




 本文介绍了一种使用条件生成对抗网络(CGAN)进行单图像去雾的方法。该网络采用编码器-解码器结构,结合ResNet和U-Net的特性,利用跳过连接捕获更多信息。为了训练网络,创建了包含室内和室外场景的有雾图像数据集。损失函数包括对抗损失、感知损失和像素级损失,以确保图像结构、细节的保留以及去雾效果。实验结果显示,该方法在合成和真实图像上都能有效去雾,且能减少伪像和颜色失真。
本文介绍了一种使用条件生成对抗网络(CGAN)进行单图像去雾的方法。该网络采用编码器-解码器结构,结合ResNet和U-Net的特性,利用跳过连接捕获更多信息。为了训练网络,创建了包含室内和室外场景的有雾图像数据集。损失函数包括对抗损失、感知损失和像素级损失,以确保图像结构、细节的保留以及去雾效果。实验结果显示,该方法在合成和真实图像上都能有效去雾,且能减少伪像和颜色失真。
贡献
- 提出了一种基于条件生成对抗神经网络的去雾网络
- 生成网络采用编码器——解码器的结构,以捕获更多有用信息
- 新的损失函数,包括:
- 合成包括室内和室外的有雾图像数据集。
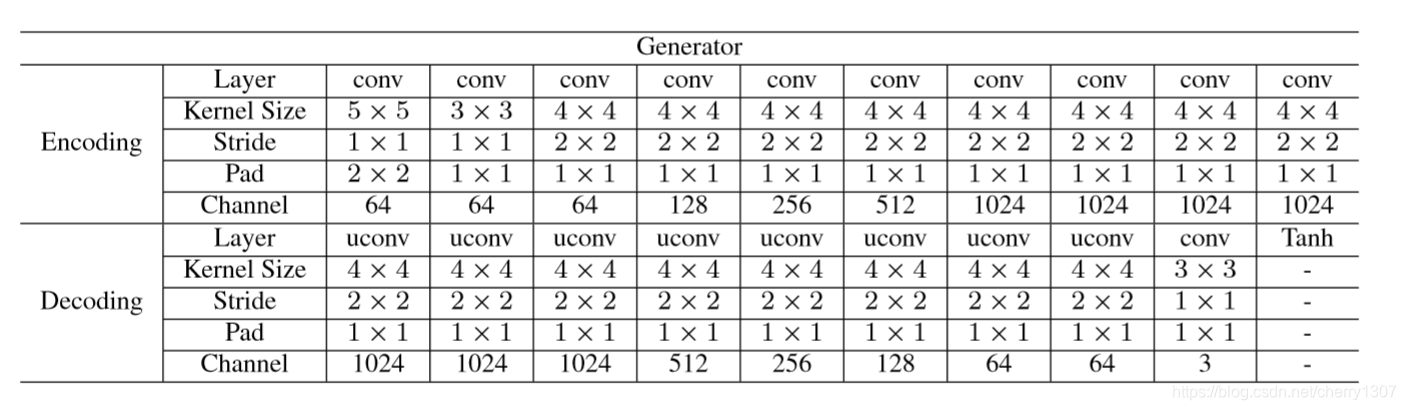
生成网络的结构

生成网络是输入有雾图像生成清晰图像,因此不仅要保留图像的结构和细节还要去雾。受ResNet和U-Net启发,在生成网络由编码器和解码器组成,使用对称层的跳过连接(skip connection)来突破解码过程中的信息瓶颈,并使用求和方法(summation method )捕获更多有用信息.
编码过程主要基于下采样操作,并向解码过程的对称层提供特征映射;
解码过程主要使用上采样操作和非线性空间转移。
配置
鉴别网络的结构
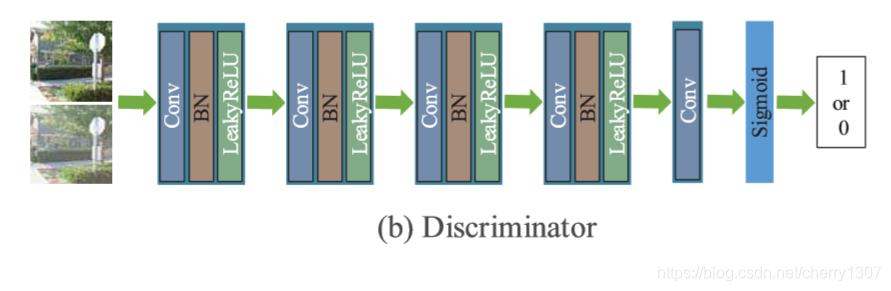
配置
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









