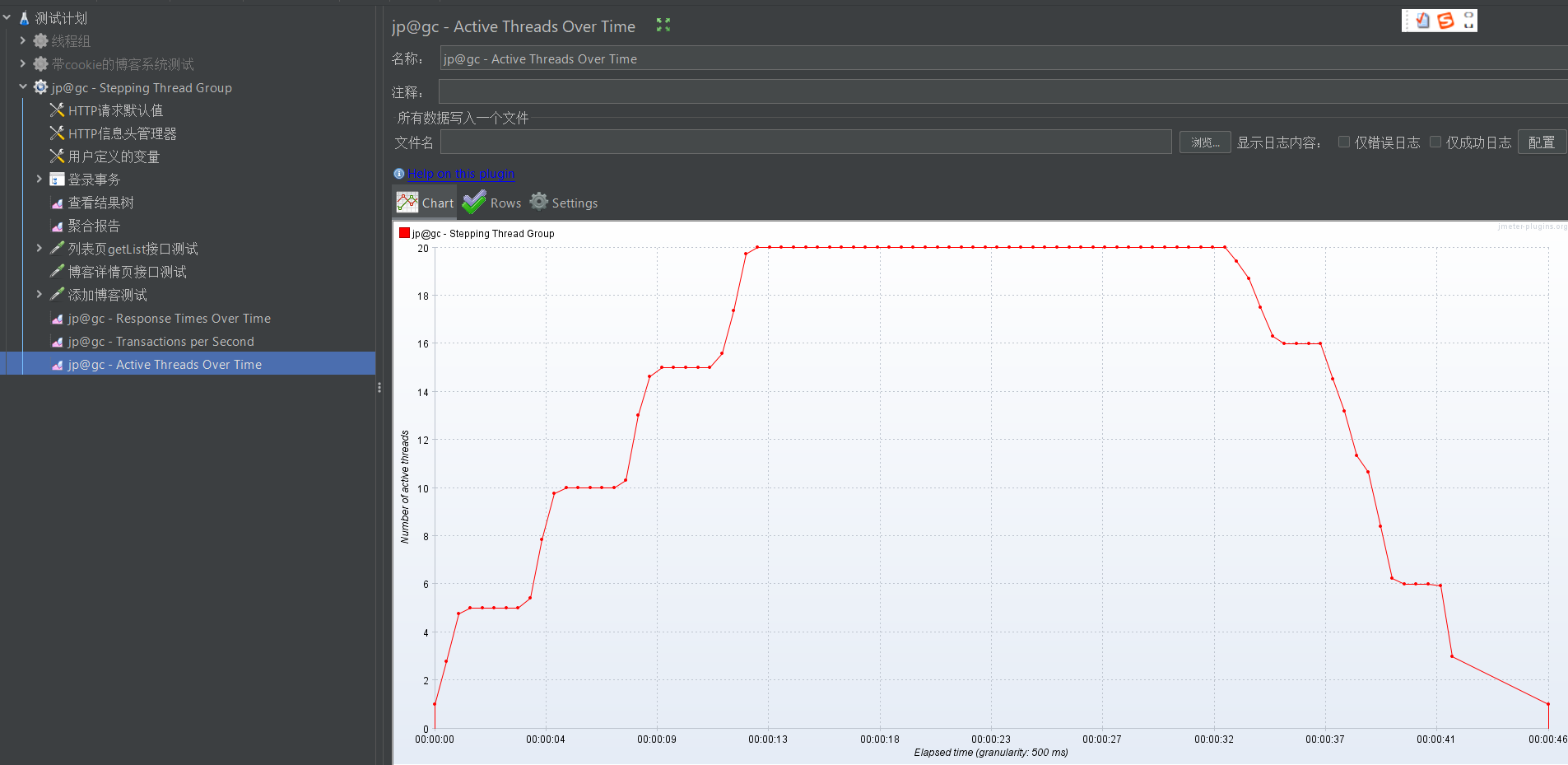
值得注意的是,吞吐量和响应时间往往是成反比的,即如果一次测试的吞吐量比较高,那它的响应时间往往很低,不信你可以自己去比较一下
测试报告
出具性能测试报告
注意,前面我们做的各种测试,都会被JMeter记录在一个jmx文件中。当你把JMeter关闭之后,下次还想接着测试,我们只需要打开对应测试项目的jmx文件就行
现在我们已经实现了一个完整的项目测试,要向上级出具我的测试报告了,这个测试报告怎么写呢?首先我肯定不能直接把我的jmx文件交给上级,因为它肯定看不懂,那怎么办呢?为了方便实用,JMeter给我们提供了一个自动化生成测试报告的接口,我们只需要执行一行命令,就能轻松地将一个jmx文件转化成一份测试报告:
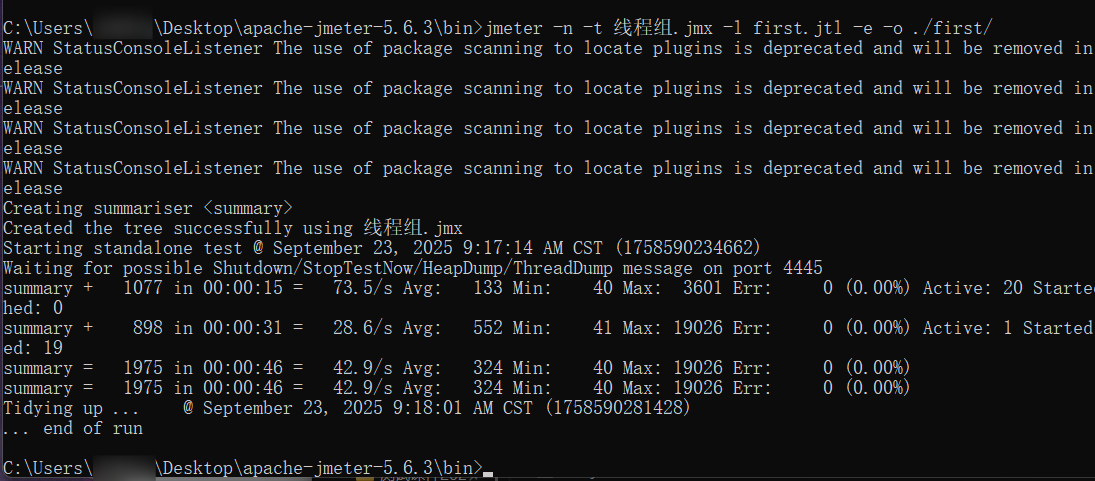
首先我们先打开cmd,然后切换到jmx文件的所在路径,输入命令jmeter -n -t 线程组.jmx -l first.jtl -e -o ./first/
- 该命令的解释如下
jmeter:启动 JMeter 程序的命令-n:表示以非 GUI 模式运行(无图形界面,适合在服务器或终端执行,节省资源)-t 第一个性能测试案例.jmx:-t指定要运行的测试计划文件,这里是当前目录下的第一个性能测试案例.jmx(JMeter 测试计划的扩展名)-l first.jtl:-l指定测试结果的输出文件,这里将结果保存为first.jtl(JMeter 结果文件格式,可用于后续生成报告或分析)-e:表示测试结束后生成 HTML 报告-o ./first/:-o指定 HTML 报告的输出目录,这里是当前目录下的first文件夹(需确保该文件夹不存在,否则会报错)
运行该命令后,JMeter 会在后台执行 线程组.jmx 中的测试计划,将详细结果保存到 first.jtl,并在测试完成后自动生成可视化的 HTML 报告,存放在 .../apache-jmeter-5.6.3/bin/first/ 目录中
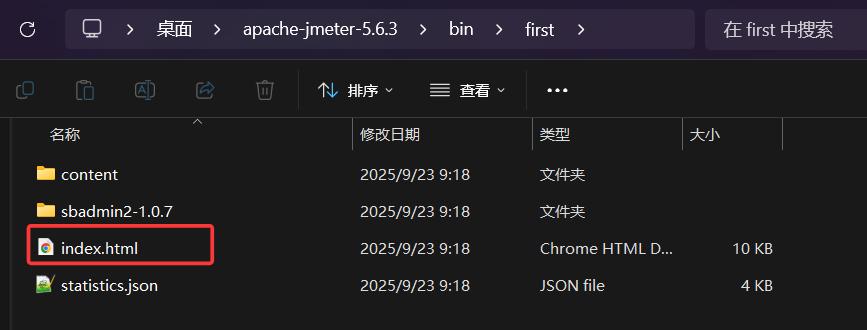
然后我们可通过浏览器打开该目录下的 index.html 查看报告。
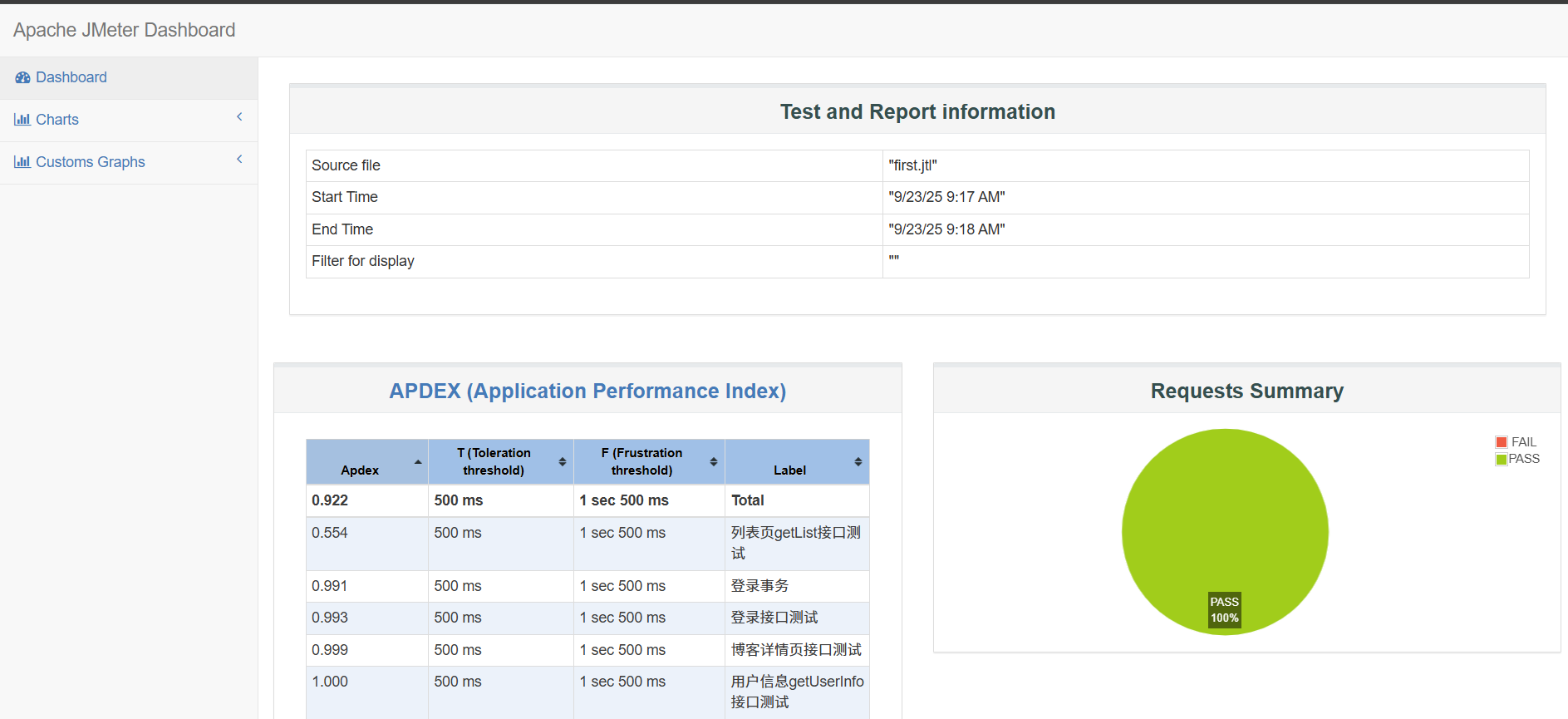
根据测试报告中的三大指标分析性能问题
指标1:响应时间
响应时间越短,性能越好。如果响应时间超过了要求,代表系统到了瓶颈
注意事项:我们要重点分析,在并发量为多少的时候,响应时间超标了,此时的并发量就是系统的瓶颈
响应时间变化的原因:
- 系统不稳定,有时快有时慢
- 随着并发压力变大而慢慢变慢,响应时间变高
指标2:错误率
高并发场景下,系统错误率越低,性能越好
要求:正确率99.99%=可靠,99.9999% = 非常可靠
错误率高的原因:
- 接口请求错误
- 服务器无法继续处理,达到了瓶颈(代码写的不好,内存泄漏、硬件资源等)
- 后端系统限流(系统里配置了不能超过多少并发)、熔断、降级
什么是熔断、降级?
- 熔断:防止系统因某个服务的故障而整体崩溃。当电商平台上用户支付时,收银台发现某个支付渠道,如微信支付失败率突增,超时严重,那么就可以临时把这个支付方式熔断掉
- 降级:主动关闭一些非核心功能,以确保核心功能的正常运行。某次腾讯视频挂了的时候,用户名称默认显示腾讯用户,这也是一种降级方式,用兜底名称做展示
指标3:吞吐量
吞吐量越大,性能越好;吞吐量相对稳定或者变低,可能系统达到了性能瓶颈
吞吐量变化规律:
- 波动很大:代表系统性能不稳定
- 慢慢变高,再趋于稳定:和并发量强相关。如果并发量小于吞吐量,慢慢增大并发量,吞吐量也会随之增加
- 慢慢变低,并发量也减少了:要么说明性能测试要结束了,并发减少;也可能是系统变的卡顿,从而导致响应时间变慢,导致单个线程发起的并发量变少

















 5560
5560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









