







HBase是一个分布式、面向列的数据库,它能够处理大规模的数据集。面对海量数据,单线程查询可能无法满足性能要求,因此,分段多线程查询成为优化性能的重要手段。本文将深入探讨如何通过分段多线程查询来提高HBase的查询效率,并提供相关代码示例。

1. 概述
在大数据环境中,HBase因其高效的存储和快速的随机读写能力,被广泛用于处理结构化和非结构化数据。随着数据量的增加,查询性能可能会成为瓶颈。为了提高查询效率,本文提出了分段多线程查询的方案,即将数据按照一定的规则分段,然后由多个线程同时进行查询操作。这种方法能够充分利用多核CPU的优势,显著提高查询速度。
2. HBase查询的基本概念
在讨论分段多线程查询之前,我们需要了解HBase的一些基本概念:
- 表(Table):HBase的数据存储单位,包含若干个行(Row)。
- 行键(Row Key):唯一标识一行数据的键值,HBase根据行键将数据分布在不同的Region中。
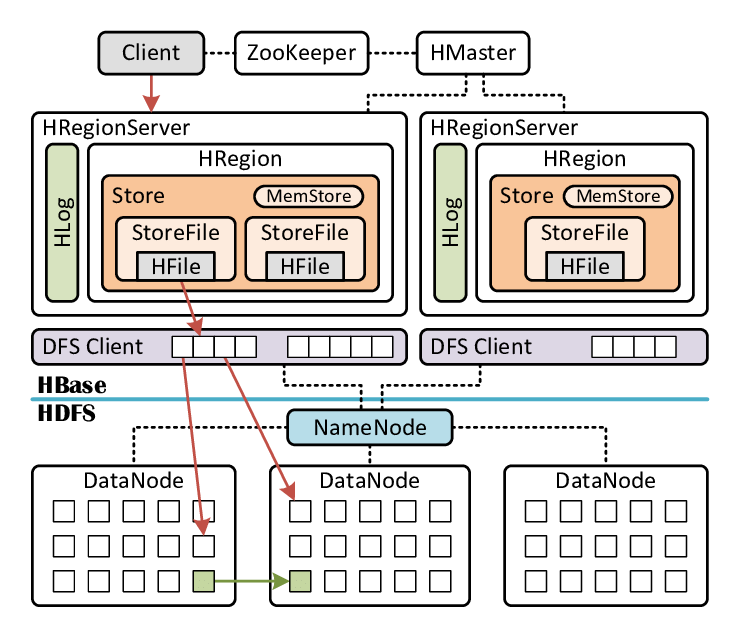
- Region:HBase中的数据分区,包含一组行数据,Region是HBase的最小分区单元。
- Region Server:负责管理Region的服务器,处理对这些Region的读写请求。
在HBase中,查询的基本过程是通过Row Key定位数据,或者通过扫描获取一段数据。这种查询方式非常高效,但在面对大量数据时,单线程扫描的效率可能不够理想。
3. 分段多线程查询的原理
分段多线程查询的核心思想是将数据分成多个区间,每个区间由一个线程负责查询。具体步骤如下:
- 确定查询范围:首先确定需要查询的数据范围。对于范围查询,可以根据Row Key进行分段。
- 分段策
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 46
46

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









