



公司简介
「Netvue」成立于2010年,是全球领先的智能家居软硬件解决方案提供商,专注于家庭安全监控。
Netvue 将专业安防摄像机与先进的 AI 技术相结合,提供与设备相互协同工作的 Netvue 云服务,支持用户实时查看监控视频画面,并智能识别可疑人员。目前,Netvue 已服务全球超过 100 万用户,累计获得 40+ 项发明专利,在细分市场中处于行业领先地位。
01/面临的挑战
GPU 成本高昂,缺乏弹性资源调度能力
出于合规性与流量调控的需求,Netvue 决定将推理服务部署在云上,并在 Google Cloud 上运行 GPU 实例以支撑其 AI 模型计算。但随着用户规模扩大,云上 GPU 成本持续上升,成为业务扩展的主要瓶颈。
尽管 Netvue 已具备一定的弹性伸缩能力,但资源选型仍高度依赖人工配置,难以高效匹配如 Spot 实例等更具成本优势的资源类型。
此外,由于尚未引入 Kubernetes 等云原生调度平台,其 GPU 服务受限于单一云厂商,导致在资源调度、版本发布及系统升级等方面存在流程繁琐、效率较低的问题。
流量波动剧烈,资源需求不稳定
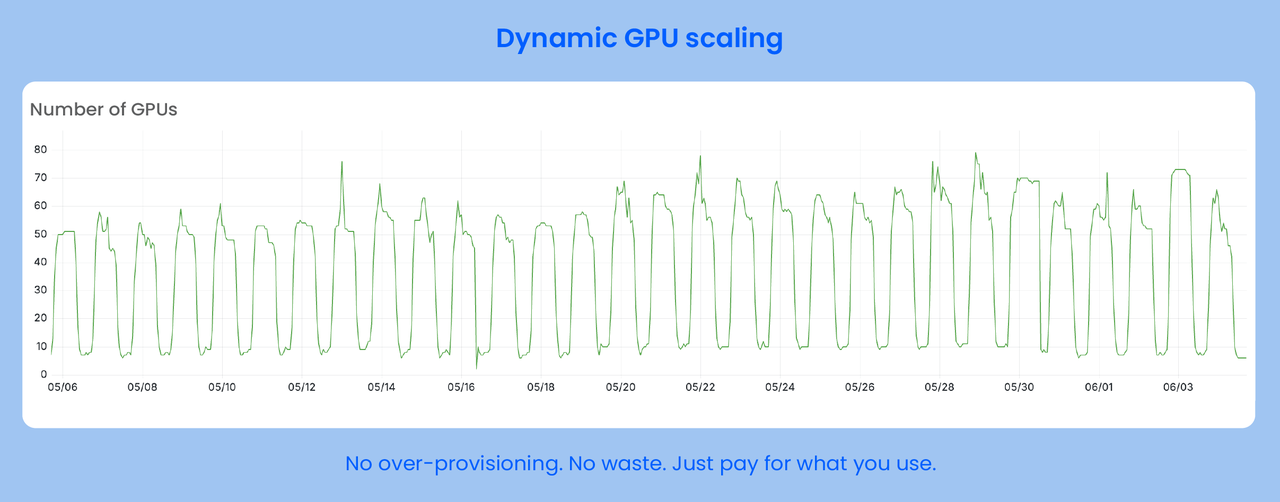
用户行为呈明显的昼夜波动,高峰期 GPU 请求短时间内激增,传统的调度策略在高峰切换时存在滞后,偶发资源争抢和冷启动,影响识别速度和用户体验。
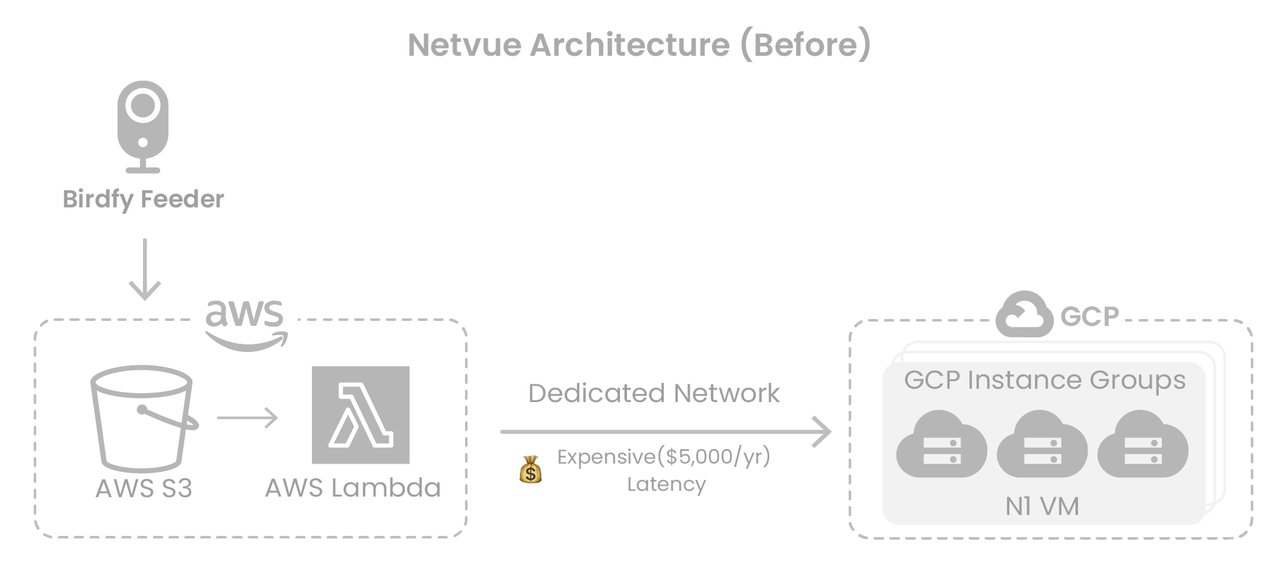
跨云访问导致数据传输成本和延迟高
Netvue 的图像与视频数据存储在 AWS S3,而推理服务运行在 GCP,两地通过专线连接。该架构不仅带来显著的带宽成本,还因跨平台传输而引发推理延迟,降低整体服务性能。
02/解决方案:重构 GPU 调度架构
成果
- GPU 成本降低 52%:通过 Spot GPU 和实例智能选型实现大规模成本优化,单卡 GPU 从 $180+/月降低到 $80+/月
- 资源调度灵活可控:构建中立的 Kubernetes GPU 弹性架构,摆脱云厂商锁定
- 响应速度提升 5 倍:服务与数据同域部署,避免跨云传输瓶颈
- 系统稳定运行:高峰期快速扩展,低谷时精准缩容,降低成本的同时保障业务稳定运行
面对挑战,Netvue 选择与 CloudPilot AI 合作,在保留现有服务逻辑的基础上,从资源选型、架构解耦、弹性扩缩容等多个维度对 GPU 架构进行了系统优化。
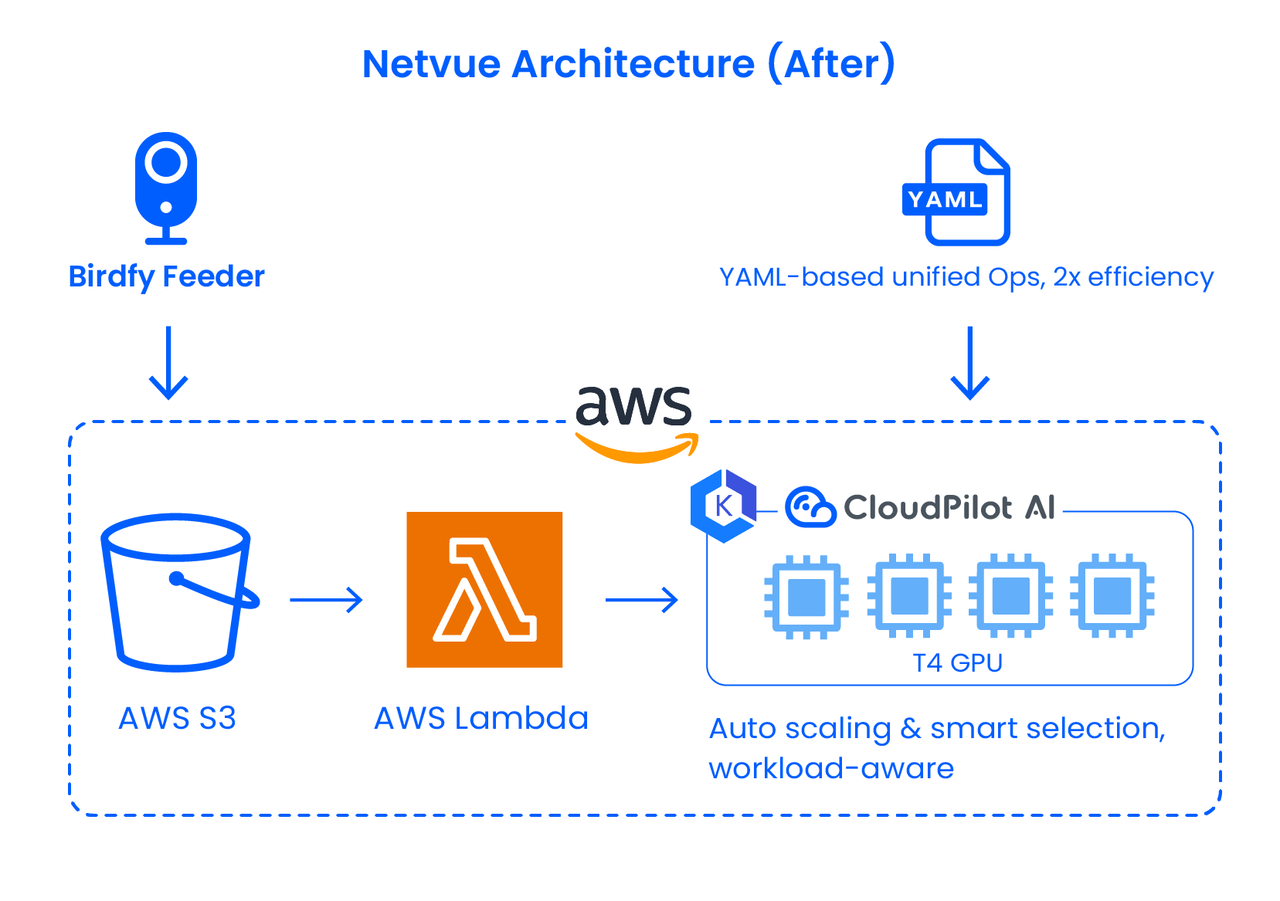
引入 Kubernetes,构建平台中立的 GPU 弹性架构
在 CloudPilot AI 的技术支持下,Netvue 将推理服务迁移至 Kubernetes 集群,并在 AWS 上建立 GPU 专用集群,实现按需调度 GPU 实例、自动扩缩容与多云资源的统一管理。这一架构不仅解耦了服务与底层平台,还为后续多云部署和快速横向扩展提供了基础。
智能节点选型,推动 GPU 从 GCP 向 AWS 平滑迁移
由于早期测试未能在 AWS 上找到满足需求的 GPU 资源,Netvue 曾被迫将 GPU 工作负载部署在 GCP。但考虑到大部分数据仍位于 AWS,跨云通信带来了传输瓶颈。
为解决这一问题,Netvue 通过 CloudPilot AI 的智能实例推荐功能,设定精细的 Instance Requirements(如:优先选择 T4/T4G 系列),最终在 AWS 上匹配到符合性能和容量要求的 Spot 实例,实现 GPU 服务的就地迁移,彻底摆脱了对专线的依赖。
同时,借助 CloudPilot AI 的 Spot 中断预测引擎,降低中断事件数量,确保 Spot 实例的稳定性。
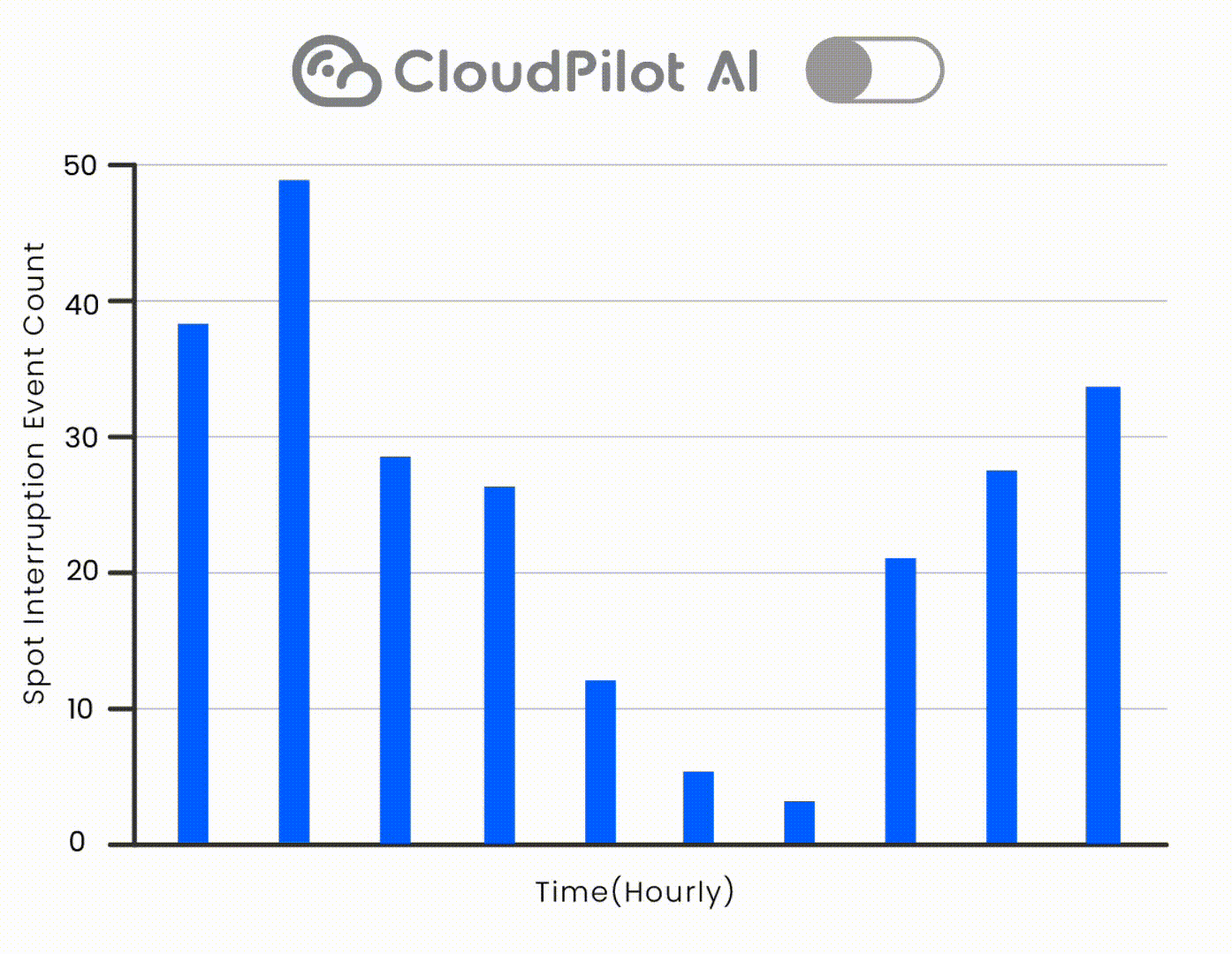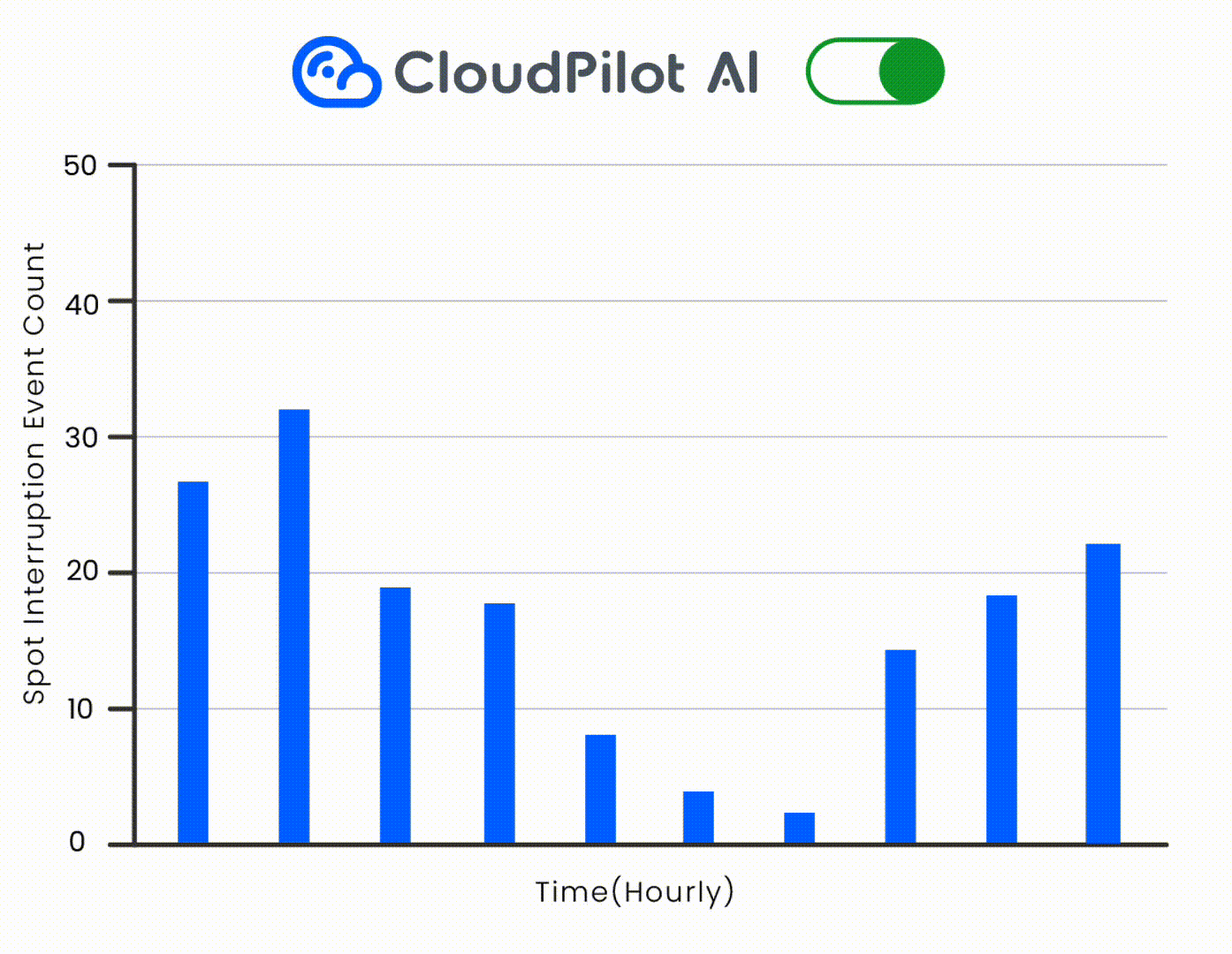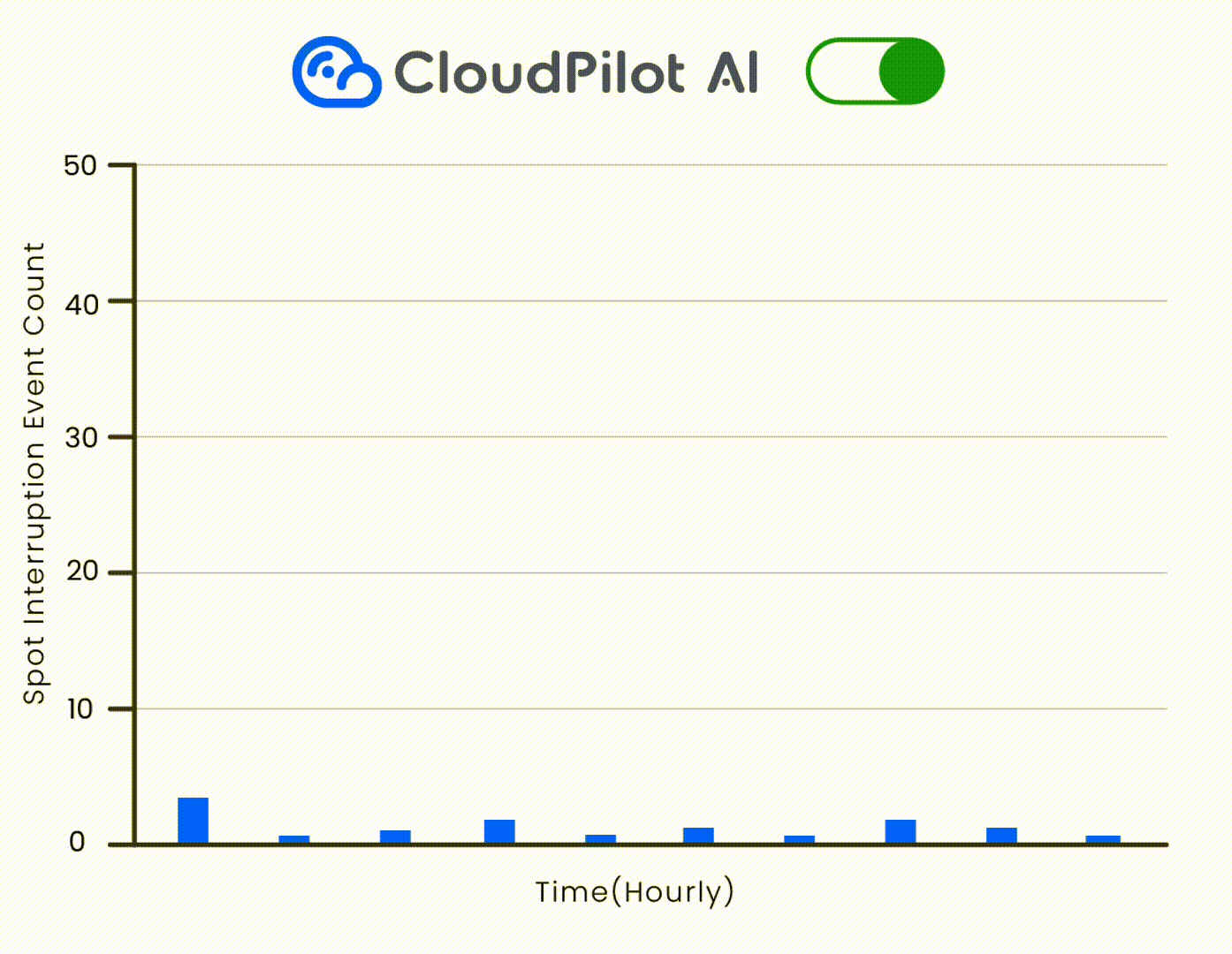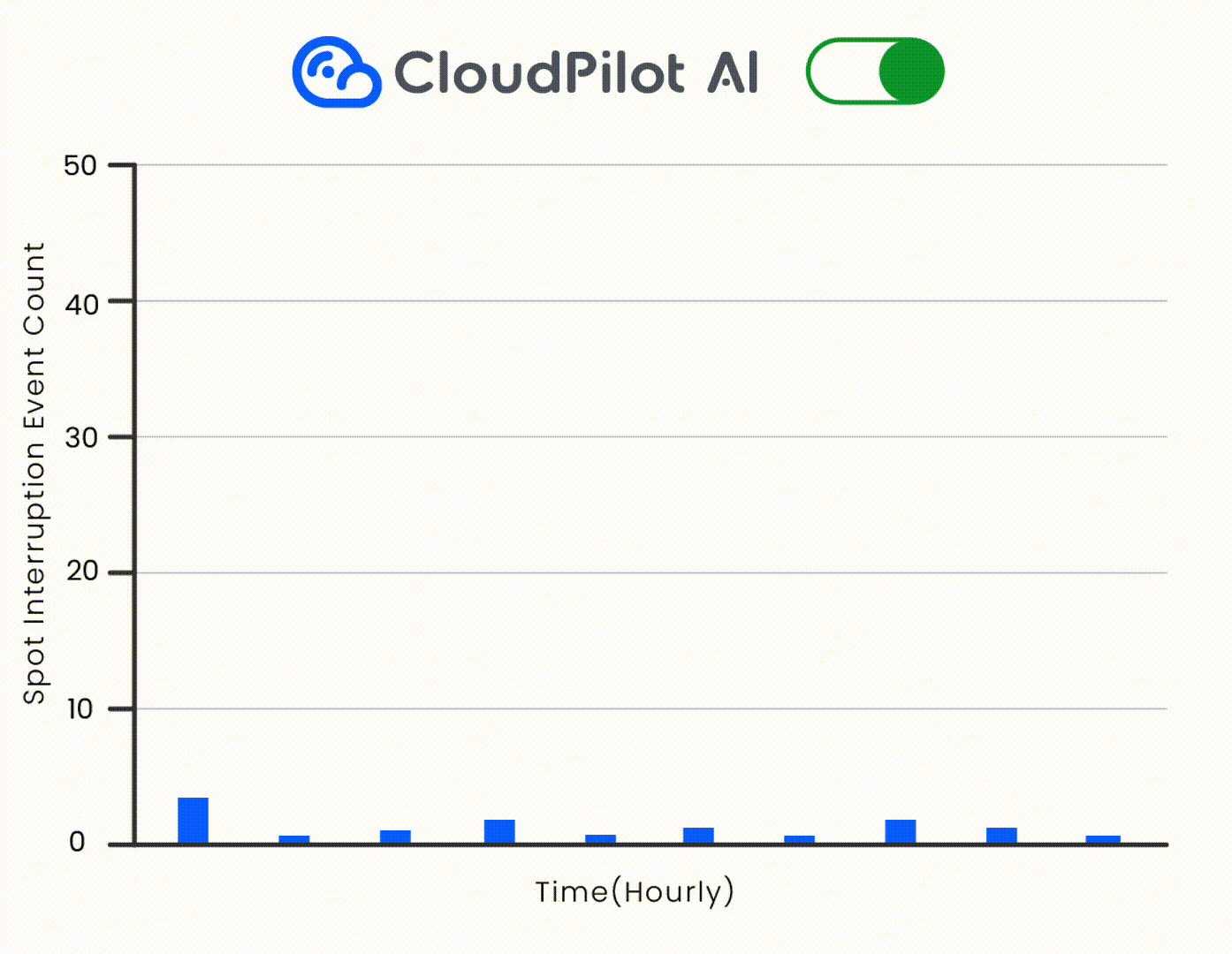
多架构 GPU 适配,提升调度灵活性
CloudPilot AI 协助 Netvue 同时适配 x86、ARM 等多种计算架构,显著扩展了 GPU 可选资源池,缓解热门资源供给紧张问题,进一步降低单位算力成本。
Netvue 平台开发部经理黄盼青表示:“随着业务的快速发展,云上 GPU 成本一度成为我们扩张的主要阻力。CloudPilot AI 不仅帮我们找到了匹配需求的高性价比资源,更让我们的基础设施具备了长期演进的能力,同时提升了平台的运维效率。”
03/基于云的 AI 推理服务与资源调度挑战
在 Netvue,Infra 团队如何支持业务发展?
我们基础设施团队主要负责支撑公司整个线上服务的运行。包括集群管理、资源调度、性能优化、成本控制等等。我们和研发团队紧密配合,确保服务在全球范围内稳定、低延迟地交付给用户。
Netvue 对实时性要求非常高,比如用户通过摄像头实时查看儿童或宠物的活动情况,我们要尽可能快地完成图像上传、分析、识别这些链路。
为此,我们在云上运行了大规模的 GPU 推理服务,并通过弹性调度,能够在用户突发增长或流量高峰时快速扩缩容,确保服务稳定不中断。所以,Infra 这块其实是整个 AI 产品体验的底座。
为什么决定开始进行云成本优化?
主要原因有两个。一是 GPU 成本快速增长,尤其是在用户数激增之后,推理请求的负载也随之大幅上升,这导致我们的成本压力非常大。二是,我们早期架构在资源调度上不够灵活,很多时候只能“硬抗”高峰期的负载,长期来看这不利于业务的可持续发展。
我们需要一种方式,既能保障性能,又能灵活地扩缩容,还要摆脱对单一云平台的依赖。正是在这样的背景下,我们决定和 CloudPilot AI 合作,系统性地进行云成本优化。
04/云上 GPU 成本智能调度实践
CloudPilot AI 的上手使用体验如何?技术支持服务怎么样?
我们在初期对 CloudPilot AI 做了比较审慎的接入。刚开始,我们和 CloudPilot AI 团队沟通比较频繁,主要是为了确保产品能顺利接入我们的集群并适配实际场景。这种深度协作的过程也帮助我们更快理解了工具的能力和边界。
CloudPilot AI 会先对我们的环境进行分析和评估,输出一些有价值的建议。我们最初选择在非生产环境试点自动化策略,包括 Spot GPU 实例推荐和调度优化功能。我们当时非常谨慎,不希望对生产环境造成任何干扰,所以在非生产环境里先做了一轮完整的测试验证。
在非生产环境里反复验证了几轮效果都很稳定之后,我们才把策略迁移到生产集群中。整个过程中,我们对 CloudPilot AI 的透明度和可控性印象很深,任何建议都有数据支撑,而且可以逐步落地,不会一上来就“全自动”。
现在我们已经能在生产环境中更大胆地应用自动化策略,节省了大量时间和人力。
CloudPilot AI 的哪项功能最能帮助到你们团队?
我们团队最受益的是智能节点选型和多架构 GPU 调度能力。
以前我们在 AWS 上找不到合适的 GPU 实例,只能退而求其次部署在 GCP。但 CloudPilot AI 的实例推荐功能非常强大,我们可以设置精细的参数,比如显存大小、GPU 型号优先级等,最终帮我们找到了性能和性价比都满意的 Spot 实例,顺利实现了从 GCP 向 AWS 的迁移。
另外,多架构适配也极大拓宽了我们的资源选择空间,让我们不再只依赖于热门资源。
具体来说,你们是怎么用智能节点选型这个功能的?
我们设了一些要求,比如“优先考虑 A10 或 T4”等,CloudPilot AI 会在这些条件范围内自动去帮我们找当前 AWS 上稳定且便宜的 Spot 实例。其实我们之前在 AWS 上找不到符合要求的 GPU,是因为没太多工具支持这种筛选,一直找不到合适的组合才放弃的。而用上 CloudPilot AI 后,我们很快就定位到可用的实例,服务也顺利迁了回来。
通过 CloudPilot AI,你们达成了怎样的结果?
最直观的成果是 GPU 成本降低了 52%。其次,我们建立了基于 Kubernetes 的平台中立架构,资源调度更加弹性灵活,服务部署在 AWS 后,数据、推理都在同一个平台,延迟降低了不少。
更重要的是,我们现在可以轻松应对流量高峰,不再担心资源冷启动或者限额问题。这种“成本降低 + 性能提升”的双赢,让基础设施真正成为业务增长的助力,而不是包袱。
05/未来展望
在 CloudPilot AI 的支持下,Netvue 不仅升级了 GPU 调度策略、显著降低推理成本,更将原本沉重的基础设施支出转化为业务增长的驱动力。持续的成本优化,让 Netvue 在保障服务质量的同时,具备了更灵活的资源调度能力与更强的市场竞争力。
未来,Netvue 将进一步接入 Spot GPU 的中断预测能力,优化高峰期服务稳定性,构建覆盖全球的高可用推理服务网络,为 AI 服务在全球范围内落地提供坚实支撑。
推荐阅读
年吞百万请求,全球知名自由职业平台Fiverr的K8s弹性伸缩方案升级

















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









