




 本文详细介绍了主成分分析(PCA)的原理、使用目的、计算步骤,包括求累计贡献率和在SPSS与Python中的实现。通过实例说明了如何通过PCA处理变量相关性,降低维度,提高机器学习效率。
本文详细介绍了主成分分析(PCA)的原理、使用目的、计算步骤,包括求累计贡献率和在SPSS与Python中的实现。通过实例说明了如何通过PCA处理变量相关性,降低维度,提高机器学习效率。
目录
[ 0 ] 一句话定义
主成分分析(principal component analysis,PCA) 是一种常用的无监督学习方法,它利用正交变换把由线性相关变量表示的观测数据转换为少数几个由线性无关变量表示的数据,线性无关的变量叫主成分,主成分个数主一般小于原始变量个数,所以它是一种降维方法。主成分分析主要用于发现数据中的基本结构,即数据中变量之间的基本关系,是一种描述性统计方法,常常用于其他机器学习方法的前处理。
——李航《统计学习方法》
[ 1 ] 使用目的和使用条件
统计分析中,变量之间可能存在相关性,以致增加了分析的难度,因而人们探索 降维 的可能性,用原始变量构造少数变量来代替多数变量,这样能保留数据中的大部分信息,同时简化了运算。
讨论: 为什么要降维/处理相关性?相关的数据难处理在哪?
从数据的意义上:举例来说,关于国家的描述有以下变量:人均收入、外汇储备、进出口贸易额等变量,这些变量不独立,反而可能十分相关,其中一个变量的自身变化往往伴随着其他变量不可忽略的变化,谈论单独某个变量对国家特征的单独贡献就没有意义,它们有着“集体贡献”,而总的贡献不是单独变量贡献之和。
从机器学习角度:要处理的数据可能有成百上千的变量,里面有与问题无关的变量,也有彼此相关的冗余变量,进行数据降维能够在较好地描述原始数据的基础上,减少计算时间,改善整体性能。机器学习的降维有两大类:
(1)特征选择:选择原始变量集的子集,不产生新的变量
(2)特征降维:生成了新的变量,如PCA
如上所述,PCA的使用条件就是变量之间存在相关性,如果是完全独立的,那么就没有做PCA的必要了。
[ 2 ] 基本思想和直观理解
把给定的一组变量 X 1 , X 2 , . . . , X p X_1,X_2,...,X_p X1,X2,...,Xp 通过线性变换转化为一组不相关的变量 Y 1 , Y 2 , . . . , Y p Y_1,Y_2,...,Y_p Y1,Y2,...,Yp,保持总方差不变,其中 Y 1 Y_1 Y1 具有最大方差,称为第一主成分,类似地,有第二、第三…第p主成分。方差表示在新变量上信息的大小。
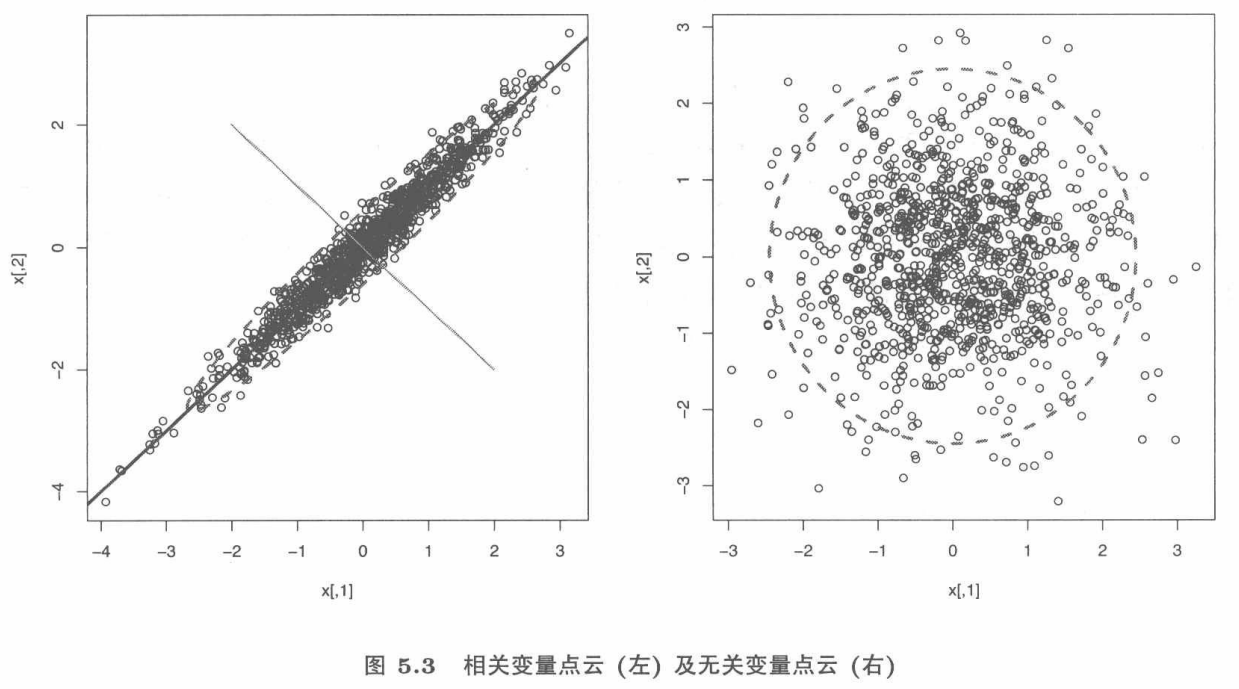
为了直观展示,假设两维的情况。左图由于两个变量相关,呈现一个椭圆的形状,沿椭圆长轴方向包含更多的信息,即方差最大的方向,而短轴方向方差较小。右图是两个不相关变量,长短轴没有差别,近似于一个正圆,因而降维没有什么意义,因为无论向那个方向投影都不会有大的差别。
下面介绍具体的步骤,现在总结要关注的几个问题:
- 如何将原始变量变换称线性无关的变量?
- 这些成分代表了原来的多少信息?
- 是否有可能解释这些成分?
[ 3 ] 具体计算步骤
我将省略一些推导和具体的计算,尽量表达出这个过程的思路,使得不需要太好的数学基础也能尽可能看懂。
目标: x = ( x 1 , x 2 , . . . , x p ) T \bm{x}=(x_1,x_2,...,x_p)^T x=(x1,x2,...,xp)T 是 p p p 维随机变量,定义一个线性变换 y i = α i T x = α 1 i x 1 + α 2 i x 2 + . . . + α p i x p y_i=\alpha_i^T\bm{x}=\alpha_{1i}x_1+\alpha_{2i}x_2+...+\alpha_{pi}x_p yi=αiTx=α1ix1+α2ix2+...+αpixp其中, α i T = ( α 1 i , α 2 i , . . . , α p i ) \alpha_i^T=(\alpha_{1i},\alpha_{2i},...,\alpha_{pi}) αiT=(α1i,α2i,...,αpi),从而将 x \bm{x}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8897
8897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









