




 本文提供了一份全面的Linux运维学习资料,针对不同水平的学习者,从零基础到进阶,旨在帮助程序员高效提升技能。同时,还给出了数据库优化建议,如索引使用、查询优化等,以提高IT行业的学习效率和实践效能。
本文提供了一份全面的Linux运维学习资料,针对不同水平的学习者,从零基础到进阶,旨在帮助程序员高效提升技能。同时,还给出了数据库优化建议,如索引使用、查询优化等,以提高IT行业的学习效率和实践效能。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

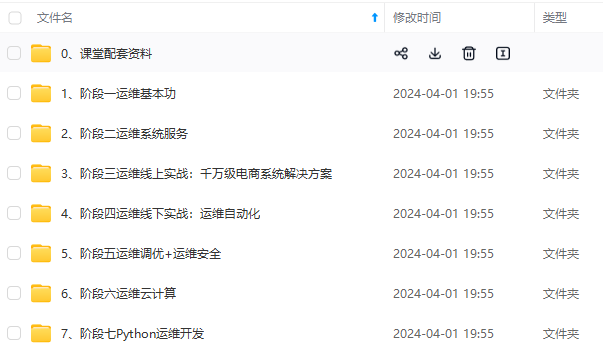
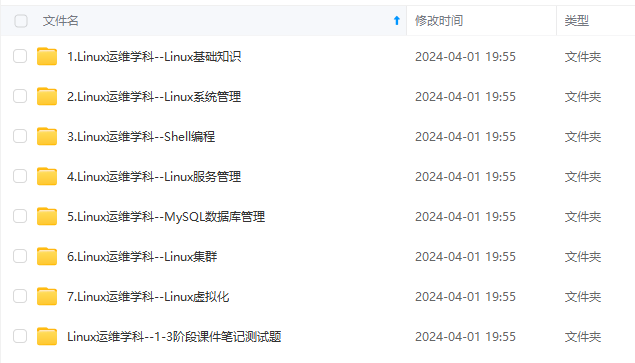
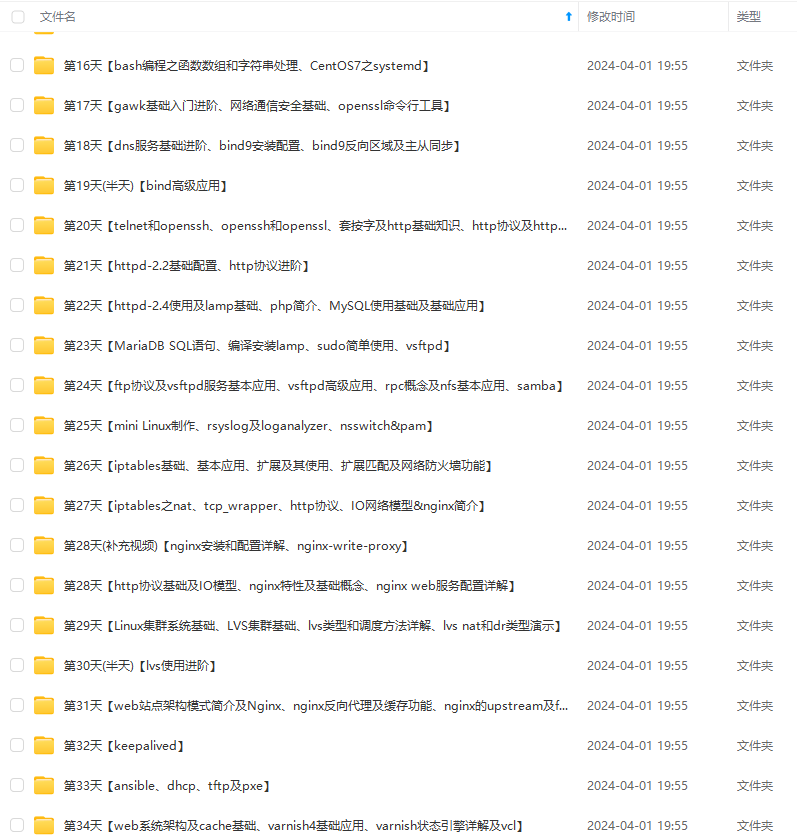
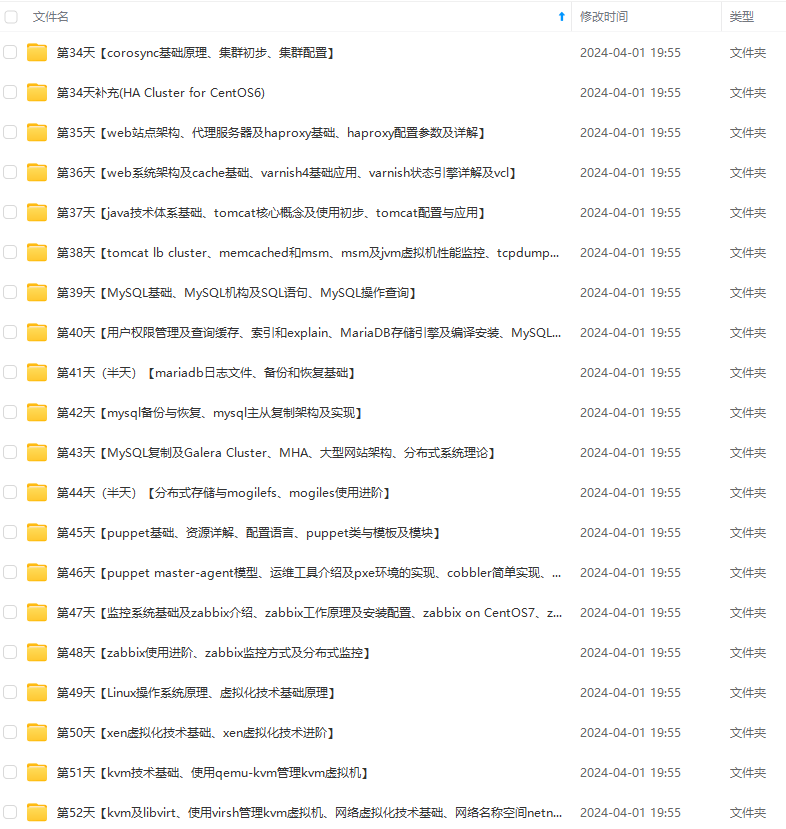
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文

- 在表中建⽴索引,优先考虑 where group by 使⽤到的字段。
- 查询时尽量避免使⽤select * ,只查询需要⽤到的字段。
- 避免在where⼦句中使⽤关键字两边都是%的模糊查询,尽量在关键字后使⽤模糊查询。
- 尽量避免在where⼦句中使⽤IN 和NOT IN。
优化:能使⽤between就不⽤in
在⼦查询中使⽤exists ⼦句 - 尽量避免使⽤or,优化:可以⽤union代替or。
- 尽量避免在where⼦句中使⽤表达式操作。
- 尽量避免在where⼦句中使⽤null判断,优化:给字段添加默认值,对默认值判断。
- 尽量不要在where条件中等号的左侧进⾏表达式.函数操作。
- 尽量避免使⽤where 1=1,优化:⽤代码拼接sql,需要where的地⽅加where,需要and的地⽅加and
- 尽量避免⼤事务操作,提⾼并发能⼒。
- ⼀个表中的索引最好不要超过6个。
- 应尽量避免在where⼦句中使⽤ != 或 <>。
- 在使⽤索引字段作为条件时,如果该索引是复合索引,那么必须使⽤到该索引中的第⼀个。字段作为条件时
才能保证系统使⽤该索引,否则该索引将不会被使⽤,并且应尽可能的让字段顺序与索引顺序相⼀致。 - Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调⽤会引起明显的性能消耗,同时
带来⼤量⽇志。 - 对于多张⼤数据量(这⾥⼏百条就算⼤了)的表JOIN,要先分⻚再JOIN,否则逻辑读会很⾼,性能很差。
- 尽量使⽤数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增
加存储开销。
这是因为引擎在处理查询和连 接时会逐个⽐较字符串中每⼀个字符,⽽对于数字型⽽⾔只需要⽐较⼀次就够
了。 - 尽量避免使⽤游标,因为游标的效率较差,如果游标操作的数据超过1万⾏,那么就应该考虑改写。游标的⼀
个常⻅⽤途就是保存查询结果,以便以后使⽤。
游标的结果集是由SELECT语句产⽣,如果处理过程需要重复使⽤⼀个记录集,那么创建⼀次游标⽽重复使⽤
若⼲次,⽐重复查询数据库要快的多。 - 尽量避免向客户端返回⼤数据量,若数据量过⼤,应该考虑相应需求是否合理。
- 什么时候【要】创建索引?
表经常进⾏ SELECT 操作。
表很⼤(记录超多),记录内容分布范围很⼴。
列名经常在 WHERE ⼦句或连接条件中出现。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









