






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第9周:猫狗识别-2(训练营内部成员可读)
- 🍖 原作者:K同学啊|接辅导、项目定制
目录
一、代码及运行结果
一、前期工作
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
# 打印显卡信息,确认GPU可用
print(gpus)
import numpy as np
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import os,PIL,pathlib
#隐藏警告
import warnings
warnings.filterwarnings('ignore')
data_dir = "./365-9-data"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
图片总数为: 3400二、数据预处理
batch_size = 64
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
AUTOTUNE = tf.data.experimental.AUTOTUNE
def preprocess_image(image,label):
return (image/255.0,label)
# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(class_names[labels[i]])
plt.axis("off")Found 3400 files belonging to 2 classes.
Using 2720 files for training.
Found 3400 files belonging to 2 classes.
Using 680 files for validation.
['cat', 'dog']
(64, 224, 224, 3)
(64,)
三、构建VGG-16网络
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(1000, (img_width, img_height, 3))
model.summary()Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________四、编译
model.compile(optimizer="adam",
loss ='sparse_categorical_crossentropy',
metrics =['accuracy'])五、训练模型
from tqdm import tqdm
import tensorflow.keras.backend as K
epochs = 10
lr = 1e-4
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):
train_total = len(train_ds)
val_total = len(val_ds)
"""
total:预期的迭代数目
ncols:控制进度条宽度
mininterval:进度更新最小间隔,以秒为单位(默认值:0.1)
"""
with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=1,ncols=100) as pbar:
lr = lr*0.92
K.set_value(model.optimizer.lr, lr)
train_loss = []
train_accuracy = []
for image,label in train_ds:
"""
训练模型,简单理解train_on_batch就是:它是比model.fit()更高级的一个用法
想详细了解 train_on_batch 的同学,
可以看看我的这篇文章:https://www.yuque.com/mingtian-fkmxf/hv4lcq/ztt4gy
"""
# 这里生成的是每一个batch的acc与loss
history = model.train_on_batch(image,label)
train_loss.append(history[0])
train_accuracy.append(history[1])
pbar.set_postfix({"train_loss": "%.4f"%history[0],
"train_acc":"%.4f"%history[1],
"lr": K.get_value(model.optimizer.lr)})
pbar.update(1)
history_train_loss.append(np.mean(train_loss))
history_train_accuracy.append(np.mean(train_accuracy))
print('开始验证!')
with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=0.3,ncols=100) as pbar:
val_loss = []
val_accuracy = []
for image,label in val_ds:
# 这里生成的是每一个batch的acc与loss
history = model.test_on_batch(image,label)
val_loss.append(history[0])
val_accuracy.append(history[1])
pbar.set_postfix({"val_loss": "%.4f"%history[0],
"val_acc":"%.4f"%history[1]})
pbar.update(1)
history_val_loss.append(np.mean(val_loss))
history_val_accuracy.append(np.mean(val_accuracy))
print('结束验证!')
print("验证loss为:%.4f"%np.mean(val_loss))
print("验证准确率为:%.4f"%np.mean(val_accuracy))开始验证!
Epoch 1/10: 100%|██████████████████| 11/11 [00:03<00:00, 3.04it/s, val_loss=0.6754, val_acc=0.6750]
结束验证!
验证loss为:0.6509
验证准确率为:0.6636
Epoch 2/10: 100%|██| 43/43 [00:10<00:00, 4.01it/s, train_loss=0.6304, train_acc=0.6094, lr=8.46e-5]
开始验证!
Epoch 2/10: 100%|██████████████████| 11/11 [00:01<00:00, 9.68it/s, val_loss=0.6856, val_acc=0.5750]
结束验证!
验证loss为:0.5927
验证准确率为:0.6830
.......
Epoch 10/10: 100%|█| 43/43 [00:11<00:00, 3.90it/s, train_loss=0.0462, train_acc=0.9844, lr=4.34e-5]
开始验证!
Epoch 10/10: 100%|█████████████████| 11/11 [00:01<00:00, 9.74it/s, val_loss=0.0685, val_acc=0.9750]
结束验证!
验证loss为:0.0732
验证准确率为:0.9736六、模型评估
epochs_range = range(epochs)
plt.figure(figsize=(14, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, history_train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, history_val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, history_train_loss, label='Training Loss')
plt.plot(epochs_range, history_val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()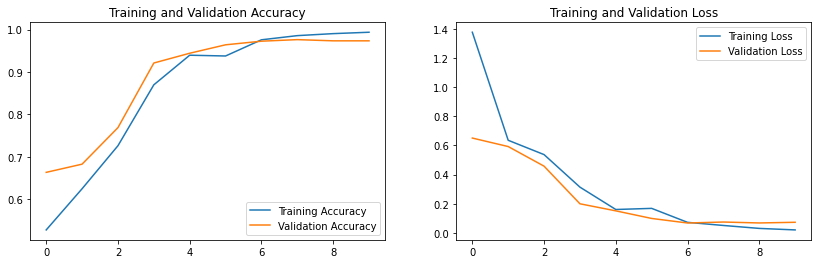
七、预测
import numpy as np
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(18, 3)) # 图形的宽为18高为5
plt.suptitle("预测结果展示")
for images, labels in val_ds.take(1):
for i in range(8):
ax = plt.subplot(1,8, i + 1)
# 显示图片
plt.imshow(images[i].numpy())
# 需要给图片增加一个维度
img_array = tf.expand_dims(images[i], 0)
# 使用模型预测图片中的人物
predictions = model.predict(img_array)
plt.title(class_names[np.argmax(predictions)])
plt.axis("off")
二、个人总结
Matplotlib库:
plt.rcParams 是Matplotlib库中的一个函数,用于配置全局的绘图参数,以影响绘制的样式和外观。通过调用plt.rcParams,你可以设置绘图时的各种参数,如字体、线条样式、颜色等,以定制图形的外观。这函数允许你在整个绘图会话中保持特定样式的一致性。
plt.rcParams函数的调用
1.使用圆括号 ():
plt.rcParams 是一个函数,通常情况下,我们使用圆括号 () 来调用函数并传递参数。例如,如果要调用 plt.rcParams 函数并传递参数设置,可以这样做:
plt.rcParams(param1=value1, param2=value2, ...)其中 param1, param2, ... 是函数的参数,value1, value2, ... 是对应参数的值。这种调用方式将根据函数的定义执行相应的操作。
2.使用[],以赋值的形式:
然而,对于 plt.rcParams 这个函数,它一般以赋值的方式使用,将参数设置为特定的值。例如:
plt.rcParams['font.sans-serif'] = ['SimHei']这里使用的是赋值操作,而不是直接调用函数。这种方式用于设置特定参数的值,而不是调用函数执行某些操作。
使用方括号 [] 只是为了设置特定参数的值,不涉及直接调用该函数或接受函数的返回值。这种写法是为了设置全局参数,以影响后续绘图的外观,而不是执行某个特定的函数。
plt.rcParams 参数说明
plt.rcParams 是Matplotlib库中用于配置绘图参数的函数。它接受一个字典作为参数,用于指定各种绘图参数的值。
常用的参数及说明如下:
-
'font.family': 设置字体族(family),如'serif'、'sans-serif'等。 -
'font.sans-serif': 设置无衬线字体,用于显示中文等。 -
'font.size': 设置字体大小。 -
'axes.labelsize': 设置坐标轴标签的字体大小。 -
'axes.titlesize': 设置图表标题的字体大小。 -
'lines.linewidth': 设置线条宽度。 -
'lines.color': 设置线条颜色。 -
'axes.grid': 设置是否显示网格。
这些参数可以通过 plt.rcParams 进行设置,以定制图表的样式和外观,使得图表符合特定的显示需求。
import matplotlib.pyplot as plt
# 设置字体为Helvetica,字体大小为12
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = ['Helvetica']
plt.rcParams['font.size'] = 12
# 设置线条宽度为2,颜色为红色
plt.rcParams['lines.linewidth'] = 2
plt.rcParams['lines.color'] = 'red'
# 显示网格
plt.rcParams['axes.grid'] = True
# 创建示例数据
x = [1, 2, 3, 4, 5]
y = [10, 12, 15, 13, 17]
# 绘制折线图
plt.plot(x, y)
# 添加标题和标签
plt.title('示例折线图')
plt.xlabel('X轴')
plt.ylabel('Y轴')
# 显示图表
plt.show()代码说明:
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号font.sans-serif:
-
plt.rcParams['font.sans-serif']是plt.rcParams函数的一个特定设置,用于指定绘图时所使用的字体族(family),通常用于支持特定字体以确保在图表中能正确显示中文或其他特定字符集。-
'font.family': 设置字体族(family),如'serif'、'sans-serif'等。 -
'font.sans-serif': 设置无衬线字体,用于显示中文等。
-
-
在这个代码片段中,
plt.rcParams['font.sans-serif'] = ['SimHei']设置了字体族为 SimHei,这是指定绘图时要使用的中文字体,确保在图表中能正确显示中文。SimHei 是中文宋体的一种常用字体。
axes.unicode_minus:
-
plt.rcParams['axes.unicode_minus'] = False是一条设置,用于正常显示负号('-')的配置。在某些情况下,特别是在显示中文标签时,可能会遇到负号显示为方框或乱码的问题。通过设置这个参数为False,可以确保负号能够正确显示,避免显示异常。这样做是为了保证在图表中正确显示负号,避免可能出现的显示问题。
-
如果将
plt.rcParams['axes.unicode_minus']设置为True,则会恢复默认行为。在默认情况下,Matplotlib会尝试使用 Unicode 来显示负号('-')。设置为
True可能是多余的,因为这是默认行为,但如果在特定情况下设置为True,可能会影响到负号的显示,特别是在使用中文标签时。通常,将其设置为False是为了确保负号能够正确显示,特别是在中文环境中。
Warnings模块:
#隐藏警告
import warnings
warnings.filterwarnings('ignore')这段代码使用了 Python 的 warnings 模块,通过 warnings.filterwarnings('ignore') 来隐藏警告信息。
具体来说,warnings.filterwarnings('ignore') 的作用是将警告信息忽略,不显示在标准输出中。这样可以在一定程度上减少输出的干扰,特别是当你知道某些警告对你的代码逻辑没有实质影响时,可以选择忽略这些警告。然而,需要谨慎使用,因为警告信息有时可能是代码中潜在问题的指示。
这段代码的目的是在程序运行时不显示警告,可能是为了提高程序输出的整洁程度。
warnings.filterwarnings 函数说明
warnings.filterwarnings 是 Python 的 warnings 模块中的一个函数,用于设置警告信息的处理方式。该函数允许你配置如何处理特定类型的警告信息。
语法:
warnings.filterwarnings(action, message='', category=Warning, module='', lineno=0, append=False)参数说明:
-
action: 设置警告处理的动作,可以是字符串或警告类。 -
message: 警告消息的匹配规则,可以是字符串或正则表达式。 -
category: 警告的类别,默认为Warning。 -
module: 警告来源的模块名。 -
lineno: 警告所在的行号。 -
append: 是否将新设置添加到已有的警告设置中,默认为False。
常见的 action 值包括:
-
'error': 将警告视为错误。 -
'ignore': 忽略警告,不显示。 -
'always': 总是显示警告。 -
'default': 恢复默认行为,即显示警告。
例子:
import warnings
# 忽略特定类型的警告
warnings.filterwarnings('ignore', category=DeprecationWarning)
# 忽略所有警告
warnings.filterwarnings('ignore')
# 将警告视为错误
warnings.filterwarnings('error')这样可以根据需要对警告进行不同的处理,例如忽略特定类型的警告,将警告视为错误等。
特定常量AUTOTUNE:
AUTOTUNE 是 TensorFlow(通常以 tf 别名引入)中的一个特定常量,用于指定数据加载和预处理时的自动调优程度。它是 TensorFlow 中的一种优化技术,可以自动选择最佳的参数来加速数据管道的性能。
具体来说,AUTOTUNE 是一个特殊常量,它的值会告诉 TensorFlow 在数据加载和预处理时自动调整并选择合适的并行级别,以最大程度地利用计算资源,从而提高数据管道的效率。
通常,你会在数据加载、预处理或数据管道构建的过程中看到类似以下用法:
import tensorflow as tf
AUTOTUNE = tf.data.AUTOTUNE
# 在数据加载时使用AUTOTUNE来自动选择并行级别
dataset = dataset.prefetch(buffer_size=AUTOTUNE)这样,TensorFlow 会根据可用的系统资源自动选择合适的并行级别,以加速数据处理过程。
map 函数详解
map 函数是 TensorFlow 数据集(tf.data.Dataset)中的一个重要方法,用于对数据集中的每个元素应用指定的函数,实现数据的预处理、转换或其他操作。
语法:
dataset.map(map_func, num_parallel_calls=None, deterministic=None)参数说明:
-
map_func: 要应用于每个元素的函数。可以是一个普通函数或一个函数的包装器。 -
num_parallel_calls: 并行调用的数量。可以是一个整数或tf.data.experimental.AUTOTUNE。 -
deterministic: 控制映射是否确定性。默认为None。
常用参数 map_func 通常是一个预处理函数,用于对数据集中的每个元素进行处理,例如图像的预处理。
例子:
import tensorflow as tf
# 定义一个简单的预处理函数
def preprocess_image(image):
# 进行图像处理
processed_image = ... # 具体的图像处理操作
return processed_image
# 创建一个数据集
dataset = ... # 假设已经创建了一个数据集
# 应用预处理函数到数据集
dataset = dataset.map(preprocess_image)
# 使用 AUTOTUNE 自动选择并行调用数量
dataset = dataset.map(preprocess_image, num_parallel_calls=tf.data.AUTOTUNE)在这个例子中,我们定义了一个预处理函数 preprocess_image,然后通过 map 函数将该函数应用到数据集中的每个元素,对图像进行预处理。使用 num_parallel_calls 可以指定并行调用的数量,加速数据处理过程。
同样使用 preprocess_image,不设置 num_parallel_calls 与设置为 tf.data.AUTOTUNE 有什么区别 ?
在使用 dataset.map() 函数时,可以选择不设置 num_parallel_calls 或将其设置为 tf.data.AUTOTUNE。
-
不设置
num_parallel_calls:dataset = dataset.map(preprocess_image)这种情况下,TensorFlow 将自动选择适当的并行调用数量,但可能不会充分利用系统资源,可能导致数据处理速度较慢。
-
设置为
tf.data.AUTOTUNE:dataset = dataset.map(preprocess_image, num_parallel_calls=tf.data.AUTOTUNE)使用
tf.data.AUTOTUNE将让 TensorFlow 自动选择并行调用的数量,以充分利用系统资源并加速数据处理。这个参数可以根据可用的 CPU 核心数和其他系统资源进行动态调整。
通常情况下,推荐使用 tf.data.AUTOTUNE 来动态选择并行调用的数量。这样可以确保在不同硬件配置下都能获得良好的性能,同时不需要手动调整并行调用数量。
可视化数据:
plt.subplot函数的使用:
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(class_names[labels[i]])
plt.axis("off")这段代码用于在一个 5x8 的图形网格中显示图像,每个图像对应一个子图。让我逐步解释:
-
ax = plt.subplot(5, 8, i + 1): 创建一个子图,该子图位于一个 5 行 8 列的网格中的第(i + 1)个位置。i是循环变量,用于遍历图像列表。 -
plt.imshow(images[i]): 用imshow函数显示第i个图像。images是图像的列表或数组,images[i]表示第i个图像。 -
plt.title(class_names[labels[i]]): 为子图设置标题,标题为对应标签的类名。labels是标签列表,labels[i]表示第i个图像的标签。class_names是类别名称列表,class_names[labels[i]]表示第i个图像的类名。 -
plt.axis("off"): 关闭坐标轴,使图像不显示坐标轴。
这样,循环遍历每个图像,分别在对应的子图上显示图像,并设置对应的标题,最后关闭坐标轴。整体效果是将图像以 5x8 的网格形式展示出来。
使用plt.subplot()函数赋值与不赋值的区别 ?
使用 plt.subplot(5, 8, i + 1) 创建子图时,可以选择将返回的子图对象(Axes 对象)赋值给 ax 变量,也可以不赋值。
-
如果你选择赋值给
ax变量,可以后续通过ax对象来操作子图,比如设置标题、坐标轴等。 -
如果不赋值给
ax变量,也可以直接通过plt对象操作子图,操作只会直接影响最后创建的子图。-
在Matplotlib中,你可以通过
plt对象直接操作最近创建的子图,但这并不会影响之前创建的子图。也就是说,plt对象的操作仅影响到最后一个子图。例如,假设你先创建了一个子图
ax1,然后创建了另一个子图ax2,如果你使用plt对象进行一些操作(如修改标题、坐标轴等),这些操作只会影响到最后创建的子图ax2,不会影响之前创建的ax1。示例:
import matplotlib.pyplot as plt # 创建第一个子图 ax1 = plt.subplot(1, 2, 1) ax1.plot([1, 2, 3], [4, 5, 6]) ax1.set_title('Plot 1') # 创建第二个子图 ax2 = plt.subplot(1, 2, 2) ax2.plot([1, 2, 3], [6, 5, 4]) ax2.set_title('Plot 2') # 使用 plt 对象直接修改最近创建的子图 plt.title('Modified Title') # 这会修改第二个子图的标题 plt.xlabel('X Label') # 这会修改第二个子图的X轴标签 # 显示图形 plt.show()在这个例子中,
plt.title('Modified Title')和plt.xlabel('X Label')只会影响到最后创建的子图ax2,而不影响之前创建的子图ax1。
-
VGG-16网络:
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(1000, (img_width, img_height, 3))
model.summary()Input函数:
input_tensor = Input(shape=input_shape)input_tensor = Input(shape=input_shape) 这行代码的作用是定义模型的输入层,为后续的模型构建提供输入的形状和大小。
具体来说:
-
Input是 Keras 提供的函数,用于创建一个输入层。 -
shape=input_shape定义了输入层的形状,也就是输入数据的形状。input_shape是在调用该函数时传入的参数,通常是一个元组,表示输入数据的形状,比如(img_width, img_height, 3)表示图像的宽、高和通道数。
这样做的目的是明确模型的输入形状,以便后续构建模型时能够知道输入数据的尺寸。在构建模型时,这个输入层会被作为第一层加入模型中。
举例:
input_tensor = Input(shape=(64, 64, 3))这里定义了一个输入层,输入图像的形状是 64x64 像素,具有 3 个通道(RGB)。
block:
在VGG16模型中,"block" 是指一组卷积层和池化层的堆叠,用于提取图像特征。这些卷积层和池化层通常以一种顺序组合在一起,形成一个 "block"。
具体来说,在VGG16模型中,这些 "block" 分为五组,每组包含一定数量的卷积层,后面跟着一个最大池化层。这样的 "block" 结构有助于逐步提取图像的特征,从较低级别的特征(如边缘和纹理)到更高级别的特征(如形状和模式)。
在代码中,每一个 "block" 都以 Conv2D 卷积层开始,然后是另一个 Conv2D 卷积层,最后是 MaxPooling2D 池化层。每个 "block" 都以这种结构来构建。
例如,这段代码中的 "1st block" 就包括了两个卷积层 (Conv2D) 和一个最大池化层 (MaxPooling2D),这就是一个 "block"。后续的 "2nd block"、"3rd block" 等也是按照类似的结构构建的。
层与层之间的连接:
为什么 x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)后面有个(input_tensor) ?
在代码 x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor) 中,(input_tensor) 的作用是将 Conv2D 层的输入指定为 input_tensor,也就是指定这个卷积层的输入是之前定义的输入层 input_tensor。
Keras 中的模型可以通过函数式 API 连接不同的层,这个连接是通过将一个层的输出作为另一个层的输入来实现的。在这种情况下,input_tensor 是一个输入层,Conv2D 是一个卷积层,这样的语法 (input_tensor) 表示将 input_tensor 作为 Conv2D 的输入。
这种方式可以帮助构建复杂的模型,特别是当你想要定义多个输入或多个输出时。在 VGG16 模型中,我们只有一个输入,因此 Conv2D 层只有一个输入,即 input_tensor。
总的来说,这种语法允许你清晰地指定每一层的输入,使模型的连接更直观、清晰。
连接的规则:
在Keras中,使用函数式API进行层的链接(也称为模型组装)时,有几个重要的条件和注意事项:
-
Input层的定义:
-
你需要首先定义一个输入层,使用
Input(shape=...)来指定输入的形状。 -
这个输入层是你模型的起点,它定义了模型的输入形状。
-
-
层的连接:
-
使用层的输出作为下一层的输入,通过将上一层的输出作为下一层的调用参数来实现连接。
-
这种方式保证了模型的层次结构和数据流。
-
-
每一层只能连接一次:
-
每个层只能在模型中连接一次,不能多次连接到不同的层。
-
-
保持连接顺序:
-
确保连接的顺序与你想要的模型结构相符合。
-
先连接的层在模型中的位置越靠前。
-
示例:
from tensorflow.keras.layers import Input, Dense
# 定义输入层
input_layer = Input(shape=(10,))
# 定义第一个隐藏层,连接到输入层
hidden_layer1 = Dense(20, activation='relu')(input_layer)
# 定义第二个隐藏层,连接到第一个隐藏层
hidden_layer2 = Dense(10, activation='relu')(hidden_layer1)
# 定义输出层,连接到第二个隐藏层
output_layer = Dense(1, activation='sigmoid')(hidden_layer2)
# 构建模型
model = Model(inputs=input_layer, outputs=output_layer)在这个例子中,hidden_layer1 连接到 input_layer,hidden_layer2 连接到 hidden_layer1,output_layer 连接到 hidden_layer2。这保持了模型层次结构的正确连接顺序。
是不是只有 keras 才可以这样使用 ?
主要针对 Keras,特别是 Keras 的函数式 API,可以方便地使用这种方式链接层。Keras 是一个高级神经网络库,提供了简洁而直观的API,可以用来构建、训练和部署深度学习模型。
TensorFlow 2.x 版本已经将 Keras 作为其官方高级 API 集成到了 TensorFlow 中,并成为 TensorFlow 的默认接口,所以在 TensorFlow 2.x 中可以直接使用 Keras。
例如,可以使用 TensorFlow 的 Keras 模块来构建模型,这样也可以使用函数式 API 链接层。示例:
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
# 定义输入层
input_layer = Input(shape=(10,))
# 定义第一个隐藏层,连接到输入层
hidden_layer1 = Dense(20, activation='relu')(input_layer)
# 定义第二个隐藏层,连接到第一个隐藏层
hidden_layer2 = Dense(10, activation='relu')(hidden_layer1)
# 定义输出层,连接到第二个隐藏层
output_layer = Dense(1, activation='sigmoid')(hidden_layer2)
# 构建模型
model = tf.keras.Model(inputs=input_layer, outputs=output_layer)这样可以在 TensorFlow 中使用 Keras 的函数式 API 链接层,构建模型。所以,这种方式不仅适用于纯 Keras,也适用于 TensorFlow 中的 Keras API。
Conv2D 卷积层:
在 Conv2D 中的第一个参数,比如64、128、256,表示卷积核(或过滤器)的数量。每个卷积核用于检测图像中的特定特征。
具体来说:
-
64、128、256 等数字代表了卷积层中的卷积核的数量。这些数字通常以2的幂次方增加,以便有效地进行计算。
-
每个卷积核负责检测图像中的某些特征,如边缘、纹理、形状等。
-
更多的卷积核意味着模型能够学习更多不同类型的特征。
在通常情况下,随着层次的加深,卷积核的数量可能会逐渐增加。这是因为在模型的较早层中,模型通常学习一些基本的特征,如边缘和颜色变化。而随着层次的加深,模型可以学习到更抽象、更复杂的特征,因此需要更多的卷积核。
需要注意的是,增加卷积核数量也会增加模型的参数量,可能会增加过拟合的风险。在设计卷积神经网络时,需要根据具体任务和数据集进行适当的选择。
这些参数是不是代表着输出张量的通道数 ?
在卷积神经网络(CNN)中,这些参数确实代表着卷积层输出张量的通道数或深度。
具体来说,每个卷积核对输入进行卷积运算,生成一个特征图(也称为卷积层的输出)。每个卷积核对应一个特征图,因此卷积核的数量就是输出张量的通道数。
举例:
-
如果一个卷积层的第一个参数是64,那么该层会有64个卷积核,产生64个特征图,输出张量的通道数也是64。
-
如果另一个卷积层的第一个参数是128,那么该层会有128个卷积核,产生128个特征图,输出张量的通道数是128。
因此,这些参数直接影响了卷积层输出张量的通道数,这个通道数决定了后续层的输入通道数。通道数的变化对于网络的学习能力和特征提取能力有重要影响。
Dense 全连接层:
x = Flatten()(x)这几行代码定义了全连接层(Fully Connected Layer)部分。让我逐一解释这些操作:
-
x = Flatten()(x):
-
Flatten()是将输入展平为一维向量的操作。这通常用于将卷积层的输出展平,以便连接到全连接层。 -
这一步将卷积层输出的特征图展平为一个长向量,为后续的全连接层做准备。
-
-
x = Dense(4096, activation='relu', name='fc1')(x):
-
Dense(4096, activation='relu', name='fc1')创建一个包含 4096 个神经元的全连接层,并使用 ReLU 激活函数。 -
这一步引入了全连接层,每个神经元与前一层的所有神经元连接。
-
4096 是这一层的神经元数量,可以根据需要调整。
-
-
x = Dense(4096, activation='relu', name='fc2')(x):
-
类似地,这一步再次创建一个包含 4096 个神经元的全连接层,使用 ReLU 激活函数。
-
这一层也有 4096 个神经元,可以根据需要调整。
-
这两个全连接层的目的是将卷积层提取的特征展开,并连接到最终的输出层,以便进行分类或其他任务。这种结构允许模型学习更高级别的特征和模式,为分类任务提供基础。
Flatten 和 Dense
Flatten() 和 Dense 在神经网络中都与全连接层(Fully Connected Layer)相关,但它们不是同一类型的层。
-
Flatten层:
-
Flatten()是 Keras 中的一个层,用于将输入展平为一维向量。 -
它不包含任何权重或可训练参数,仅执行数据重塑操作。
-
通常用于将卷积层的输出(二维特征图)展平为一维向量,以便连接到全连接层。
-
-
Dense层:
-
Dense是全连接层,也称为密集连接层。 -
在全连接层中,每个神经元与前一层的所有神经元相连接。
-
Dense层包含权重和偏置项,这些参数会在训练过程中学习和优化。 -
通过
Dense层可以实现输入与所有神经元的连接。
-
所以,Flatten() 用于数据重塑,没有可训练参数,而 Dense 是真正的全连接层,包含可训练的权重和偏置项。
在一般情况下,通常会在卷积神经网络(CNN)中使用卷积层和池化层来提取特征,然后通过 Flatten() 将特征展平,最后使用多个 Dense 全连接层来进行分类或其他任务。
Flatten 与 Dense 是怎么配合工作的,Dense 与Dense 又是怎么配合的 ?
-
Flatten 层与 Dense 层的配合:
-
在典型的卷积神经网络(CNN)中,卷积层和池化层用于提取图像的特征。这些层生成的特征图是多维的,但在连接到全连接层之前,我们通常需要将这些特征展平为一维向量。
-
这时就需要使用
Flatten层,它将多维特征图展平为一维向量,保持了特征的顺序,但去除了维度信息。
-
-
Dense 层与 Dense 层的配合:
-
在全连接层中,不同的
Dense层可以串联在一起,形成多层全连接结构。 -
例如,第一个
Dense层接收来自前一层的展平后的特征向量作为输入,执行线性变换和非线性激活(如 ReLU)操作,并输出新的特征向量。 -
这个新的特征向量会作为下一个
Dense层的输入,再次执行线性变换和非线性激活,得到更高级的特征表示。 -
这样,通过多个
Dense层的叠加,模型可以逐渐学习到更抽象、更复杂的特征,并进行最终的分类或预测。
-
这种结构充分利用了神经网络的层次化特性,通过特征的逐步提取和组合,实现对复杂任务的建模和学习。
Flatten 用于将输入展平为一维向量, Dense 创建一个包含 n 个神经元的全连接层,一维向量是怎么传个这 n 个神经元的 ?
假设输入向量 x 是 1×3 的一维向量,对于一个具有 5 个神经元的全连接层:
-
权重 W 将是一个 5×3 的矩阵,每一行对应一个神经元的权重,每列对应 x 中的一个特征。
-
偏置项 b 是一个 1×5 的向量,每个神经元有一个对应的偏置项。
运算过程如下:
-
W⋅x 进行矩阵乘法,得到一个 1×5 的结果向量,每个元素代表对应神经元的加权和。
-
加上偏置项 b,对应元素相加,得到每个神经元的输入值。
-
每个神经元的输入值通过激活函数(如 ReLU、Sigmoid 等)进行非线性变换,得到每个神经元的输出。
这样,每个神经元都会对输入向量 x 产生一个输出,这些输出组成了全连接层的输出。每个神经元都有自己的权重和偏置项,因此能够学习不同的特征和模式。
然后这些输出再当成下一层全连接层的输入,像之前那样 W⋅x+b,然后再非线性激活。这就是神经网络的前向传播过程。
神经网络的前向传播过程:
每个全连接层的输出就是下一层的输入。所以,将上一层全连接层的输出作为下一层的输入,然后再应用权重 W、偏置项 b,最后通过非线性激活函数。
具体流程如下:
-
上一层的输出(或者说特征向量)作为输入传递给当前全连接层。
-
对输入应用权重矩阵 W 和偏置 b,得到线性组合 W⋅x+b 。
-
应用非线性激活函数(如 ReLU、Sigmoid、Tanh 等)来引入非线性性质,产生当前全连接层的输出。
-
这个输出成为下一层的输入,继续这个过程,直到达到网络的最后一层或输出层。
这种逐层传递、加权、非线性激活的过程使得神经网络能够学习和表达复杂的特征和模式,从而完成任务,比如分类、回归等。
像 dense 的第一个参数比如设置为 4096,这个参数的设置有什么要求,设置大一点有什么好处 ?
设置全连接层的神经元数量(比如 Dense 的第一个参数设置为 4096)需要根据具体问题和架构进行权衡和调整,没有固定的绝对要求,但有一些指导原则和常见做法:
-
根据任务需求和复杂度选择:
-
对于复杂的任务或大规模的数据集,可能需要更多的神经元,以提高模型的拟合能力和学习特征的复杂度。
-
对于简单的任务或较小规模的数据集,可以选择较少的神经元,以避免过拟合和减少模型复杂度。
-
-
避免过拟合:
-
设置过多的神经元可能导致模型过拟合训练数据,即模型过于复杂,学习了训练数据中的噪声而不是通用特征。
-
可以通过使用正则化技术、丢弃(dropout)等方法来缓解过拟合。
-
-
计算资源和效率:
-
设置较多的神经元可能会增加模型的计算资源需求,包括内存和计算时间。
-
考虑到硬件和计算能力,要确保模型适合运行在你的目标平台上。
-
-
网络设计和架构:
-
构建模型时,整体架构、深度、每层的神经元数量都应该经过仔细设计和调整,以保持良好的平衡。
-
设置较大的神经元数量有可能使得模型更加复杂,可以学习到更多复杂的特征。但要注意过度复杂化可能导致过拟合或计算成本过高。通常,建议根据具体任务的复杂度、数据集大小和计算资源进行调整。

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









