




 本文探讨了Transformer模型中Self-Attention机制的改进,提出了DenseSynthesizer、RandomSynthesizer和FactorizedModel等变体,旨在减少计算复杂度。实验表明,这些方法在效果上虽稍逊于Vanilla Transformer,但在翻译和生成任务中仍有竞争力,而在GLUE任务上效果下降。此外,Synthesizer在运行效率上优于Vanilla Transformer和CNN。
本文探讨了Transformer模型中Self-Attention机制的改进,提出了DenseSynthesizer、RandomSynthesizer和FactorizedModel等变体,旨在减少计算复杂度。实验表明,这些方法在效果上虽稍逊于Vanilla Transformer,但在翻译和生成任务中仍有竞争力,而在GLUE任务上效果下降。此外,Synthesizer在运行效率上优于Vanilla Transformer和CNN。
1. 文章简介
前两天在看Google的Transformer Quality in Linear Time突然想起来这篇long long ago之前看过的transformer的变体,因此这里就回来考个古,顺便加深一下理解吧。
这篇文章同样是Google提出来的一个工作,不过是在20年了。某种程度上,确实还是非常的佩服Google的,因为考虑到近年来Transformer在NLP以及CV领域的各种猪突猛进,主流的工作感觉都是在Transformer的基础上进行工作迁移,结构优化以及各种细化研究,但是Google自己却总感觉对于Transformer本身不太满意,时不时就搞出一篇文章来想要从根本上推翻transformer的基础架构。
这篇Synthesizer就是其中之一,他的关注点在于Transformer自身的self-attention的权重计算部分,考察 Q Q Q和 K K K的点积计算attention权重的方式是否是真的必要的。如果直接给出一个与输入token无关的全局self-attention权重是否同样能够生效,感觉实在考察self-attention结构之所以有效的更为本质的原因。
结论而言,文章认为 Q Q Q和 K K K的点积计算attention权重的方式似乎效果并不是那么的重要,直接训练权重都能够获得不弱于sota的结果,甚至直接随机权重然后fix都能得到一些过去的结果……
不过要想要达到sota,似乎attention权重还是要和输入权重关联起来才能达到效果的最优。
Anyway,当时看这篇文章感觉还是很震惊的,不过两年过去了,感觉似乎这篇文章相关的结构也没有被大幅利用起来,整体来说还是vanilla的transformer占着主导的地位……
2. 核心方法
如前所述,这篇文章的核心就是针对self-attention的结构进行了细化研究,尝试优化掉了点积操作,从而可以考察self-attention权重的更本质的含义。
我们首先给出各个版本的self-attention结构图以及对应的参数量如下:


1. Vanilla Self-Attention (V)
对于最基础的self-attention结构,假设attention层的输入为 X ∈ R l ∗ d X \in \mathbb{R}^{l*d} X∈Rl∗d,则有:
{ Q = W Q ⋅ X + b Q K = W K ⋅ X + b K V = W V ⋅ X + b V O = s o f t m a x ( W Q ⋅ W k T d ) ⋅ V \left\{ \begin{aligned} Q &= W_Q \cdot X + b_Q \\ K &= W_K \cdot X + b_K \\ V &= W_V \cdot X + b_V \\ O &= softmax(\frac{W_Q \cdot W_k^T}{\sqrt{d}}) \cdot V \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧QKVO=WQ⋅X+bQ=WK⋅X+bK=WV⋅X+bV=softmax(dWQ⋅WkT)⋅V
其中, W Q , W K , W V ∈ R d × d W_Q, W_K, W_V \in \mathbb{R}^{d \times d} WQ,WK,WV∈Rd×d,所以,总的参数量级为 O ( 3 d 2 ) O(3d^2) O(3d2),Self-Attention部分的参数量级为 O ( 2 d 2 ) O(2d^2) O(2d2)( W Q , W K W_Q, W_K WQ,WK)。
后续由于只调整self-attention的权重部分,因此,我们说的self-attention部分的参数量就仅指除了 V V V之外的部分的参数量,即权重部分的参数量。
2. Dense Synthesizer (D)
Dense Synthesizer的核心思路是说使用FFN层来替换掉attention权重的生成过程,即:
{ B = W 2 ( σ R ( W 1 ⋅ X + b 1 ) ) + b 2 V = W V ⋅ X + b V O = s o f t m a x ( B ) ⋅ V \left \{ \begin{aligned} B &= W_2(\sigma_R(W_1 \cdot X + b_1)) + b_2 \\ V &= W_V \cdot X + b_V \\ O &= softmax(B) \cdot V \end{aligned} \right. ⎩⎪⎨⎪⎧BVO=W2(σR(W1⋅X+b1))+b2=WV⋅X+bV=softmax(B)⋅V
其中, W 1 ∈ R d × d W_1 \in \mathbb{R}^{d \times d} W1∈Rd×d, W 2 ∈ R l × d W_2 \in \mathbb{R}^{l \times d} W2∈Rl×d,因此,其参数量级为 O ( d × l + d 2 ) O(d\times l + d^2) O(d×l+d2)。
3. Random Synthesizer (R)
Random Synthesizer的思路较之上述的Dense Synthesizer则更加暴力,我们直接给出一组与输入无关的权重矩阵,然后直接训练这组权重然后考察效果。
具体而言,即为:
{ V = W V ⋅ X + b V O = s o f t m a x ( R ) ⋅ V \left \{ \begin{aligned} V &= W_V \cdot X + b_V \\ O &= softmax(R) \cdot V \end{aligned} \right. {VO=WV⋅X+bV=softmax(R)⋅V
其中, R ∈ R l × l R \in \mathbb{R}^{l\times l} R∈Rl×l,对应的参数量极同样为 O ( l 2 ) O(l^2) O(l2)。
4. Factorized Model
这里,我们注意到一点,这里,我们虽然减少了权重的计算,但是Self-Attention层的参数总量却从 O ( 2 d 2 ) O(2d^2) O(2d2)增加到了KaTeX parse error: Undefined control sequence: \tims at position 4: O(l\̲t̲i̲m̲s̲ ̲d + d^2)(Dense Synthersizer)或者 O ( l 2 ) O(l^2) O(l2)(Random Synthesizer)。
由于通常来说句长 l l l是大于模型维度 d d d的,因此模型的参数总量事实上是有所增加的。
因此,这里通过对句长进行拆分来缩减来减少参数总量。
我们假设句长 l = a × b l = a \times b l=a×b,则我们具体有:
1. Factorized Dense Synthesizer (FD)
{ A = σ R ( W 0 ⋅ X + b 0 ) B 1 = W 1 A + b 1 B 2 = W 2 A + b 2 B = B 1 ∗ B 2 \left \{ \begin{aligned} A &= \sigma_R(W_0 \cdot X + b_0) \\ B_1 &= W_{1}A + b_{1} \\ B_2 &= W_{2}A + b_{2} \\ B &= B_1 * B_2 \end{aligned} \right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧AB1B2B=σR(W0⋅X+b0)=W1A+b1=W2A+b2=B1∗B2
其中, W 0 ∈ R d × d , W 1 ∈ R a × d , W 2 ∈ R b × d W_0 \in \mathbb{R}^{d \times d}, W_1 \in \mathbb{R}^{a \times d}, W_2 \in \mathbb{R}^{b \times d} W0∈Rd×d,W1∈Ra×d,W2∈Rb×d。
由此,就可以将参数总量缩减至 O ( d 2 + d × ( a + b ) ) O(d^2 + d \times (a + b)) O(d2+d×(a+b))。
2. Factorized Random Synthesizer (FR)
{ R = R 1 × R 2 V = W V ⋅ X + b V O = s o f t m a x ( R ) ⋅ V \left \{ \begin{aligned} R &= R_1 \times R_2 \\ V &= W_V \cdot X + b_V \\ O &= softmax(R) \cdot V \end{aligned} \right. ⎩⎪⎨⎪⎧RVO=R1×R2=WV⋅X+bV=softmax(R)⋅V
其中, R 1 ∈ R l × k , R 2 ∈ R k × l , k ≪ l R_1 \in \mathbb{R}^{l \times k}, R_2 \in \mathbb{R}^{k \times l}, k \ll l R1∈Rl×k,R2∈Rk×l,k≪l。
5. Mixture of Synthesizer
Mixture of Synthesizer方法事实上就是在计算权重过程中联合使用上述的全部方法,具体而言,即有:
O = S o f t m a x ( ∑ i α i ⋅ S i ( X ) ) ⋅ V O = Softmax(\sum_{i} \alpha_i \cdot S_i(X)) \cdot V O=Softmax(i∑αi⋅Si(X))⋅V
其中, ∑ i α i = 1 \sum_i \alpha_i = 1 ∑iαi=1,为一组归一化的权重因子,而 S i ( X ) S_i(X) Si(X)上上述介绍的任意一种权重因子。
为了泛化其效果,参数 α \alpha α并没有使用超参,而是交由模型自己进行学习得到的。
3. 实验考察
下面,我们来看一下上述各个版本下的模型实际的效果以及性能。
1. 模型效果考察
1. 翻译 & 语言模型
文中首先考察一下变换了self-attention的权重构成方式之后在翻译以及语言模型上的效果。

可以看到:
- 即便是随机参数之后直接固定住attention权重,模型也能够训练得到一个还过得去的结果;
- Dense以及Random的方式训练得到的模型在效果上和vanilla Transformer效果都是相接近的,只是略有降低而已;
- Factorized方法似乎多少对于性能还是会产生一定的下滑,但是幅度事实上也并不大;
- 采用Mix权重方式能够获得最好的效果
2. 文本生成
同样的,作者也在文本归纳以及对话任务当中也进行了一下考察,得到结果如下:

可以看到:
- 在summary任务当中最优的模型为D+V模型;
- 在对话任务当中,最优的模型为Dense Synthesizer模型;
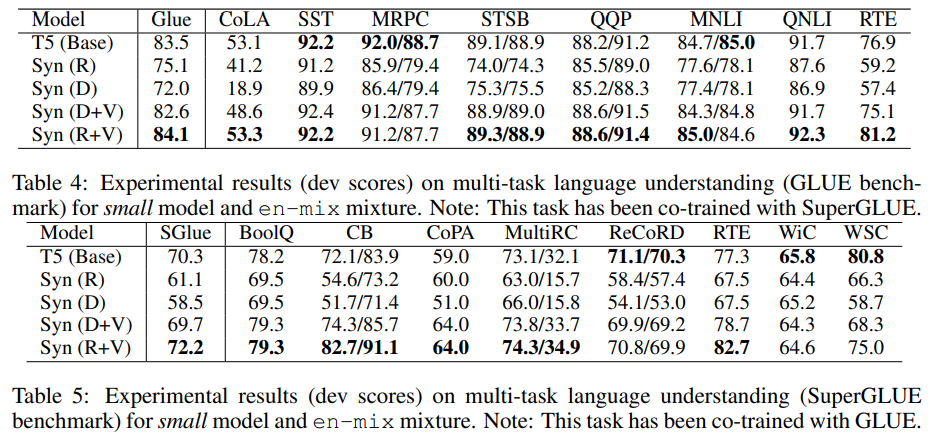
3. GLUE & SuperGlue
在Glue和SuperGlue任务当中,Vanilla Transformer的设计则是完全优于Dense Synthesizer和Random Synthesizer的,但是后两者同样可以提供一些辅助的效果,使得Mixture模型达到更好的效果。
4. 结论
综上,我们可以看到:
- Synthesizer在效果上整体是略逊于Vanilla Transformer的,不过对于生成系列的任务,他们效果其实差不了太多;
- 在Glue系列任务当中,单一的Synthesizer倒是有明显的效果下滑,不过他们依然是有意义的,通过Mixture的方式,他们可以更进一步的提升模型的效果。
2. 模型性能考察
最后,我们来考察一下Synthesizer模型的实际运行性能。
1. 与Transformer以及CNN比较
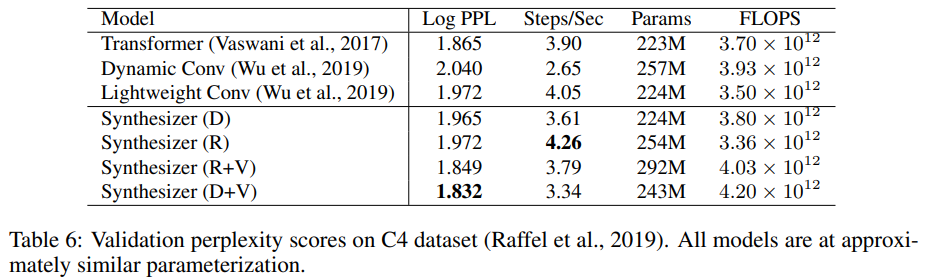
首先,文中拿Synthesizer与Vanilla Transformer以及Conv网络比了一下效果,得到结果如下:
可以看到:
- 虽然效果有所下滑,不过Synthesizer在运行速度上确实是优于Vanilla Transformer以及Conv网络的。
2. 与Linformer比较
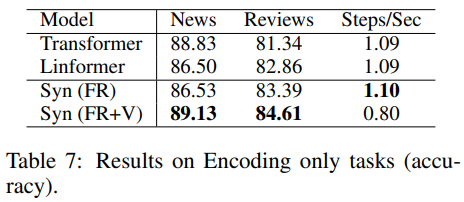
同样的,文中还拿Synthesizer与Linformer进行了一下比较,得到结果如下:
可以看到:
- FR版本的Synthesizer运行的性能是优于Vanilla Transformer以及Linformer的,效果上则是在Reviews上面有所提升,而在News上面有所下滑;
- 表中既然没有给出非Factorized版本的模型效果,大概率它们的性能也是有所下滑的吧;
3. 结论
综上,Synthesizer去除了点积计算之后确实在性能上通常能够带来一定的提升,但是考虑到效果,并不一定总是我们想要的结果。
4. 结论 & 思考
综上,整体来说,无怪乎Synthesizer无法全面替代掉Vanilla Transformer,虽然其在计算量上面确实较之Vanilla Transformer有一定的减少,但是其代价就是增加了参数量,并且其模型的效果较之Vanilla的Transformer同样所有下滑,虽然在翻译以及生成任务上的下滑并不明显。
但是从好的一面来说,文中对于self-attention权重本质的考察还有很有意义的,只不过与文中的目标相反,似乎从结果来看,还是与token相关联的self-attention权重才是比较好的权重生成方式。

















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









