




 本文介绍了如何在Elasticsearch中安装和配置IK分词器,以解决默认中文分词不当的问题。通过对比ik_smart和ik_max_word两种分词算法,展示了它们在分词粒度上的差异。此外,还分享了如何自定义字典,确保特定词汇如'少司命'作为一个完整词被保留。最后,通过实例展示了分词效果,并提醒注意版本兼容性,以避免重启Elasticsearch时出现闪退。
本文介绍了如何在Elasticsearch中安装和配置IK分词器,以解决默认中文分词不当的问题。通过对比ik_smart和ik_max_word两种分词算法,展示了它们在分词粒度上的差异。此外,还分享了如何自定义字典,确保特定词汇如'少司命'作为一个完整词被保留。最后,通过实例展示了分词效果,并提醒注意版本兼容性,以避免重启Elasticsearch时出现闪退。
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神"会被分为"我"∵"爱"“狂"∵"神”,这显然是不符合要求的,所以我们需要安装中文分词器ik来
解决这个问题。
如果要使用中文,建议使用ik分词器!
IK提供了两个分词算法 : ik smart和ik_max_word,其中 ik_smart为最少切分,ik_max_word为最细粒度划分!一会我们测试!
分词器下载
ik分词器下载
注意版本要一致,否则重启elasticsearch闪退
下载完成后,解压放到elasticsearch的plugins中
重启elasticsearch 一直闪退(elasticsearch ,ik,kibana同版本) !!!
本人版本 v7.11.1官网此版本需要自行去进行编译
可在此下载别人编译好的文件
重启elasticsearch ,分词器ik被加载

elasticsearch-plugin list 查看加载的插件

分词算法
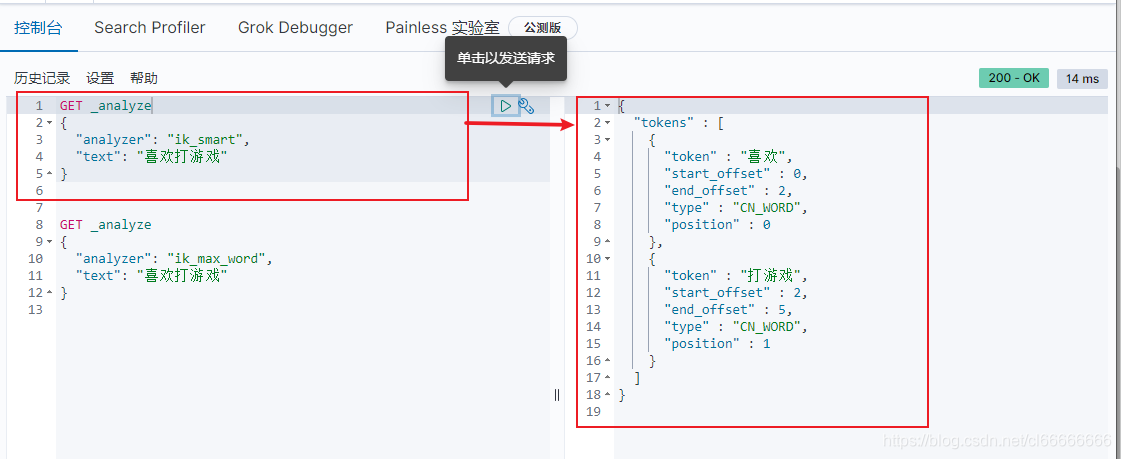
ik smart 最少切分;没有重复数据
GET _analyze
{
"analyzer": "ik_smart",
"text": "喜欢打游戏"
}
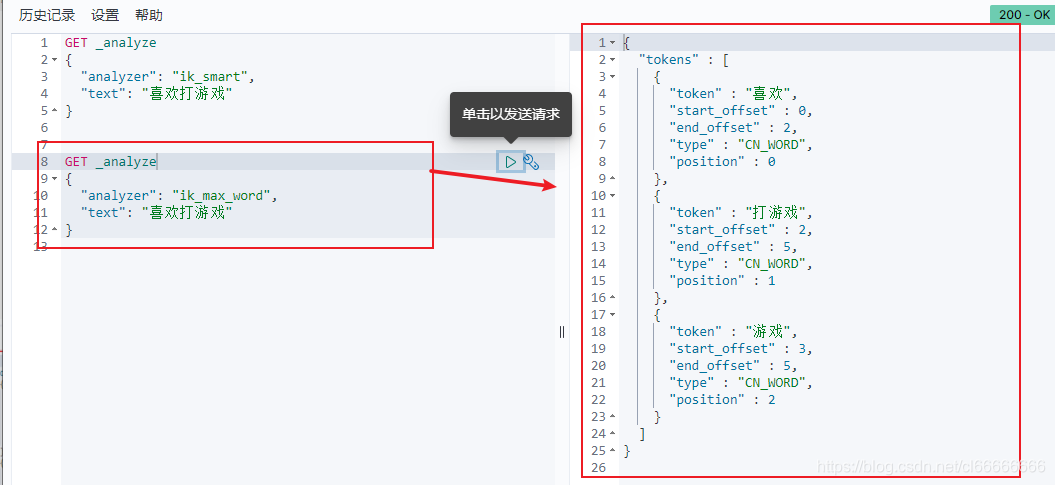
ik_max_word最细粒度划分;穷尽所有可能
GET _analyze
{
"analyzer": "ik_max_word",
"text": "喜欢打游戏"
}
分词器配置
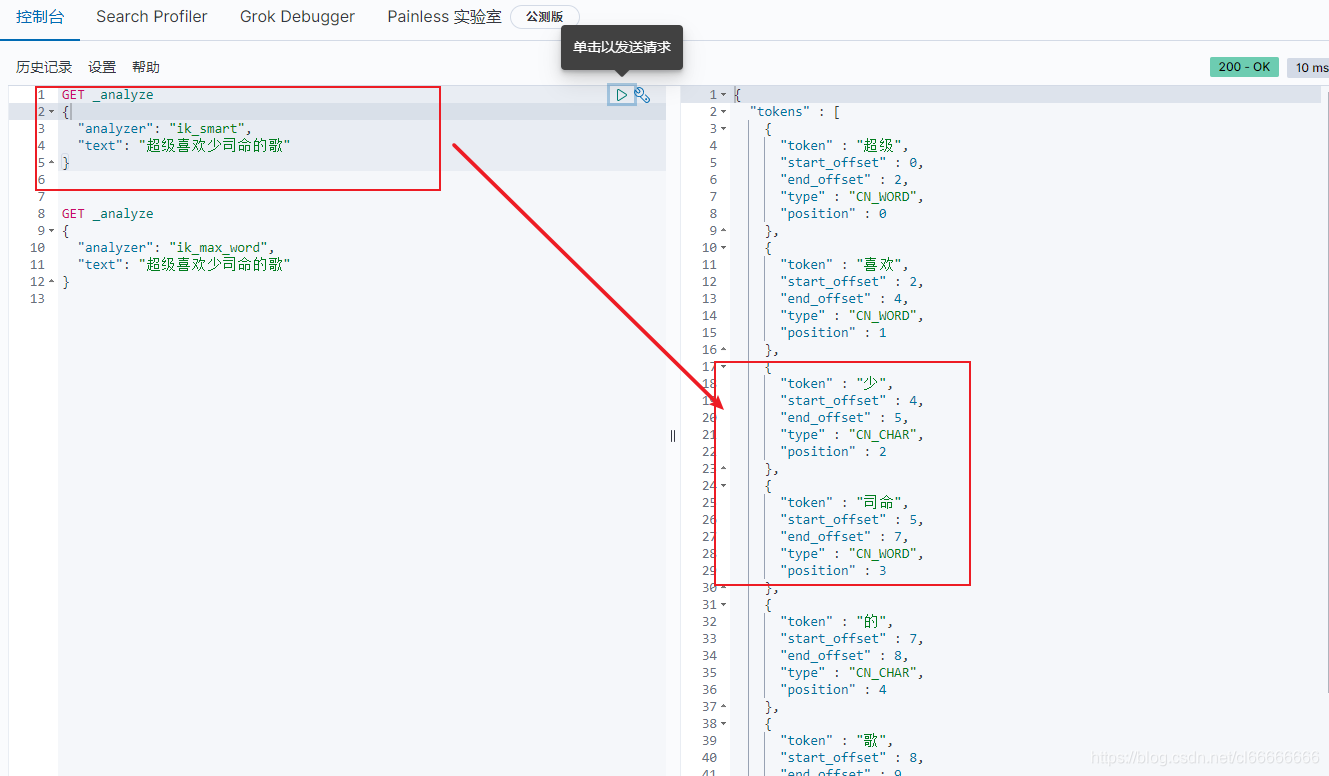
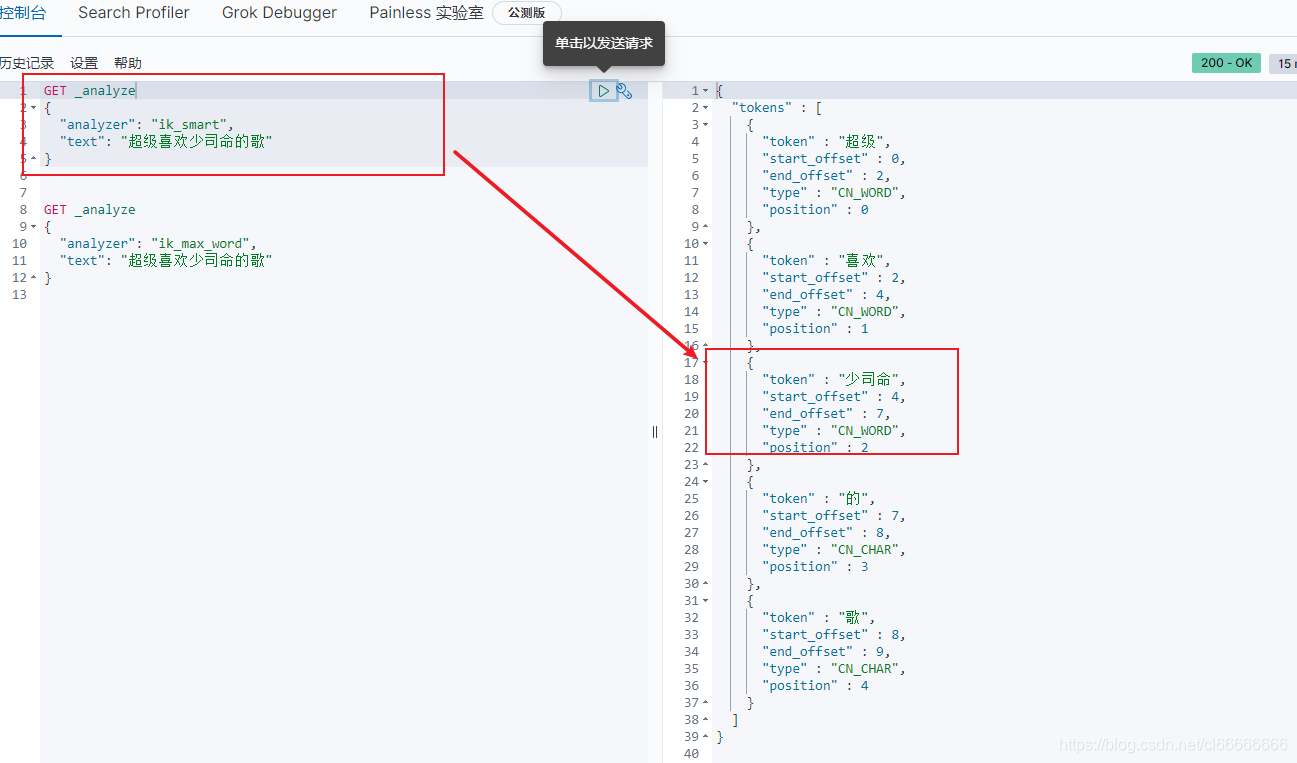
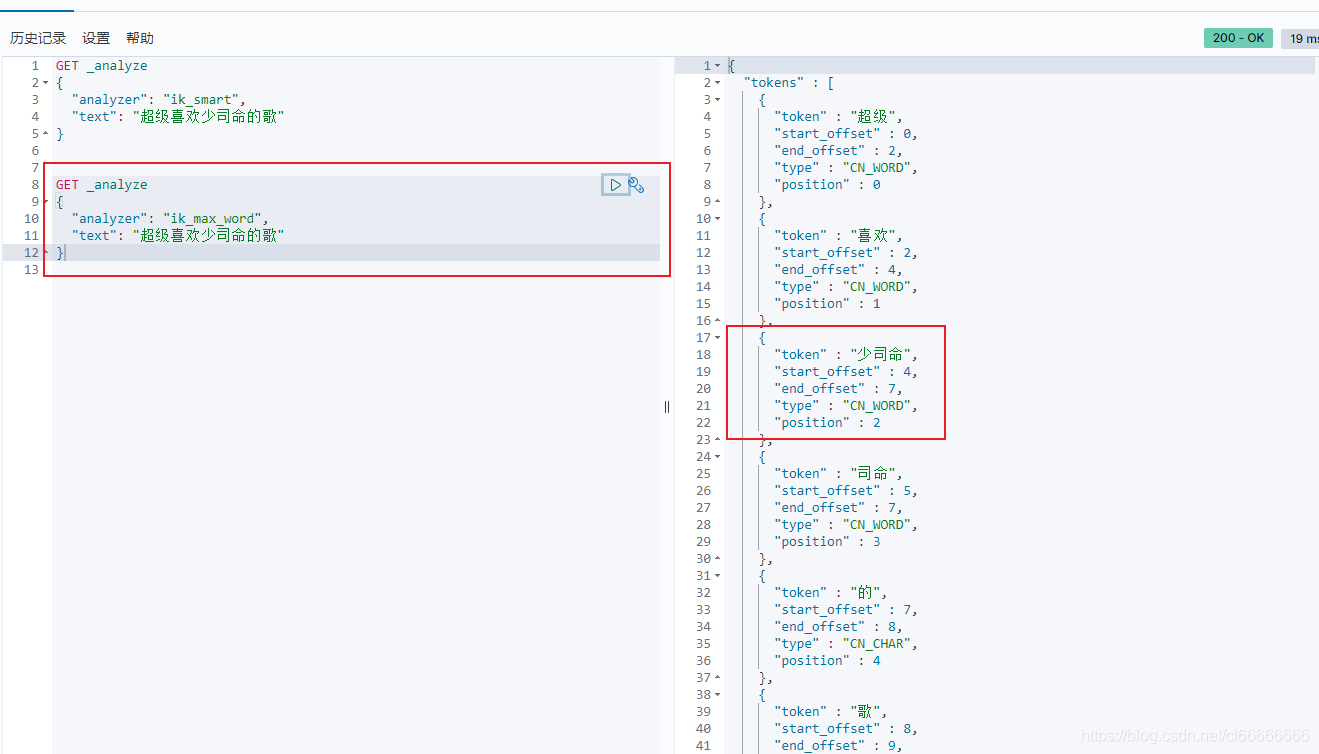
问题 :少司命 这个词被拆分了
这种自己需要的词,需要自己加到我们的分词器的字典中!|
ik分词器增加自己的配置
找到ik文件config目录
D:\elasticsearch\elasticsearch-7.11.1\plugins\elasticsearch-analysis-ik-7.11.1\config
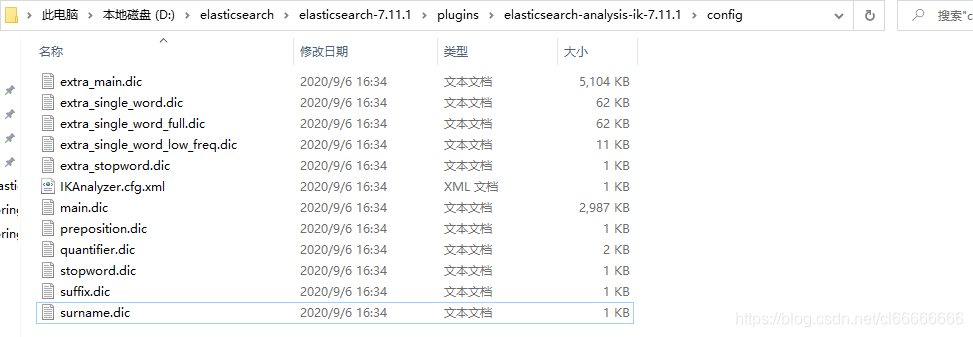
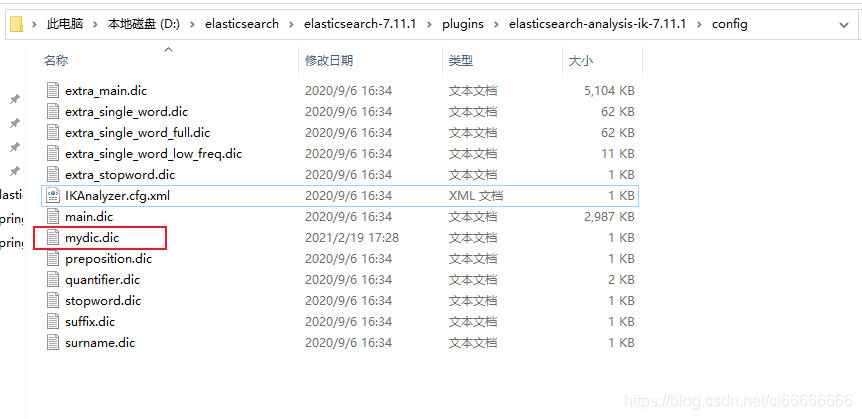
创建自己的dic文件;将 少司命 写在此文件中
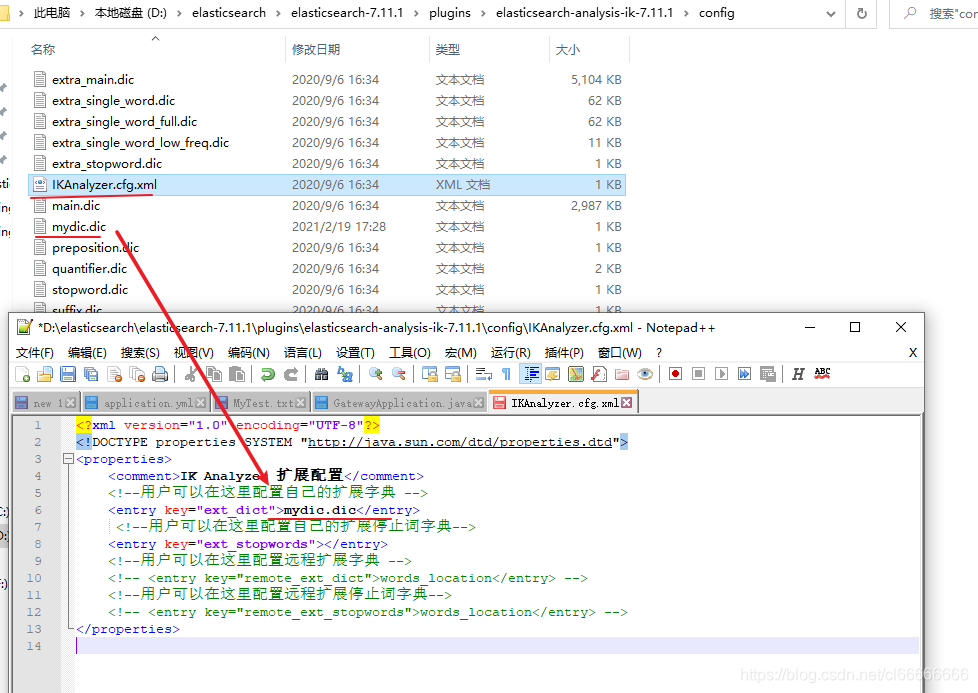
将此文件注入到 IKAnalyzer.cfg.xml 文件中
重启es,可以看到日志里加载了自定义的字典mydic.dic
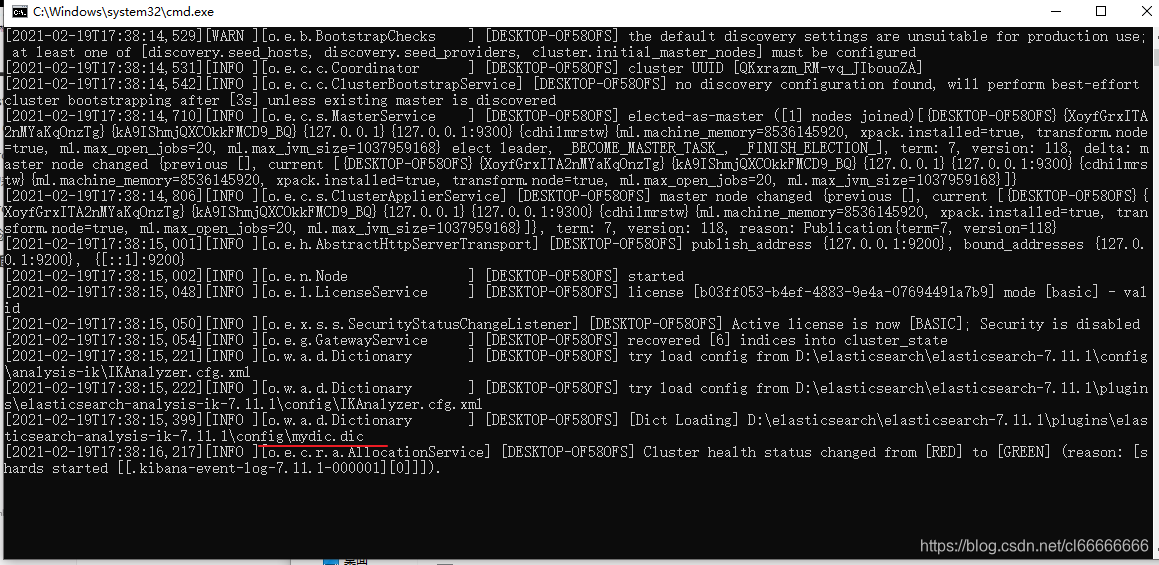
重启kibana,再进行测试
少司命 是一个完整的词


















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











