




 本文详细介绍了数据库的基础知识,包括SQL语法、数据库的安装与卸载、数据类型的使用、表的操作、查询语句、多表查询、约束、存储过程、触发器以及视图等内容。着重讲解了如何创建、修改和删除数据库对象,以及如何执行DML、DQL、DCL和DDL操作。此外,还探讨了存储过程和触发器的概念及应用,以及视图在数据安全和权限控制中的意义。
本文详细介绍了数据库的基础知识,包括SQL语法、数据库的安装与卸载、数据类型的使用、表的操作、查询语句、多表查询、约束、存储过程、触发器以及视图等内容。着重讲解了如何创建、修改和删除数据库对象,以及如何执行DML、DQL、DCL和DDL操作。此外,还探讨了存储过程和触发器的概念及应用,以及视图在数据安全和权限控制中的意义。
一.简介
1.概述
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理的大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
2.常见数据库
SQLServer: 微软的中小型关系型数据库
MySQL: 中小型的关系型数据库
Oracle: 大型的关系型数据库
关系型数据库: 具有行和列的这种二维表结构的数据库
非关系型数据(NOSQL): 用键值关系来存储数据类似 json
SQL:
结构化查询语言,用来对关系型数据库进行操作,他是一套规范,关系型数据库,都会遵循此规范,但是允许各家的数据库有差异,这些差异,我们称之为方言
SQL语法
对SQL语句我们习惯分为以下四类
(1): DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等
(2): DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(增、删、改)
(3): DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别
(4): DQL(Data Query Language):数据查询语言,用来查询记录(数据)
3.数据库的安装与卸载
安装按照提示正常安装即可
安装地址
登录方法:
mysql -h 主机名 -u 用户名 -p
卸载的正确步骤:
1.可以使用第三方的卸载软件来卸载
2.在控制面板里面常规卸载
1.停止后台服务 电脑–右键–管理—服务—mysql–右键停止掉
2.卸载
3.清除残留文件 C:\ProgramData\MySQL 把这个MySQL文件夹删除
二.数据库的用法
1.数据库中常见的列的数据类型
(1): int:整型
例:id int
(2): double:浮点型
例:money double(5,2)表示最多5位,其中必须有2位小数,即最大值为999.99;
(3): char:固定长度字符串类型;
例:name char(10)
(4): varchar:可变长度字符串类型;
例:name varchar(10)
(5): text:字符串类型;
存大格式的文本 比如存个小说但是一般不用
(6): blob:字节类型;
存字节类型的数据 比如电影字节 图片字节 但是一般不会把字节数据存到数据库当中
(7): date:日期类型;
格式为:yyyy-MM-dd;
(8): time:时间类型;
格式为:hh:mm:ss
(9): datetime:日期时间类型
格式为:yyyy-MM-dd hh:mm:ss
(10): timestamp:时间戳类型
格式为:yyyy-MM-dd hh:mm:ss
如果该类型的字段不给赋值,则默认当前时间
2.数据库的创建
(1): 创建数据库:create database 数据库名
例如: create database mydb;
(2): 查询所有库:show databases;
(3): 删除:drop database mydb;
(4): 修改数据库编码:alter database mydb character set=‘gbk’;
(5): 查看建库语句:show create database mydb;
3.对表头的操作
(1): 切换库 : use mydb;
(2): 创建表:create table 表名(列名1 数据类型,列名2 数据类型2(长度), …);
例:create table student(
id int,
name varchar(16),
age int,
sal double(5,2),
birthday timestamp
);
注意:
1.创建表时,列名 是要有数据类型的
2.列名的命名的规范:遵循java中的命名规范,记住不要拿MySQL中的关键字来命名
(3): 查看改库下所有的表:show tables;
(4): 查看表结构 desc 表名;
例如: desc student;
(5): 修改表名:alter table 旧表名 rename to 新表名
alter table student rename to stu;
(6): 删除表 drop table 表名
drop table student;
(7): 添加一个列
alter table student add(phone varchar(11));
(8): 删除一个列
alter table student drop phone;
(8): 修改列名
alter table student change name username varchar(20);
(9): 修改列的数据类型
alter table student modify username char(20);
(10): 修改表的名字与数据类型:
alter table student change username username varchar(20);
(11): 查看建表语句
show create table student;
9.复制表
创建一张表会把另一张表中的字段和对应的数据全部复制过去
语法:create table 表名 as select * from 另一张表 where true;
CREATE TABLE employee2 AS SELECT * FROM employee WHERE 1=1;
-- 条件为真 将表中的字段和数据一块复制
如果我们只想要字段,不要数据
create table 表名 as select * from 另一张表 where false;
CREATE TABLE employee2 AS SELECT * FROM employee WHERE 1=2;
-- 条件为假 只复制字段,不复制数据
如果我只想还要个别字段
create table 表名 as select 表名.字段名,表名.字段名2 from 另一张表 where 1=2;
CREATE TABLE employee3 AS SELECT emp_no,dept_no FROM employee WHERE 1=2;
我创建的这张表也可以来自一个子查循
create table 表名 as 子查询
查询在1998年1月4日参加项目的所有职员的姓名并把他复制到一张临时表
SELECT lsb.emp_fname AS 姓,lsb.emp_lname AS 名 FROM (SELECT emp_fname,emp_lname FROM employee WHERE emp_no IN(SELECT emp_no FROM works_on WHERE enter_date LIKE '1998-01-04%')) AS lsb;
3.对表中数据的操作
DML:给表中 插入数据,删除数据,修改数据
1.插入数据
insert into 表名(字段名,字段名2,…) valuses(值1,值2,…);
例:insert into student(id,name,age,sal) values(1,‘zhangsan’,23,555.55);
注意:
1.字符串类型的类值、日期类型的值都需要用单引号引起来
例:insert into student(name,birthday) values(‘wangwu’,‘2019-8-19 18:18:20’);
2.对于timestamp类型的值如果不赋值则默认为当前时间
3.如果说需要给表中所有的字段都插入值可以简写为:
例:insert into student values(10,‘zhangsan222’,23,555.55,null);
2.删除数据
–逐行删除
无条件的删除表中所有数据
例:delete from 表名;
删除表中所有的数据,再创建一个新的空表
例:truncate table 表名;
条件删除
where = > < >= <= and 并且 or 或者
例:delete from student where name=‘zhangsan’ and age=18;
3.修改数据
update student set 字段名=‘修改的值’ , set 字段名 … where 条件
例:update student set name=‘wangwu’,age=23 where name=‘zhangsan’ and age=20;
4.查询数据
(1)查询表中所有信息:
SELECT * FROM 表名;
SELECT * FROM employee;
(2)查询个别字段:
SELECT 字段名1,字段名2… FROM 表名;
SELECT emp_fname,emp_lname FROM employee;
(3)条件查询:
假设有如下表employee:
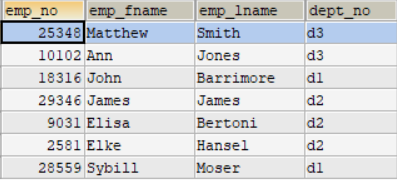
查询员工号大于10000的且属于d2部门的人
SELECT * FROM employee WHERE emp_no>10000 AND dept_no=‘d2’;
查询员工号大于10000的和属于d2部门的人
SELECT * FROM employee WHERE emp_no>10000 OR dept_no=‘d2’;
查询员工编号是空的人
SELECT * FROM employee WHERE emp_no IS NULL;
查询员工编号不是空的人
SELECT * FROM employee WHERE emp_no IS NOT NULL;
模糊查询
–查询姓中带有s的
SELECT * FROM employee WHERE emp_fname LIKE '%S%'
–查询姓中以s开头的
SELECT * FROM employee WHERE emp_fname LIKE 'S%'
–查询姓中以s结尾的
SELECT * FROM employee WHERE emp_fname LIKE '%S'
–查询姓中第四个字符是s的(加三个_)
SELECT * FROM employee WHERE emp_fname LIKE '___S%'
聚合函数
–COUNT(empno) 统计一列由多少个,不能统计null值
SELECT COUNT(*)AS 总人数 FROM employee;
–查询所有编号相加之和
SELECT SUM(emp_no) AS 编号和 FROM employee;
–查询最大编号
SELECT MAX(emp_no) AS 最大编号 FROM employee;
–查询最大编号
SELECT MIN(emp_no) AS 最小编号 FROM employee;
–查询编号的平均值
SELECT AVG(emp_no) AS 平均 FROM employee;
分页查询
用法: limit 起始索引,每页条数
起始索引=(页码-1)*每页的条数
例如:
查询第一页:
SELECT * FROM employee LIMIT 0,4;
查询第二页:
SELECT * FROM employee LIMIT 4,4;
5.多表查询
表works_on
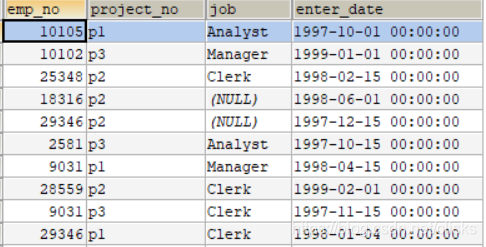
(1)显示内连接
不符合条件的信息,不做展示
例如:
查询employee表中的员工编号和姓,works_on表中的员工工作和工作日期,二表得共同点为员工编号
SELECT employee.`emp_no`,employee.`emp_fname`, works_on.`job`,works_on.`enter_date` FROM employee,works_on WHERE employee.`emp_no`=works_on.`emp_no`;
(2)隐身内连接
表1 inner join 表2 on (inner 可以省略不写)
例如:显示俩表的所有信息
SELECT employee.*,works_on.* FROM employee INNER JOIN works_on ON employee.`emp_no`=works_on.`emp_no`;
(3)外连接
外连接中outer 可以省略不写
左外连接和右外连接可以互换
左外连接 :
LEFT 关键字左边的表中的信息会全部展示,在右边表中没有符合条件的以null展示
例如:显示俩表的所有信息
SELECT employee.*,works_on.* FROM employee LEFT OUTER JOIN works_on ON employee.`emp_no`=works_on.`emp_no`;
右外连接
RIGHT 右边的表中的信息全部展示,没有对应的以null展示
SELECT employee.*,works_on.* FROM employee RIGHT OUTER JOIN works_on ON employee.`emp_no`=works_on.`emp_no`;
(4)关联查询
N张表关联查询 关联条件 得 N-1 个
查询在1998年1月4日参加项目的所有职员的姓名
SELECT emp_fname,emp_lname FROM employee WHERE emp_no=(SELECT emp_no FROM works_on WHERE enter_date LIKE '1998-01-04%');
(5)内连接查询
查询works_on表中项目为p2人的姓名
SELECT works_on.`project_no` AS 项目,employee.`emp_fname` 姓,employee.`emp_lname` 名 FROM employee,works_on WHERE employee.`emp_no`=works_on.`emp_no` AND works_on.`project_no`='p2'
6.对表中数据的其他操作
用AS给字段起别名(AS可以省略)
SELECT emp_no 员工编号,emp_fname 姓,emp_lname 名,dept_no AS 部门 FROM employee;
用AS给表起别名
SELECT e.`emp_no`,e.`emp_fname`,e.`dept_no` FROM employee AS e WHERE e.`emp_no` IS NOT NULL;
用DISTINCT 对结果进行去重
SELECT DISTINCT dept_no FROM employee WHERE dept_no='d2';
排序(order by)
SELECT * FROM employee ORDER BY emp_no ASC; – 默认升序排列
SELECT * FROM employee ORDER BY emp_no DESC; – 降序排列
分组
–求每个部门最大编号的员工
SELECT dept_no AS 部门, MAX(emp_no) AS 部门平均编号 FROM employee GROUP BY dept_no;
–求每个部门员工编号大于15000的人数
SELECT dept_no AS 部门号, COUNT(*) AS 部门人数 FROM employee WHERE emp_no>15000 GROUP BY dept_no;
where 和 having 的区别
where 是分组之前,进行条件筛选,不符合条件的不参与分组,having 是对分组之后产生的结果集,进行再次筛选
例如:员工编号大于15000的员工且分组后的平均编号大于25000
SELECT dept_no AS 部门号, AVG(emp_no) AS 平均编号 FROM employee WHERE emp_no>15000 GROUP BY dept_no HAVING 平均编号>25000
4.约束
对插入表中的数据做出一种限定,为了保证数据的有效性和完整性
1.主键约束(primary key)
(1)特点
非空且唯一,一张表中只能有一个主键
(2)用法
方式一:建表时就添加主键约束
CREATE TABLE test2(
NAME VARCHAR(10) PRIMARY KEY,
age INT
);
方式二:通过修改表添加主键,添加时表中不能有数据
ALTER TABLE test ADD PRIMARY KEY (NAME);
方式三:
CREATE TABLE test3(
NAME VARCHAR(10),
age INT,
PRIMARY KEY(NAME)
);
(3)联合主键
方式与设置主键相同,只是参数不同,把参数看为一个整体,都相同才算不为唯一,即不能添加,参数有一个不同均可添加
CREATE TABLE test4(
NAME VARCHAR(10),
age INT,
PRIMARY KEY(NAME,age)
);
2.唯一约束(unique)
对null值不起作用
CREATE TABLE test5(
NAME VARCHAR(10) UNIQUE,
age INT
);
3.非空约束(not null)
CREATE TABLE test6(
NAME VARCHAR(10) NOT NULL,
age INT
);
4.非空且唯一
CREATE TABLE test7(
NAME VARCHAR(10) NOT NULL UNIQUE,
age INT
);
5.自增长约束
只针对整数类型,配合主键约束来使用
要求:
(1).被修饰的字段类型支持自增. 一般int
(2).被修饰的字段必须是一个key 一般是primary key
CREATE TABLE test8(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
age INT
);
INSERT INTO test8(NAME,age) VALUES('aa',20);
注意:删除第n行后从第n+1行继续排序
6.非负约束(UNSIGNED)
TINYINT 范围-128–127,加非负约束后范围变为0–255,没有负数
CREATE TABLE test9(
id TINYINT UNSIGNED,
NAME VARCHAR(10) NOT NULL,
age INT,
sex ENUM('男','女')
-- enum 枚举类型:可以起到指定的约束效果
);
7.外键约束(foreign key)
为了保证数据的有效性和完整性,需要在多表一方添加外键约束,去关联单表一方的主键,让这两张表之间产生相互的制衡
(1)实体
数据库中的就可以看作一个实体
实体和实体之间的关系
一对一,一对多,多对多
(2)特点
1.主表中不能删除从表中已引用的数据
2.从表中不能添加主表中不存在的数据
(3)案例演示
一对多 :用户和订单案例
-- 创建用户表
CREATE TABLE USER(
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(20)
);
-- 创建订单表
CREATE TABLE orders(
id INT PRIMARY KEY AUTO_INCREMENT,
totalprice DOUBLE,
user_id INT
);
-- 在多表一方添加外键约束去关联主表一方的主键
-- 在多表的一方添加外键约束格式:
-- alter table 多表名称 add foreign key(外键名称) references 一表名称(主键);
ALTER TABLE orders ADD FOREIGN KEY(user_id) REFERENCES USER(id);
8.修改表
(1)删除主键约束
-- 1.删除了唯一性,非空性可以正常使用
ALTER TABLE test DROP PRIMARY KEY;
-- 2.删除非空
ALTER TABLE test MODIFY NAME VARCHAR(20) NULL;
(2)删除一个有主键约束和自增长约束的字段
-- 1.删除自增长
ALTER TABLE test2 CHANGE id id INT;
-- 2.删除主键约束
ALTER TABLE test2 DROP PRIMARY KEY;
-- 3.删除非空约束
ALTER TABLE test2 MODIFY id INT NULL;
(3)删除外键约束
方式一:
– 1.删除从表中的数据
– 2.删除主表中的数据
方式二:级联删除,直接删除主表与从表的信息
ALTER TABLE orders ADD FOREIGN KEY(user_id) REFERENCES USER(id) ON DELETE CASCADE;
级联更新:更新主表与从表中的信息
ALTER TABLE orders ADD FOREIGN KEY(user_id) REFERENCES USER(id) ON UPDATE CASCADE;
三.数据库的存储过程
1.概念
存储过程是数据库中的一个对象,存储在服务端,用来封装多条SQL语句且带有逻辑性,可以实现一个功能,由于他在创建时,就已经对SQL进行了编译,所以执行效率高,而且可以重复调用,类似与我们Java中的方法
2.参数
in:输入参数
out:输出参数
inout:输入输出参数
DELIMITER $$
CREATE
PROCEDURE `performance_schema`.`myTestPro`(IN num INT,OUT r INT)
BEGIN
DELETE FROM emp WHERE empno=num;
SELECT COUNT(*) FROM emp INTO r;
END$$
DELIMITER ;
3.语法
基本写法演示:
DELIMITER $$
CREATE
PROCEDURE `performance_schema`.`myTestPro`()
BEGIN
END$$
DELIMITER ;
注意:创建存储过程需要管理员分配权限
(1)调用存储过程 call
call myTestPro(9527,@rr)
(2)删除存储过程 drop
drop procedure myTestPro;
(3)查看存储过程 show
show procedure status\G; – 查看所有的存储过程状态
show create procedure 存储过程名字\G; – 查看创建存储过程的语句
(4)带有IF逻辑的存储过程 if then elseif else
DELIMITER $$
CREATE PROCEDURE pro_testIf(IN num INT,OUT str VARCHAR(20))
BEGIN
IF num=1 THEN
SET str='星期一';
ELSEIF num=2 THEN --注意elseif 连在一块
SET str='星期二';
ELSEIF num=3 THEN
SET str='星期三'; -- 注意要用分号结束
ELSE
SET str='输入错误';
END IF; -注意要结束if 后面有分号
END $$
(5)带有循环的存储过程 while do
DELIMITER $
CREATE PROCEDURE pro_testWhile(IN num INT,OUT result INT)
BEGIN
-- 定义一个局部变量
DECLARE i INT DEFAULT 1;
DECLARE vsum INT DEFAULT 0;
WHILE i<=num DO
SET vsum = vsum+i;
SET i=i+1;
END WHILE; -- 要记得结束循环
SET result=vsum;
END $
(6)控制循环的两个关键字
leave 相当于java中的 break
iterate相当于java中的continue
(7)变量
1.全局变量(内置变量):
可以在多个会话中去访问他
查看所有全局变量:
show variables
查看某个全局变量:
select @@变量名
修改全局变量:
set 变量名=新值
2.局部变量:
在存储过程中使用的变量就叫局部变量。只要存储过程执行完毕,局部变量就丢失!!
定义局部变量的语法:
DECLARE i INT DEFAULT 1;
给变量设置值
set i=10;
3.会话变量:
只存在于当前客户端与数据库服务器端的一次连接当中。如果连接断开,那么会话变量全部丢失!
定义会话变量:
set @变量=值
查看会话变量:
select @变量
(8)编码
mysql服务器的接收数据的编码
character_set_client
mysql服务器输出数据的编码
character_set_results
设置数据库编码
SET character_set_client=gbk
查看数据库编码
SELECT @@character_set_client
四.数据库的触发器(Trigger)
1.概念
触发器:数据库中的一个对象,相当于JS中的监听器,触发器可以监听 增删改三个动作
例如:说我想监听一张表,只要我增删改了这张表中的数据,我就可以触发这个触发器,去往另外一张表中记录一下日志
2.基本语法
DELIMITER $$
CREATE TRIGGER `mytestdb`.`myTriger` BEFORE/AFTER INSERT/UPDATE/DELETE ON `mytestdb`.`<Table Name>` FOR EACH ROW
-- BEFORE 行为发生之前就触发
-- AFTER 行为发生之后触发
-- FOR EACH ROW 行级触发,每操作一行就触发
BEGIN
END$$
DELIMITER ;
案例演示:
我往一张表test中插入了数据,在日志表logger中添加一条记录
DELIMITER $$
CREATE TRIGGER `mytestdb`.`MyTri3` AFTER DELETE ON test FOR EACH ROW
BEGIN
INSERT INTO logger VALUES(NULL,"你删除了一条数据",NOW());
END$$
DELIMITER ;
old和new
old.字段
可以获取到被监听的表中的字段的旧值
new.字段
可以获取到被监听表中更新后的字段的新值 比如插入新值或者修改旧值
例如:我往一张表t1中添加一条数据,另一张表t2也要添加一条同样的数据
DELIMITER $$
CREATE TRIGGER `mytestdb`.`myTri6` AFTER INSERT ON `mytestdb`.`t1` FOR EACH ROW
BEGIN
INSERT INTO t2 VALUES(new.id,new.username,new.age);
END$$
DELIMITER ;
例如:我修改一张表t1中的数据,另一张表t2中的数据也要修改
DELIMITER $$
CREATE TRIGGER `mytestdb`.`MyTri7` AFTER UPDATE ON `mytestdb`.`t1` FOR EACH ROW
BEGIN
UPDATE t2 SET id=new.id,username=new.username,age=new.age WHERE id=old.id;
END$$
DELIMITER ;
五.视图(view)
1.概念
视图:有结构(有行有列),但没有结果(结构中不真实存储数据)的虚拟的表,虚拟表的结构来源不是自己定义,而是从对应的基表中产生(视图数据的来源)
2.创建视图语法
create view 视图名称 as select语句
这个语句可以是一张或多张表的的普通查询,或多表查询
视图一旦创建,系统会在视图对应的数据库文件夹下,创建一个对应的结构文件:frm文件.
创建单表视图
create view my_v1 as select * from student;
创建多表视图
create view my_v2 as select a.字段名,b.字段名 from a,b where a.id=b.id;
注意:
1.不要查询两张表中的同名字段 不然会报错
2.MySQL中视图不支持封装子查询查出来的数据
3.查看视图
show tables; desc my_v1
如果要查看视图创建语句的的时候把table 改成view
show create view my_v1;
4.视图的使用
select * from my_v1;
视图的执行其实本质就是执行封装的select 语句
5.删除视图
drop view 视图名称
例如:drop view my_v1
6.修改视图
视图本身不可以修改,但是视图的来源是可以修改的(其实就是修改select 语句)
例:alter view 视图名字 as 新的select语句
7.视图的意义
(1)视图可以节省SQL语句,将一条复杂的查询语句,使用视图进行保存,以后可以直接对视图进行操作.
(2)数据安全,视图操作注意是针对查询语句的,如果对视图结构进行处理(比如删除),不会影响基表的数据,所以相对来说数据比较安全
(3)视图往往是在大项目中去使用,而且是多系统中去使用.我可以对外提供一些有用的数据,隐藏一些关键的数据
(4)视图对外可以提供友好的数据:不同的视图提供不同的数据,对外提供的数据好像是经过专门设计的一样.
(5)视图可以更好的进行权限控制 比如对外隐藏我的一些基表的名称
8.视图数据的操作
视图是可以进行数据操作的(比如 增,删,改,视图中的数据),但是有很多限制
(1)视图插入数据
(1多表视图不能插入数据
(2单表视图中可以插入数据(如果视图中字段没有基表中不能为空的字段且没有默认值的字段,是插入不成功的)
(3视图是可以向基表中插入数据的 (视图的操作是影响基表的)
(2)视图删除数据
(1:多表视图不能删除数据
(2:单表视图可以删除数据,也会影响到基表
(3)视图更新数据
(1单表视图,多表视图都可以更新数据
更新限制:with check option
create view my_v1 as select * from student where age>30 with check option;
with check option 决定通过视图更新的时候,不能将已得到数据age>30的学生 改成age<30 的.
那么update my_v1 set age=20 where id=1; 就会报错 不允许改 因为做了限制
六.函数
1.概念
函数:包括内置函数,和自定义函数
2.自定义函数语法
DELIMITER $$
CREATE FUNCTION `mytestdb`.`myFun`(num INT)
RETURNS INT
BEGIN
DECLARE i INT DEFAULT 100;
SET i=i+num;
RETURN i;
END$$
DELIMITER ;
3.函数和存储过程的区别
1.存储过程没有返回值,函数必须要有返回值。但是存储过程可以用out能实现返回值这个作用
2.存储过程有in out inout 这几个参数类型 函数的参数全是用来收实参

















 6497
6497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









