







写在最前面的
实践的顺序,
应该是先将基础的 数据结构题目类型给实现。
然后再开始尝试 实现对应类型的算法题目,如回溯算法, 贪心算法, 动态规划, 图论;
-
基础的数据结构, 推荐卡尔的:
代码随想录:https://programmercarl.com/; -
算法部分,卡尔的内容结合: https://labuladong.online/algo/home/; 两者在原理解释上结合来看;
-
计算机基础知识,
操作系统、计算机网络、数据结构与算法、数据库、计算机组成原理, 基本
踏实的学习应该是在大学本科, 后续可以自学, 参考 阿秀的笔记
https://interviewguide.cn/notes/01-guide/web-guide-reading.html;
1. ACM 编程模式
在面试过程中,写代码时,
会出现ACM 的编程风格,即需要自己处理输入,输出,这里推荐参考:
-
牛客网的示例练习
-
卡尔网的 https://kamacoder.com/;
2. ACM
2.1 多行输入
输入描述:
输入包括两个正整数a,b(1 <= a, b <= 1000),输入数据包括多组。
输出描述:
输出a+b的结果
示例1
输入例子:
1 5
10 20
输出例子:
6
30
import sys
# 循环执行每行输入, 每行读入后,依次执行如下操作
for line in sys.stdin:
cur_input = line.split() #
out = int(cur_input[0]) + int(cur_input[1]) # 将列表中每个元素转换成整型;
print(out)
-
首先我们从终端输入的每一行数据 被读入之后被视为字符类型,
-
每一行中,我们通过空格键来分隔各个数据, 在一行输入结束后,按下 enter 键, 读入之后被表示为换行符 \n ;
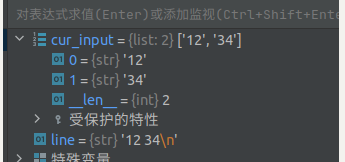
3. line.split 会对当前行中的数据处理, 通过split函数将他们分隔多个数据存储到列表中, 且此时列表中的每个元素仍是 str 类型; 在split()的过程中,如果不指定特殊字符, 则默认通过使用空格符 来分隔;
for line in sys.stdin:
从标准输入读取:for 循环 for line in sys.stdin: 从标准输入中逐行读取输入,直到到达文件结尾 (EOF)。当输入源(例如来自终端的文件或用户输入)关闭时,可能会发生这种情况。在典型的使用场景中(例如在管道中使用脚本或从文件重定向脚本时),这允许脚本无限期地处理输入或直到输入流关闭。
line.split()
处理每一行输入:在循环内,每次处理每一行输入。 line.split() 方法将字符串 line 拆分为列表 cur_input ,其中每个元素都是一个子字符串(最初在输入中用空格分隔)。例如,如果输入行是“123 456”,则 cur_input 将是 ['123', '456'] 。
int(cur_input[0]) + int(cur_input[1]) :此表达式将 cur_input 的第一个和第二个元素转换为整数并对它们求和。结果不会打印或存储在变量 out 之外,这意味着将使用每个新输入行重新计算结果,并且先前的结果将被覆盖。
注意,其中默认使用的分隔符有如下:
Space (' ') 空格 ( ' ' ):表示单词或字符之间的常规空格字符。
Tab ('\t'): 制表符 ( '\t' ):表示制表符,通常用于文本对齐。
Newline ('\n'):换行符 ( '\n' ):在 Unix/Linux 系统中表示一行的结束。它将光标移动到下一行。
Carriage Return ('\r'): 回车符 ( '\r' ):在较旧的 Mac 系统中单独使用,在 Windows 系统中与换行符 ( '\r\n' ) 结合使用,表示行的结束。它将光标返回到行的开头。
Form Feed ('\f'):换页 ( '\f' ):不太常用,该字符在打印机中推进进纸或在文本文档的某些上下文中更改到新“页面”。
当不带任何参数的情况下调用 split() 时,它会将任何上述这些空白字符的序列视为单个分隔符,并且还会在拆分之前自动删除字符串中的任何前导和尾随空白。此行为对于解析输入(其中元素之间的间距量可能不同或使用不同的行结束约定)特别有用。
2.2 输入多行, 需要指定行号
输入描述:
输入第一行包括一个数据组数t(1 <= t <= 100)
接下来每行包括两个正整数a,b(1 <= a, b <= 1000)
输出描述:
输出a+b的结果
示例1
输入例子:
2
1 5
10 20
输出例子:
6
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









