



在 Hive 数据仓库开发中,创建表时添加中文注释是提升数据可读性的重要手段。但许多开发者会遇到中文注释显示为????或乱码的问题,本文将结合 Hive 元数据存储机制和字符集编码原理,提供一套完整的解决方案。
1在使用 DBeaver 连接 Hive 时,中文注释显示乱码通常是由于字符集编码不匹配或驱动配置问题导致的。以下是结合元数据存储、驱动配置和客户端设置的完整解决方案:
一、核心问题定位
- 元数据编码冲突:Hive 元数据存储在 MySQL 中,若 MySQL 字符集为
latin1(默认),则中文注释会被截断为乱码。 - JDBC 驱动编码缺失:DBeaver 使用的 Hive JDBC 驱动未正确传递 UTF-8 编码参数。
- DBeaver 界面显示设置:客户端界面的字符集与数据库返回数据不匹配。
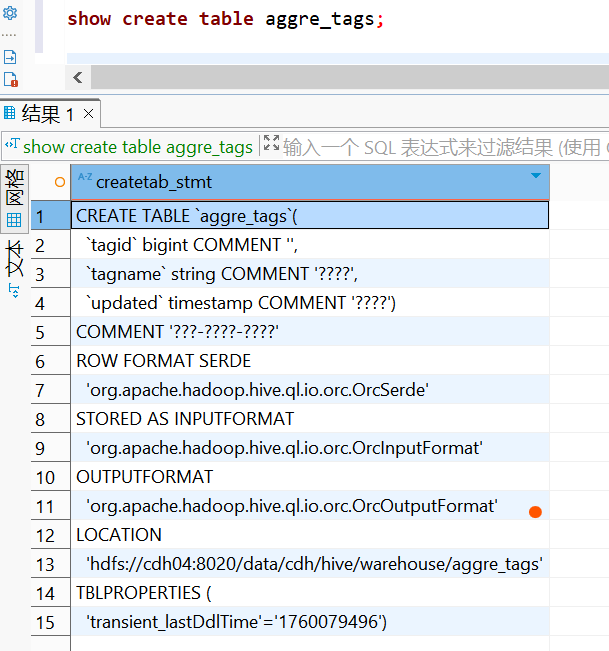
二、DBeaver 专属解决方案
1. 配置 JDBC 连接参数
在 DBeaver 的 Hive 连接设置中,手动添加 UTF-8 编码参数:
plaintext
jdbc:hive2://<host>:<port>/<database>?useUnicode=true&characterEncoding=UTF-8
操作步骤:
- 右键点击 Hive 连接 → 编辑连接 → 连接设置
- 在URL字段末尾添加上述参数(示例):
plaintext
jdbc:hive2://localhost:10000/default?useUnicode=true&characterEncoding=UTF-8 - 点击测试连接确保参数生效。
2. 升级 / 替换 Hive JDBC 驱动
- 下载对应版本驱动:
- 对于 CDH 5.15+,使用
hive-jdbc-uber-2.6.5.0-292.jar(可从 Cloudera Manager 安装包中获取)。 - 对于原生 Hive 3.x,使用官方
hive-jdbc-3.1.2.jar。
- 对于 CDH 5.15+,使用
- 添加驱动到 DBeaver:
- 进入数据库 → 驱动管理器 → 新建驱动
- 选择驱动类型为Generic,类名为
org.apache.hive.jdbc.HiveDriver - 点击添加文件,导入下载的 JDBC 驱动包。
3. 调整 DBeaver 界面编码
- 全局设置:
- 编辑 → 首选项 → 通用 → 文本文件 → 编码,设置为 UTF-8。
- 结果集显示设置:
- 在查询结果窗口右键 → 设置 → 结果集编码,强制选择 UTF-8。
三、元数据存储层修复
若已创建的表仍显示乱码,需同步修复hive数据仓库依赖的MYSQL元数据库;
1查看现在hive的元数据库表结构,可以看到默认的表结构注释是latin1字符集,导致中文注释存储在HIVE元数据库中出现字符集不一致,需要手工修复;
mysql> show create table COLUMNS_V2;
| COLUMNS_V2 | CREATE TABLE `COLUMNS_V2` (
`CD_ID` bigint NOT NULL,
`COMMENT` varchar(256) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`COLUMN_NAME` varchar(767) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`TYPE_NAME` mediumtext,
`INTEGER_IDX` int NOT NULL,
PRIMARY KEY (`CD_ID`,`COLUMN_NAME`),
KEY `COLUMNS_V2_N49` (`CD_ID`),
CONSTRAINT `COLUMNS_V2_FK1` FOREIGN KEY (`CD_ID`) REFERENCES `CDS` (`CD_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
2手工修复HIVE的元数据库表的存储属性;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
四、驱动兼容性验证
| Hive 版本 | 推荐 JDBC 驱动 | 特殊配置 |
|---|---|---|
| Hive 0.13.x-2.3.x | hive-jdbc-2.3.9.jar | 需在驱动属性中添加hive.metastore.uris参数 |
| Hive 3.0+ | hive-jdbc-3.1.2.jar | 无需额外配置 |
| CDH 5.15+ | hive-jdbc-uber-2.6.5.0-292.jar | 需排除hadoop-common依赖 |
五、验证与测试
- 创建测试表:
sql
CREATE TABLE test_table ( id INT COMMENT '用户ID', name STRING COMMENT '用户姓名' ) COMMENT '用户信息表'; - DBeaver 验证:
- 执行
DESCRIBE FORMATTED test_table,检查注释是否正常显示。 - 在 MySQL 中查询元数据:
sql
SELECT PARAM_VALUE FROM TABLE_PARAMS WHERE PARAM_KEY = 'comment';
- 执行
- 特殊场景处理:
- 若分区字段仍乱码,执行
ALTER TABLE PARTITION_PARAMS MODIFY COLUMN PARAM_VALUE VARCHAR(40000) CHARACTER SET utf8;。 - 对于视图乱码,修改
TBLS表的VIEW_EXPANDED_TEXT字段编码。
- 若分区字段仍乱码,执行
六、常见问题排查
- 连接测试成功但注释仍乱码:
- 检查 MySQL 元数据是否已修改为 UTF-8。
- 确认 DBeaver 驱动属性中未遗漏
characterEncoding=UTF-8参数。
- 驱动加载失败:
- 确保驱动包路径正确,且未与其他版本冲突。
- 对于 Kerberos 环境,需在 URL 中添加
principal=hive/_HOST@REALM参数。
通过以上步骤,可彻底解决 DBeaver 中 Hive 中文注释乱码问题。建议在生产环境操作前,先在测试环境验证配置

















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









