 PyTorch中实现Balanced Cross-Entropy损失函数
PyTorch中实现Balanced Cross-Entropy损失函数





 本文介绍了在变化检测任务中,由于样本不均衡问题,如何基于PyTorch的F.cross_entropy和F.binary_cross_entropy实现BalancedCross-Entropy损失函数。这个损失函数通过引入权重因子beta来解决正负样本不平衡,代码中展示了优化后的实现方式,避免了嵌套循环导致的计算效率低下,并处理了可能的log无穷值问题。
本文介绍了在变化检测任务中,由于样本不均衡问题,如何基于PyTorch的F.cross_entropy和F.binary_cross_entropy实现BalancedCross-Entropy损失函数。这个损失函数通过引入权重因子beta来解决正负样本不平衡,代码中展示了优化后的实现方式,避免了嵌套循环导致的计算效率低下,并处理了可能的log无穷值问题。
当你明白了pytorch中F.cross_entropy以及F.binary_cross_entropy是如何实现的之后,你再基于它们做改进重新实现一个损失函数就很容易了。
1、背景
变化检测中,往往存在样本不均衡的情况,也就是changed pixel很少,而unchange pixel占据大多数,论文DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images中统计了在CCD和BCCD数据集中change-pixel与unchanged-pixel的比例。
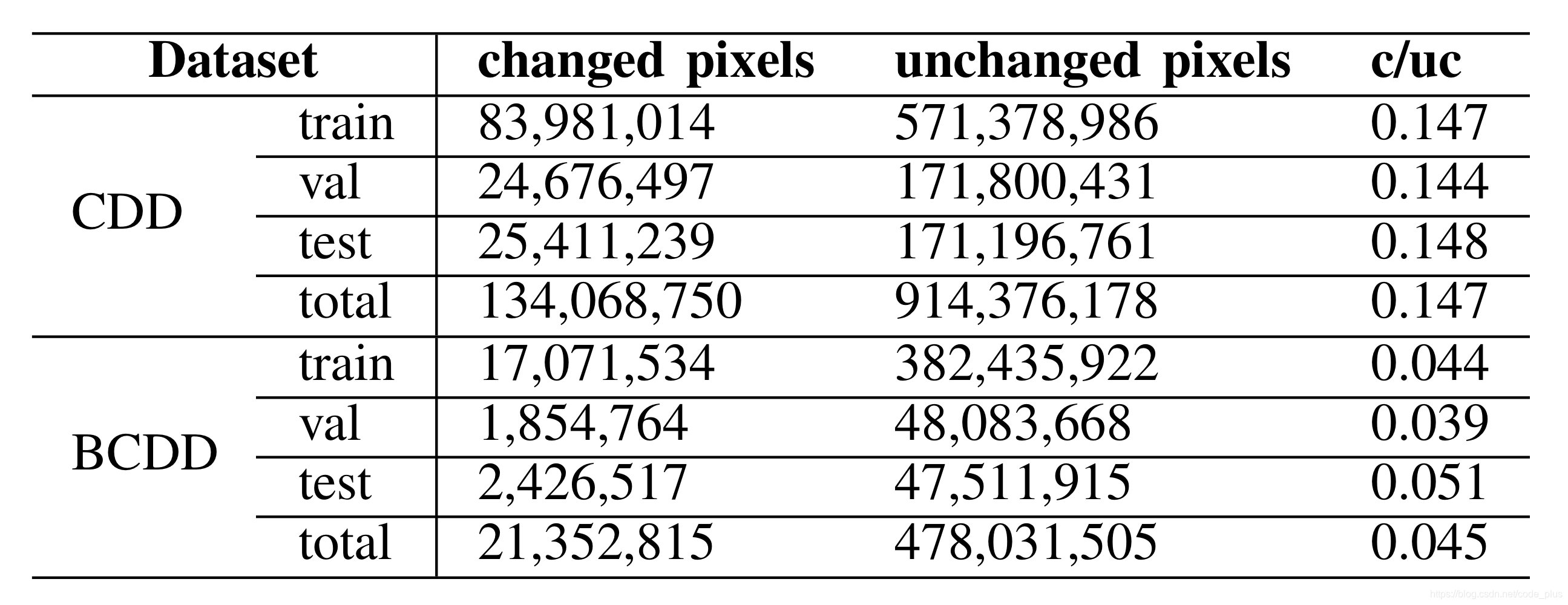
显然,样本间存在严重的不平衡问题,这个时候为了解决数据不平衡的问题,我们需要改进损失函数,如使用同时为正负样本加权的Balanced Cross-Entropy损失函数,可通过beta控制,该函数的公式如下:
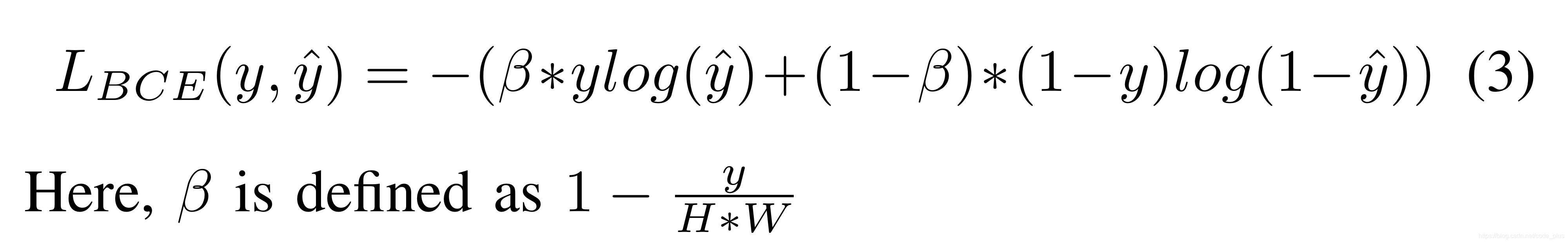
这里给大家分享篇论文,A survey of loss functions for semantic segmentation介绍了语义分割中常用的损失函数,包括上面的Balanced Cross-Entropy。
2、pytorch中实现Balanced Cross-Entropy
class Balanced_CE_loss(torch.nn.Module):
def __init__(self):
super(Balanced_CE_loss, self).__init__()
def forward(self, input, target):
input = input.view(input.shape[0], -1)
target = target.view(target.shape[0], -1)
loss = 0.0
for i in range(input.shape[0]):
beta = 1-torch.sum(target[i])/target.shape[1]
for j in range(input.shape[1]):
loss += -(beta*target[i][j] * torch.log(input[i][j]) + (1-beta)*(1 - target[i][j]) * torch.log(1 - input[i][j]))
return loss
发现其实上述的代码也就是在binary_cross_entropy的实现基础上加了一个beta系数,其中beta=1-y/(w*h)。
3、优化
如果按照上面的写法,那你在训练的时候你就会无语了,对于嵌套的for循环,cuda加速巨慢无比,所以我们将上述代码进行一些优化。而且在pytorch实现的损失函数中对log的输出做了限制(我在一文搞懂F.binary_cross_entropy的具体实现中有提及),所以我们也对其做一个限制,否则训练的时候可能会出现无穷值,导致方向传播出问题。
class Balanced_CE_loss(torch.nn.Module):
def __init__(self):
super(Balanced_CE_loss, self).__init__()
def forward(self, input, target):
input = input.view(input.shape[0], -1)
target = target.view(target.shape[0], -1)
loss = 0.0
# version2
for i in range(input.shape[0]):
beta = 1-torch.sum(target[i])/target.shape[1]
x = torch.max(torch.log(input[i]), torch.tensor([-100.0]))
y = torch.max(torch.log(1-input[i]), torch.tensor([-100.0]))
l = -(beta*target[i] * x + (1-beta)*(1 - target[i]) * y)
loss += torch.sum(l)
return loss
注:如有错误还请指出!

















 2185
2185






 到【灌水乐园】发言
到【灌水乐园】发言







