




作者:代来,腾讯 CSIG 工程师
背景
互联网技术高速发展的背景下,数据已经成为各大公司的最宝贵资源之一。大数据领域经过近十年的高速发展,无论是离线计算还是实时计算、不管是数据仓库还是数据中台都已深入各大公司的各个业务。在复杂业务的背景下,迫切需要一套高效的大数据架构。以数据仓库为例,经过了几次架构升级。其中,首先诞生的一个比较成熟的流批一体架构就是 Lambda 架构,然后就是升级版的 Kappa 架构。
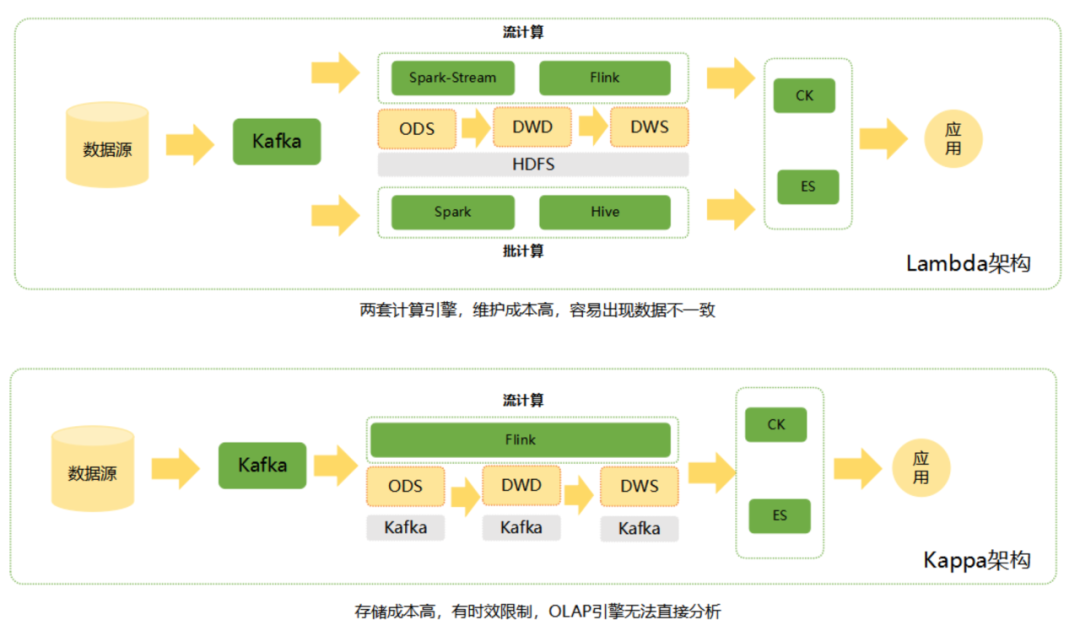
对于传统的 Lambda 架构,流与批是两条割裂的链路,维护成本高且容易出现数据不一致的情况。新的 Kappa 架构使用 Kafka 作为存储,简化了架构,但是 Kafka 的数据承载能力有限且数据格式不利于计算引擎进行数据分析。
Lambda 架构至今也是很多公司使用的成熟架构,其中令我们非常头疼的一个痛点就是,即使我们选用了 Flink + Hive 的近实时的架构支持了实时读写,也会面临着一些问题的困扰。这些问题就是随着 Hive 中的表和分区越来越多并且对分区的实时性要求越高的时候,就会产生非常多的元数据,这对 Hive 的 Metastore 以及存储 Hive 元数据的数据库的产生很大的压力。而且,元数据过多也会导致生成查询计划变慢,严重的会影响到线上业务的稳定性。
Kappa 架构中也有令我们很头疼的痛点。其中,Kafka 本身存储成本很高且数据的保留具有时效性。如果消费端出现故障导致数据积压,那么当数据到达过期时间后就会造成数据丢失且没有被消费。这种情况的后果可能是灾难性的。
基于以上痛点,我们有没有一种可用的方案,好用的架构来解决它们呢?
答案是肯定的,这就是本文要介绍的流批一体、仓湖融合的升级架构解决方案以及高效的数据入湖配套方
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3128
3128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









