




 本文深入解析Linux虚拟文件系统(VFS)的设计理念与核心组件,包括超级块、索引节点、目录项及文件对象等四大对象的功能与作用。通过具体实例说明各对象如何协作,为用户提供统一的文件操作接口。
本文深入解析Linux虚拟文件系统(VFS)的设计理念与核心组件,包括超级块、索引节点、目录项及文件对象等四大对象的功能与作用。通过具体实例说明各对象如何协作,为用户提供统一的文件操作接口。
目录
1 虚拟文件系统概述
Linux中“一切皆文件”,所有文件都放置在以 “/” 为根目录的一个目录树中。所有的硬件设备也都是文件,各有自己的文件系统(比如对新硬盘进行格式化的时候就要给其设置一个文件系统)。但是在Linux中访问任何类型的文件时,不管是普通文件还是设备文件等,都可以统一使用open(),read(),write()这样的系统调用。这就是虚拟文件系统VFS的核心思想,在具体的文件系统之上提供更高一层的抽象,给各种文件系统提供统一的IO操作接口。
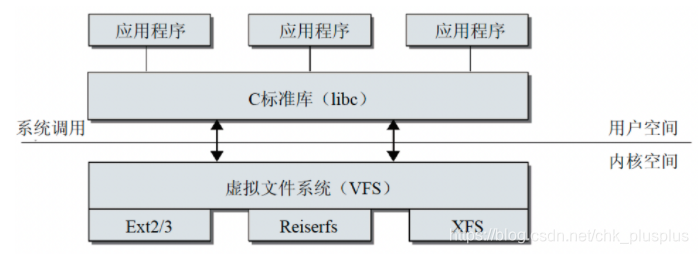
VFS是一个内核软件层。主要利用四种对象来建立一种统一的文件模型,VFS相当于定义了一种标准,只要是按照VFS标准接口开发的文件系统都可以接入linux,按照VFS标准即表示这个底层文件系统要有(或者支持)四大对象,当文件系统被挂载时,所有与它有关的信息都放入super_block结构体中。从用户的角度看,Linux的文件系统只有VFS。
VFS四大对象即四种内存内核区的结构体对象,在具体的文件系统中有对应的数据来初始化这四种对象,所以要注意区分内核中的对象和具体文件系统对应的磁盘数据区域:
superblock(超级块):存储文件系统的元数据,一个超级块对应一个实际的文件系统。
inode(索引节点):存储磁盘上文件的元数据
dentry(目录项):保存文件名与inode之间的映射关系,以及目录与目录下文件之间的映射关系。是一种逻辑上的概念,有缓存机制。
file:一个进程打开一个文件时会创建一个FILE结构体,它与具体的进程和用户关联,需要注意的是FILE对象与进程相关联,但是并不意味着FILE对象是某个进程专属的,即不同进程文件描述表中的FILE*指针可以指向相同的FILE对象。
2 底层文件系统与VFS四大对象
磁盘与底层文件系统例子
磁盘(disk):一个硬件设备,比如我们平时买的硬盘,可以分成很多个分区。
分区(partition):从磁盘上划出来的一块空间,类似windows中可以分CDE区,通常情况下,一个分区只能格式化为一个文件系统(虽然现在有新技术将一个分区格式化为多个文件系统),但我们通常可以认为一个分区。
扇区(sector):硬件上I/O操作的最小单位,通常是512字节。
块(block):Linux虚拟文件系统I/O操作的最小单位,操作系统在读取硬盘的时候,一次性读取的最小单位是一个块,一般是4KB的大小。。
块组(block group):一个分区可以分成好几个块组,如下图所示,同一个分区内的块组通常是属于同一个文件系统。
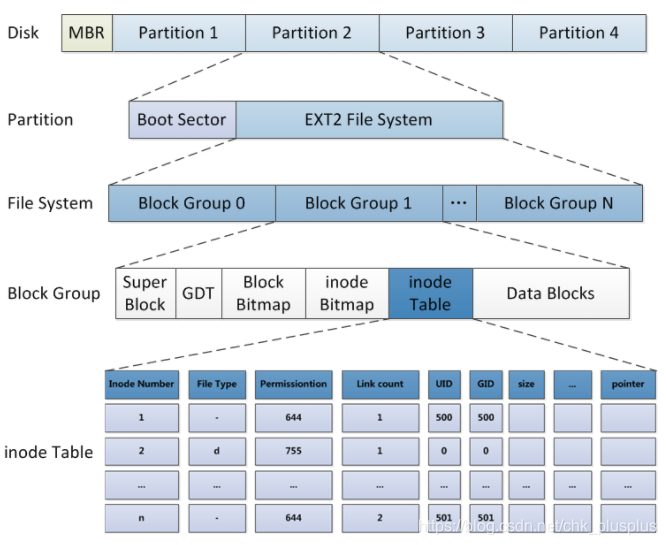
以下概念均是底层文件系统划分的数据区域,并非VFS内存中四大对象,但是要用这些信息来初始化四大对象,且对四大对象的改变最终要回写回这些区域:
引导块(boot sector):一个分区由引导块和底层文件系统组成,但是一般只有根文件系统中这一块有引导代码,其它文件系统中这一块空着。
超级块(super block):是一个文件系统的核心,描述整个分区的文件系统信息,在每个块组的开头有一份拷贝。记录了该文件系统的块大小,上次挂载时间,块组个数,每个块组中块的个数,以及空闲块数和空闲Inode数等,超级块区域的数据用于初始化VFS的超级块对象,同样的,VFS超级块对象可以改变之后回写回磁盘超级块区域。
块组描述符表(GDT):存储当前块组的全局信息,比如逻辑块位图的块号,i节点位图的块号,以及空闲的块数和空闲的inode数等。
逻辑块位图(盘块位图Block Bitmap):如果某一位为1,则这个位对应的逻辑块或者说数据区的那个块是被使用了的,否则是空闲的。其本身只占一个块。
索引节点位图(inode Bitmap):如果某一位为1,则代表这一位对应的 inode 表中那个区域没有存信息。也是占一个块。从这里也可以看出inode的数目是有限的,如果有非常多的小文件的话可能造成一种情况,磁盘还有空间,inode号码用完了。
索引节点表(inode table):inode表中每个inode节点(即索引节点)对应一个磁盘文件,存储了磁盘文的元信息,即除了文件名以外的所有信息。比如用户组,权限,大小,修改时间等。inode中还保存了指向文件实际数组的地址信息。通过inode机制实现了文件数据本身和数据描述信息的分开存储。
数据区(Data Blocks):这里存储的就是实际的磁盘数据了。对于普通文件,其内容就是文件数据,对于目录文件,其内容是该目录下的所有文件名(包块子目录),对于软链接,其内容是原目标路径名。
超级块对象super block
一个超级块对象对应一个具体的文件系统,超级块在内存中的实体是一个结构体 struct super_block。超级块实现了对具体的文件系统的一种抽象,即不管底层是什么文件系统,在VFS中处理的时候都将其抽象为一个 super_block结构体对象。超级块是一个全局的数据结构,这里我们所说的超级块都是只存在于内存中的数据结构。
具体地,内核中文件系统部分调用alloc_super()函数从磁盘中读取底层文件系统超级块区域,然后用其中的数据来给内存中超级块对象赋值。
struct super_block {
struct list_head s_list; /* 系统将所有文件系统的超级块组成链表*/
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned long s_blocksize;
unsigned char s_blocksize_bits;
unsigned char s_dirt;
unsigned long long s_maxbytes; /* Max file size */
struct file_system_type *s_type; //文件系统类型
const struct super_operations *s_op; //操作函数集
struct dquot_operations *dq_op;
struct quotactl_ops *s_qcop;
struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry *s_root; //挂载根目录
struct rw_semaphore s_umount;
struct mutex s_lock;
int s_count;
int s_syncing;
int s_need_sync_fs;
atomic_t s_active;
#ifdef CONFIG_SECURITY
void *s_security; //LSM框架的安全域
#endif
struct xattr_handler **s_xattr;
struct list_head s_inodes; /* 所有的inode节点链表*/
struct list_head s_dirty; /* dirty inodes */
struct list_head s_io; /* parked for writeback */
struct hlist_head s_anon; /* anonymous dentries for (nfs) exporting */
struct list_head s_files;
struct block_device *s_bdev;
struct list_head s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
int s_frozen;
wait_queue_head_t s_wait_unfrozen;
char s_id[32];/* Informational name */
void *s_fs_info; /* Filesystem private info */
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
};
s_list:是一个list_head结构体对象。list_head结构体如下定义。内核中使用一个双向环形链表将所有超级块连起来管理,即每个超级块的s_list属性都包含了指向内核链表中前一个元素和后一个元素的指针。全局变量super_blocks用于指向链表中第一个元素。Linux内核经常用该对象间接定义双向循环链表来管理数据。具体使用方法可以参考linux内核链表list_head的原理与使用_不休的博客-优快云博客
struct{
list_head *prev;
list_head *next;
}s_blocksize:文件系统中数据块大小,单位是字节
s_dirt:脏位,在具体的硬件设备中有关于其文件系统的数据,将设备挂载以后,会用其关于文件系统的数据来初始化内存中的super_block结构体对象。而VFS是允许对超级块对象进行修改的,修改后的数据最终是要写回磁盘对应区域的。s_dirt用于判断超级块对象中数据是否脏了即被修改过了,即与磁盘上的超级块区域是否一致。
s_dirty:脏inode的双向循环链表,用于同步内存数据和底层存储介质。当我们在用户去用open打开一个文件,内存中会创建dentry和inode,当我们用write往文件中写入数据,则该inode脏了,将其加入到s_dirty链表
s_files:该超级块表是的文件系统中所有被打开的文件。
s_type:是指向file_system_type类型的指针,file_system_type结构体用于保存具体的文件系统的信息。
s_op:super_operations结构体类型的指针,因为一个超级块对应一种文件系统,而每种文件系统的操作函数可能是不同的。super_operations结构体由一些函数指针组成,这些函数指针用特定文件系统的超级块区域操作函数来初始化。比如里边会有函数实现获取和返回底层文件系统inode的方法。
s_inodes:是一个list_head结构体对象,指向超级块对应文件系统中的所有inode索引节点的链表。
索引节点对象inode
保存文件元数据,即文件大小,设备标识符,用户标识符,用户组标识符,文件模式,扩展属性,文件读取或修改的时间戳,链接数量,指向存储该内容的磁盘区块的指针,通过索引节点inode可以找到文件的具体数据在磁盘中的位置。inode有两种,一种是VFS的inode对象,一种是具体文件系统的inode磁盘区域。前者在内存中,后者在磁盘中。所以每次其实是将磁盘中的inode读取之后初始化内存中的inode,这样才是算使用了磁盘文件inode。inode是唯一的,一个inode对象了磁盘上的一个真实文件。
<span style="font-size:14px;">440 struct inode {
441 struct list_head i_hash;
442 struct list_head i_list;
443 struct list_head i_dentry;
444
445 struct list_head i_dirty_buffers;
446 struct list_head i_dirty_data_buffers;
447
448 unsigned long i_ino;
449 atomic_t i_count;
450 kdev_t i_dev;
451 umode_t i_mode;
452 unsigned int i_nlink;
453 uid_t i_uid;
454 gid_t i_gid;
455 kdev_t i_rdev;
456 loff_t i_size;
457 time_t i_atime;
458 time_t i_mtime;
459 time_t i_ctime;
460 unsigned int i_blkbits;
461 unsigned long i_blksize;
462 unsigned long i_blocks;
463 unsigned long i_version;
464 unsigned short i_bytes;
465 struct semaphore i_sem;
466 struct rw_semaphore i_alloc_sem;
467 struct semaphore i_zombie;
468 struct inode_operations *i_op;
469 struct file_operations *i_fop; /* former ->i_op->default_file_ops */
470 struct super_block *i_sb;
471 wait_queue_head_t i_wait;
472 struct file_lock *i_flock;
473 struct address_space *i_mapping;
474 struct address_space i_data;
475 struct dquot *i_dquot[MAXQUOTAS];
476 /* These three should probably be a union */
477 struct list_head i_devices;
478 struct pipe_inode_info *i_pipe;
479 struct block_device *i_bdev;
480 struct char_device *i_cdev;
481
482 unsigned long i_dnotify_mask; /* Directory notify events */
483 struct dnotify_struct *i_dnotify; /* for directory notifications */
484
485 unsigned long i_state;
486
487 unsigned int i_flags;
488 unsigned char i_sock;
489
490 atomic_t i_writecount;
491 unsigned int i_attr_flags;
492 __u32 i_generation;
493 union {
494 struct minix_inode_info minix_i;
495 struct ext2_inode_info ext2_i;
496 struct ext3_inode_info ext3_i;
497 struct hpfs_inode_info hpfs_i;
498 struct ntfs_inode_info ntfs_i;
499 struct msdos_inode_info msdos_i;
500 struct umsdos_inode_info umsdos_i;
501 struct iso_inode_info isofs_i;
502 struct nfs_inode_info nfs_i;
503 struct sysv_inode_info sysv_i;
504 struct affs_inode_info affs_i;
505 struct ufs_inode_info ufs_i;
506 struct efs_inode_info efs_i;
507 struct romfs_inode_info romfs_i;
508 struct shmem_inode_info shmem_i;
509 struct coda_inode_info coda_i;
510 struct smb_inode_info smbfs_i;
511 struct hfs_inode_info hfs_i;
512 struct adfs_inode_info adfs_i;
513 struct qnx4_inode_info qnx4_i;
514 struct reiserfs_inode_info reiserfs_i;
515 struct bfs_inode_info bfs_i;
516 struct udf_inode_info udf_i;
517 struct ncp_inode_info ncpfs_i;
518 struct proc_inode_info proc_i;
519 struct socket socket_i;
520 struct usbdev_inode_info usbdev_i;
521 struct jffs2_inode_info jffs2_i;
522 void *generic_ip;
523 } u;
524 };</span>
以上是通用的inode对象结构体定义。
i_no:便是inode的唯一性编号
i_count:访问该inode结构体对象的进程数
i_nlink:硬链接计数,等于0时将文件从磁盘移除。
i_hash:指向哈希链表指针,用于查询,已经inode号码和对应超级块的时候,通过哈希表来快速查询地址。具体看下边管理inode节点。也是list_head类型对象,这种对象就对应了一个双向循环链表。
i_dentry:指向目录项链表指针,因为一个inode可以对象多个dentry,因此用一个链表将于本inode关联的目录项都连在一起。
i_op:索引节点操作函数指针,指向了inode_operation结构体,提供与inode相关的操作
i_fop:指向file_operations结构提供文件操作,在file结构体中也有指向file_operations结构的指针。
i_sb:inode所属文件系统的超级块指针
管理inode节点的四个链表(前两个是全局链表,第三个在超级块中):
inode_unused:目前未被使用的inode节点链表,即尚在内存中没有销毁,但是没有进程使用,i_count为0。
inode_in_use:当前正在使用的inode链表,i_count > 0且 i_nlink > 0
super_block中的s_dirty:将所有修改过的inode链接起来
inode_hashtable:为了加快查找效率,将正在使用的和脏的inode放入一个哈希表中,但是不同的inode的哈希值可能相等,hash值相等的inode哦那个过i_hash成员连接。
注意是所有位于内存中的inode会存放在一个名为inode_hashtable的全局哈希表中,如果inode还在磁盘,没有缓存到内存,则不会加入全局哈希表。inode_hashtable加快了对索引节点对象的搜索,但前提是要知道inode号码和对应的超级块对象。
注意在inode_hashtable哈希表中的元素是链表,是通过inode对象中的i_hash成员链接起来的双向循环链表,在这个子链表中对应的inode的哈希值是相等的。即inode_hashtable本质是一个数据和链表的结合体。
目录项dentry
与超级块对象super block和索引节点对象inode不同,dentry在底层磁盘上并没有对象的实体,dentry是只存在于内存中的对象,其本质是缓存了磁盘文件查找的结果,即dentry中包含了文件名到inode结构体地址的映射,所以也叫“dcache”。而VFS中的超级块对象和索引节点对象一是为了为不同底层文件系统提供更高层的表示,二是为了提高效率,所以其在内存和底层磁盘有具体对应的数据。
目录项与目录文件是不同的,目录文件是磁盘上的具体的一种文件,目录项则是在内存用于记录文件名和inode节点映射关系的一种数据结构,可以说是为了提高查找效率而存在的。首先先要搞懂目录是什么。
简而言之,目录的本质就是一个表,存储了该目录下文件的文件名和对应的inode编号。从inode table中找到对应编号的inode,就可以找到对应的数据。而目录项dentry本质上是在查找文件过程中缓存在内存中的对象,所以目录项也被称为目录项缓存dcache,其与目录文件并不是一种像内存中与磁盘上的超级块,索引节点那样的对应关系。
也有些地方将目录文件中代表该目录下一个文件的表项叫做目录项,其实也没错,知道其与内存中dentry的区别即可,其实也可以理解为磁盘上超级块与内存中超级块之间的关系。
举个例子,如下图中所示目录结构:
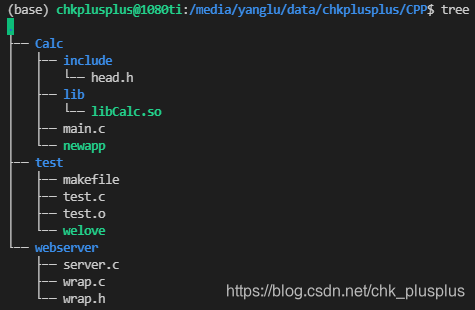
对于CPP这个目录文件,其存储的数据内容是:
| 文件名 | inode编号(只是举例,不代表真实情况) |
| . | 1 |
| .. | 2 |
| Calc | 3 |
| test | 4 |
| webserver | 5 |
即对于目录文件CPP来说,其内容是目录下文件名与其对应inode编号的映射。目录文件CPP下一共有五个文件,都是目录文件。其中“.”是当前目录文件的硬链接,即其与CPP关联的是同一个inode,“..”是上一级目录的硬链接。
![]()
如图中所示,CPP目录文件的硬链接数(下文中讲解)是5,目录文件CPP本身,CPP目录下的 “.”,以及目录文件Calc,test,webserver这三个目录下的“..”,这五个目录文件互为硬链接,因此硬链接数是5。因为一个目录下一定含有其本身的硬链接,这也就是为什么目录文件的硬链接数至少为2。
而对于目录文件test来说,其数据内容是:
| 文件名 | inode编号 |
| . | 4 |
| .. | 1 |
| makefile | 6 |
| test.c | 7 |
| test.o | 8 |
| welove | 9 |
test目录下包括了当前目录文件的inode编号以及上级目录即CPP的inode编号,以及三个普通文件与其inode编号的映射。
现在假设我们要查找 ../CPP/test/test.c 这个文件,则步骤为(假设已知CPP的inode编号,胡罗CPP之前文件的查找过程):
由CPP的inode编号找到文件名CPP对应的索引节点,由索引节点找到对应数据块,从数据块中取出CPP文件的内容。即上文中目录文件表1。
从目录文件表1找到 test 对应的inode编号,然后找到对应索引节点以及数据块,从数据块中取出目录文件test的内容,即目录文件表2。
从目录文件表2中找到test.c对应的inode编号,从而找到test.c在磁盘上的数据块,取出内容。
这样一个查找文件的过程涉及大量的磁盘操作,由于磁盘相比内存速度很慢,因此产生了dentry的缓存机制,即每次VFS访问底层数据时,都将访问结果保存下来,即在内存中构造dentry结构来保存文件名(d_name)和inode号码对应的索引节点的地址之间的映射。并且,当查找一个文件时,查找到其路径上的每个文件时候在内存中都会构造一个dentry结构体对象,并通过一定的机制(其实就是定义各种链表来间接形成一个树形层次结构以便于管理)来形成文件系统的目录树结构。
对于上文中查找test.c文件的例子来说,CPP,test,test.c,搜索到路径上的这三个文件时候都会建立相应的dentry,并且这三个文件的目录层次关系也会保留。
即dentry或者说dcache的目的有两个,一是保存访问到的文件名与索引节点地址间的映射关系,二是维护好文件之间的目录层次关系。dentry结构体定义如下:
struct dentry {
atomic_t d_count;//目录项对象引用计数器
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode *d_inode; /* Where the name belongs to - NULL is
struct hlist_node d_hash; /* 链接到dentry cache的hash链表 */
struct dentry *d_parent; /* 指向父dentry结构的指针 */
struct qstr d_name;//文件名
struct list_head d_lru; /* LRU list */
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* 是子项的链表头,子项可能是目录也可能是文件,所有子项都要链接到这个链表, */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
int d_mounted; /*表示dentry是否是一个挂载点,如果是挂载点,该成员不为0
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
d_count:目录项对象引用计数器
d_name:文件名
d_inode:inode节点的指针,便于快速找到对应的索引节点
d_sb:指向对应超级块的指针
d_op:指向dentry对应的操作函数集
d_subdirs & d_child:某目录的d_subdirs与该目录下所有文件的d_child成员一起形成一个双向循环链表,将该目录下的所有文件连接在一起,目的是保留文件的目录结构,即一个d_subdirs和多个d_child一起形成链表,d_subdirs对应文件在d_child对应文件的上一层目录。具体可见下图。
d_parent:指向父目录的dentry对象,具体看下图。
通过d_subdirs和d_child把同一目录下的文件都连接了起来形成链表,然后通过d_parent成员可以确定该链表对应的文件所在的目录,这三个成员一起就能完全保留文件之间的目录层次关系。比如当移动文件的时候,只需要将dentry对象从旧得父dentry链表(d_subdirs)上脱离,链接到新的父dentry的d_subdirs链表上,并将d_parent成员指向新的父dentry即可。可以看到移动文件并没有移动底层文件,甚至没有改变inode,只是改变了缓存中的dentry(最终改变目录文件),因此在同一个文件系统中移动文件会很快,但是跨文件系统就会改变inode和底层数据区了,因此速度很慢。
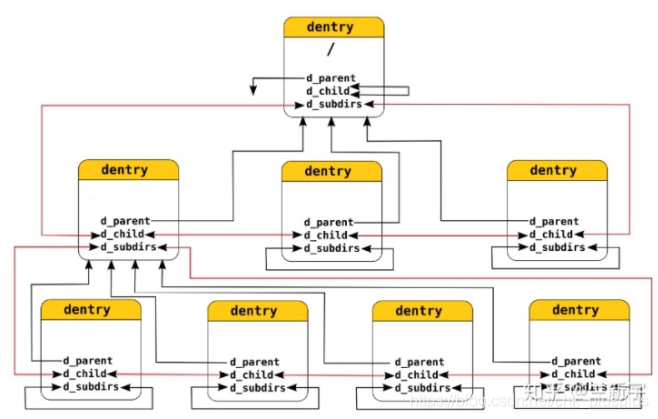
dentry_hashtable & d_hash:dentry_table哈希表维护在内存中的所有目录项,哈希表中每个元素都是一个双向循环链表,用于维护哈希值相等的目录项,这个双向循环链表是通过dentry中的d_hash成员来链接在一起的。
FILE文件对象
是VFS四大对象里唯一一个进程级对象,即与具体的进程相关联,与进程相关联的意思是,某个进程打开一个文件,内核就会创建一个FILE对象,但是并不意味着这个FILE对象是这个进程专属的,不同进程中的文件描述符表中的指针可以指向相同的FILE对象(进程间通信?),从而共享这个对象。具体看下图:
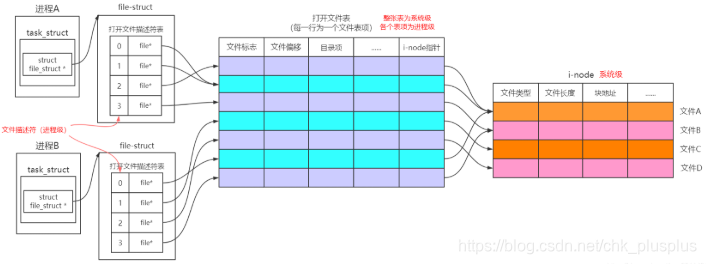
每个进程的进程控制块PCB中都有一个文件描述符表,文件描述符表的索引就是所谓的文件描述符,在系统调用层面,都是用文件描述符来进行各种IO操作。这个表的默认大小是1024,进程每次调用open打开一个文件的时候,内核就会创建一个FILE对象,然后把文件描述符表中最小可用的索引号给这个FILE对象,并用一个FILE*指针作为文件描述符表对应位置的表项,来指向代表打开文件的这个FILE对象。系统级的打开文件表是由所有内核创建的FILE对象通过其fu_list成员连接成的双向循环链表。即系统集打开文件表中的表项就是FILE对象,FILE对象中有目录项成员dentry,dentry中有指向inode索引节点的指针,即通过打开文件表中的表项,就能找到对应的inode。注意上图打开文件表中把目录项和inode指针列了两列,实际上inode指针应该是目录项中的成员。
进程A中,
文件描述符0和1指向同一个文件表项,可能是用了dup函数进行文件描述符重定向
文件描述2和0&1最终指向了同一个inode,即同一个底层文件,原因应该是用open重复打开了同一个文件,因此虽然文件描述符2和 0&1 有不同的文件表项,但是最终指向的文件是一样的。因为每调用一次open,内核就会创建一个FILE对象,不同的FILE对象虽然可以对应同一个磁盘文件,但是其读写位置等信息可以不一样。
进程A中的文件描述符012最终指向文件与进程B中文件描述符0指向文件是一样的,因为在不同的进程中用open打开了同一个文件。
实际上,还存在下图中的情况,不同进程中的文件描述符项指向了同一个打开文件表的文件表项,下图中进程A和B的文件描述符2指向了同一个打开文件表项,可能是因为用fork创建了子进程,子进程会与父进程共享文件描述符表。

struct file {
union {
struct list_head fu_list; //文件对象链表指针linux/include/linux/list.h
struct rcu_head fu_rcuhead; //RCU(Read-Copy Update)是Linux 2.6内核中新的锁机制
} f_u;
struct path f_path; //包含dentry和mnt两个成员,用于确定文件路径
#define f_dentry f_path.dentry //f_path的成员之一,当前文件的dentry结构
#define f_vfsmnt f_path.mnt //表示当前文件所在文件系统的挂载根目录
const struct file_operations *f_op; //与该文件相关联的操作函数
atomic_t f_count; //文件的引用计数(有多少进程打开该文件)
unsigned int f_flags; //对应于open时指定的flag
mode_t f_mode; //读写模式:open的mod_t mode参数
loff_t f_pos;//当前文件指针位置
off_t f_pos; //该文件在当前进程中的文件偏移量
struct fown_struct f_owner; //该结构的作用是通过信号进行I/O时间通知的数据。
unsigned int f_uid, f_gid;// 文件所有者id,所有者组id
struct file_ra_state f_ra; //在linux/include/linux/fs.h中定义,文件预读相关
unsigned long f_version;//记录文件的版本号,每次使用之后递增
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data;//使用这个成员来指向分配的数据
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
spinlock_t f_ep_lock;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
};fu_list:用于将所有的打开的FILE文件连接起来形成打开文件表
f_path:里边包含目录项dentry和挂载点信息
f_op:指向与文件相关的操作合集,比如read,write,lseek等
f_count:指示有多少个进程在使用该文件,这里也能看出FILE并不是某个进程的私有对象
f_flags:打开文件时候指定的标志,对应open的flags参数,
f_pos:文件的读写位置
进程与VFS四大对象联系示意图,这几个东西都是在内核空间中的

一个目录项dentry可以对应多个FILE(比如多次打开同一文件),一个inode可以对应多个dentry(比如打开多个互为硬链接的文件),inode与底层文件之间是一对一的关系。

















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









