




SpringAI整合OpenAI系列(三)
一、Embedding Models
在Spring AI中,提供了不同模型的嵌入(Embedding),我想分享一下我对Embedding这个概念的理解。简单来说,Embedding就是将你的数据转换成一种程序更容易理解的结构。
比如说,想象一下我们在看一张图片。我们看到的其实是由许多像素点组成的,而计算机并不能直接理解这些像素点。通过Embedding,我们可以把这张图片转化为一个向量(即一组数字),这样计算机就能更方便地处理和分析这张图片了。同样的道理也适用于文本、音频或其他类型的数据。比如,一段文字可以被转换成一个向量,代表它的含义和上下文。这样,当我们进行相似性搜索或其他机器学习任务时,计算机就能通过这些向量来比较和理解不同的数据。
总之,嵌入的目的就是把复杂的数据以一种简化而高效的方式表示出来,使得机器学习模型能够更好地理解和处理这些数据。这种转化不仅提高了计算效率,还能帮助模型捕捉到数据之间的潜在关系和相似性。
当然Spring AI中是提供了Embedding的能力,具体可以看一下官方的文档和Demo:https://docs.spring.io/spring-ai/reference/api/embeddings/openai-embeddings.html
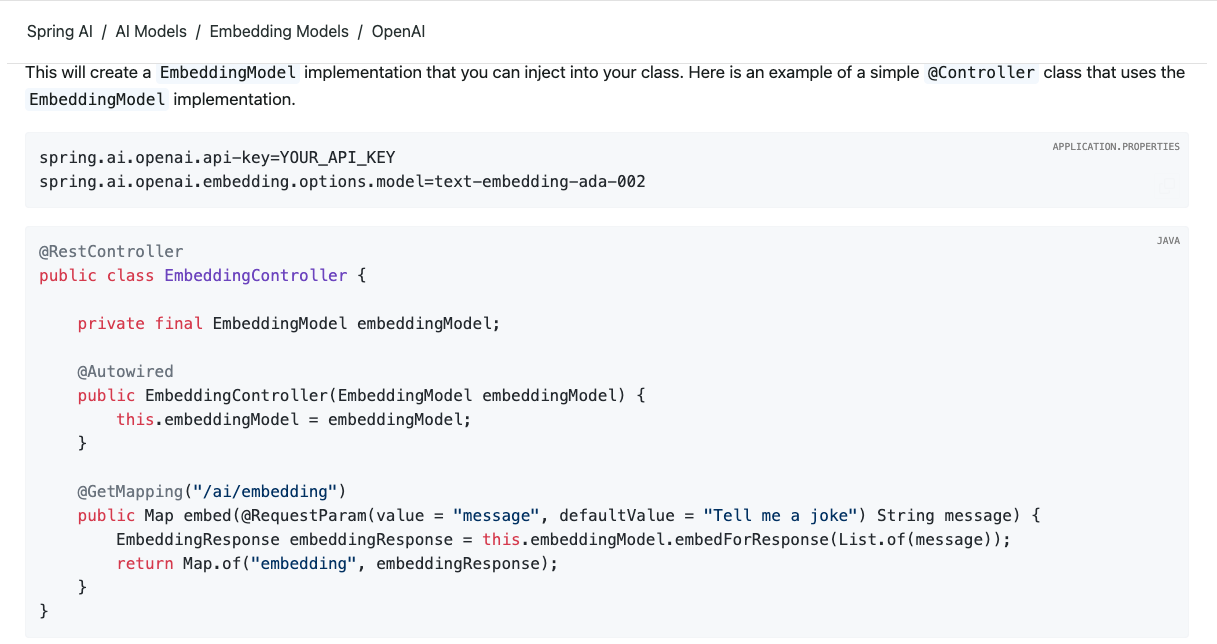
初步了解了Embedding的概念之后我们接下去就可以尝试理解向量数据库了
二、Vector Databases 向量数据库
向量数据库是一种特别的数据库类型,在人工智能(AI)应用中非常重要。
跟传统的关系数据库不一样,向量数据库的查询方式是基于相似性搜索,而不是精确匹配。当你输入一个向量作为查询时,向量数据库会返回与这个向量“相似”的其他向量。关于如何计算这种相似性,后面会有更详细的解释。
使用向量数据库的第一步是把你的数据加载进去。之后,当用户发出查询时,系统会先找出一组相似的文档。这些文档可以为用户的问题提供上下文,然后再把这些信息和用户的查询一起发送给AI模型。这种方法叫做检索增强生成(RAG)。
在向量数据库中,我们需要Embedding我们的原数据,其中这些原数据,就是生成我们RAG的基础数据,所以我们平时梳理文档的时候,应该尽量通俗易懂一些,而不是搞一些乌烟瘴气的概念,让人很难理解。
举个例子,你做BI报表查询的时候一定会有一些表达式吧
-
"country == 'BG'"
-
"genre == 'drama' && year >= 2020"
-
"genre in ['comedy', 'documentary', 'drama']"
这些内容需要梳理的文档
-
等于: '=='
-
减少 : '-'
-
增加: '+'
-
大于: '>'
-
大于等于: '>='
-
小于: '<'
-
小于等于: '<='
-
不等于: '!='
先将这个文档Embedding,然后存入redis(redis支持向量存储)
三、代码实现
首先我们添加redisStore的依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-store-spring-boot-starter</artifactId>
</dependency>
然后我们需要创建一个文档作为我们存储到向量数据库的基础数据,我这里存储两个文档,一个是我需要数据分析的表[结构性文档],另外一个是就是一些解释性文档。(当然这只是一个简单的DEMO,如果想实现BI智能分析的功能,就很考验数仓体系建设的完整度,沉淀的文档,相关的概念设计,这些是利用大模型实现BI报表的基础,如果有时间,我也会分享一些,我在数仓体系建设上的思考和总结)
下面是我的[结构性文档]
表名:dwd_order_detail
| 字段名 | 字段类型 | 是否主键 | 描述 | 设计说明 |
|---|---|---|---|---|
order_id |
STRING | 是 | 订单ID | 唯一标识订单,分布式ID或数据库生成。 |
user_id |
STRING | 否 | 用户ID | 唯一标识下单用户,与用户维度表关联。 |
| < |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 7137
7137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









