




 本文介绍了如何通过线程池优化一个使用JNI调用人脸检测SDK的Java应用。原本每次调用都会加载许可证和创建大对象,导致响应慢。优化措施包括将算法流程封装为Callable任务,定制线程预加载许可证和对象,以及使用ThreadPoolExecutor配置自定义线程工厂。优化后,接口耗时降低60%,并发性能提升。线程池核心线程数设定为CPU核心数+1,拒绝策略选择AbortPolicy防止主线程执行任务时缺少必要对象。
本文介绍了如何通过线程池优化一个使用JNI调用人脸检测SDK的Java应用。原本每次调用都会加载许可证和创建大对象,导致响应慢。优化措施包括将算法流程封装为Callable任务,定制线程预加载许可证和对象,以及使用ThreadPoolExecutor配置自定义线程工厂。优化后,接口耗时降低60%,并发性能提升。线程池核心线程数设定为CPU核心数+1,拒绝策略选择AbortPolicy防止主线程执行任务时缺少必要对象。
场景:
现有一个人脸检测算法sdk包(C++),使用java中的jni调用该sdk提供出java可直接调用的接口,并打包成jar包(作为依赖包)供业务系统调用。
人脸算法执行流程为:(1)加载lisence -> (2)初始化FaceDetect、FaceAttribute 等对象 -> (3)传入图片数据进行检测 。 其中第一步加载lisence在整个系统的生命周期中,只需要加载一次就行。第二步需要创建的对象比较大。
初始情况:直接调用jar包接口,每次业务系统调用都会进行加载lisence,创建初始化FaceDetect、FaceAttribute对象。这样造成接口执行耗时久,大对象频繁创建销毁。
优化:
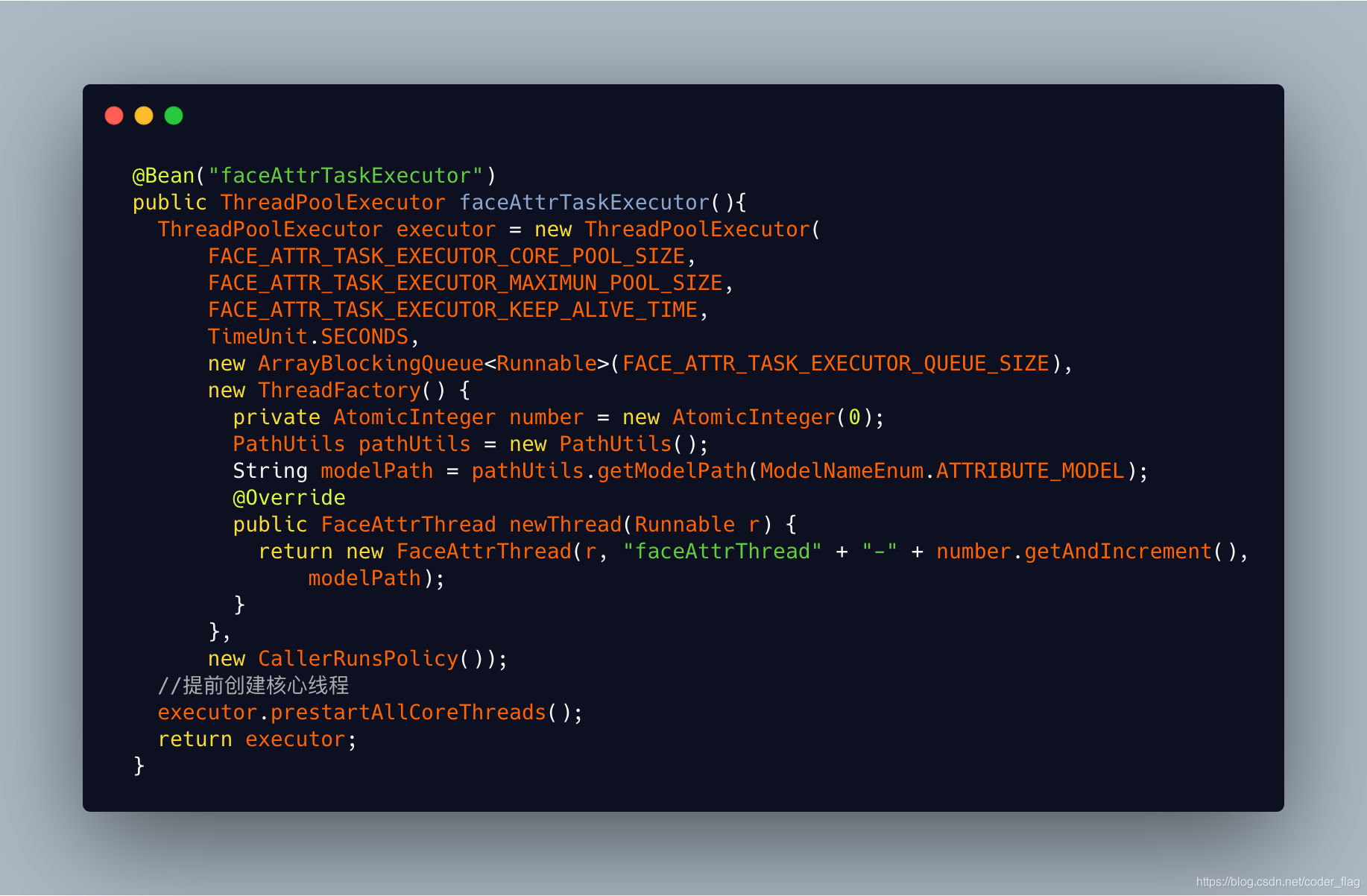
(1)依赖包中的算法执行流程,封装成一个Callable<FaceAttrInfo[]>,可以给线程池调用,使用Callable接口是因为需要返回算法执行后识别出的人脸结果。

(2)继承Thread,定制自己的线程,在线程初始时,加载lisence,创建FaceDetect、FaceAttribute 对象。

(3)在业务系统调用处,使用ThreadPoolExecutor 创建线程池,其中通过ThreadFactory参数指定我们要创建的线程为上述第二步自定义的线程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









