



一分钟搞懂RAG {#rag}
世界上95%的信息都是私有信息, 无法用于模型训练, 但我们可以在使用模型时把这些信息喂给它.
RAG 主要解决2个问题, 一是无法获取最新的信息. 二是幻想.
RAG 在prompt 给 LLM 之前会先访问指定的信息源查找, 之后再把检索的信息一起喂给 LLM.
它由2部分组成 retriever 和 knowledge base.
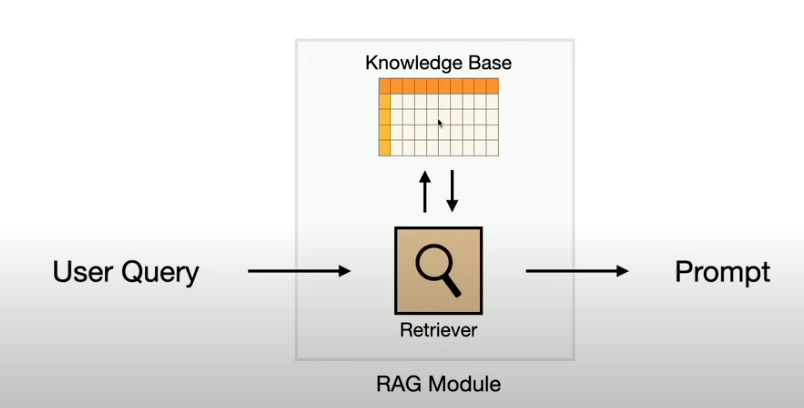
我们的信息是怎么变成 knowledge base 的呢?
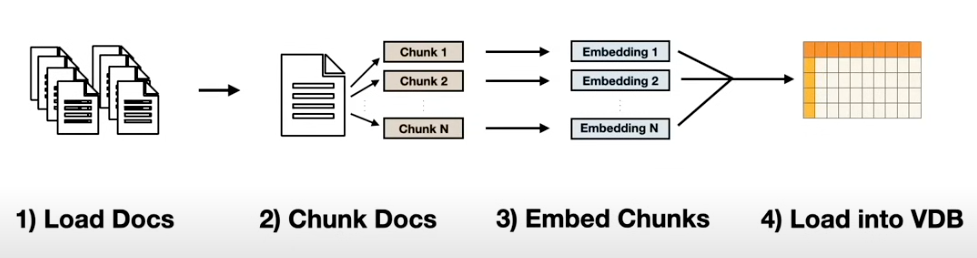
rag 先把每一个文档数据都向量化成一个数值数组, 这样就可以对其进行计算, 当你查询时, 就可以计算出哪个文档和你的问题关系最大(retriever 做的就是这个事情), 然后用问题和这个文档重新组合 prompt 一起发给 LLM.

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









