





作者:余建涛,大数据平台产品中心高级工程师
摘要
Spark UI是查看Spark作业运行情况的重要窗口,用户经常需要根据UI上的信息来判断作业失败的原因或者分析作业如何优化。DLC团队实现了云原生的Spark UI Sevice,相较于开源的Spark History Server,存储成本降低80%,大规模作业UI加载速度提升70%。目前已在公有云多个地域上线,为DLC用户提供Spark UI服务。
背景
Spark History Server原理
Spark History Server(以下简称SHS)是Spark原生的UI服务,为了更好了解本文工作的背景,这里先简单介绍下SHS的原理。概况来讲,SHS建立在Spark事件(Spark Event)之上,通过持久化和回放Spark Event来还原Spark作业当前的状态和运行过程中的统计信息。
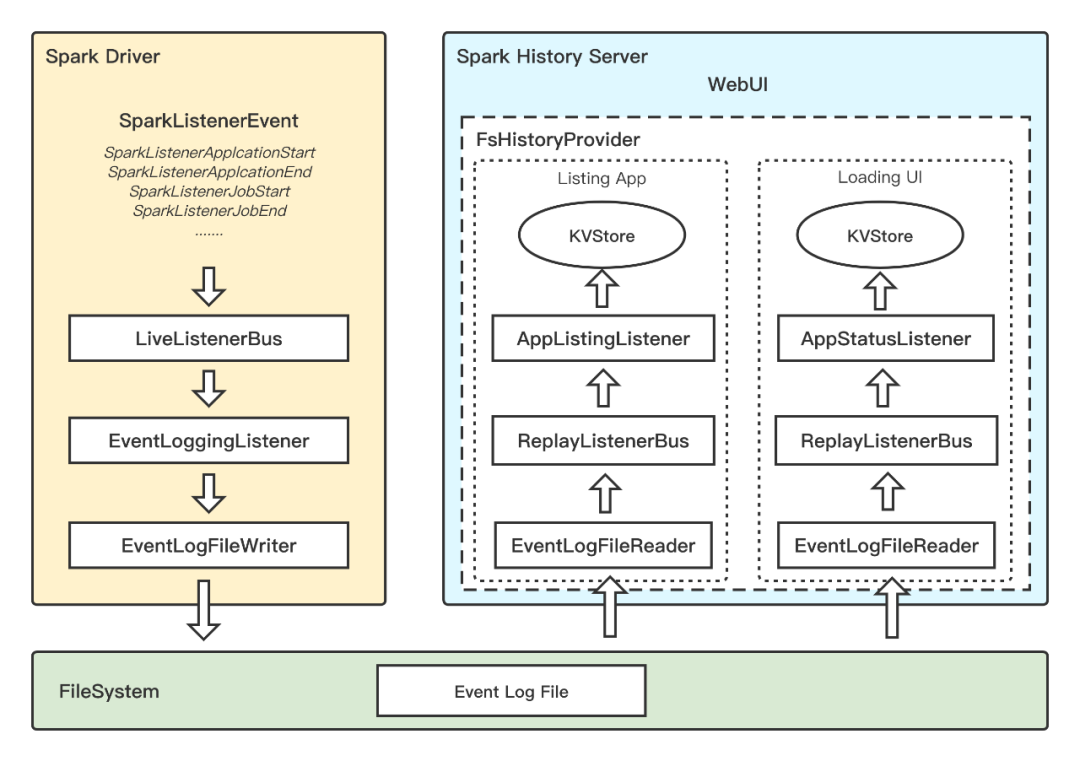
图1 原生Spark History Server原理
如图1左侧,在作业运行过程中,Spark Driver内部各模块会不断产生与作业运行相关的事件,如ApplicationStart/ApplicationEnd,JobStart/JobEnd,StageStart/StageEnd,TaskStart/TaskEnd等,所有事件都会发送到LiveListenerBus,然后在LiveListenerBus内部分发到各个子队列,由子队列上注册的Listener来处理。SHS实现了EventLogQueue队列和监听该队列的EventLoggingListener,EventLoggingListener负责将Event序列化为Json格式,然后由EventLogFileWriter持久化到Event Log文件。Event Log文件通常通常存储在分布式文件系统。
图1右侧是Spark History Server,在其内部FsHistoryProvider负责事件回放,即将事件反序列化后发送到ReplayListenerBus,然后由相应的Listener处理。这里主要包含两个过程,首先是Application listing,FsH
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









