







 在项目中使用Spark从Oracle数据库抽取数据到Hive时,遇到Number类型数据小数位数增多甚至出现科学计数法的問題。经过排查,发现问题源自Spark SQL在处理Oracle的Number字段时的默认行为。通过查阅资料和源码,了解到解决方案是将Oracle的Number类型映射为StringType,以保持数据原样存储在Hive中。测试后问题得到解决,这是一个关于Spark SQL与Oracle数据迁移的教训。
在项目中使用Spark从Oracle数据库抽取数据到Hive时,遇到Number类型数据小数位数增多甚至出现科学计数法的問題。经过排查,发现问题源自Spark SQL在处理Oracle的Number字段时的默认行为。通过查阅资料和源码,了解到解决方案是将Oracle的Number类型映射为StringType,以保持数据原样存储在Hive中。测试后问题得到解决,这是一个关于Spark SQL与Oracle数据迁移的教训。
项目中涉及到从oracle库抽取数据到hive库,出现了这样一个bug,抽取到hive库的数字小数位数格外的多,甚至有些出现了科学计数问题。
oracle的数据

从oracle抽取到hive库的数据
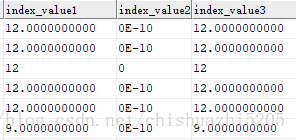
刚开始以为是代码中map部分的转换造成的

于是将转换的部分注释了起来,直接取oracle的值总归是没错的吧。信誓旦旦的就把bug返了回去。
结果……没过多久bug又回来了,仔细一看,问题依旧如故。怎么会出现这样的问题呢?明明是直接从oracle查了数据直接插入hive,中间没有其他的转换。
于是在代码中将查询的oracle数据show()了一下,才发现,原来查出来的dataset中就已经是多了很多位了(以后不亲眼看到执行完的数据,坚决不返bug)。苦思不得,问问度娘先。
参考1:https://blog.youkuaiyun.com/qq_14950717/article/details/51323679
从这篇博客中得知
在1.6以前的版本中,当Oracle表字段为Number时,对应DataType为decimal
但是如何解决呢?
参考2:https://bbs.aliyun.com/detail/337340.html?page=e
这篇博客讲到了spark 读取oracle,字段类型为Date的处理
和我的问题很相似,于是乎看了看源码org.apache.spark.sql.jdbc.OracleDialect
private case object OracleDialect extends JdbcDialect {
override def canHandle(url: String): Boolean = url.startsWith("jdbc:oracle")
override  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3248
3248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









