






今天加油把昨天学习的写完,部门的任务好多,终于闲下来了。
决策树模型
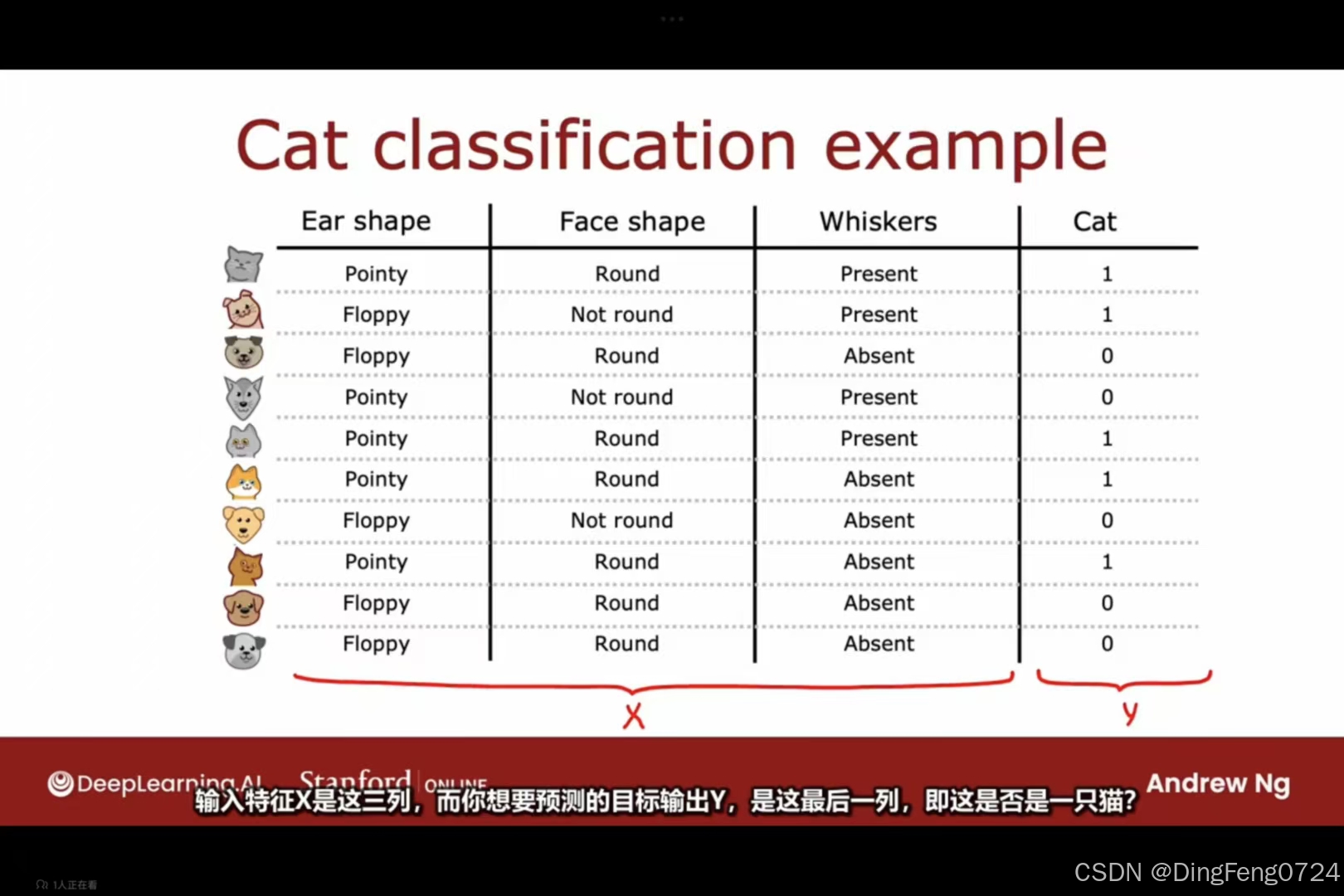
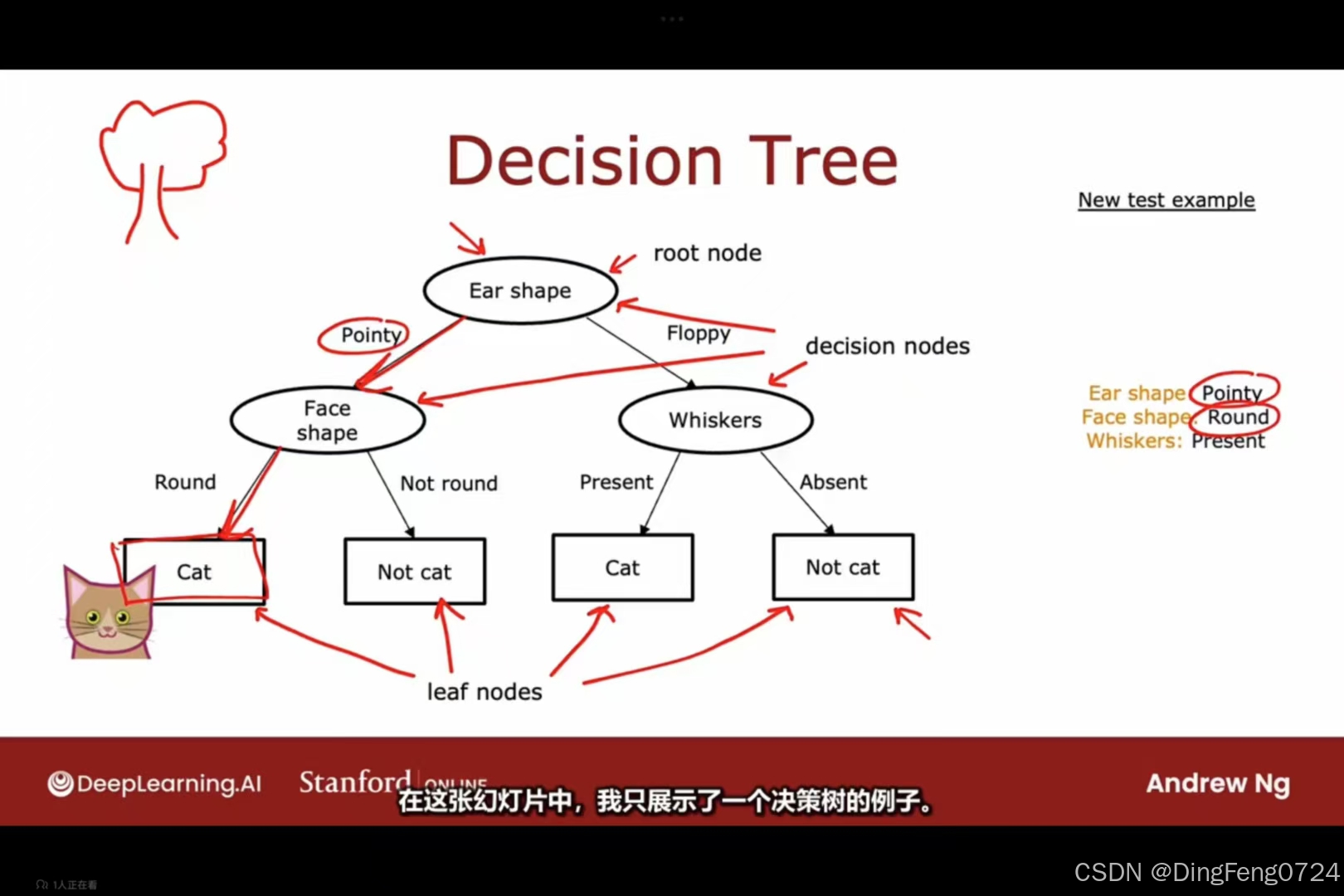
可以看到决策树的根节点是数据集,叶子节点就将数据认定的类别
决策树的纯度
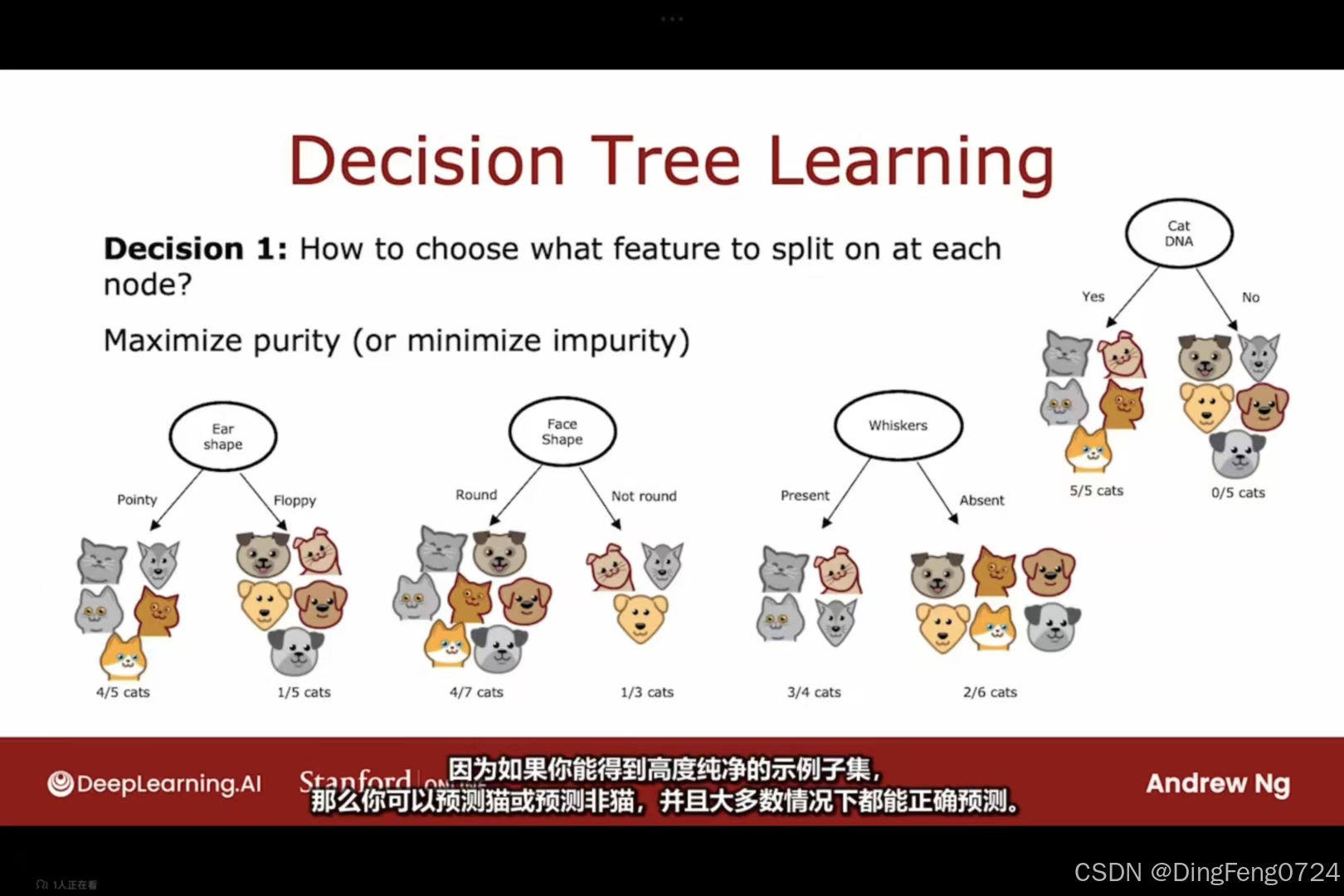
判断一个决策树的性能是看其是否能够得到一个高纯度子集。
熵函数

由图片可知熵函数再0到1是都接近为0但在1/2处却接近为1(log的底数为2)这可以很好的用数字形式判断出一个叶子节点是否过大。
选择信息拆分增益
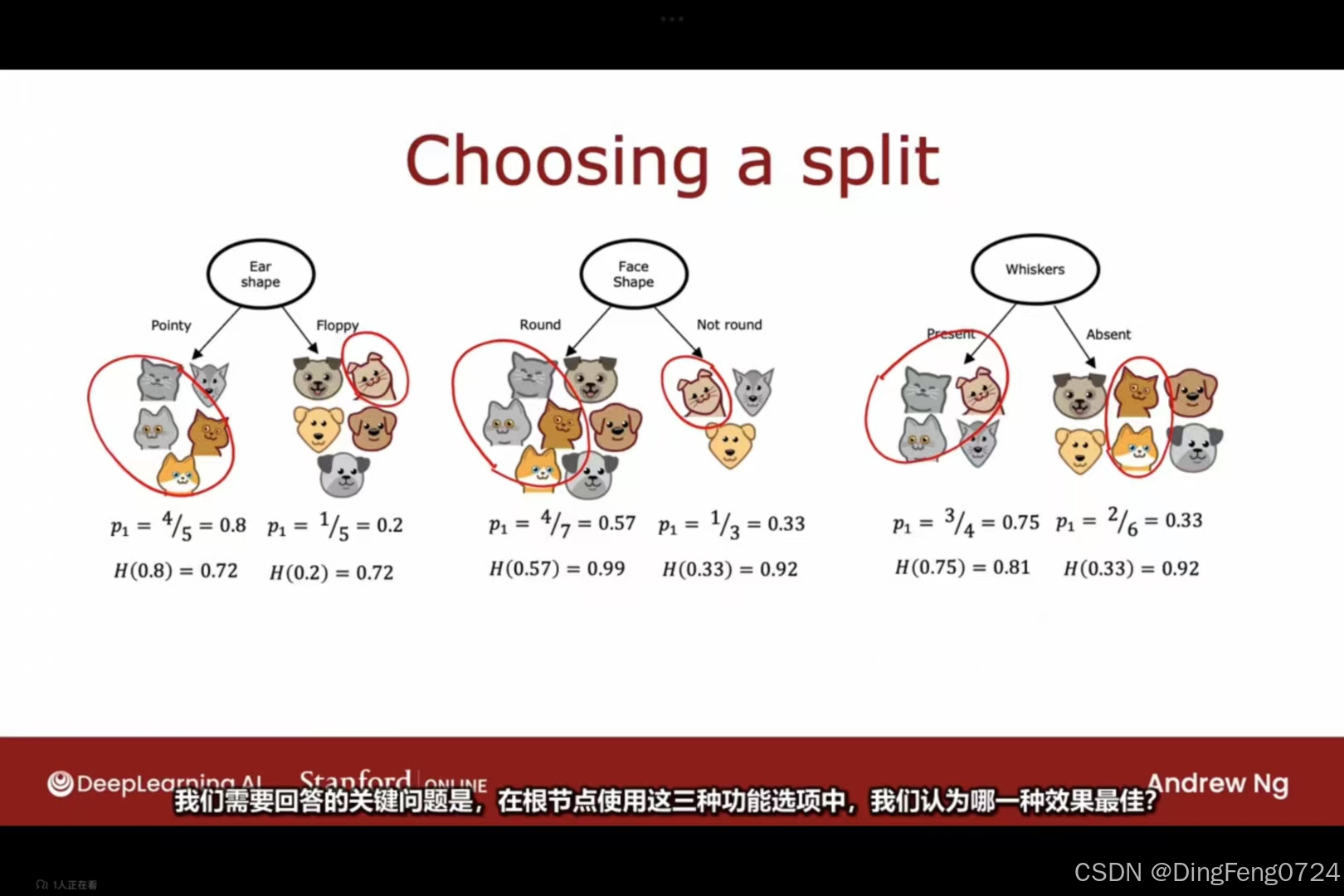 我们可以三个信息拆分条件分别对训练集进行一遍决策树,这时候我们可以将这三个信息拆分条件得到的自己纯度输入进熵函数当中,得到的值分别除以自己样本数据在总量中的占比,在用跟节点的熵去减去他们之和
我们可以三个信息拆分条件分别对训练集进行一遍决策树,这时候我们可以将这三个信息拆分条件得到的自己纯度输入进熵函数当中,得到的值分别除以自己样本数据在总量中的占比,在用跟节点的熵去减去他们之和
决策树学习四步法
-
初始化根节点
- 将所有训练样本置于根节点
- 计算当前节点熵值(衡量数据不纯度)
-
特征选择策略
信息增益 = H_{根节点} - \sum_{子节点} \left( \frac{样本占比}{总样本} \times H_{子节点} \right)- 遍历所有特征计算信息增益
- 选择信息增益最大的特征作为分割条件(关键误区修正:无需单独除以样本占比,应直接加权计算子节点熵)
-
递归分割
- 根据选定特征划分左右分支
- 对每个子节点重复步骤1-2
-
停止条件判定
- 纯节点:子节点中样本100%属于同一类别(熵=0)
- 深度限制:继续分割会导致树深度超过预设阈值
- 最小样本数:节点样本数低于设定值

独热编码
-
核心作用
- 离散特征处理:将分类变量(如颜色、性别)转换为二进制向量
- 消除数值误解:避免算法将类别数值误判为连续量(如将红=1、蓝=2视为大小关系)
-
在决策树中的特殊表现
原始特征:[颜色] = {红, 蓝, 绿} 独热编码后: - 红:[1,0,0] - 蓝:[0,1,0] - 绿:[0,0,1]- 优势:避免决策树对无序类别特征的错误分割(如
颜色 > 1.5的无意义判断) - 劣势:增加特征维度,可能影响树的生长效率(需权衡计算成本)
- 优势:避免决策树对无序类别特征的错误分割(如
连续具有价值的功能
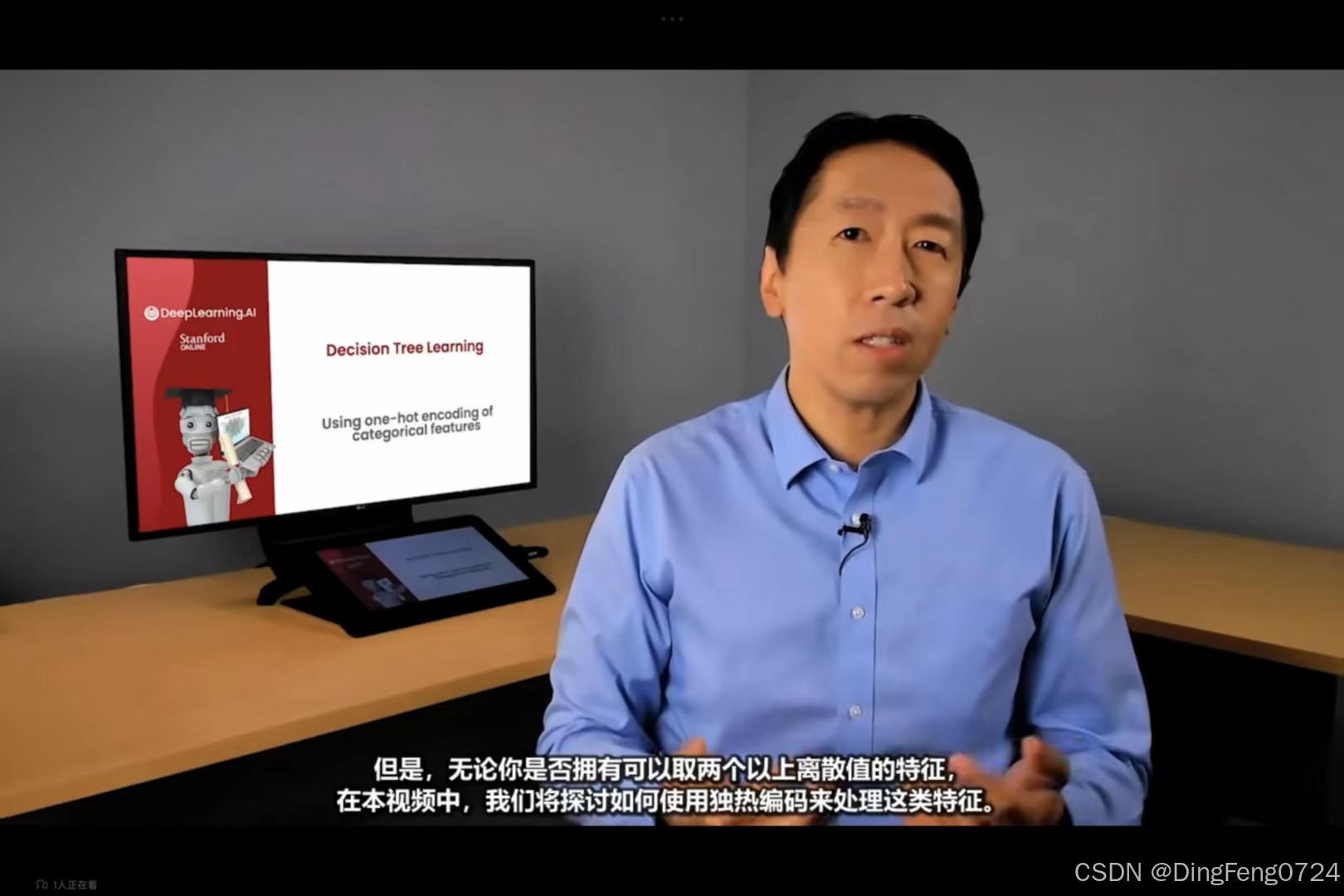
可以将判断条件设置为决策树的筛选条件。你将测试这个阈值的九种不同可能值,然后尝试选择能给你带来最高信息增益的那个。
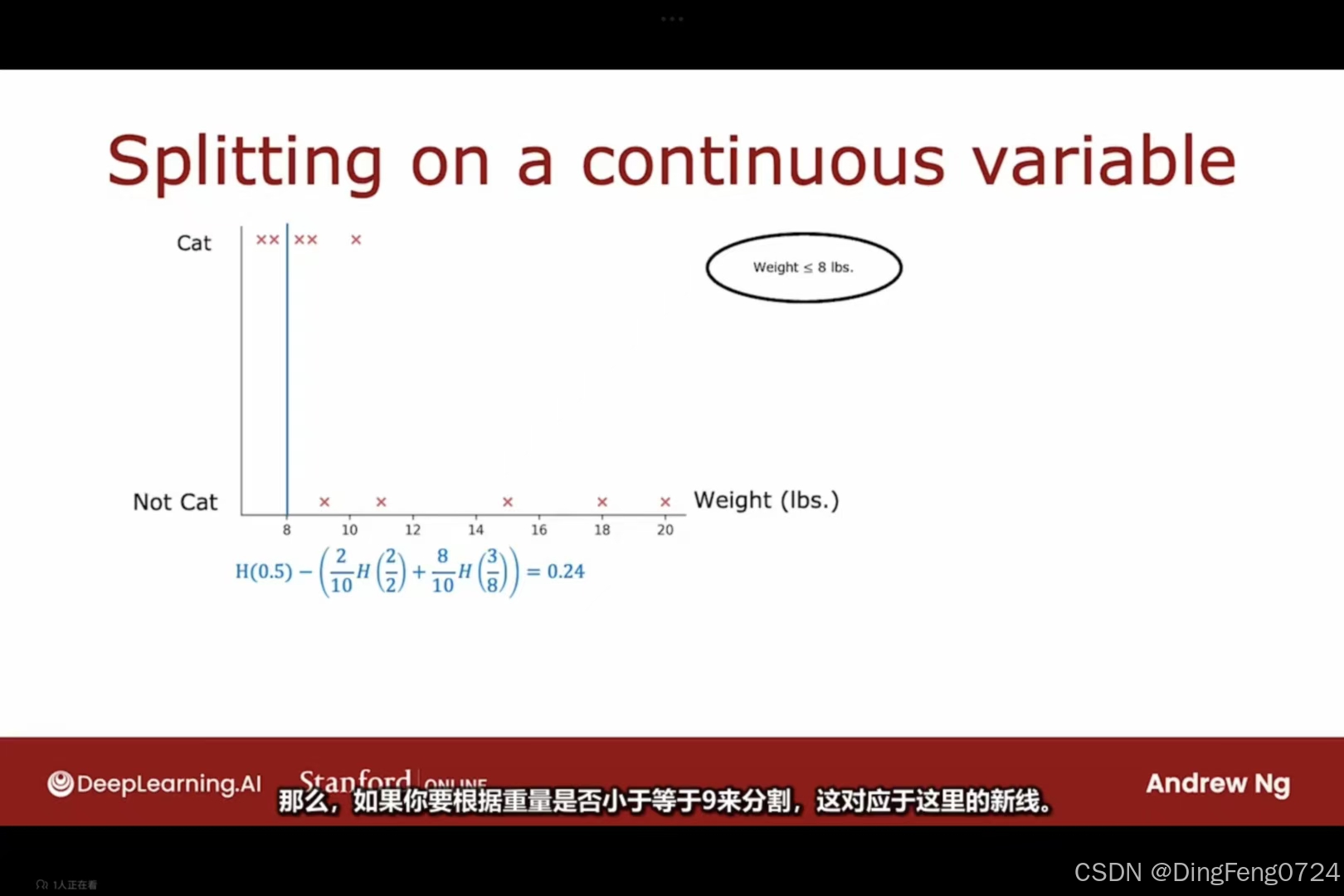
回归树
不同于决策树是将数据集进行分类,回归树则是预测一些离散的数据
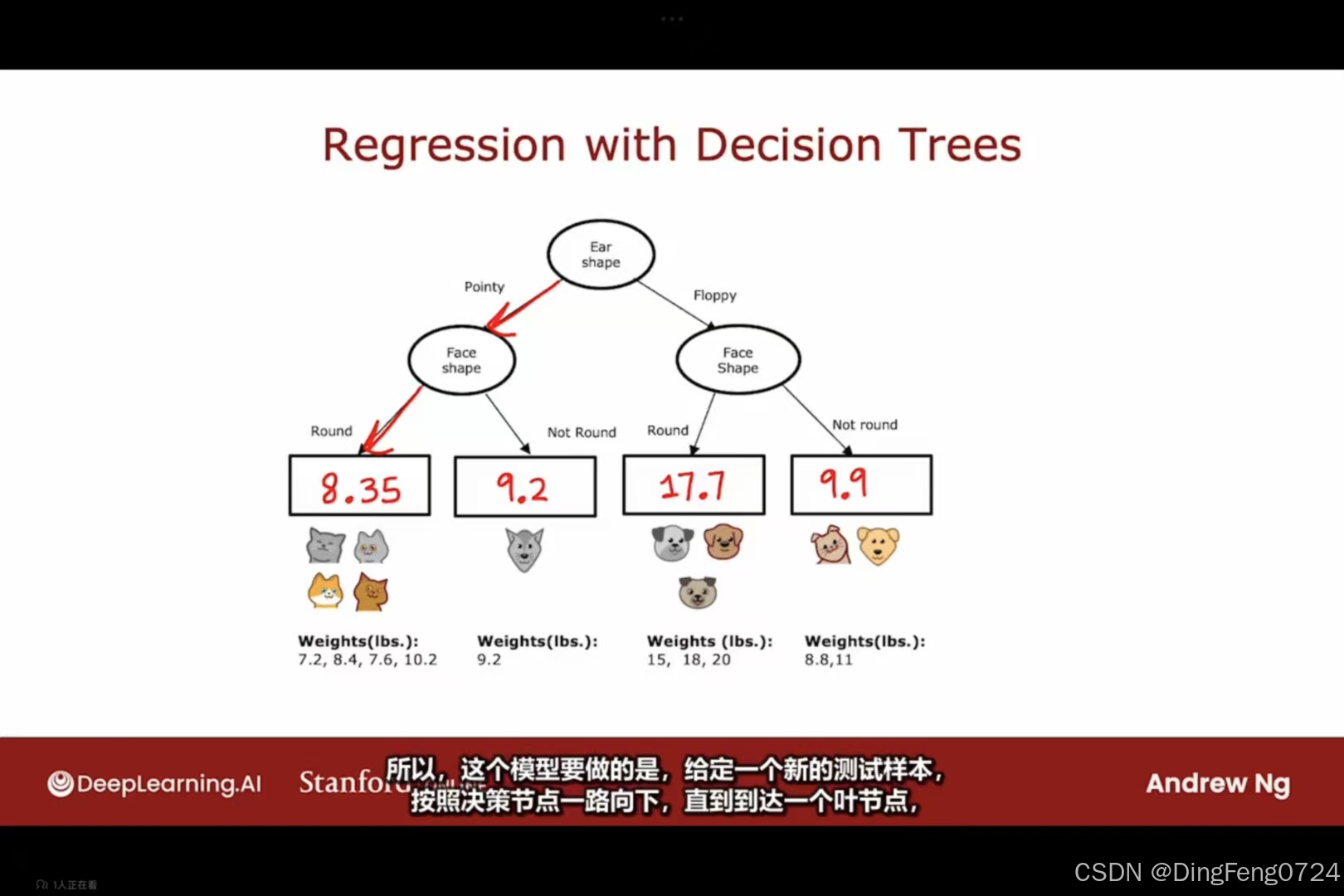 随机森林
随机森林
一.随机森林是一种集成学习(Ensemble Learning)方法,通过构建多棵决策树并聚合其预测结果来提升模型性能。其核心思想基于两个关键机制:
- Bagging(Bootstrap Aggregating):通过有放回抽样生成多组训练子集
- 随机特征选择:每棵树分裂时仅考虑随机子集的特征
其可以显出降低某些数据对于模型稳定性的影响
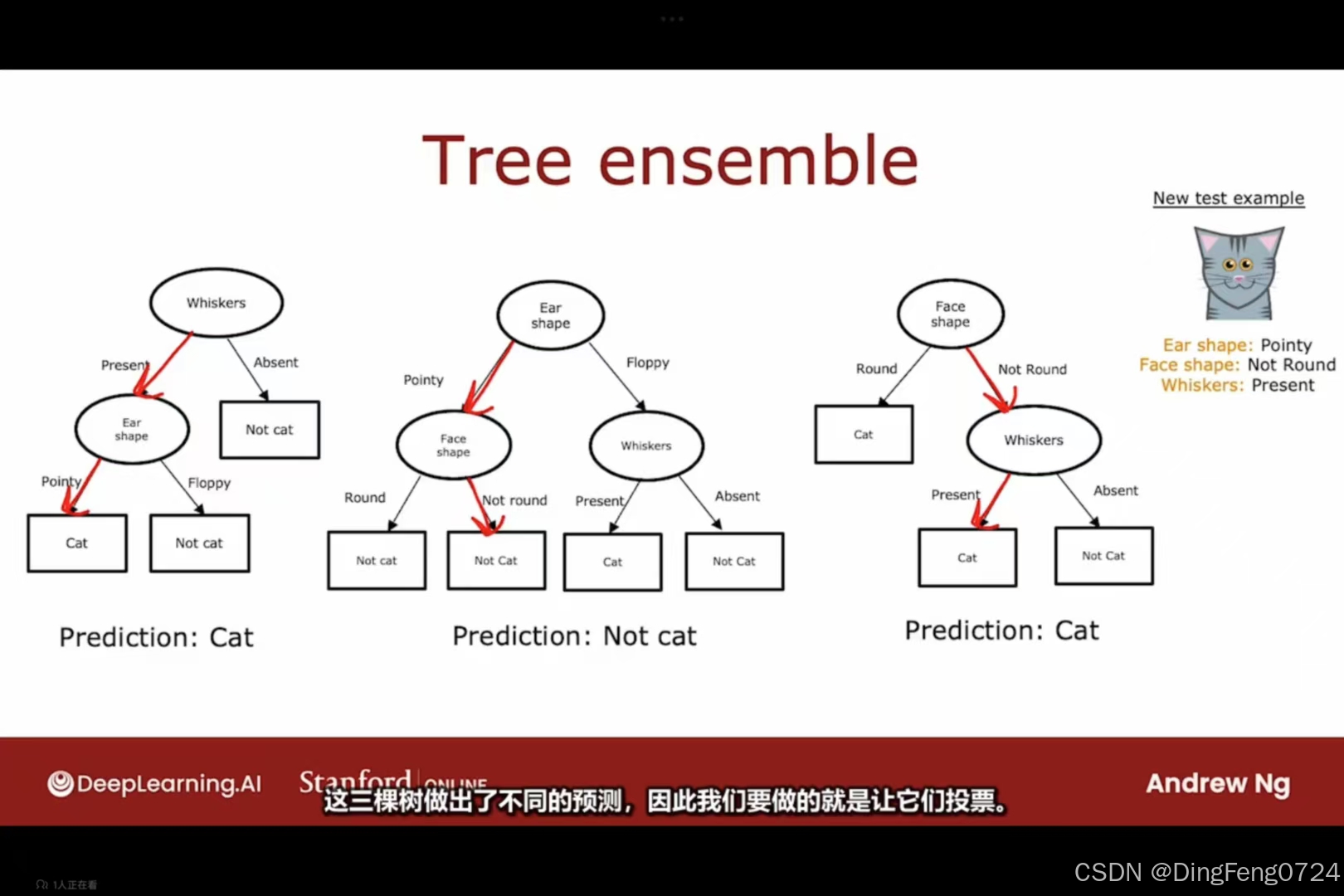 有放回抽样
有放回抽样
For b = 1 to B: 1. Bootstrap采样: 从原始训练集(size=m)有放回抽取m个样本 → 允许重复
2. 基学习器训练: 基于新采样集训练决策树(图示为猫/非猫分类树)
 XGboost算法
XGboost算法

 XGboost
XGboost
XGBoost核心特性
-
统一框架设计
- 同时支持分类(Classification)与回归(Regression)任务
- 仅需替换模型类名:
XGBClassifier↔XGBRegressor
-
梯度提升架构
- 通过加法模型(Additive Model)迭代优化目标函数
- 每轮迭代添加一棵树,修正前序模型的残差
 以上是其实现分类和回归的代码
以上是其实现分类和回归的代码
何时使用决策树
在结构化的数据适合使用决策树如excel表格。非结构化的数据则推荐使用神经网络。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









