




 本文深入探讨了信息熵、条件熵、联合熵、互信息等概念,以及它们在决策树算法中的应用。介绍了信息增益、增益率和基尼系数作为特征选择的准则,并分析了各自的优缺点。通过示例解释了如何计算这些指标,以及如何利用它们来构建决策树,如ID3、C4.5和CART算法。
本文深入探讨了信息熵、条件熵、联合熵、互信息等概念,以及它们在决策树算法中的应用。介绍了信息增益、增益率和基尼系数作为特征选择的准则,并分析了各自的优缺点。通过示例解释了如何计算这些指标,以及如何利用它们来构建决策树,如ID3、C4.5和CART算法。
信息
I ( X = x i ) = − log 2 p ( x i ) I(X=x_i)=-\log_2{p(x_i)} I(X=xi)=−log2p(xi)
公式中的负号是为了确保信息为0/正;
底数:只需满足大概率事件X对应于高的信息量即可。
I(x):表示随机变量的信息;
p(xi):当xi发生时的概率。
一个具体事件的信息量应该是随着其发生概率而递减的,且不能为负。
熵
在信息论和概率论中,熵度量随机变量的不确定性。熵又称为自信息(self-information),可以视为描述一个随机变量的不确定性的数量。信息熵考虑随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望,计算公式:
H ( X ) = ∑ i = 1 n p ( x i ) I ( x i ) = − ∑ i = 1 n p ( x i ) log b p ( x i ) H(X)=\sum_{i=1}^np(x_i)I(x_i)=-\sum_{i=1}^np(x_i)\log_bp(x_i) H(X)=∑i=1np(xi)I(xi)=−∑i=1np(xi)logbp(xi)
如果n表示X变量取值种类,那么p(xi)表示X变量取xi值占总体样本的比例。
熵只依赖X的分布,和X的取值没有关系,熵是用来度量不确定性。熵越大,表明X=xi的不确定性越大。反之亦然。在机器学习分类中,熵越大表明这个类别的不确定性更大,反之越小。当随机变量的取值为两个时,熵随概率的变化曲线如图:
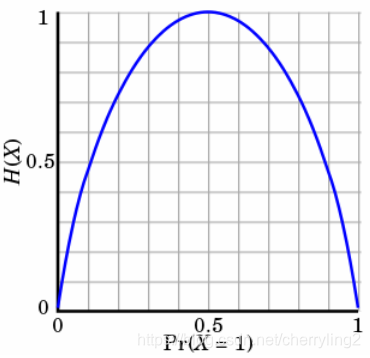
当p=0/1时,H§=0,随机变量完全没有不确定性;
当p=0.5时,H§=1,此时随机变量的不确定性最大。
示例:
X = [1 0 1 1 0] Y = [1 1 1 0 0]
p(X=0)=2/5 p(X=1)=3/5
p(Y=0)=2/5 p(Y=1)=3/5
H ( X ) = − 2 / 5 × log ( 2 / 5 ) − 3 / 5 × log ( 3 / 5 ) = 0.292 H(X)=-2/5\times\log(2/5)-3/5\times\log(3/5)=0.292 H(X)=−2/5×log(2/5)−3/5×log(3/5)=0.292
H ( Y ) = − 2 / 5 × log ( 2 / 5 ) − 3 / 5 × log ( 3 / 5 ) = 0.292 H(Y)=-2/5\times\log(2/5)-3/5\times\log(3/5)=0.292 H(Y)=−2/5×log(2/5)−3/5×log(3/5)=0.292
相对熵
相对熵(relative entropy)又称Kullback-Leibler差异(Kullback-Leibler divergence)或简称KL距离,是衡量相同事件空间里两个概率分布相对差距的测度。两个概率分布 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x)的相对熵定义为:
D ( p ∣ ∣ q ) = ∑ x ∈ X p ( x ) log p ( x ) q ( x ) D(p||q)=\sum_{x\in X}p(x)\log\frac{p(x)}{q(x)} D(p∣∣q)=∑x∈Xp(x)logq(x)p(x)
该定义中约定 0 log 0 q ( x ) = 0 0\log\frac{0}{q(x)}=0 0logq(x)0=0, p ( x ) log p ( x ) 0 = ∞ p(x)\log\frac{p(x)}{0}=\infty p(x)log0p(x)=∞。
表示成期望值为:
D ( p ∣ ∣ q ) = E p ( log p ( x ) q ( x ) ) D(p||q)=E_p(\log\frac{p(x)}{q(x)}) D(p∣∣q)=Ep(logq(x)p(x))
交叉熵
如果一个随机变量 X p ( x ) X~p(x) X p(x), q ( x ) q(x) q(x)为用于近似 p ( x ) p(x) p(x)的概率分布,那么随机变量X和模型q之间的交叉熵(cross entropy)定义为:
H ( X , q ) = H ( X ) + D ( p ∣ ∣ q ) = − ∑ x p ( x ) log q ( x ) = E p ( log 1 q ( x ) ) H(X,q)=H(X)+D(p||q)=-\sum_xp(x)\log q(x)=E_p(\log\frac{1}{q(x)}) H(X,q)=H(X)+D(p∣∣q)=−∑xp(x)logq(x)=Ep(logq(x)1)
由此,可以定义语言 L = ( X i ) p ( x ) L=(X_i)~p(x) L=(Xi) p(x)与其模型q的交叉熵为:
H ( L , q ) = − lim n → ∞ 1 n ∑ x 1 n p ( x 1 n ) log q ( x 1 n ) H(L,q)=-\lim_{n\rightarrow\infty}\frac{1}{n}\sum_{x^n_1}p(x^n_1)\log q(x^n_1) H(L,q)=−limn→∞n1∑x1np(x1n)logq(x1n)
根据信息论的定理:假定语言L是静态(stationary)遍历的(ergodic)随机过程,L与其模型q的交叉熵计算公式就变为:
H ( L , q ) = − lim n → ∞ 1 n log q ( x 1 n ) H(L,q)=-\lim_{n\rightarrow\infty}\frac{1}{n}\log q(x^n_1) H(L,q)=−limn→∞n1logq(x1n)
可以近似地采用如下计算方法:
H ( L , q ) ≈ − 1 n log q ( x 1 n ) H(L,q)\approx-\frac{1}{n}\log q(x^n_1) H(L,q)≈−n1logq(x1n)
困惑度perplexity:在设计语言模型时,通常用困惑度来代替交叉熵衡量语言模型的好坏。给定语言L的样本 l l n = l 1 , . . . , l n l^n_l=l_1,...,l_n lln=l1,...,ln,L的困惑度 P P q {PP}_q PPq定义为:
P P q = 2 H ( L , p ) ≈ 2 − 1 n log q ( l l n ) = [ q ( l l n ) ] − 1 n {PP}_q=2^{H(L,p)}\approx2^{-\frac{1}{n}\log q(l^n_l)}=[q(l^n_l)]^{-\frac{1}{n}} PPq=2H(L,p)≈2−n1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1526
1526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









