 MYSQL复合查询详解
MYSQL复合查询详解




文章目录
- 复合查询
- 基本查询回顾
- 我想查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J ,我该怎么做?
- 我想给所有的工人信息排序之后依次输出,排序的规则是:不同部门之间升序排列,同一部门内工资降序排列,我该怎么做?
- 我想给所有的工人信息排序之后依次输出,排序的规则是:按照年薪进行降序排序 ,我该怎么做?
- 我现在想查询工资最高的员工的名字和工作岗位,我该怎么做?
- 我现在想输出所有工资高于平均工资的员工信息,我该怎么做?
- 我现在想输出每个部门的平均工资和最高工资,我该怎么做?
- 我现在想输出所有平均工资低于2000的部门的部门编号以及他们的平均工资,我该怎么做?
- 我想打印出每种岗位的雇员总数以及该岗位的平均工资,我该怎么做?
- 多表查询
- 自连接
- 子查询
- 表的内联和外联
复合查询
基本查询回顾
我们的基本场景还是上次的数据库,数据库中有三张表,分别是emp、dept和salgrade
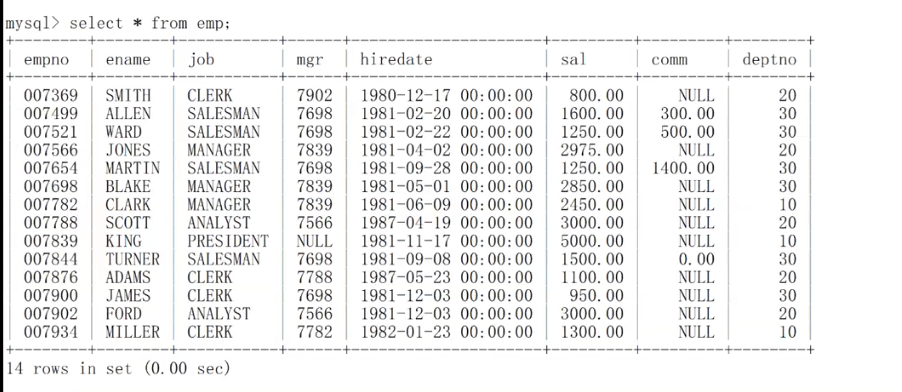

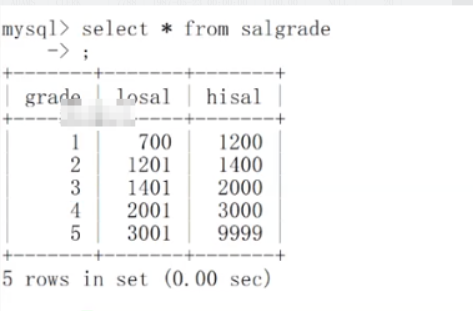
我想查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J ,我该怎么做?
select ename,sal,job from emp where (sal>500 or job ='MANAGER' ) and (substring(name,1,1)=J);
select ename,sal,job from emp where (sal>500 or job ='MANAGER' ) and ename like 'J%');
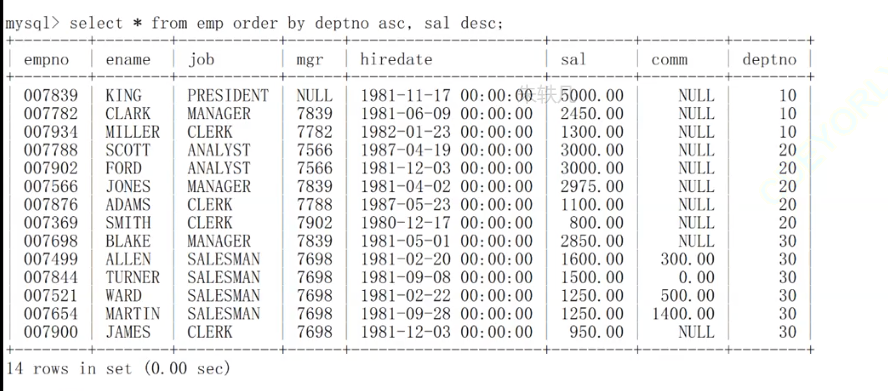
我想给所有的工人信息排序之后依次输出,排序的规则是:不同部门之间升序排列,同一部门内工资降序排列,我该怎么做?
select ename,sal,job from emp order by deptno asc, sal desc;
我想给所有的工人信息排序之后依次输出,排序的规则是:按照年薪进行降序排序 ,我该怎么做?
属性栏里面没有年薪呀,这怎么处理?
年薪=12*月薪+ 年终奖金
我们用12 * sal+comm来表示年薪,其中如果某条记录comm一栏为空,那么这样运算是会报错的
为了防止这种情况,我们用ifnull语句进行一个处理,修改变成
12 * sal+ifnull(comm,0),然后我们再将其命名为 total ,即
12 * sal+ifnull(comm,0) as total
即如果comm不为Null,结果就是12 * sal+comm
如果comm为Null,结果就是12 * sal+0=12*sal
select ename , 12*sal+ifnull(comm,0) as total from emp order by total desc;
我现在想查询工资最高的员工的名字和工作岗位,我该怎么做?
思路:先用select进行子查询出max(sal),再用拿到的max(sal)去查询工资等于max(sal)的员工
- select 是可以组合使用的,常见的就是子查询
- 子查询是“由内向外的”,也符合我们的语义理解!
select ename, job from emp where sal=(select max(sal) from emp);
请问为什么最后where语句不能直接写sal=max(sal)?
因为max(sal)的值需要通过select max(sal) from emp返回
我现在想输出所有工资高于平均工资的员工信息,我该怎么做?
- 先求平均值:select avg(sal) from emp;
- 输出所有工资高于平均工资的员工信息:select * from emp where sal > (select avg(sal) from emp);
由于所有员工的工资都是整数,而我avg(sal)求出来的平均薪资都是小数点后带好多位的浮点数,我现在就想用format将结果保留的小数少一些,这样感觉比较起来也好看些,但是最后发现结果不太对,这是为什么?
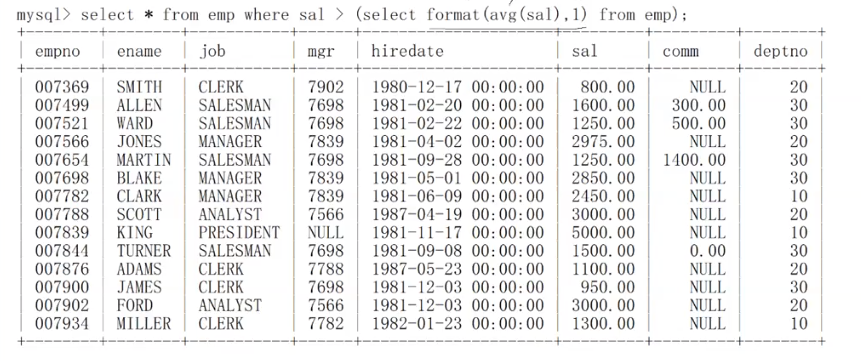
format存在的意义不是用来比较的!!而是用来显示的!!format应该放在最后,需要显示的时候在统一使用!
format只能用于最后输出结果时对数据进行截断,在中间比较的过程中,这些数的结构不会因为format发生改变
我现在想输出每个部门的平均工资和最高工资,我该怎么做?
select deptno, avg(sal), max(sal) from emp group by deptno;

上面有个问题,就是avg(sal)求出来的结果太长了,不好看,我想弄短一点,于是我们可以用format对其进行修饰format(avg(sal),2),将其控制在小数点后两位,整理之后就变成

我现在想输出所有平均工资低于2000的部门的部门编号以及他们的平均工资,我该怎么做?
第一步:我先不考虑小于2000的条件,我先把所有部门以及他们的平均工资都打出来:
select deptno, avg(sal) from emp group by deptno;
第二步:添加条件筛选:
select deptno, avg(sal) from emp group by deptno having avg(sal)<2000;
注意我们这时候用having而不用where,原因是什么?
我们后面条件筛选中会用到平均值avg(sal),所以要先执行第一步,让他把平均值先算出来,即这个条件筛选的执行时机,需要在select语句之后,所以用having
我想打印出每种岗位的雇员总数以及该岗位的平均工资,我该怎么做?
select job, count(*) 人数, avg(sal) 平均工资 from emp group by job
这里人数和平均工资分别是我给 count(*) 和avg(sal) 这两列取的别名
多表查询
多表查询的本质处理思路是什么?
通过笛卡尔积将多张表聚合成一张表
再对这张聚合表进行单表查询操作
解释这条指令的含义:select count(*) from dept, emp, salgrade;(其中dept, emp, salgrade是三个数据库)
我知道select count(*) from dept;是统计数据库dept的数据个数,那select count(*) from后面跟三个数据库,结果是不是就是三个数据库的记录条数之和呢?
不是,结果是三个数据库的记录条数之积(为什么?)
所谓的笛卡尔积,只是在数学层面,穷举了多个表的数据组合全部情况
这三个数据库做笛卡尔积之后,相当于是三个维度,三个维度的记录之间任意组合形成了最终的记录(维度1,维度2,维度3)
单纯的笛卡尔积往往不实用,因为有些组合是没有意义的,因此我们往往结合筛选使用
我现在想输出员工名+员工工资+所在部门的名字(员工名和员工工资属于表emp,而部门的名字属于表dept),我该怎么做?
- 第一步:先做笛卡尔积:
select * from emp,dept;
做完笛卡尔积,本质:是我们把所有相关的数据,聚合到了一张表,接下来的问题,就变成了一个单表查询!!!
所有的所谓的多表查询,首先要想到的是,将多张表看待成为一张表,所有的 mysql 查询,都变成了对一张表的查询!
我又是如何得知,需要哪些表呢??根据题面,追溯需要的数据都在哪些表里面 + 关联字段 - 第二步:从生产的复合表中,筛选出你要的行
select * from emp,dept where emp.deptno =dept.deptno; - 第三步:进一步筛选出你要的列
select emp.ename, emp.sal, dept.dname from emp,dept where emp.deptno =dept.deptno;
我现在想输出部门号为10的部门名,员工名和工资 (员工名和员工工资属于表emp,而部门的名字属于表dept),我该怎么做?
select dept.dname, emp.ename, emp.sal from emp , dept where dept.deptno=emp.deptno and emp.deptno=10;
我现在想输出每个员工的姓名、工资和工资级别(员工名和员工工资属于表emp,而工资级别属于表salgrade),我该怎么做?
第一步:先做笛卡尔积,形成复合表select * from emp, salgrade;
第二步:根据条件,筛选行select * from emp, salgrade where emp.sal between salgrade.local and salgrade.hisal;
第三步:筛选所需列select emp.ename , emp.sal, salgrade.grade from emp, salgrade where emp.sal between salgrade.local and salgrade.hisal;
自连接
什么是自连接?
自连接就是一张表自己和自己做笛卡尔积,俗称自交
为什么要自连接?
在公司的员工表中,包含这个公司所有的员工信息,在员工信息中有一栏mgr,记录着该员工的上级领导员工编号。我现在有一个问题,如果我想查找一个名叫FORD的员工的上级领导的编号和姓名,我该怎么做?
这时候我们有两种方法,第一种叫做子查询,即正常思路:
-
查找一个名叫FORD的员工的上级领导的编号(记录在员工的mgr属性栏中):
select msg from emp where ename = FORD;
-
根据刚刚查询出来的这个领导的编号,到数据库中查领导这个人
select ename, empno from emp where empno = 7566;

-
这两步合起来就是:
select ename, empno from emp where empno = (select msg from emp where ename = FORD);
然后我们的第二种方法就是自查询
首先认识一下这句话是啥意思:from emp leader, emp worker
这句话中给emp表起了两个别名
因为要先做笛卡尔积,所以别名可以方便识别
- 先让这张表自交:
select * from emp leader, emp worker - 在自交形成的复合表中,筛选出复合条件的行:
select * from emp leader, emp worker where worker.ename='FORD' and worker.mgr = leader.empno; - 筛选需要打印出来的列:
select leader.empno leader.ename from emp leader, emp worker where worker.ename='FORD' and worker.mgr = leader.empno;
提问:where的优先级不是很高吗,为什么3中where语句的emp两个重命名能立即生效呢?
这里是在from中对emp进行的重命名,优先级是最高的
子查询
什么是单行子查询?
单行子查询就是子查询的返回结果是一行记录
我想查询所有和smith同一部门的员工, 我该怎么做?
select ename from emp where deptno=(select deptno from emp where ename='SMITH')

什么是多行子查询?
就是子查询的返回结果是多行记录
其实MySQL 查询的所有的结果,无论是单行还是多行,单列还是多列,我们都可以将其看待成为一个 “表结构”!!MySQL 中一切皆表格!
在where条件语句中进行多行子查询
我现在想查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,最终结果不包含10号部门,我该怎么做?
- 首先我们要查询10号部门的工作岗位:
select job from emp where deptno=10; - 通过查询我们发现,10号部门的工作岗位貌似不止一个啊,这应该如何处理呢?
答案是用 where job in (…)来处理多值返回的情况,即
select * from emp where job in (select job from emp where deptno=10;)
最终的结果如下处理方案如下:select ename, job, sal, deptno from emp where job in (select job from emp where deptno = 10) and deptno <> 10;

我现在想显示工资比部门30的所有员工工资都高的员工信息,我该怎么办?
-
我先拿到部门30 的所有员工工资
select distinct sal from emp where deptno=30; -
条件语句中用关键字all:
select * from emp where sal > all(select distinct sal from emp where deptno=30);
我现在想显示工资比部门30的任意员工工资高的员工信息,我该怎么做?
如何理解“比任意员工工资都高”?(any和all的区别)
就是我可以只比部门30中的某一个人高,也可以比部门30中的所有人高
where sal > all(...);的意思sal是比括号里所有人的工资中最高的工资还要高
where sal > any(...);的意思sal是比括号里所有人的工资中最低的工资还要高
我们采用关键词any ,条件语句就可以写成:where sal > any(select distinct sal from emp where deptno=30);
总的指令就是:select * from emp where sal > any(select distinct sal from emp where deptno=30);
我现在想查询和SMITH的部门和岗位完全相同的所有员工(不包含SMITH),我该怎么做?
select ename from emp where
deptno=(select deptno from emp where ename='SMITH')
and job=(select job from emp where ename='SMITH')
and ename <> 'SMITH';
我们可以把上面的指令简写成:
select ename from emp where
(deptno, job)=(select deptno, job from emp where ename='SMITH')
and ename <> 'SMITH';
在from 语句中进行多行子查询
我想显示所有高于自己部门平均工资的员工的信息(姓名、所在部门、工资、部门平均工资)
-
输出各部门的名称及平均工资
select deptno avg(sal) from emp group by deptno -
将步骤1得出的表和emp作笛卡尔积,再加上条件得到一张复合表(每个员工都可以看到自己所在部门的平均工资了):
select * from emp, (select deptno, avg(sal) from emp group by deptno) as avg_t where emp.deptno= avg_t.deptno; -
再对上面的表进行进一步筛选,筛选出那些工资比所在部门平均工资多的员工:
select emp.ename, emp.sal, emp.deptno, avg_t.dt_avg
from emp, (select deptno, avg(sal) as dt_avg from emp group by deptno) as avg_t
where emp.deptno= avg_t.deptno and emp.sal>avg_t.dt_avg;
4.注意:我们上一步中打印出的是员工的部门号,并没有打印出部门的名称,部门的名称在另一张表dept中,为了打印出员工的部门名称,我们还需要将dept表与3形成的表进行一次笛卡尔积
select ename, sal, avg_t, dname
from dept ,
(select emp.ename, emp.sal, emp.deptno, avg_t.dt_avg from emp,
(select deptno, avg(sal) as dt_avg from emp group by deptno)
as avg_t where emp.deptno= avg_t.deptno and emp.sal>avg_t.dt_avg;)
as a where dept.deptno=a.deptno;
我想查找每个部门工资最高的人的姓名、工资、部门、最高工资 ,我该怎么做?
-
我先把每个部门的最高工资找出来:
select max(val) m_val from emp group by deptno; -
加上部门编号

-
然后将得到的这张表与员工表作笛卡尔积,使得每个员工的信息列中,也有自己部门的最高工资:
select * from emp, (select max(val) m_val from emp group by deptno) max_sal where emp.deptno = a.deptno -
在3得到的表中加上最后一个条件emp.sal = a.m_sal,筛选出最高工资的员工:
select * from emp, (select max(val) m_val from emp group by deptno) max_sal
where emp.deptno = a.deptno and emp.sal = a.m_sal;
- 人家要哪几列,我就给哪几列
我想显示每个部门的信息(包括部门名,部门编号,部门地址,这个部门包含的员工数量),我该怎么做?
- 求每个部门包含的员工数量:
select deptno, count(*) as 总人数 from emp group by deptno - 将dept表与上表做笛卡尔积,为每个部门添加一列信息列,表示该部门的员工数量:
select dname,dept.deptno,loc,总人数, from dept,
(select deptno, count(*) as 总人数 from emp group by deptno)
_count where dept.deptno=_count.deptno;
合并查询
我现在想将工资大于2500或职位是manager的人找出来
方法1:select * from emp where sal > 2500 or job='manager';
方法2:使用union语句
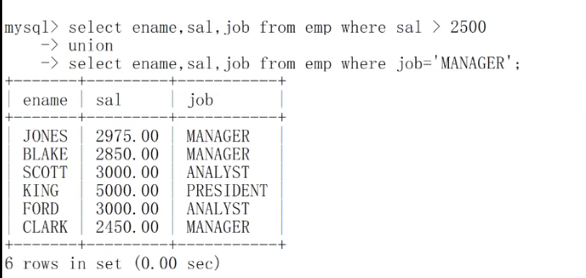
union和union all的区别是?
使用union时,会自动去掉结果集中的重复行,而使用union all则不会去掉
除了这条外,其他(用法)完全相同
表的内联和外联
在 MySQL 中,“内联”和“外联”通常指的是表连接(JOIN)操作中的两种核心类型,用于将多个表中的数据根据关联条件组合起来。它们的核心区别在于是否保留不满足关联条件的记录。
一、内连接(INNER JOIN,即“内联”)
内连接是最常用的连接方式,只保留两个表中满足关联条件的记录,不满足条件的记录会被过滤掉。
语法:
SELECT 列名
FROM 表1
INNER JOIN 表2
ON 表1.关联字段 = 表2.关联字段;
特点:
- 结果集仅包含两个表中“匹配成功”的记录(即满足
ON后条件的记录)。 - 可以简写为
JOIN(省略INNER)。
示例:
假设有 students 表(学生信息)和 scores 表(成绩信息),通过 student_id 关联:
-- 查询有成绩的学生信息(只显示既有学生记录又有成绩记录的行)
SELECT students.name, scores.math
FROM students
INNER JOIN scores
ON students.id = scores.student_id;
二、外连接(OUTER JOIN,即“外联”)
外连接会保留其中一个表(或两个表)中不满足关联条件的记录,未匹配的字段用 NULL 填充。根据保留的表不同,外连接又分为三种:
1. 左外连接(LEFT OUTER JOIN)
保留左表(FROM 后的表)所有记录,右表中不匹配的记录用 NULL 填充。
语法:
SELECT 列名
FROM 左表
LEFT OUTER JOIN 右表
ON 左表.关联字段 = 右表.关联字段;
可简写为 LEFT JOIN(省略 OUTER)。
示例:
-- 查询所有学生的成绩,包括没有成绩的学生(左表是 students,全部保留)
SELECT students.name, scores.math
FROM students
LEFT JOIN scores
ON students.id = scores.student_id;
– 结果中,没有成绩的学生的 math 字段会显示 NULL
2. 右外连接(RIGHT OUTER JOIN)
保留右表(JOIN 后的表)所有记录,左表中不匹配的记录用 NULL 填充。
语法:
SELECT 列名
FROM 左表
RIGHT OUTER JOIN 右表
ON 左表.关联字段 = 右表.关联字段;
可简写为 RIGHT JOIN。
示例:
-- 查询所有成绩对应的学生,包括成绩表中存在但学生表中不存在的记录(右表是 scores,全部保留)
SELECT students.name, scores.math
FROM students
RIGHT JOIN scores
ON students.id = scores.student_id;
3. 全外连接(FULL OUTER JOIN)
保留两个表中所有记录,不匹配的字段用 NULL 填充。
⚠️ 注意:MySQL 不直接支持 FULL OUTER JOIN,但可以通过 LEFT JOIN + RIGHT JOIN + UNION 模拟:
-- 模拟全外连接
SELECT students.name, scores.math
FROM students
LEFT JOIN scores ON students.id = scores.student_id
UNION -- 合并结果,自动去重
SELECT students.name, scores.math
FROM students
RIGHT JOIN scores ON students.id = scores.student_id;
三、核心区别总结
| 连接类型 | 保留的记录 | 语法关键词 |
|---|---|---|
| 内连接(内联) | 仅保留两表中匹配的记录 | INNER JOIN(或 JOIN) |
| 左外连接(外联) | 保留左表所有记录 + 右表匹配记录 | LEFT JOIN |
| 右外连接(外联) | 保留右表所有记录 + 左表匹配记录 | RIGHT JOIN |
| 全外连接(外联) | 保留两表所有记录(MySQL 需模拟) | 无直接支持,用 UNION 模拟 |
根据业务需求选择合适的连接方式,例如:需展示“所有用户及其订单”用左连接(用户表为左表),需展示“所有订单及对应用户”用右连接(订单表为右表)。
表的内连接
什么叫做内连接?
内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,只保留两个表中满足关联条件的记录,不满足条件的记录会被过滤掉。我们前面学习的查询都是内连接,也是在开发过程中使用的最多的连接查询。
内连接的格式
select ... from 表1,表2 where ...select ... from 表1 inner join 表2 on 链接条件1 and 链接条件2 (inner join表示内连接)
内连接举例:我想显示SMITH的名字和部门名称,我该怎么做?
格式1: select ename, dname from emp, dept where emp.deptno=dept.deptno and emp.ename='SMITH';
格式2:select ename, dname from emp inner join dept on emp.deptno=dept.deptno and emp.ename='SMITH';
表的外连接
什么叫做外连接?
外连接(Outer Join)是数据库中连接操作的一种,它用于结合两个或多个表中的记录,即使某些记录在关联条件下在某个表中没有匹配项,也会将这些记录包含在结果集中。
外连接主要分为左外连接(Left Outer Join)、右外连接(Right Outer Join)和全外连接(Full Outer Join)
什么是左外连接?
左外连接会返回左表中的所有记录,以及右表中与左表匹配的记录。
如果右表中没有与左表记录匹配的项,则右表对应的字段值将显示为 NULL。
举例:下图是两张表

下面我们根据id将两张表合成一张表,合成时使用内连接和左外连接的对比如下

什么是右外连接?
把左外连接定义里面的左改成右,右改成左,就是右外连接的定义
在如下图所示的两张表中,我想查询所有学生的成绩,即使学生没有成绩,我也想将这个学生的成绩显示出来,我该怎么做?

使用我们的左外连接(为什么?)
即使学生没有成绩,我也想将这个学生的成绩显示出来,对应左外连接连不上时,将右表数据置null
左外连接格式:select … from 表1 left join 表2 on 条件1 and 条件2
解决方案:select name, grade from stu left join exam on exam.id=std.id;
我想查询所有成绩,即使该成绩没有对应的学生,我也想将这个成绩显示出来,我该怎么做?
解决方案:select name, grade from stu right join exam on exam.id=std.id;
我想列出部门名称和这些部门的员工信息,同时列出没有员工的部门 ,我该怎么做?
select demp.dname, emp.ename from dept left join emp dept on emp.deptno=dept.deptno;

















 4741
4741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









