



- redis
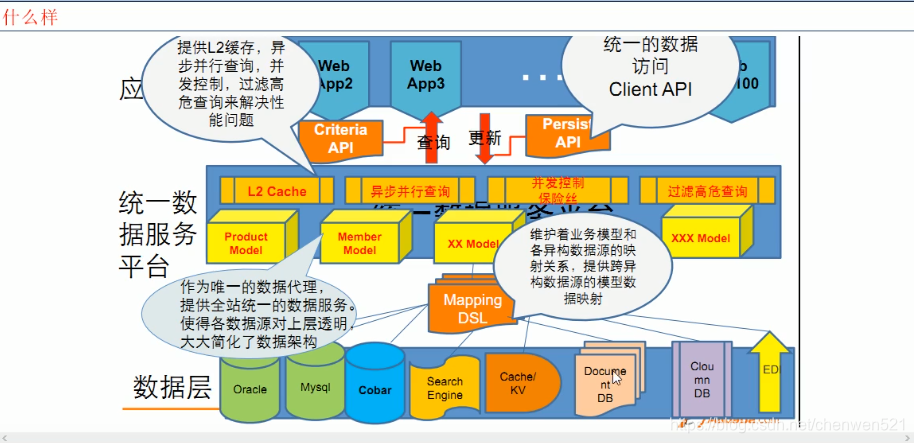
- 聚合模型
列族: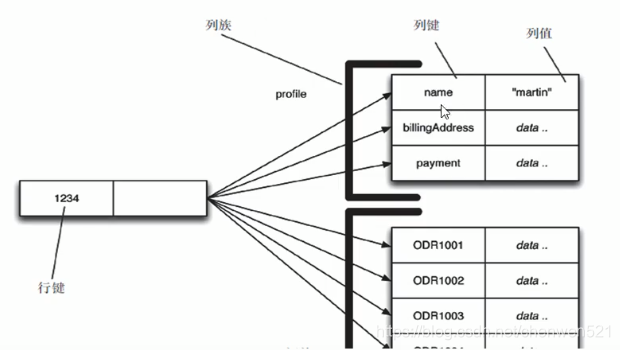
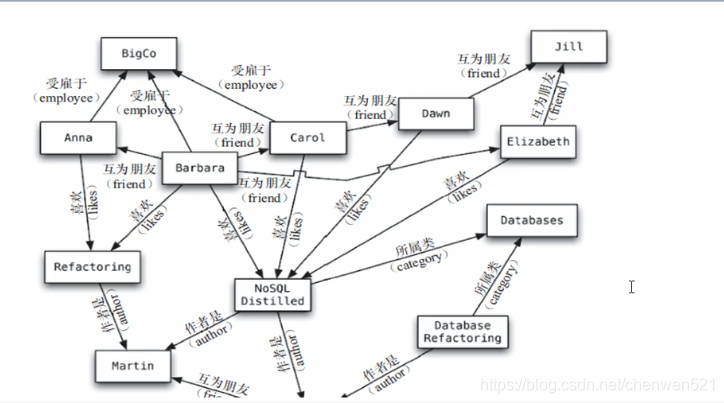
图:
利用appendonly.aof进行恢复。
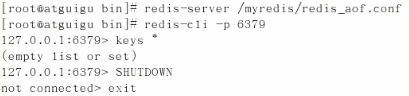
此时appendonly自动开启:
进行写操作:
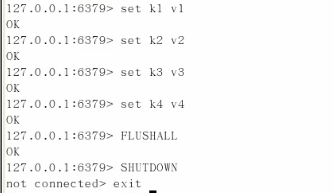
flushall、shutdown会产生dump.rdb
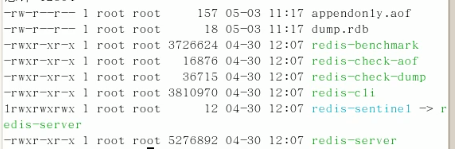
记录所有写操作命令:

由于会把每一步的操作都记录下来,所以理所当然,flushall也被记录下来重新执行了一遍。
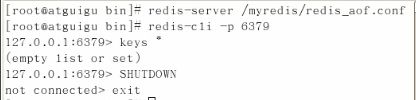
若没有flushall这条命令,则将会被顺利恢复。
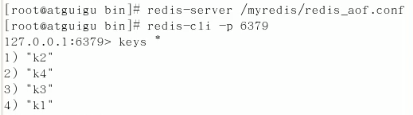
若aof里面的记录被破坏:

则不能被正常启动。

将appendonly.aof进行修复。把所有不符合语法规范的语句统统删光。
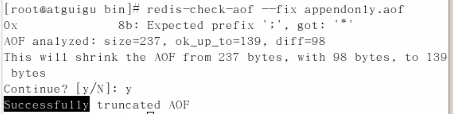
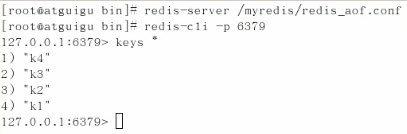
重启且恢复成功:
一主二从:
从机shutdown:
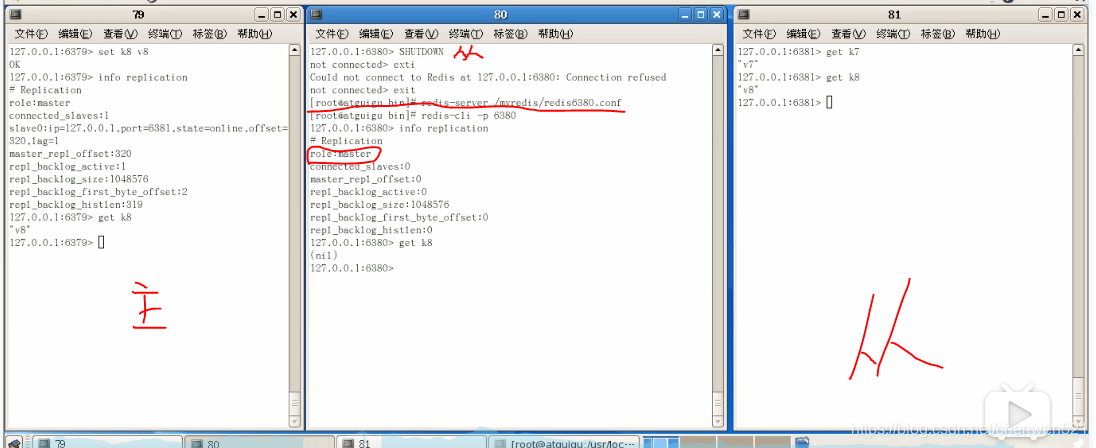
薪火相传:
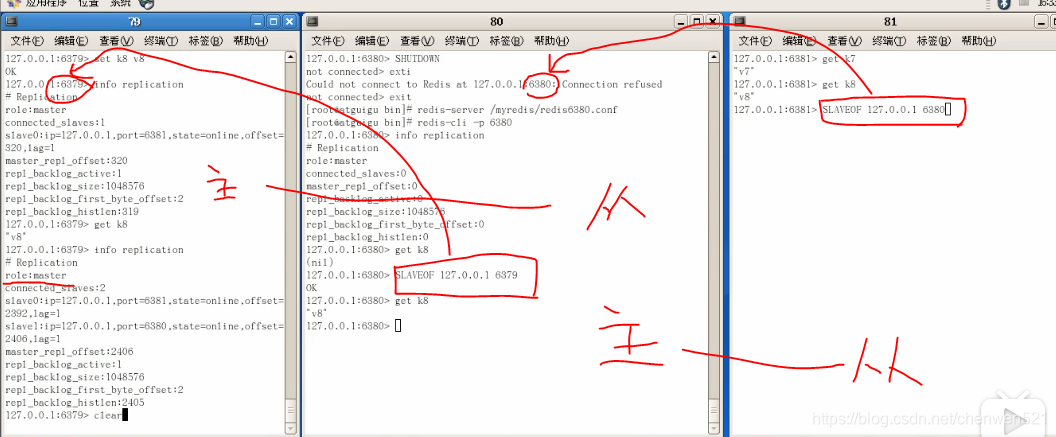

此时中间slave的角色:
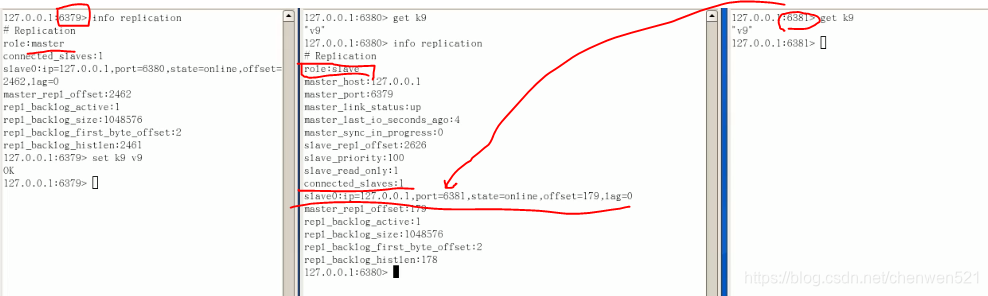
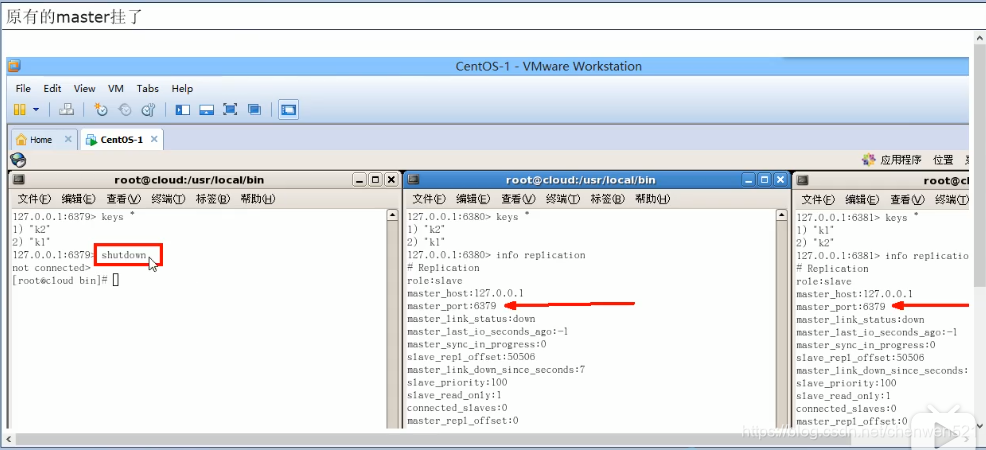
哨兵模式: 6379是主,对从机6380和6381进行巡逻
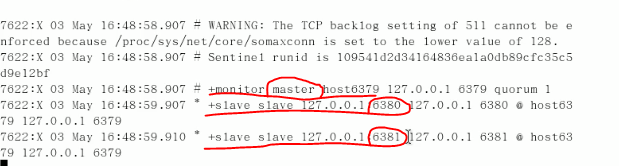
步骤1:
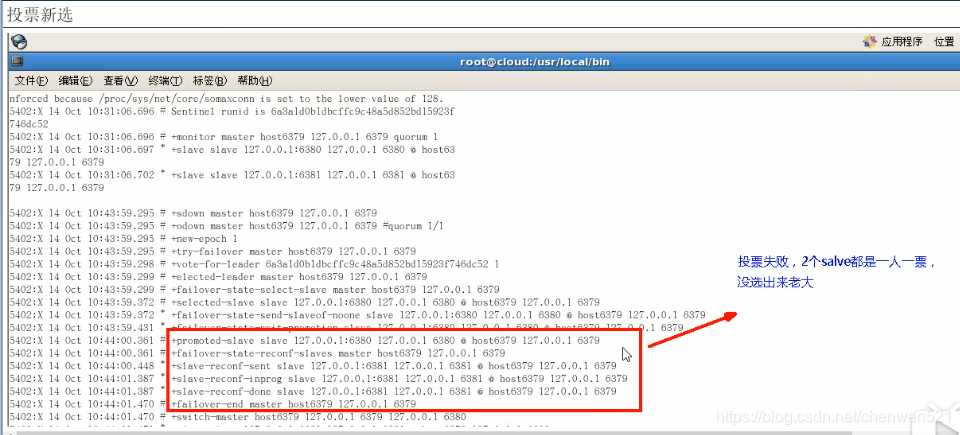
步骤2:
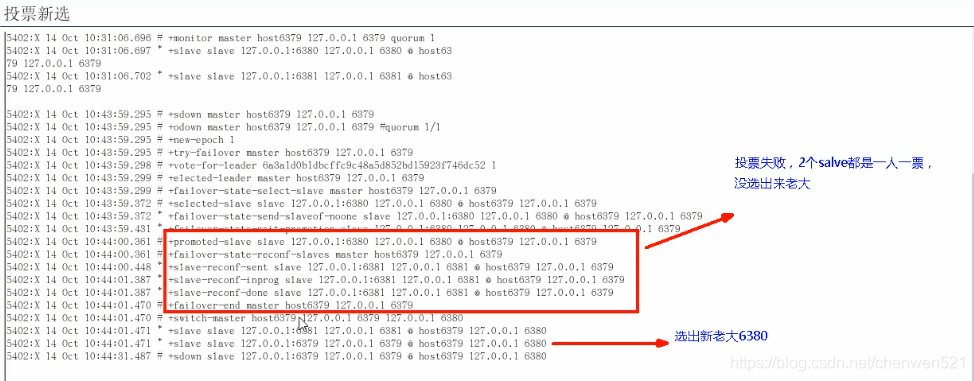
步骤3:
面试题之Redis集群:
面试题之Redis集群高可用:
面试题之Redis KEY过期策略
面试题之Redis简介
基础概念捋顺
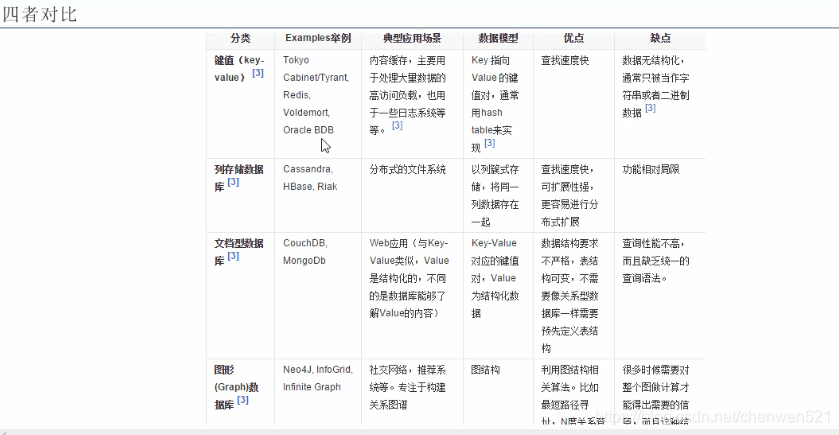
一、nosql
- 是什么?

- 作用:

- 为什么要用nosql
关系型数据库存放在磁盘中,磁盘I/O性能低,当访问量高时,性能低下,不利于高并发
关系型数据库数据关系复杂,不易扩展。而如今的数据特点:大数据,多类型。

- 特征:

- 常见的nosql数据库:

- 针对不同场景的应用
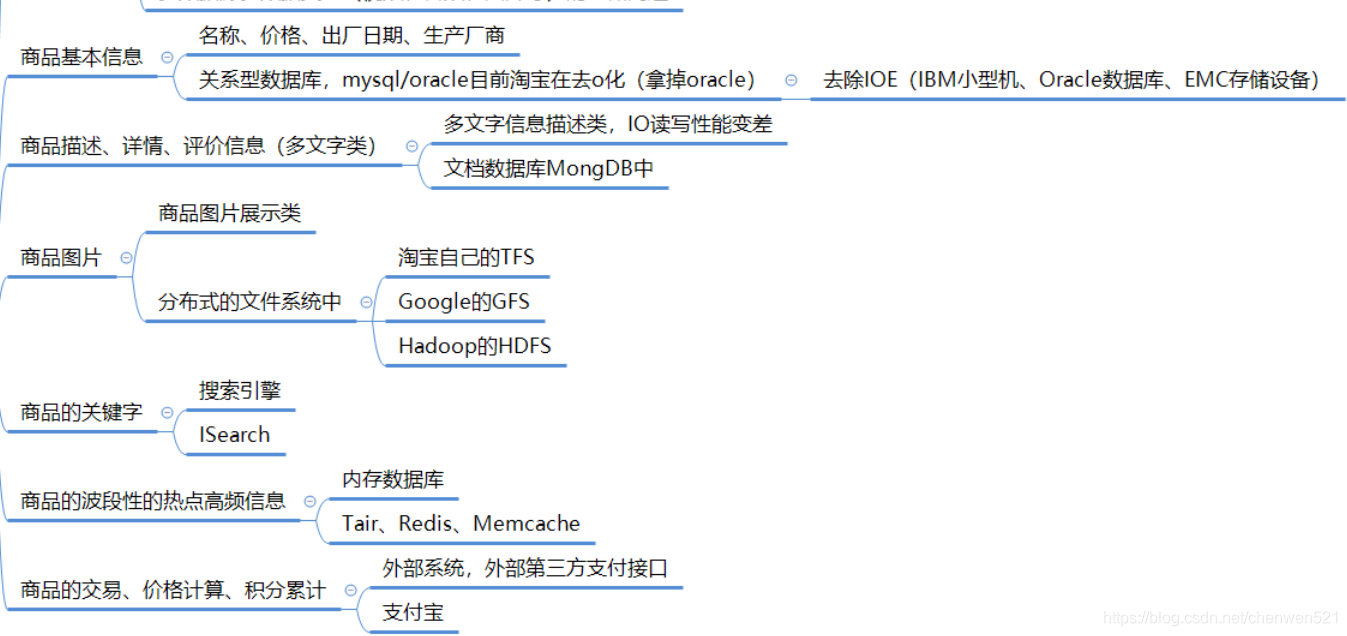
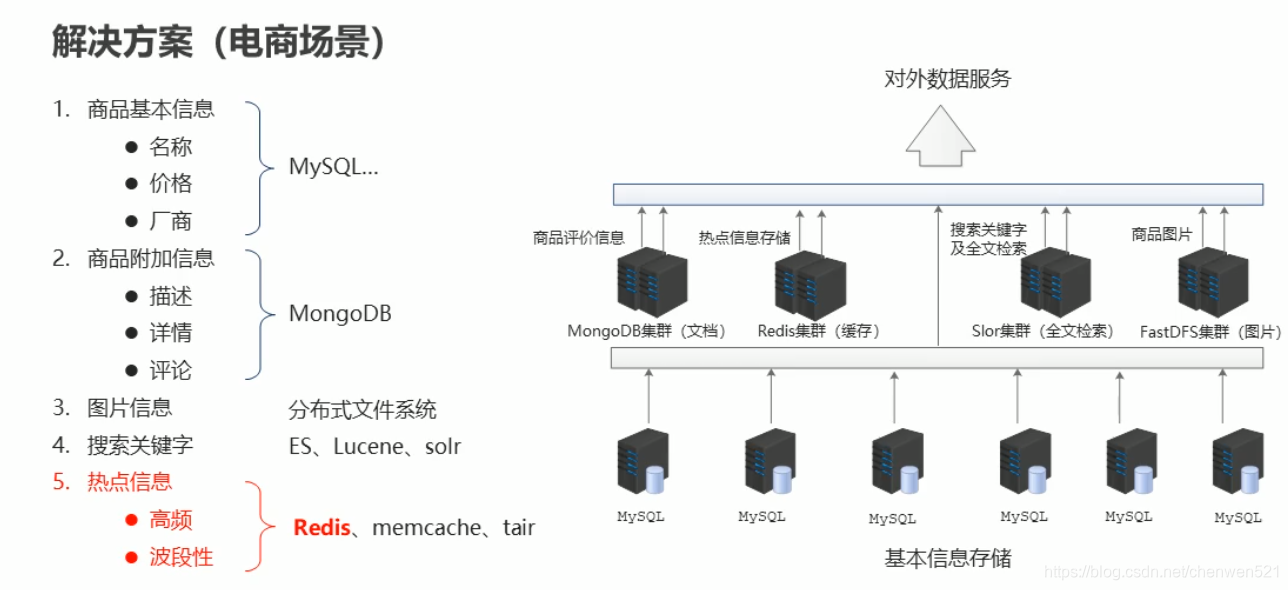
二、Redis
- 简介:

- 特点:

- 应用:

Redis五种数据类型:
1. String
2. hash:
- 出现原因:

改进:
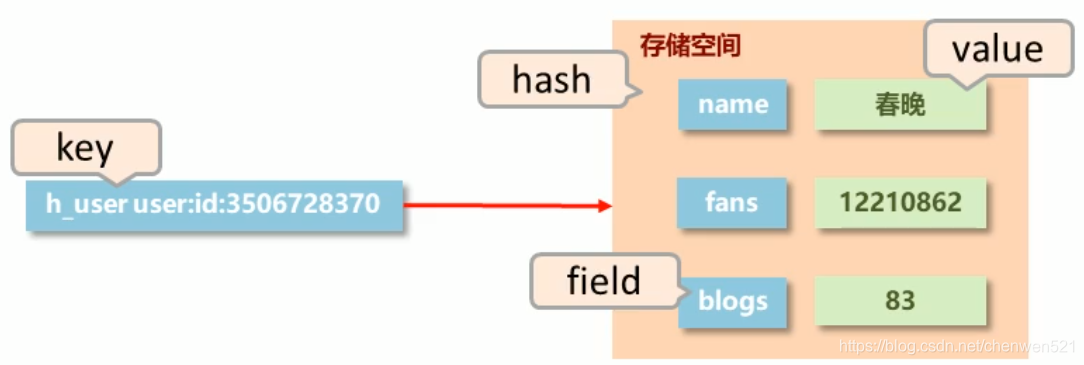
- hash类型:
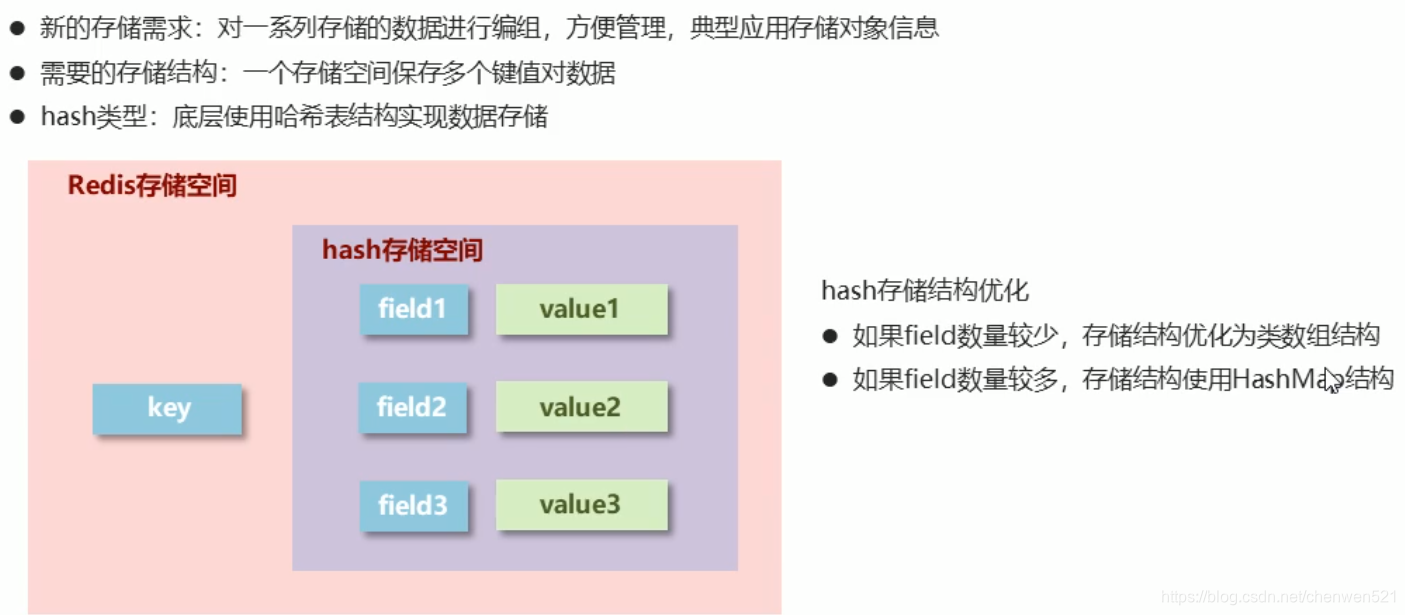
- 基本操作:


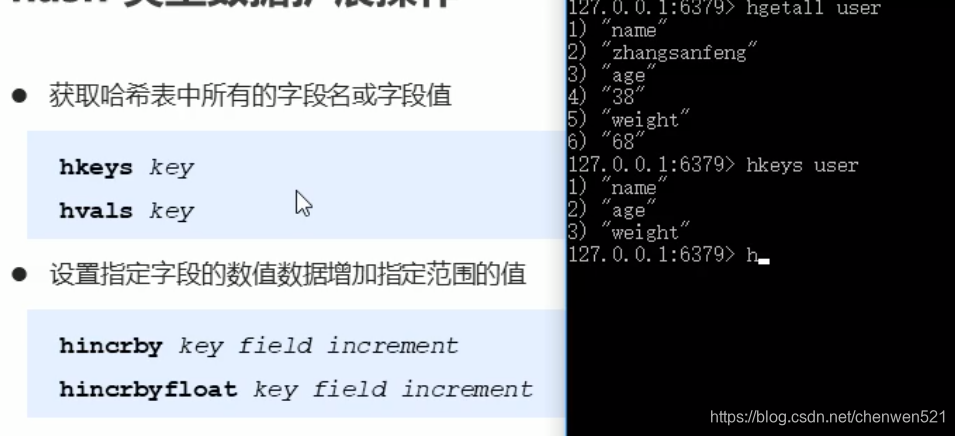
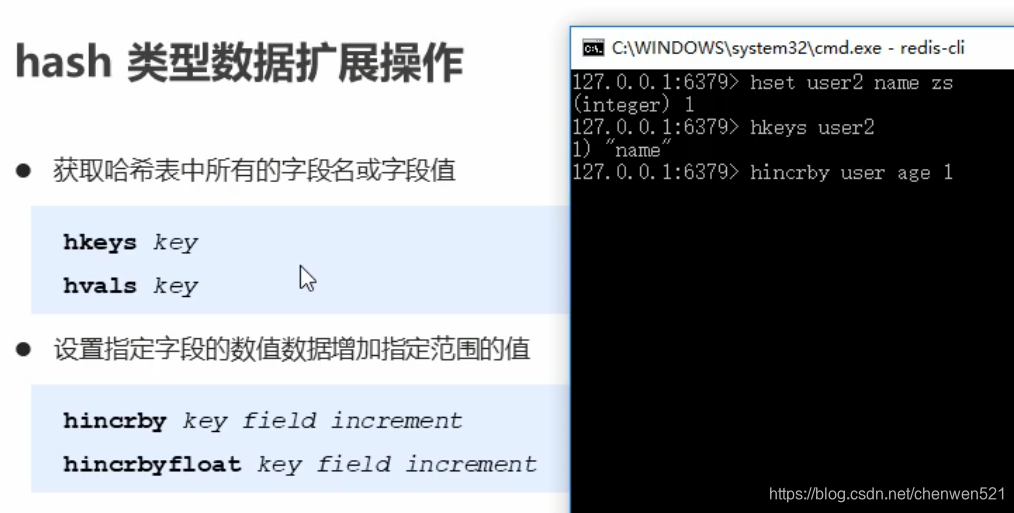
- hash类型数据操作的注意事项:

- hash类型应用场景之购物车(买家):
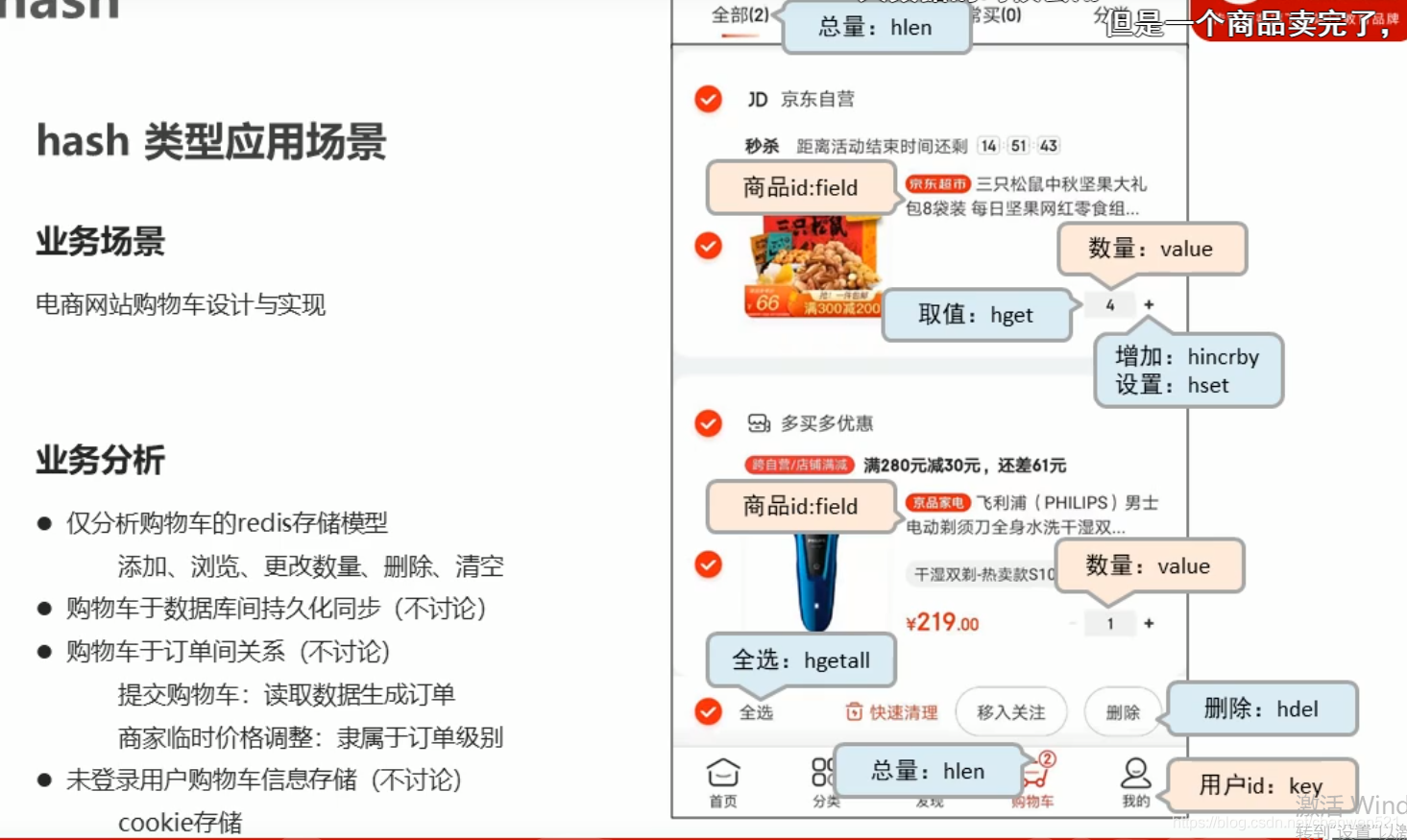
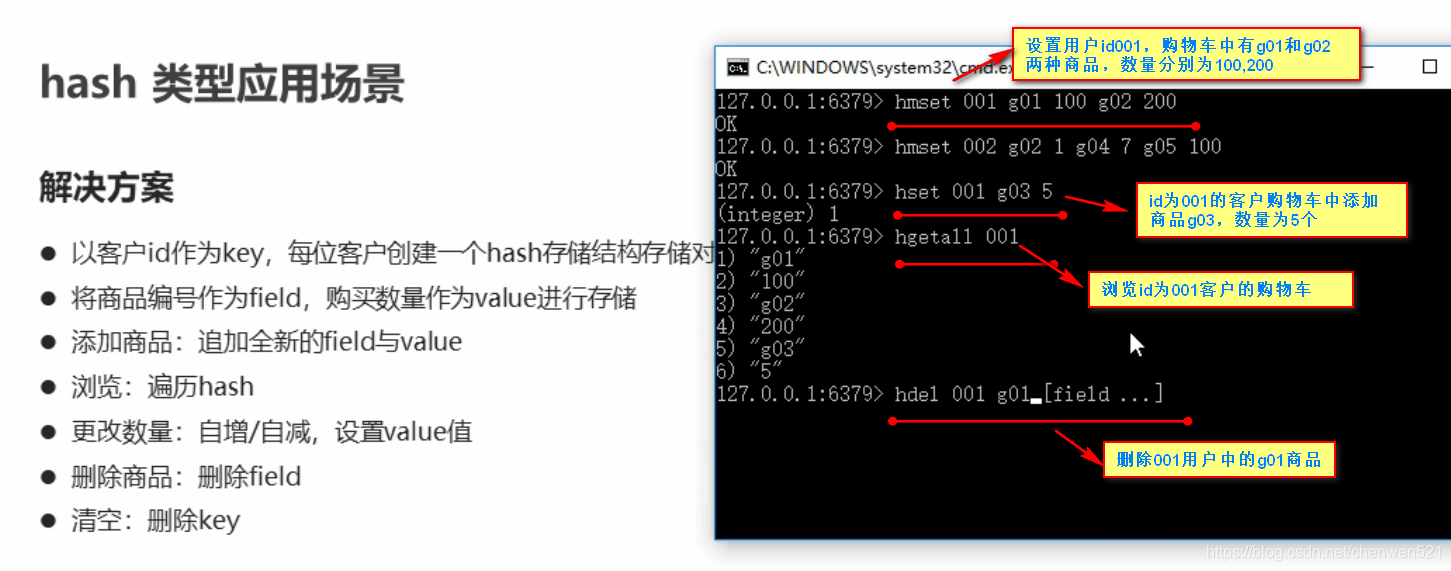

- hash类型应用场景之业务场景(卖家):



自己理解:redis用不同的数据结构存储一些数据,供服务器可以高效使用这些数据以处理某些业务,
首先:服务器处理业务首先需要拿到数据
然后:数据如何存储?用关系型或者菲关系型数据库存储
选择标准:服务器需要快速拿到这些数据还是不用快速拿到
在数据库中如何存储这些数据:选择适合存储这些数据的数据结构对数据进行存储。
3. list
- list类型特点 多个数据 顺序

- list类型数据基本操作



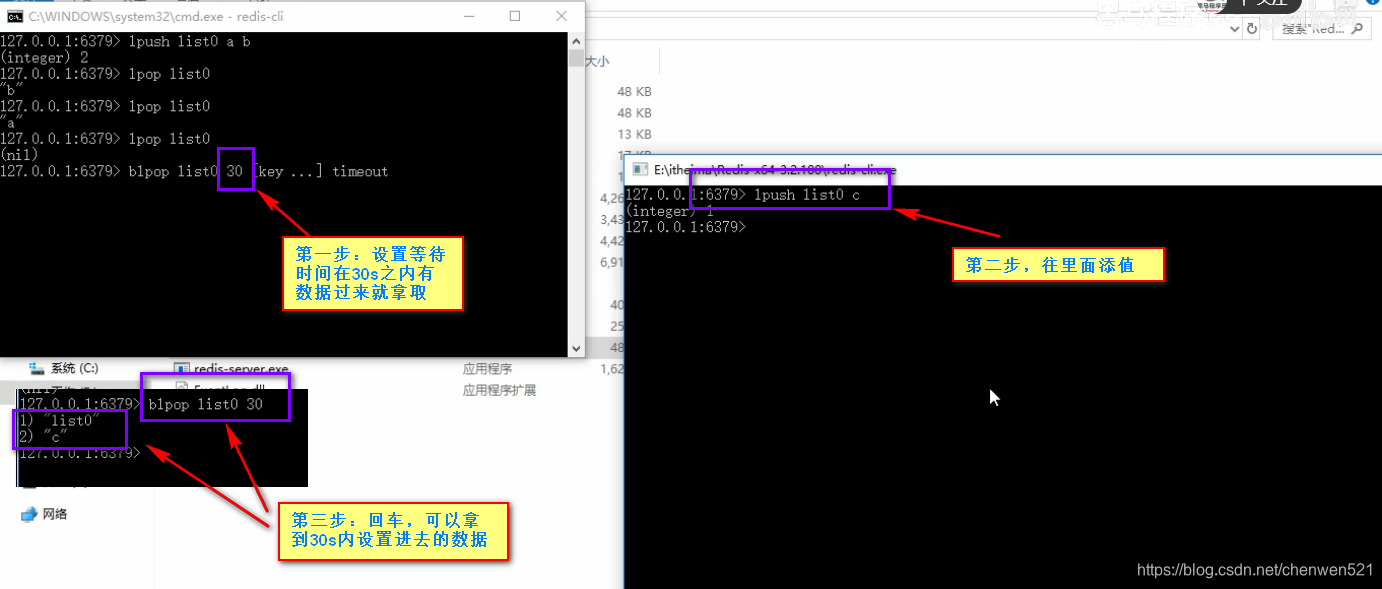
- 业务场景
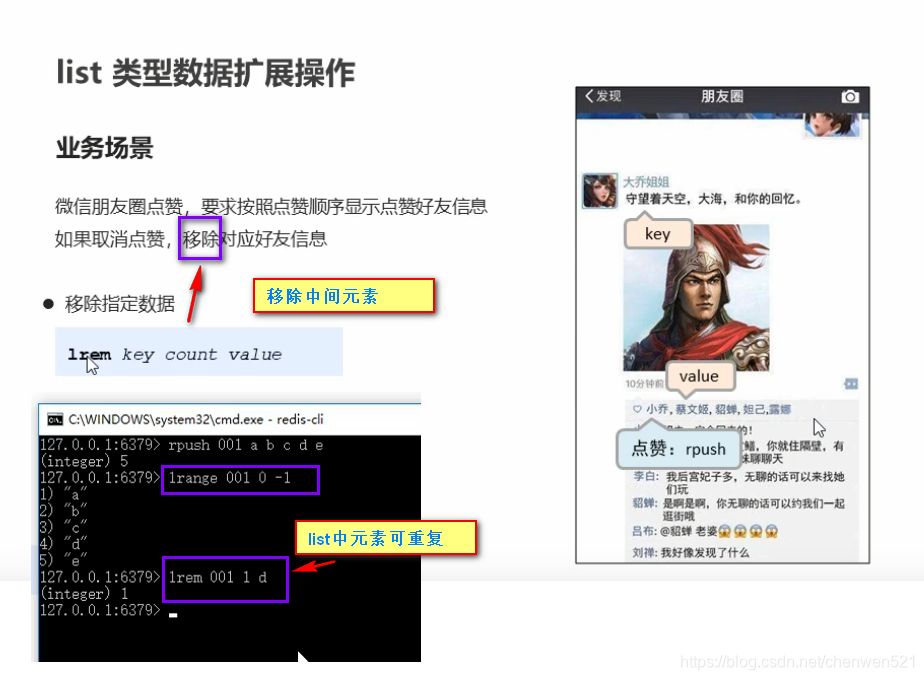

- 注意事项

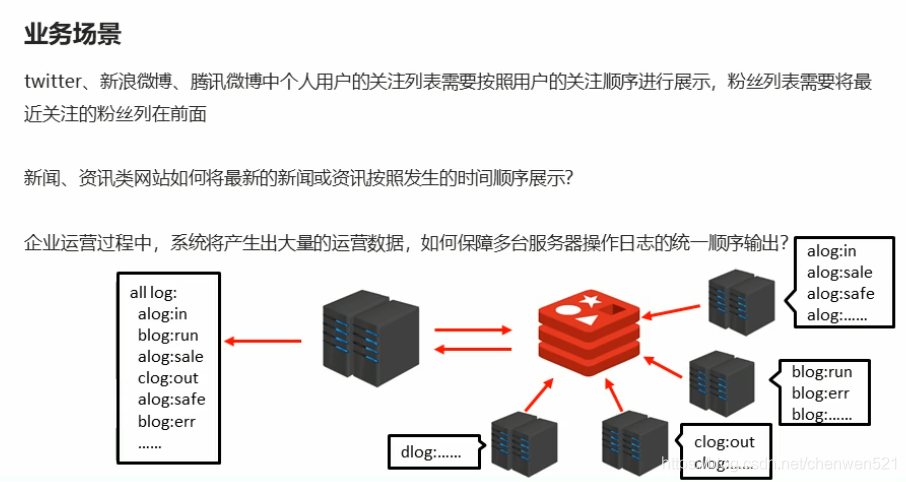
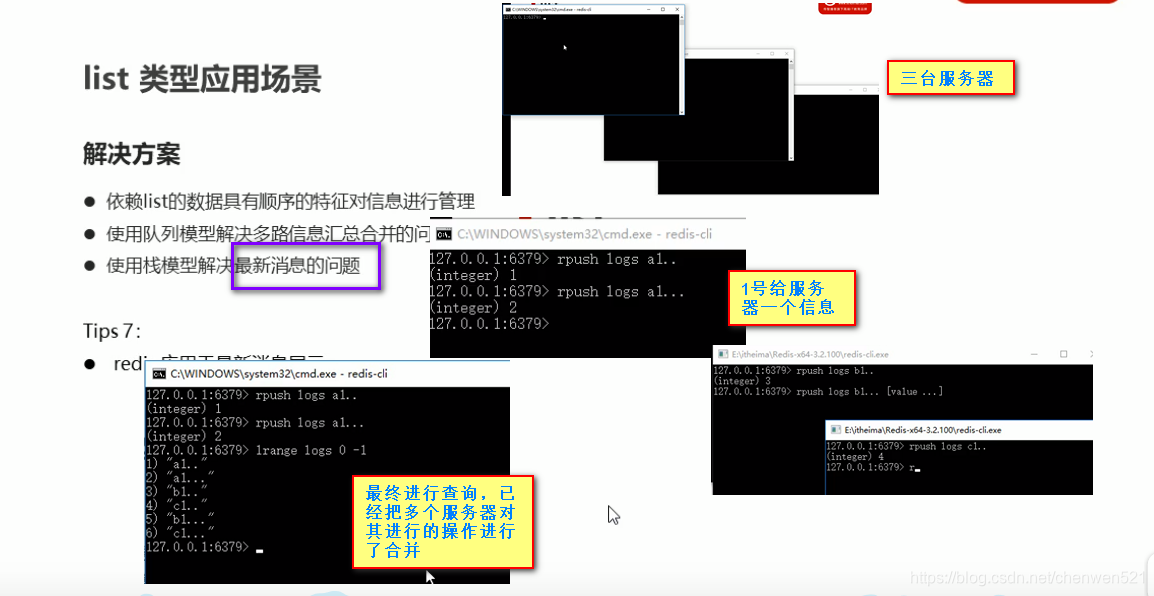
- 综合应用场景
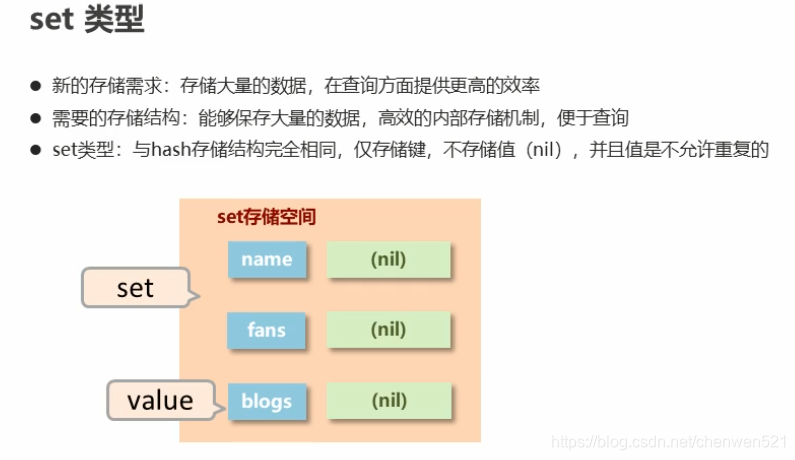
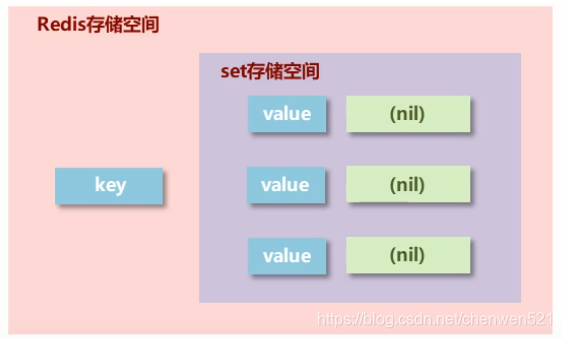
4.set
- set类型
为什么?list也可以存储大量数据,但由于底层是链表,读取数据太慢…
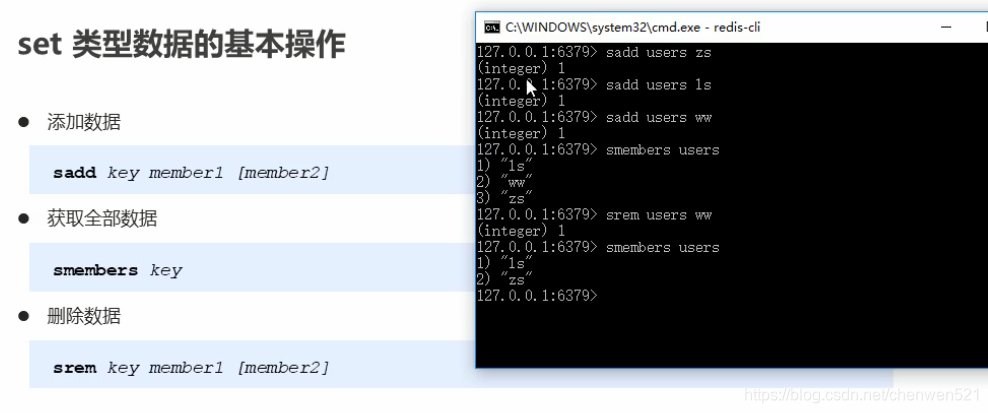
- 基本操作
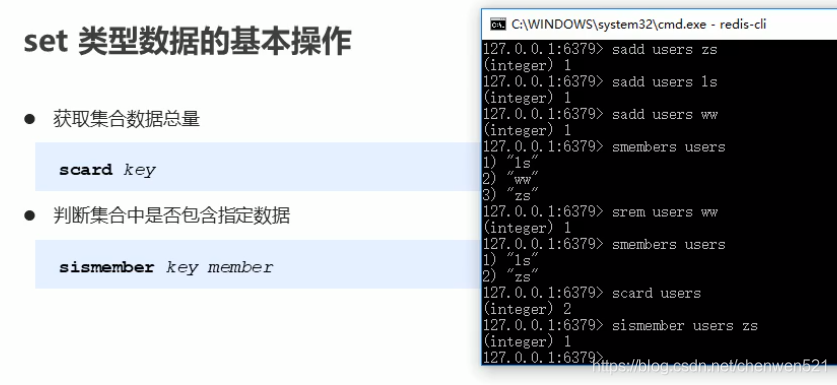
- 业务场景
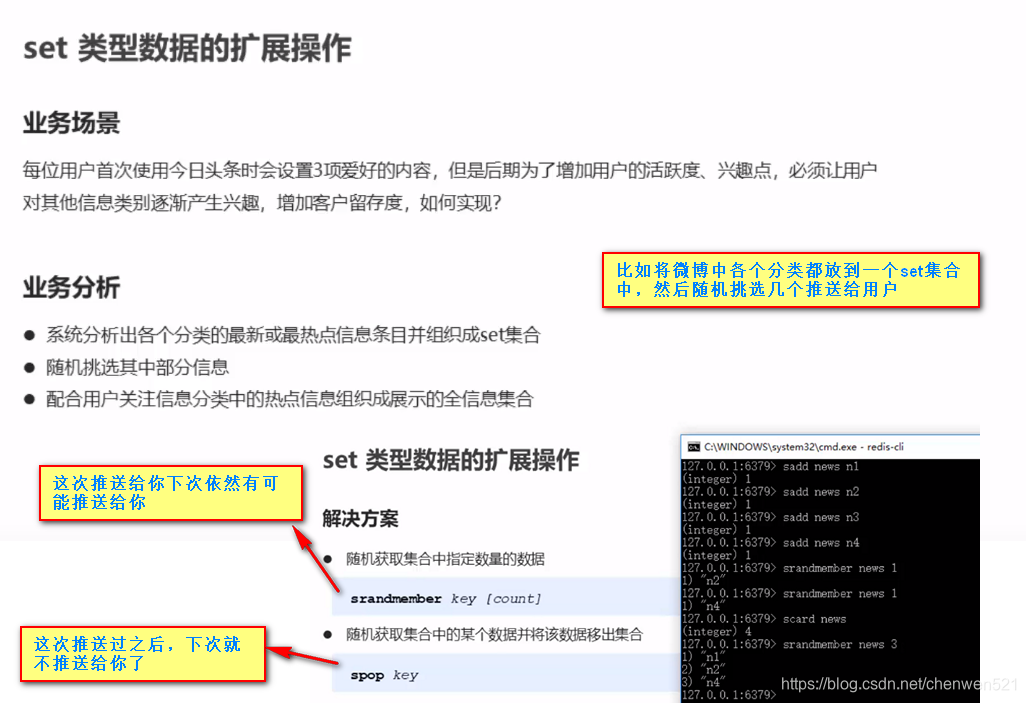


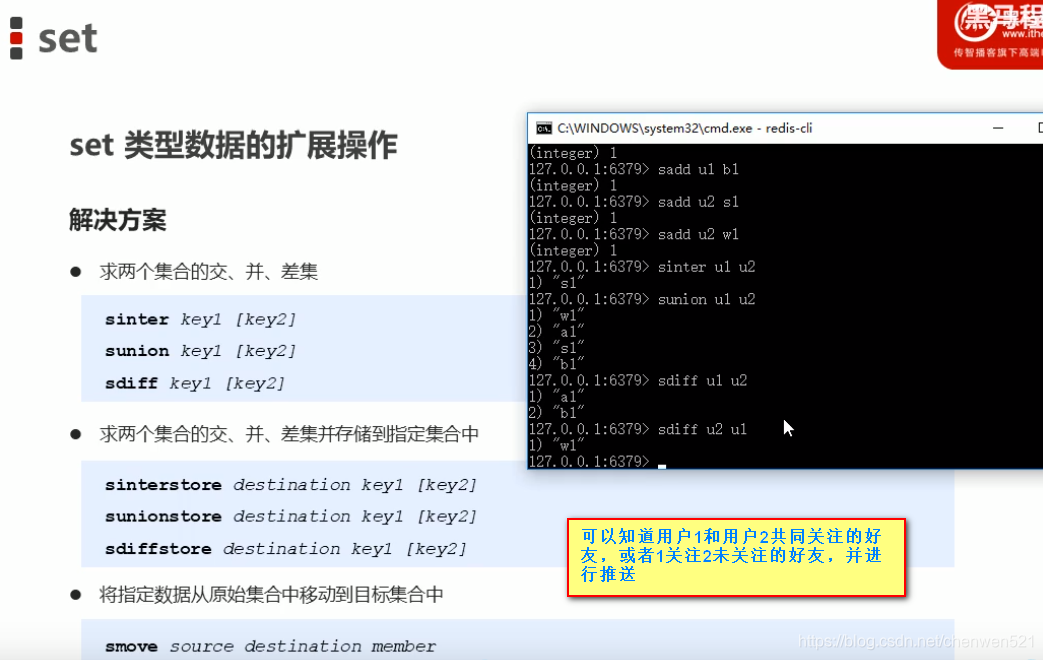

- 注意事项


- set类型应用场景(数据过滤)

应用场景:


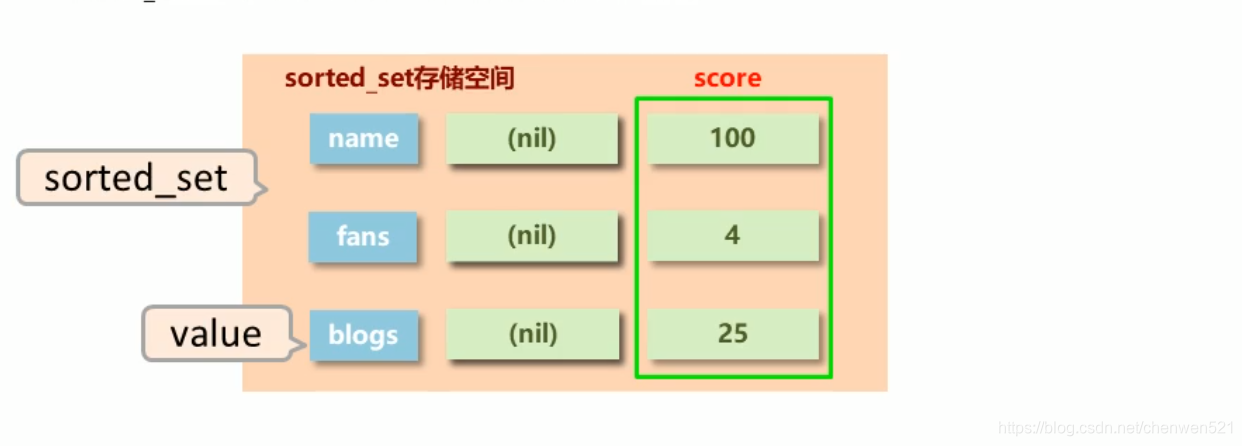
5.sorted_set
-
为什么?set、list没有对结果进行排序的特征。所以出现sorted_set(既可以存储大量数据,也可以对其进行排序 ),比如排行榜等…

-
sorted_set类型
-
基本操作
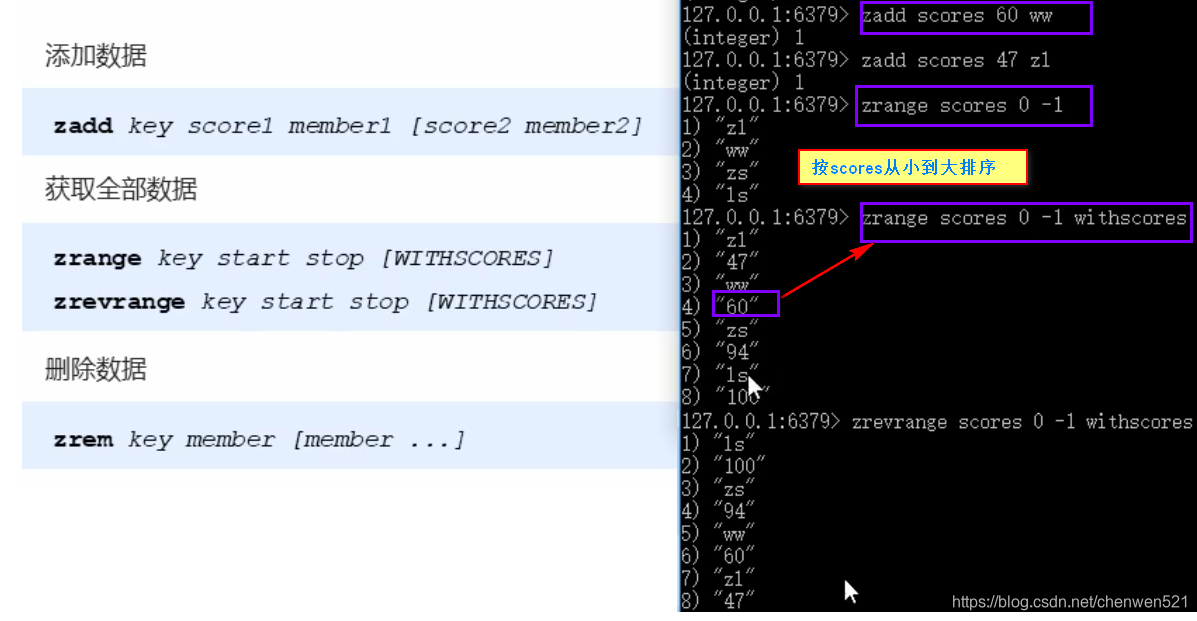
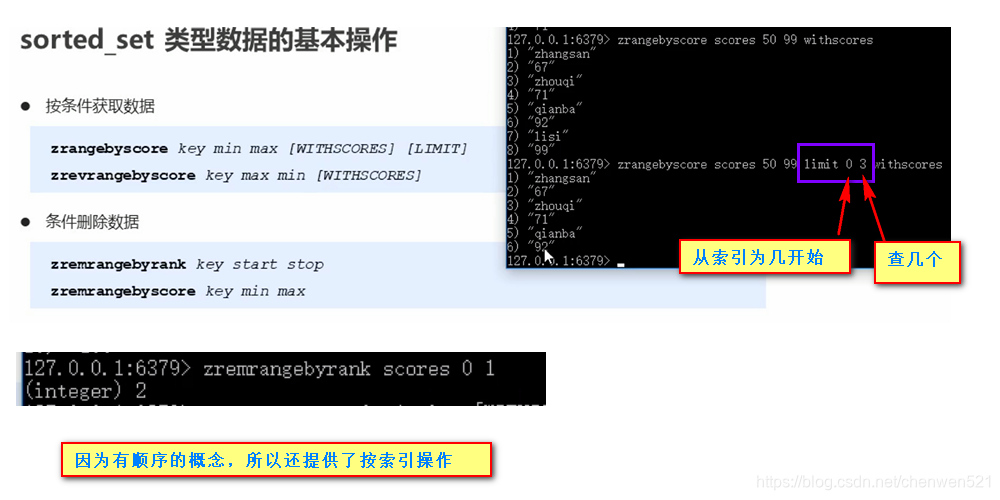

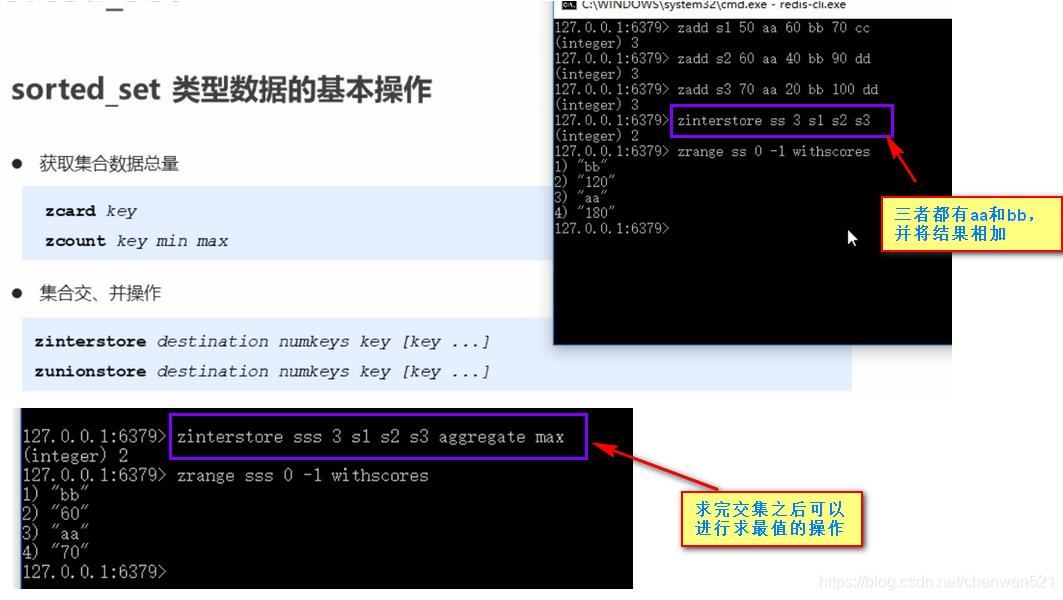
-
扩展操作
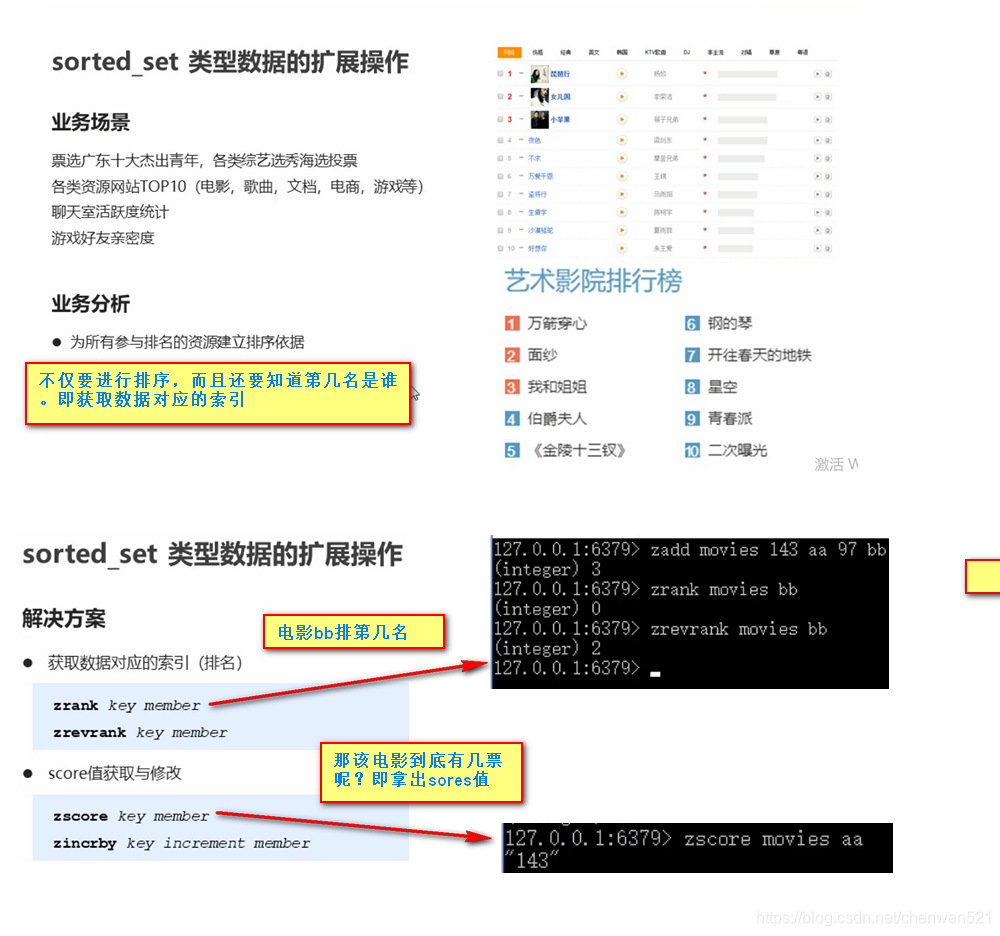

-
注意事项

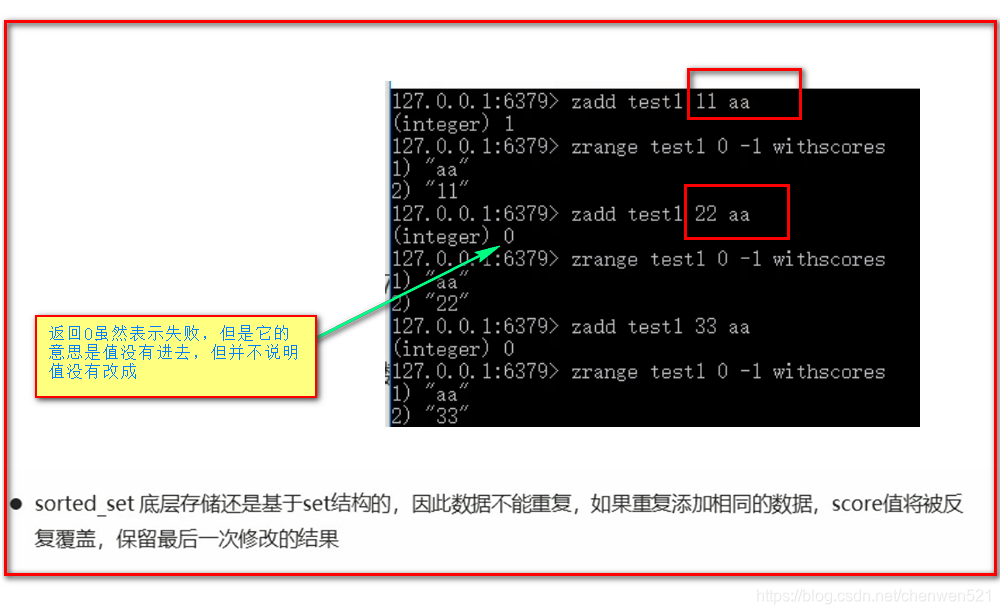
-
应用场景



6.综合实践案例
- 业务场景
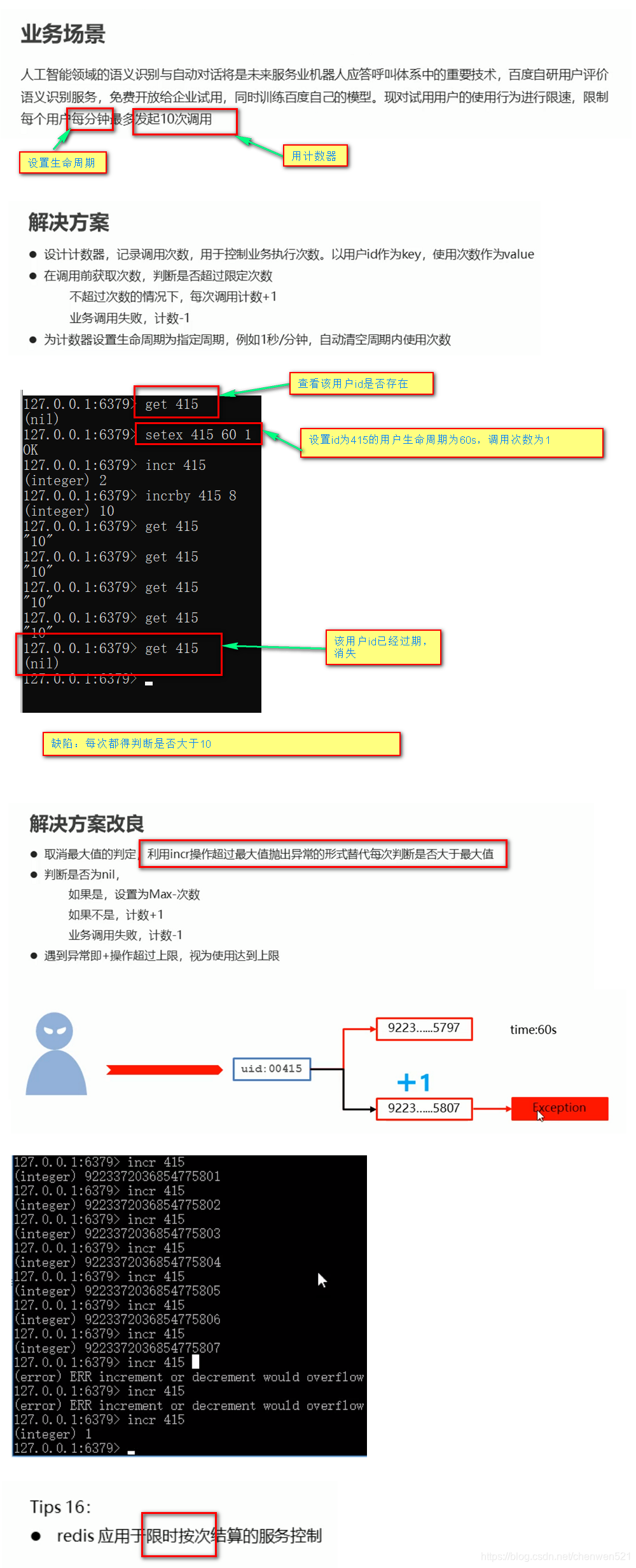


通用命令
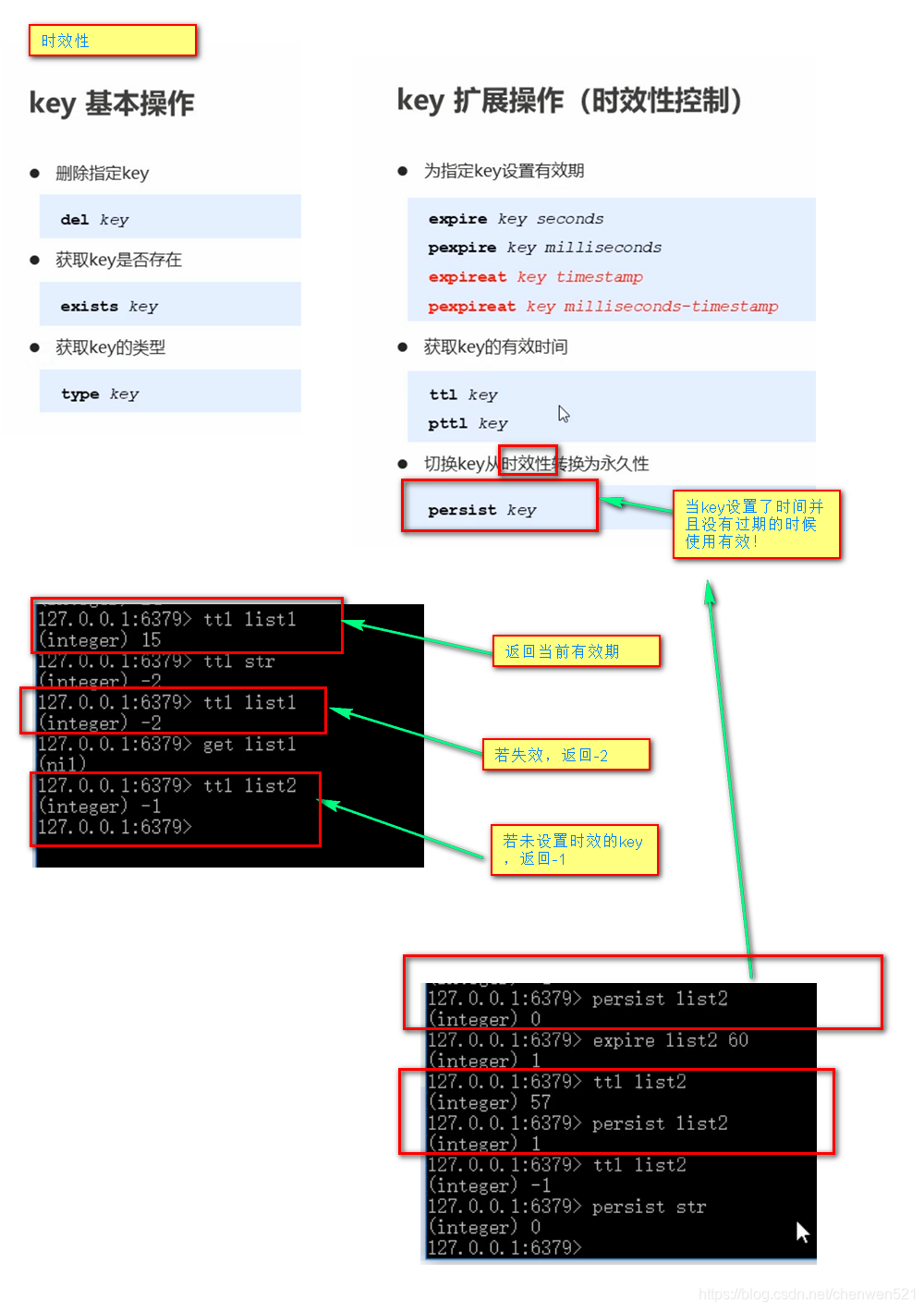
1. key特征

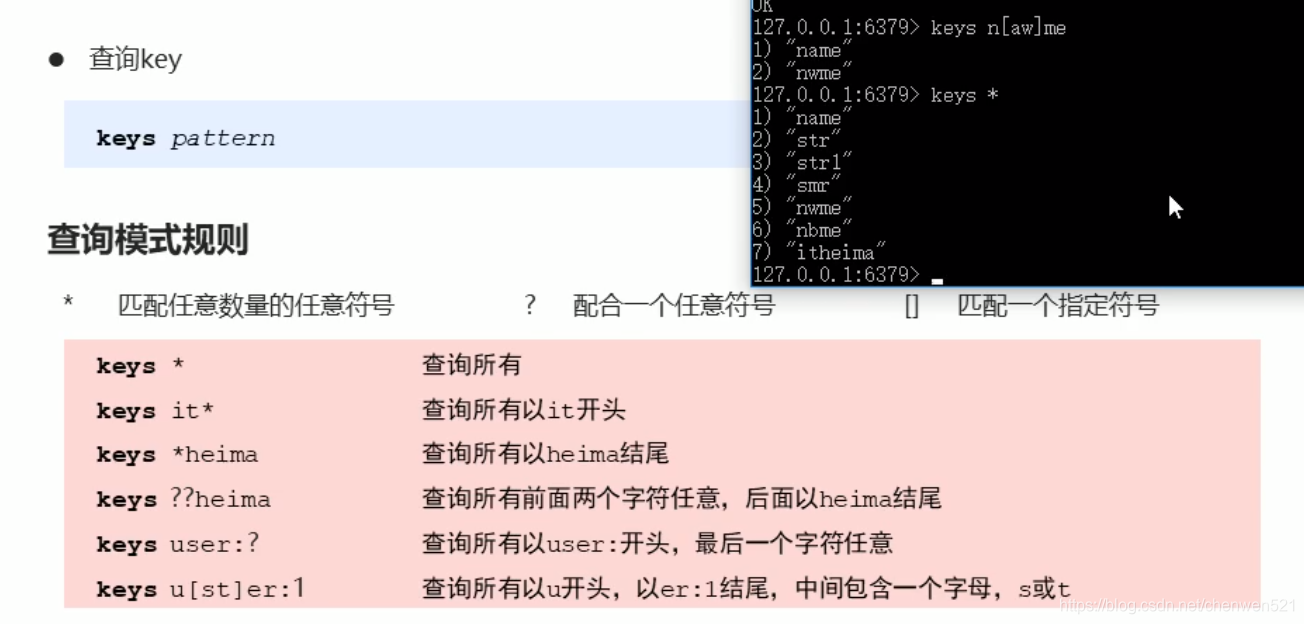


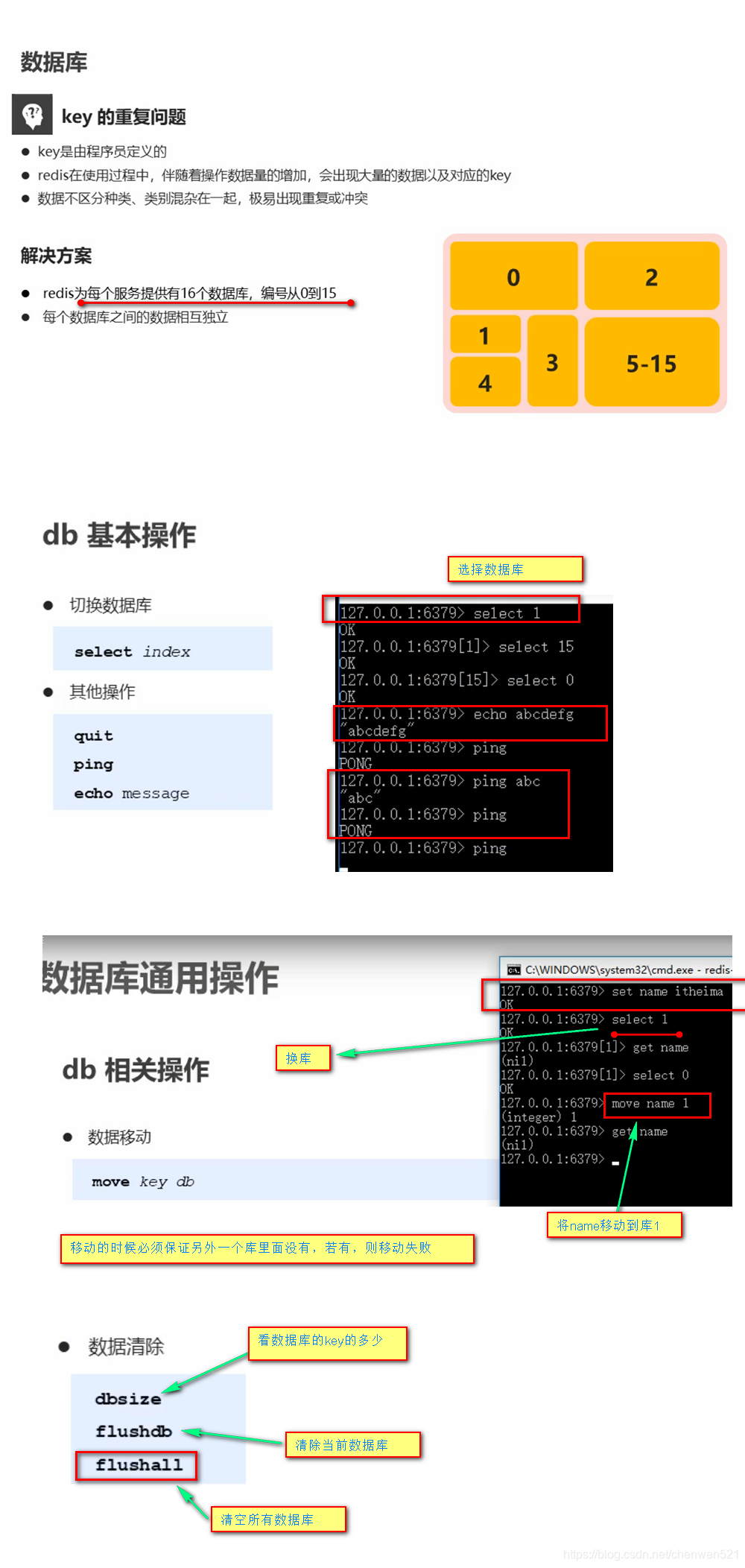
2. 数据库通用操作
Jeids(java连接redis的一个工具类)用java操作redis
1. 简单操作
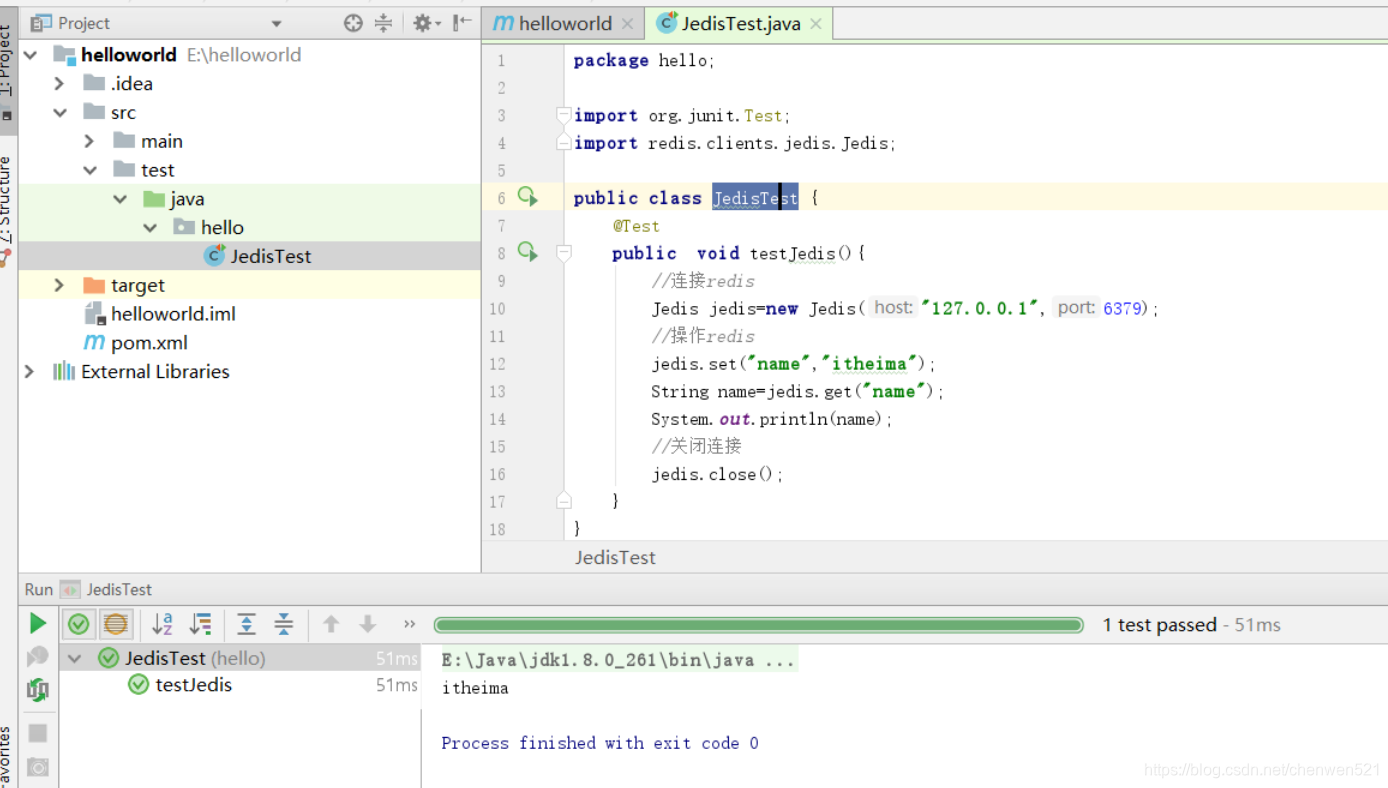

2. Jedis简易工具类开发(配置连接池)

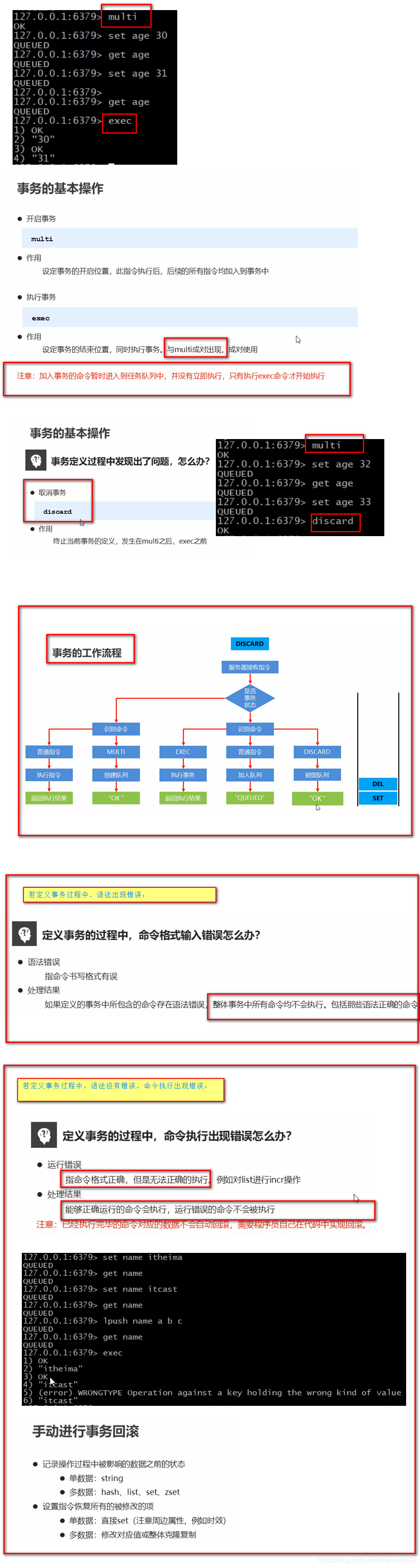
事务
1. 什么是事务

2. 开启事务

3. 事务操作
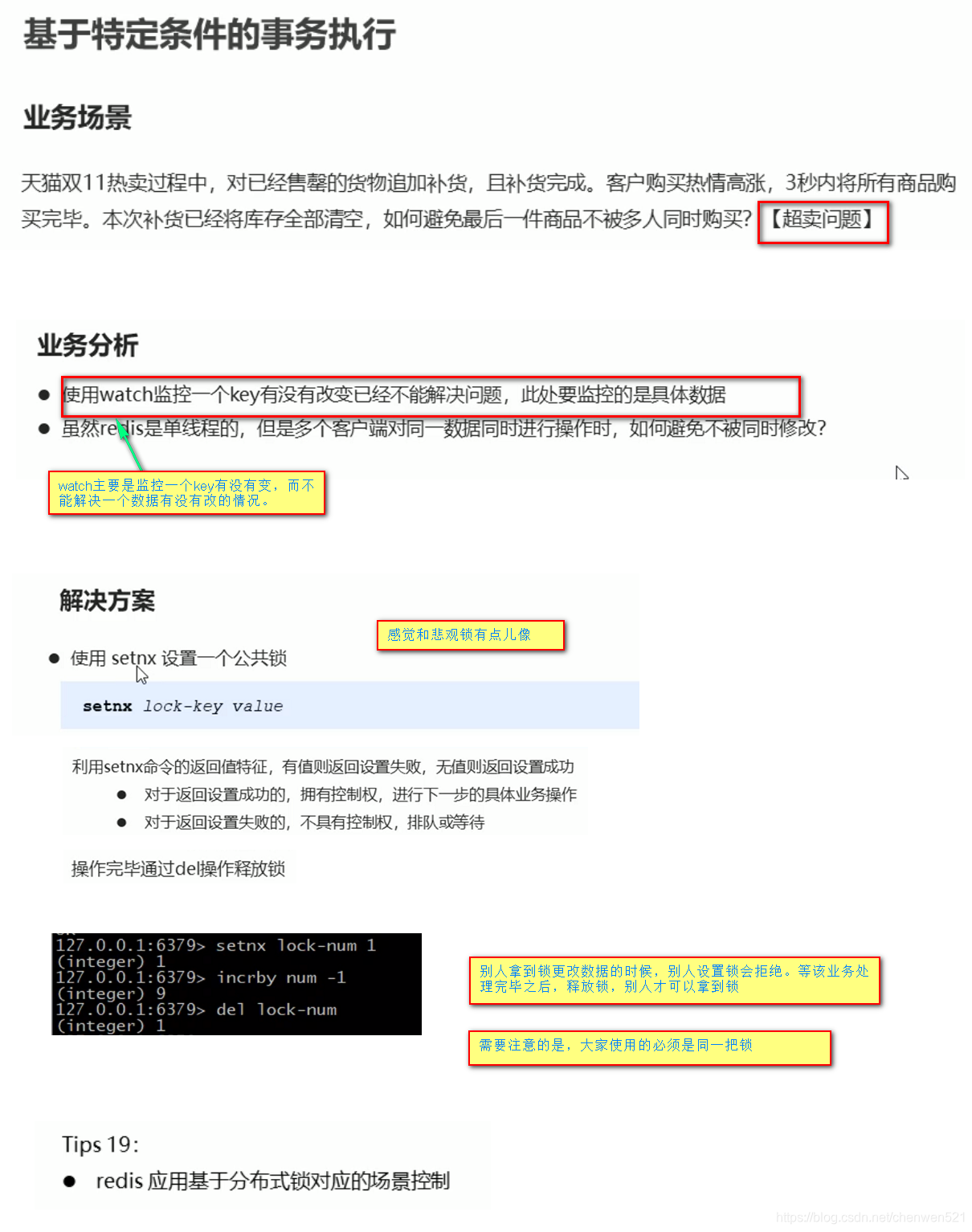
4. 锁

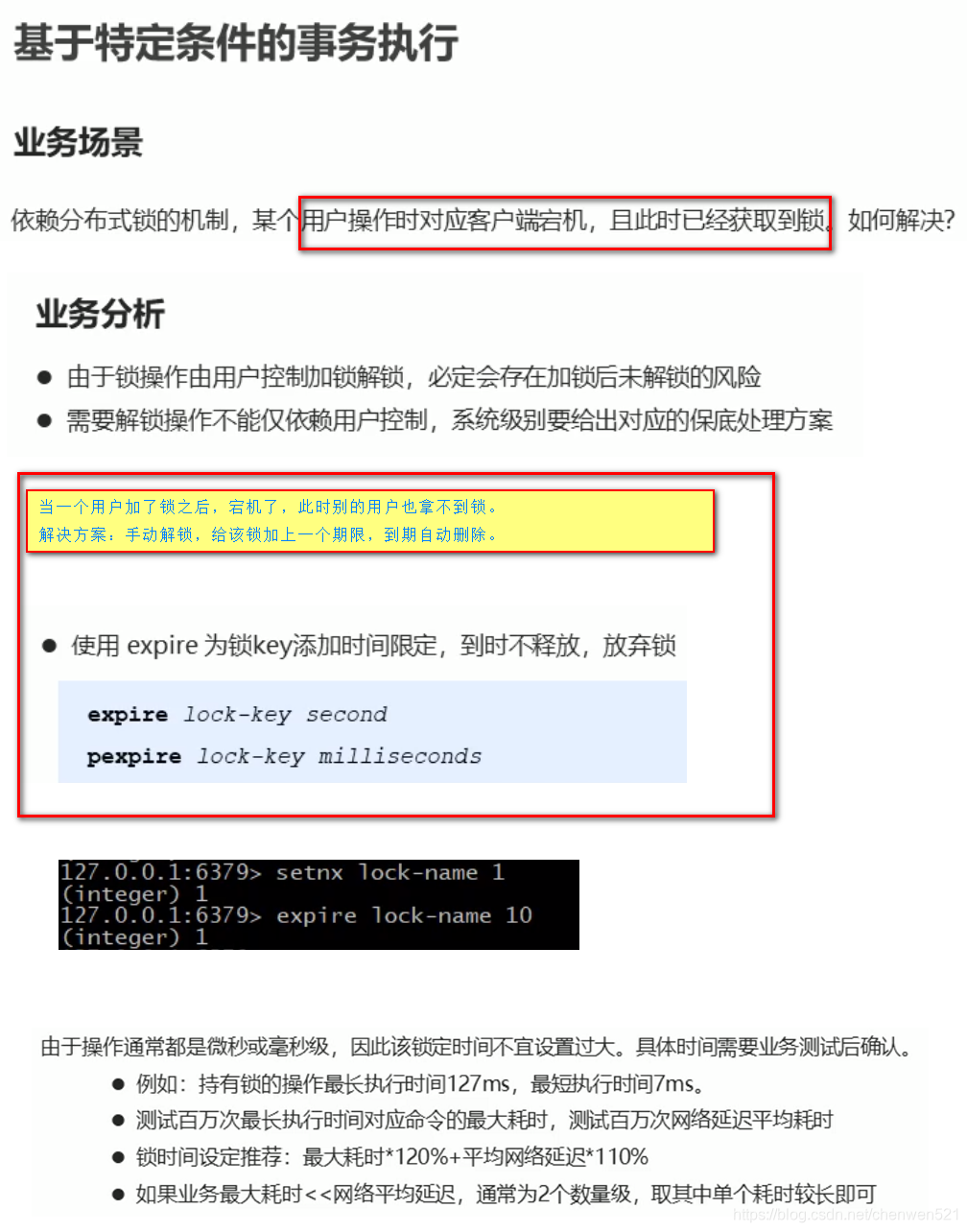
5. 分布式锁(超卖)
6. 对分布式锁加强,解决死锁问题
过期键删除策略

数据逐出(不过期)
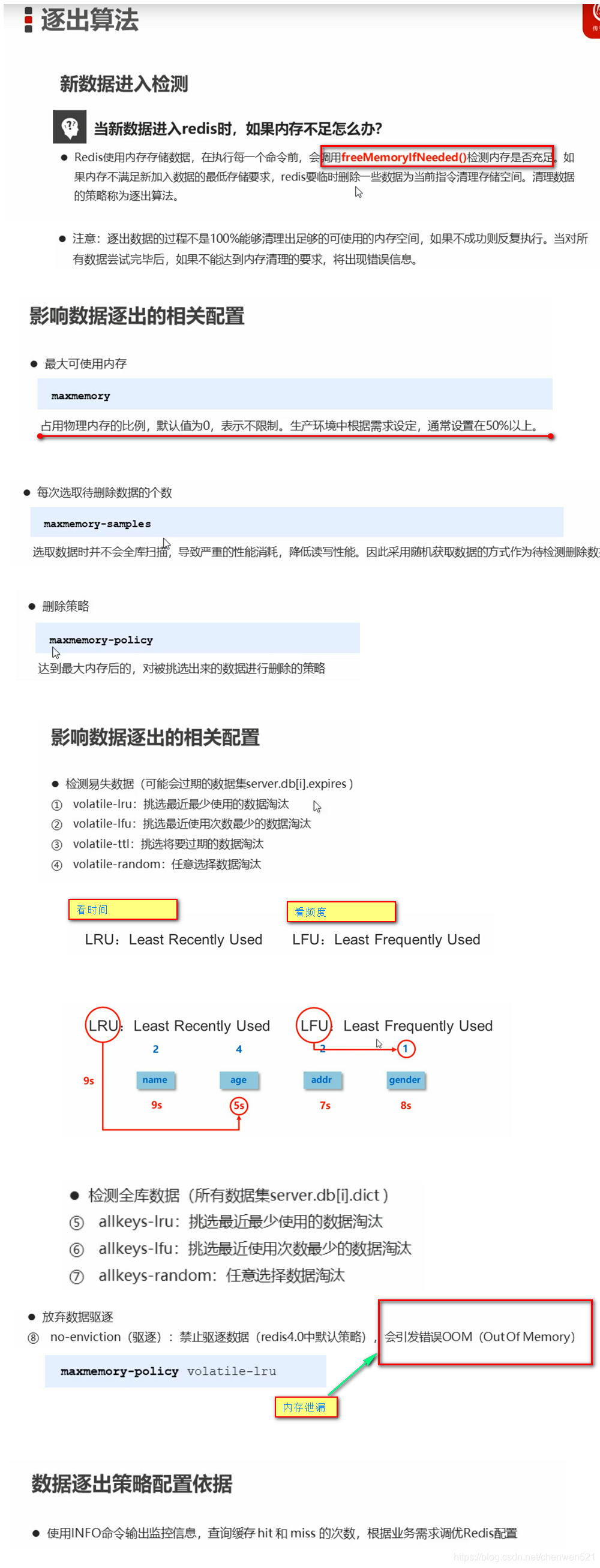
不管哪种策略都会占用内存空间,同时也会消耗掉CPU性能,选择的时候要达到一种平衡。没有绝对好的策略。
基于Linux环境安装Redis



企业级解决方案
缓存预热
当活动一开始,服务器直接宕机了,因为请求过多,而数据库存在硬盘上,过多的I/O操作导致高负载。处理方法就是,日差就日常统计数据访问记录,统计访问频度过高的热点数据。先将这些数据放在缓存中。


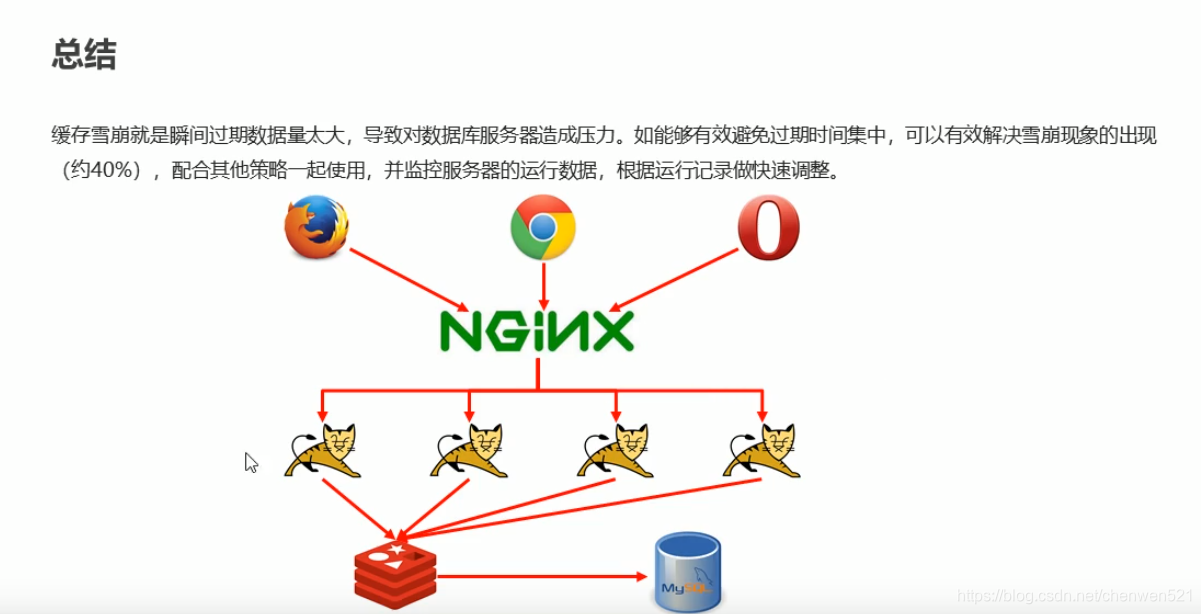
缓存雪崩(多个高热数据)


缓存中key值不可能都一直存在,所以都有一个过期时间。突然有某一时间点,大量的key集中过期,导致大量的请求奔向数据库。数据库接收到大量请求无法处理。

在redis和数据库延长一下,弄多级缓存。

缓存击穿(单个高热数据且过期)



正好有一个key高热且过期


预防为主
缓存穿透(黑客故意给你整崩,直接访问没有的数据)





性能指标监控


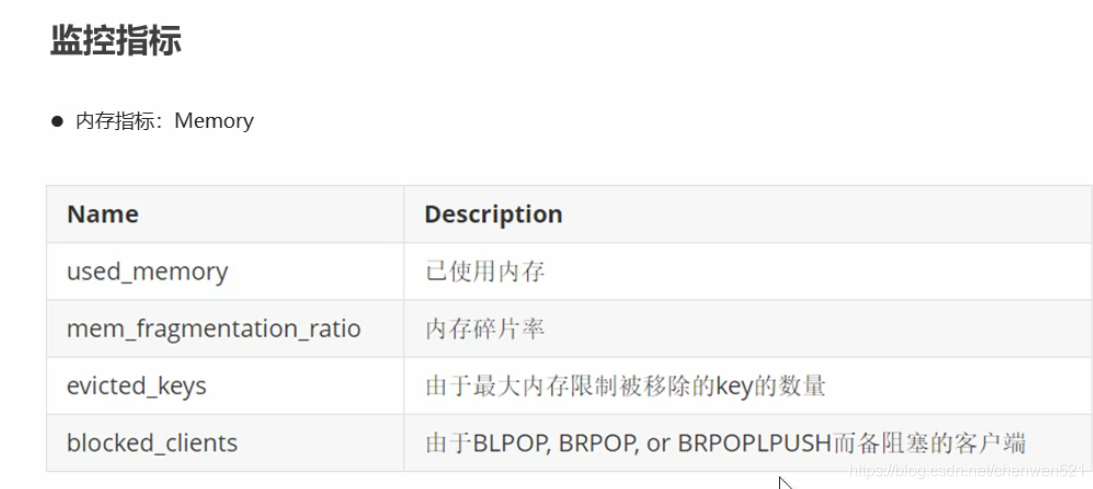
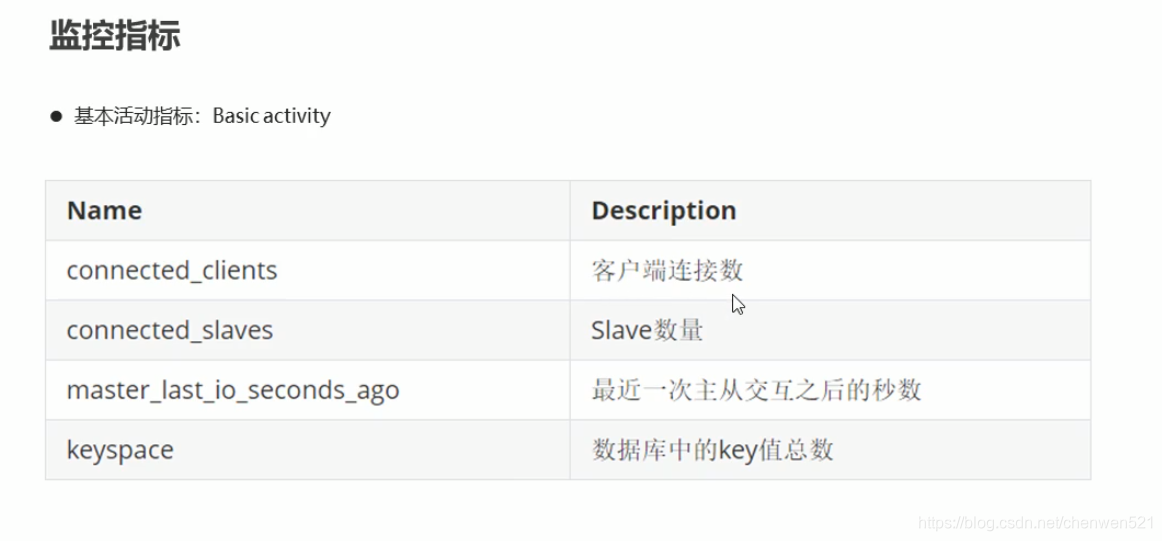
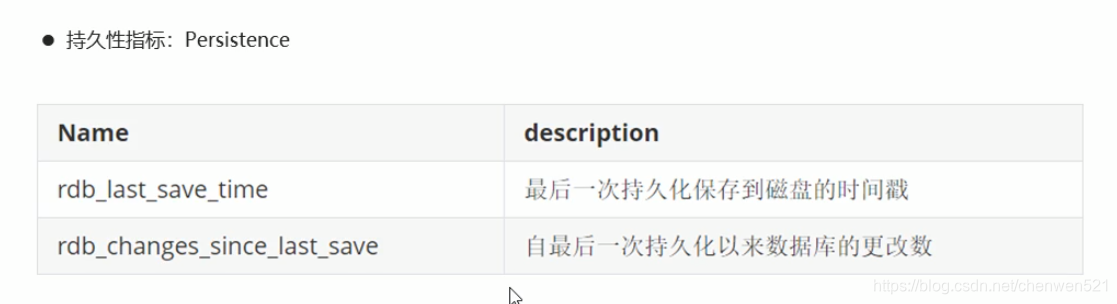

持久化
1. 简介


2. redis持久化的方式

3. RDB
启动方式

优缺点:

4. AOF
启动方式

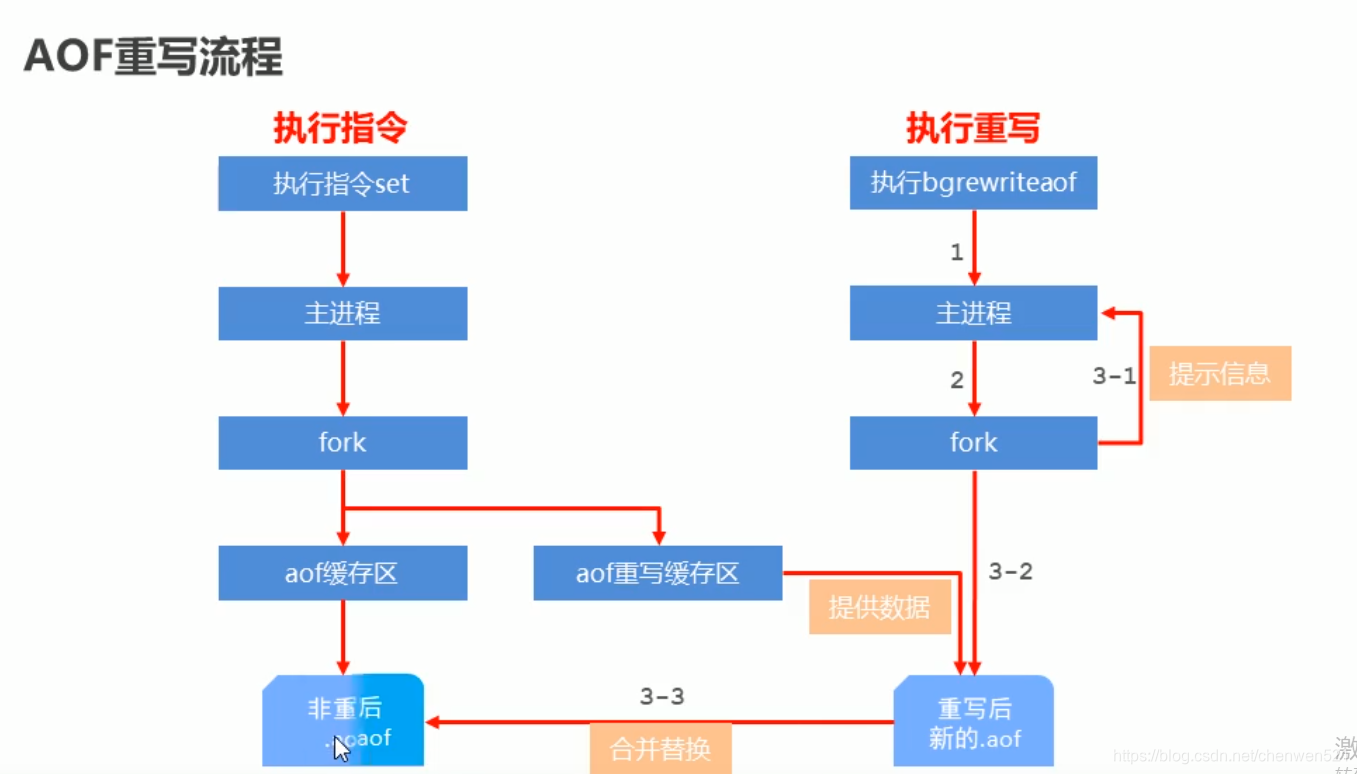
AOF重写
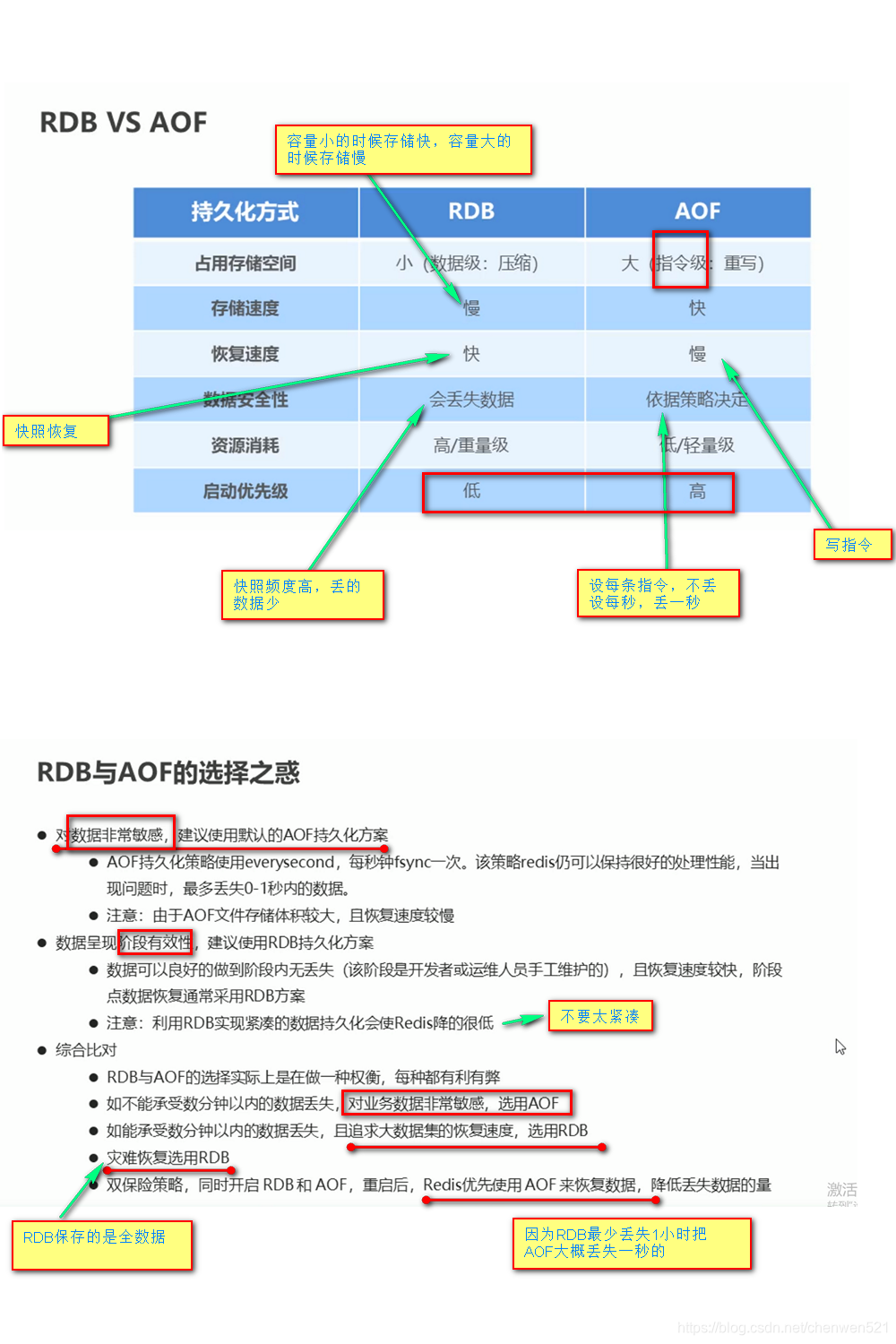
5. RDB与AOF区别
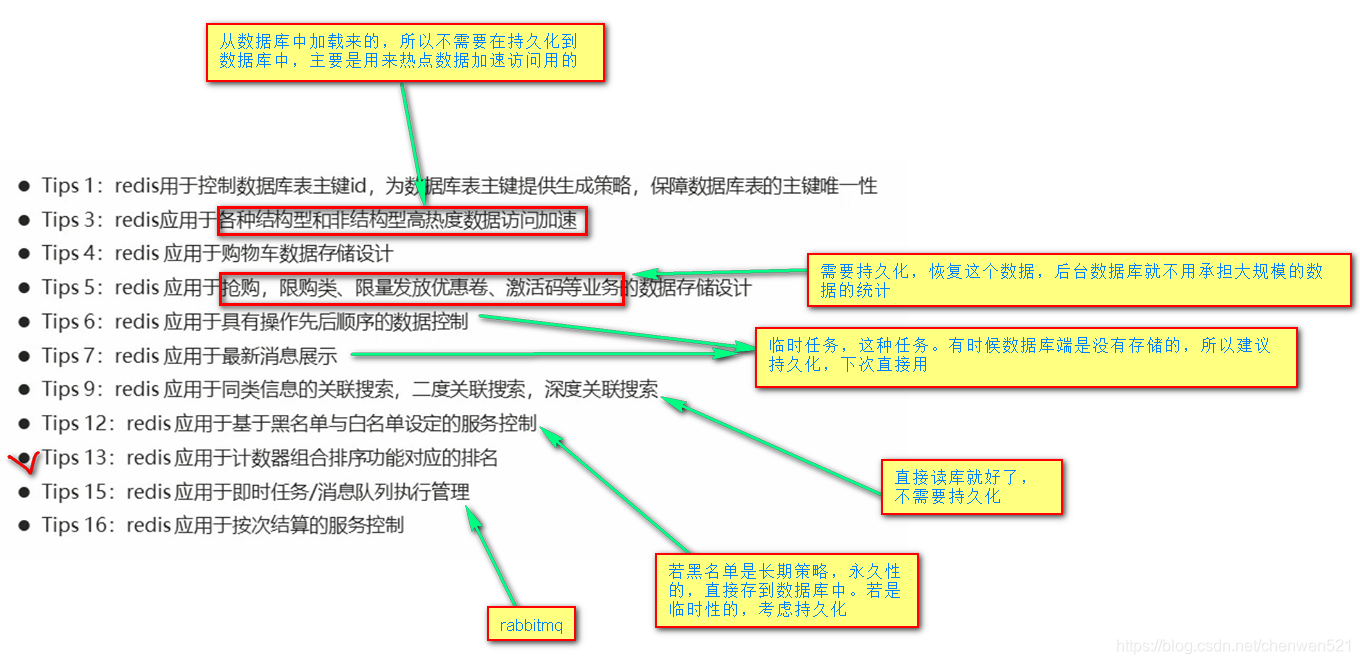
6. 应用场景
服务器基础配置

高级数据类型
1. Bitmaps
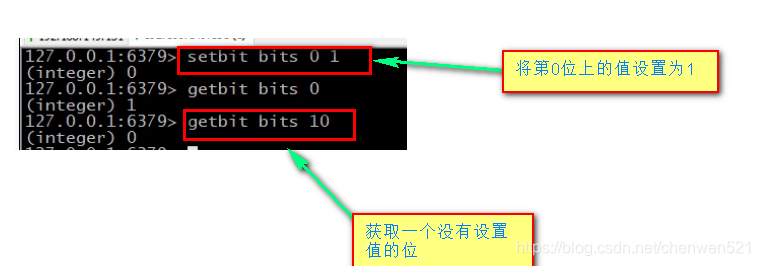
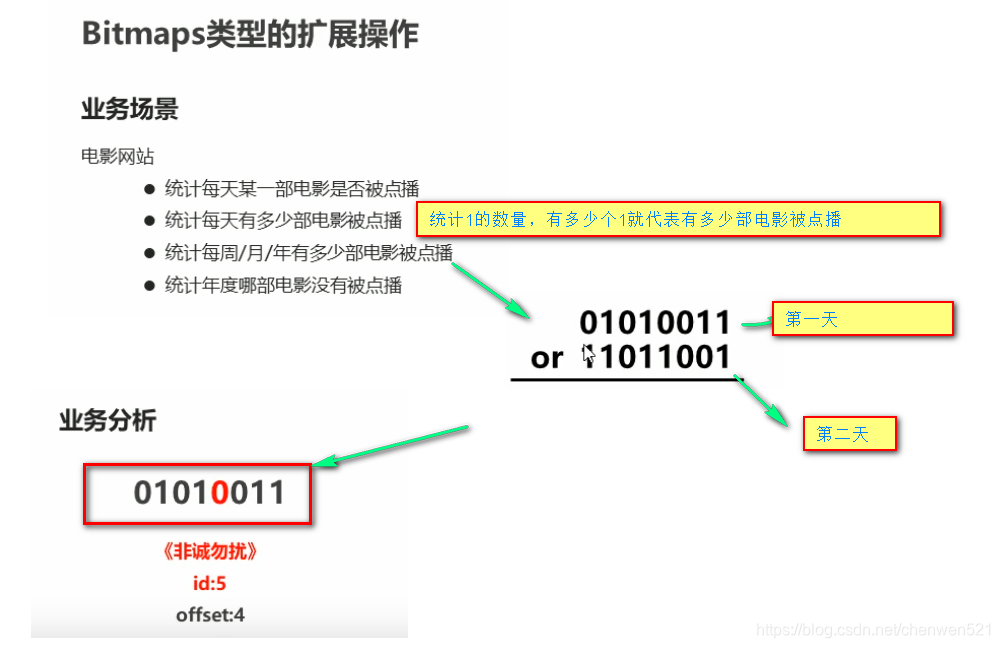

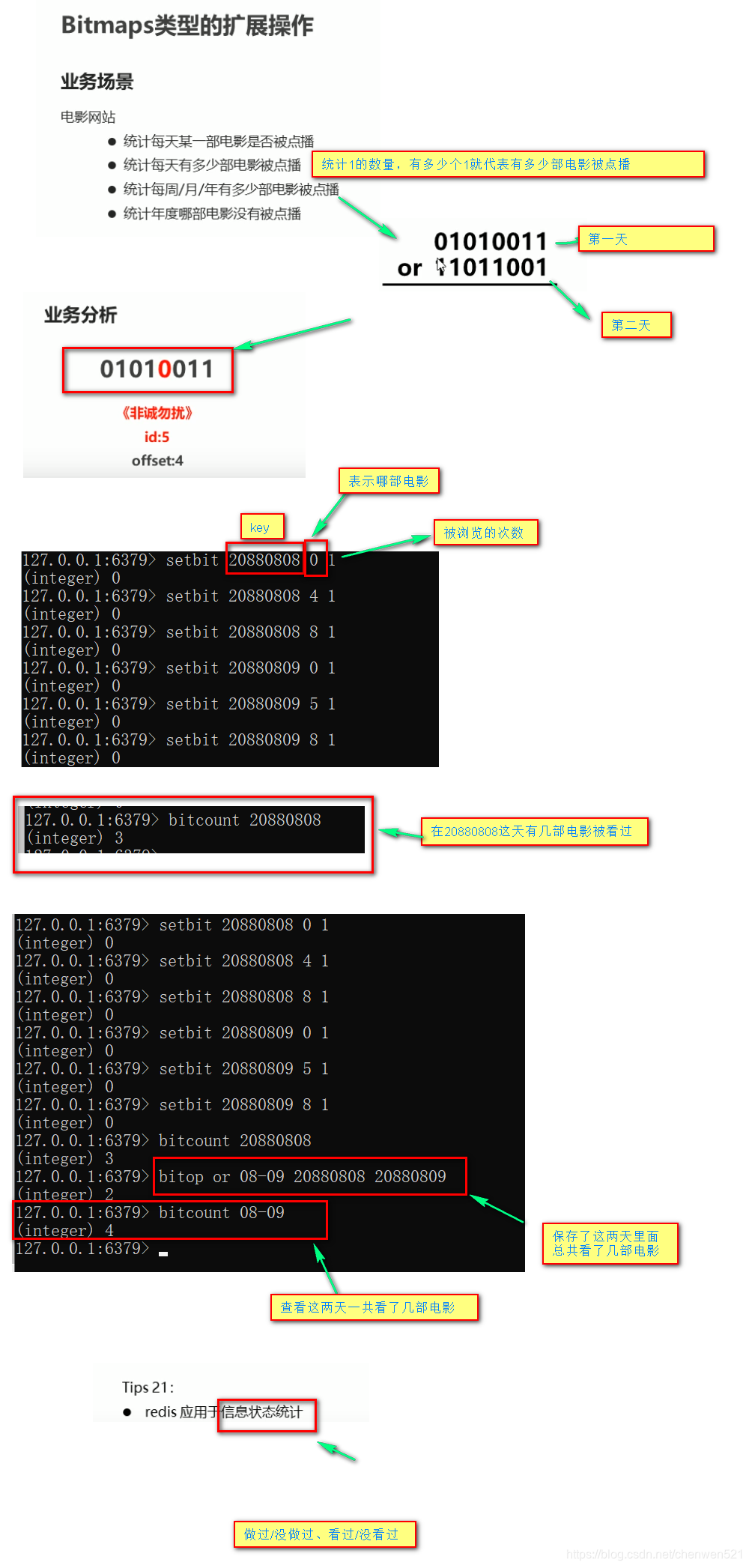
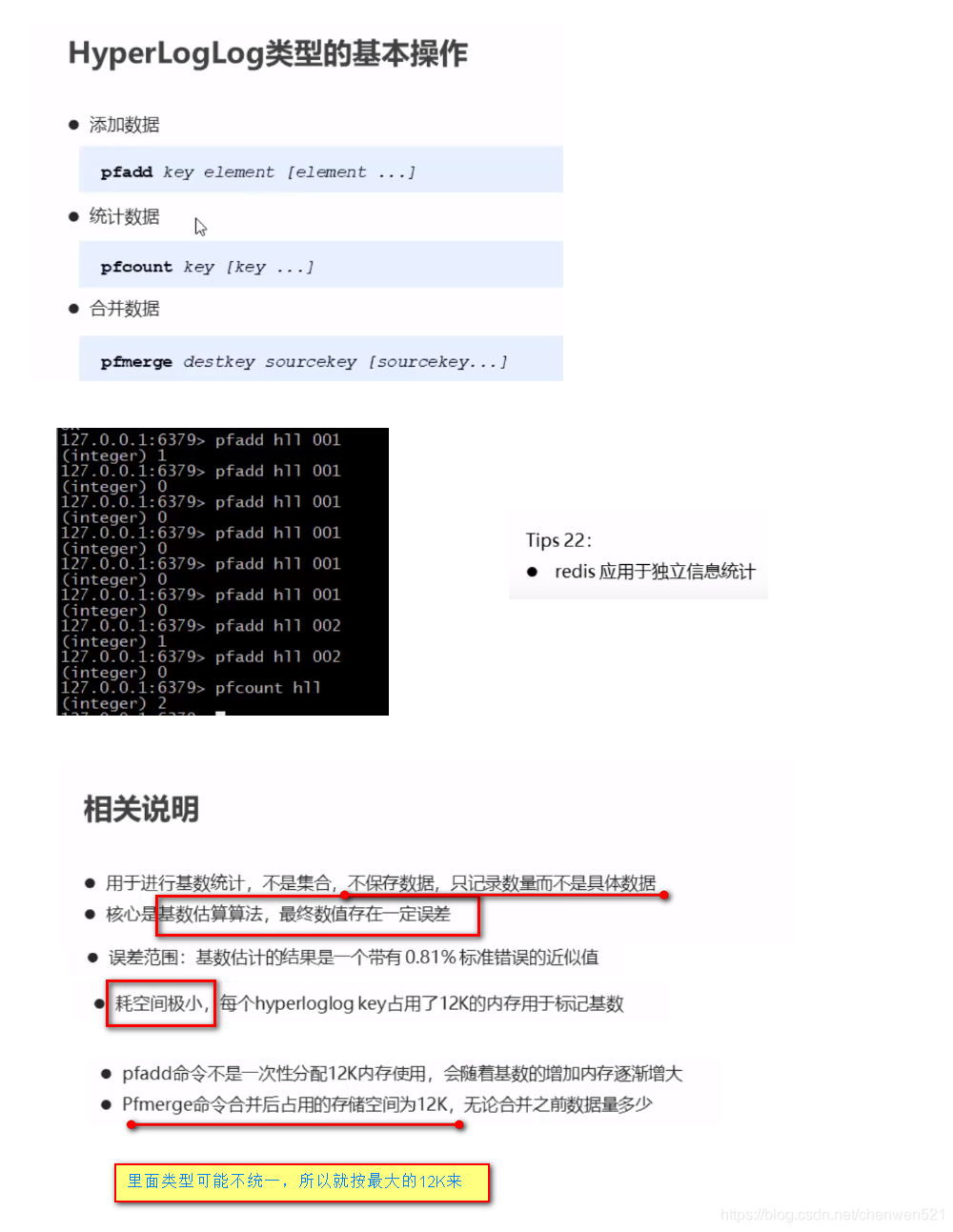
2.HyperLogLog
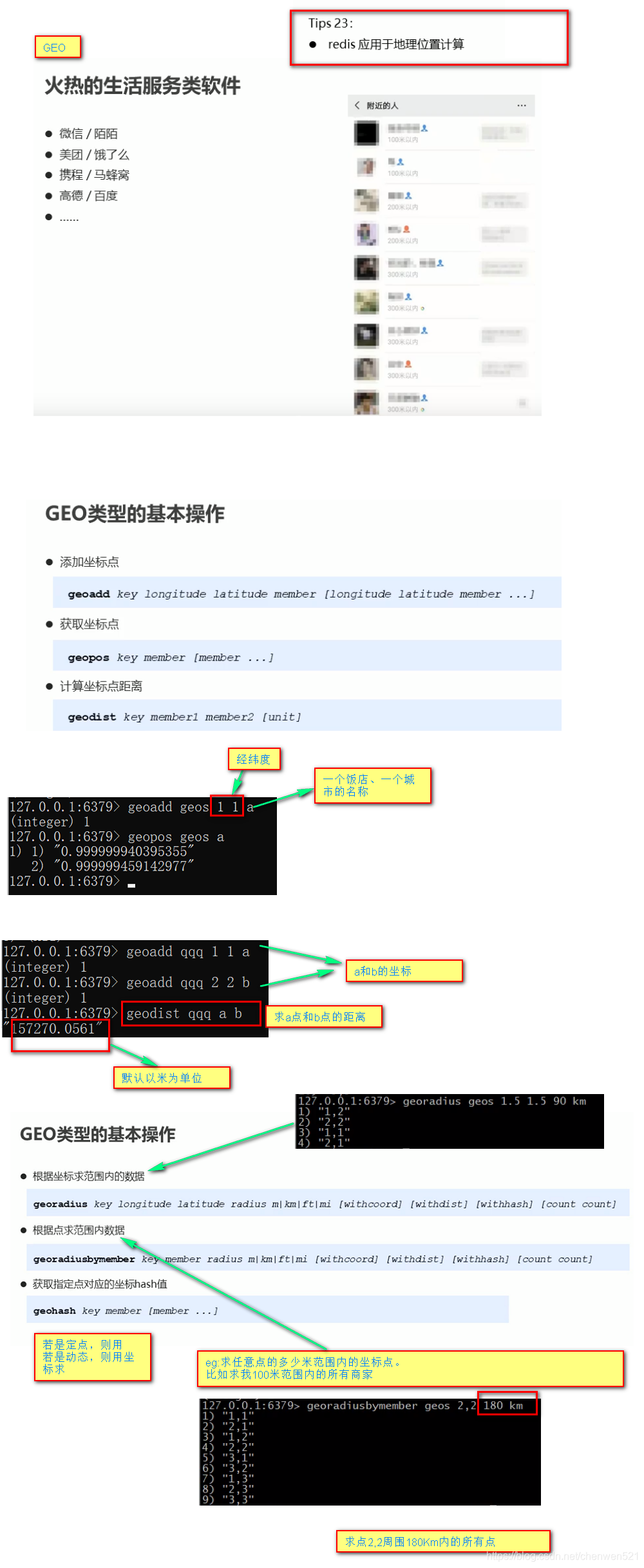
3.GEO:地理位置计算,比如美团、地图等
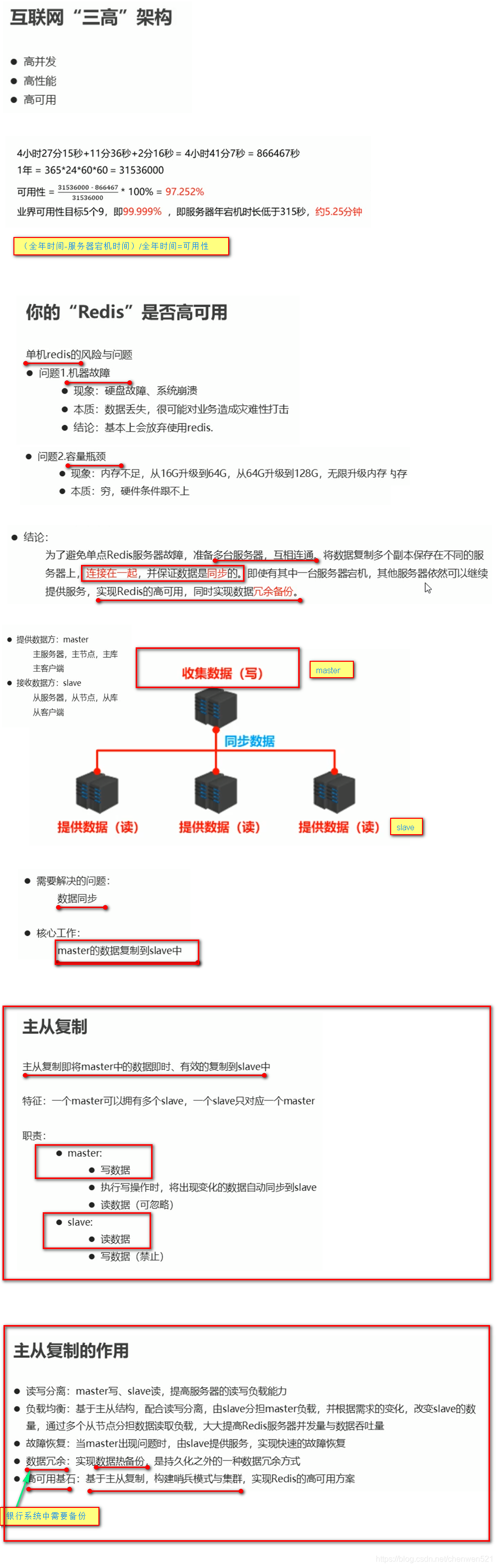
主从复制
简介
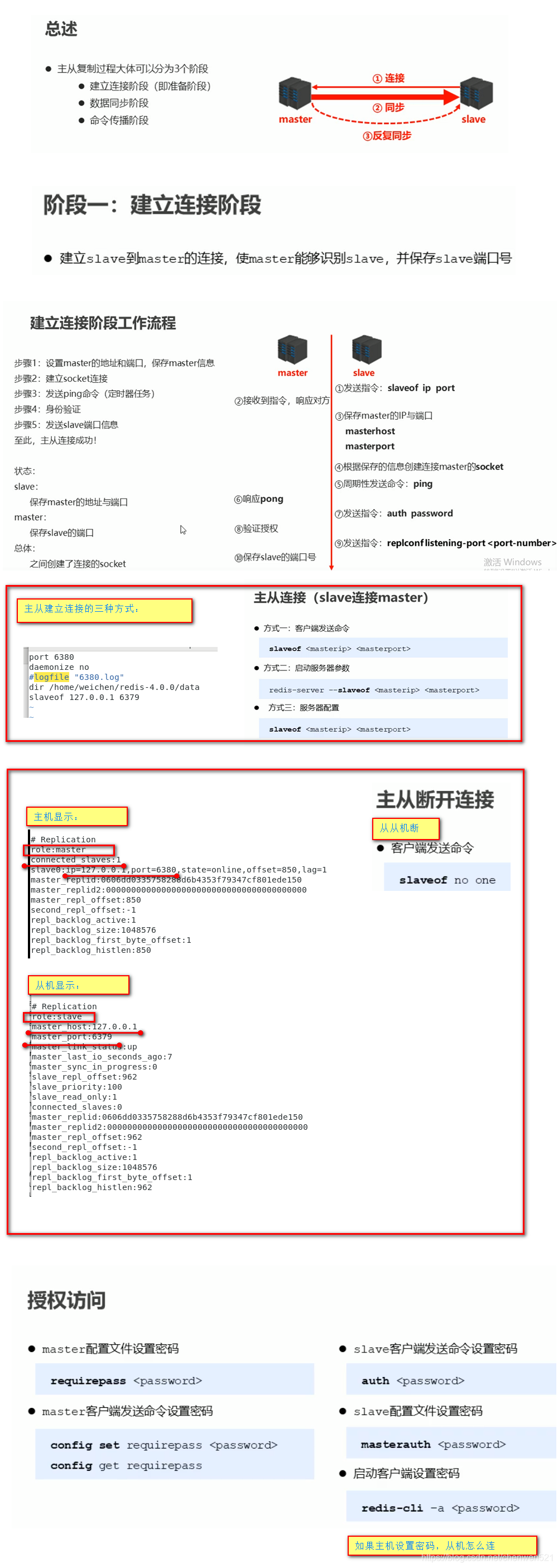
主从复制工作流程
1. 建立连接
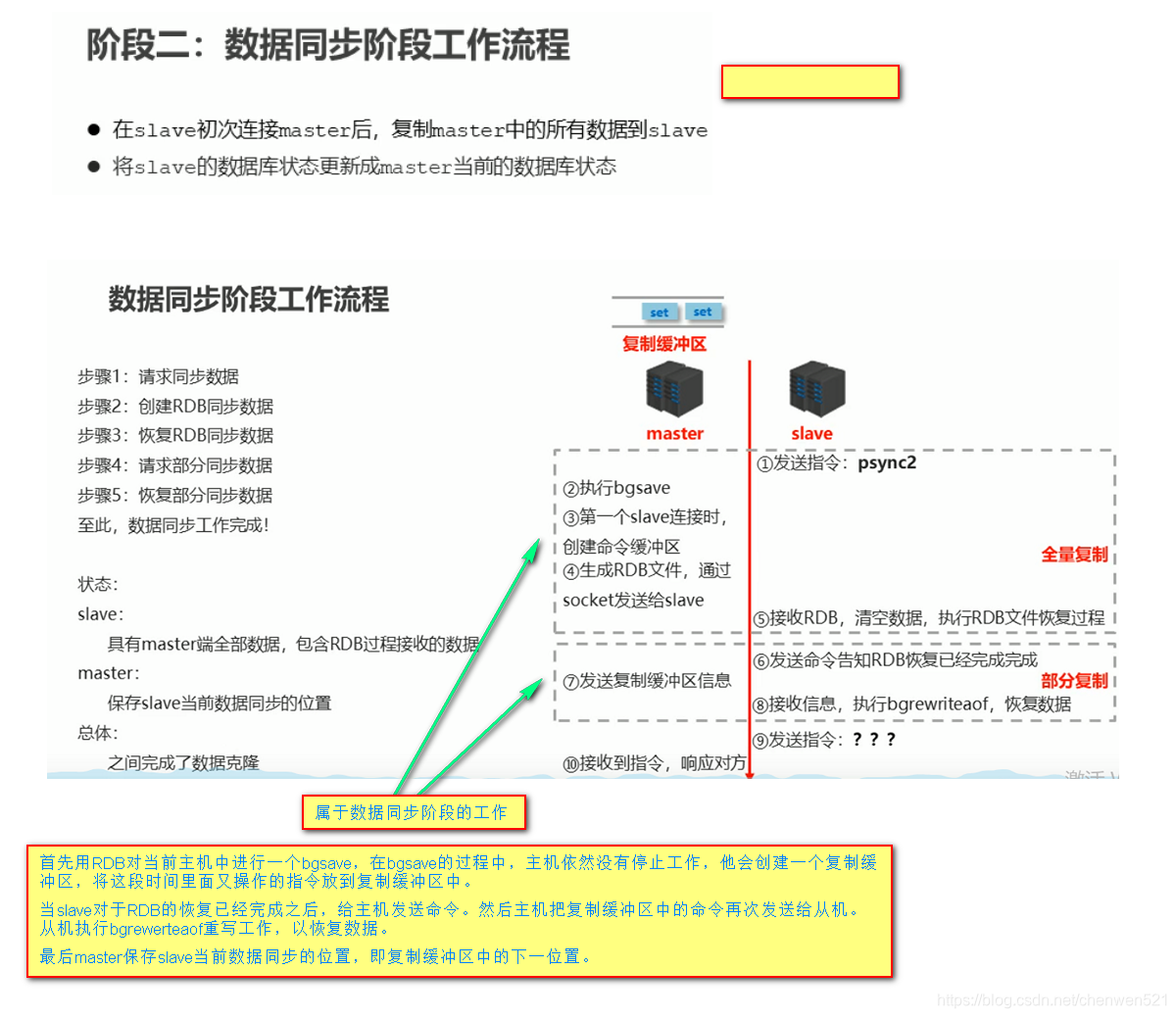
2. 数据同步

3. 命令传播过程
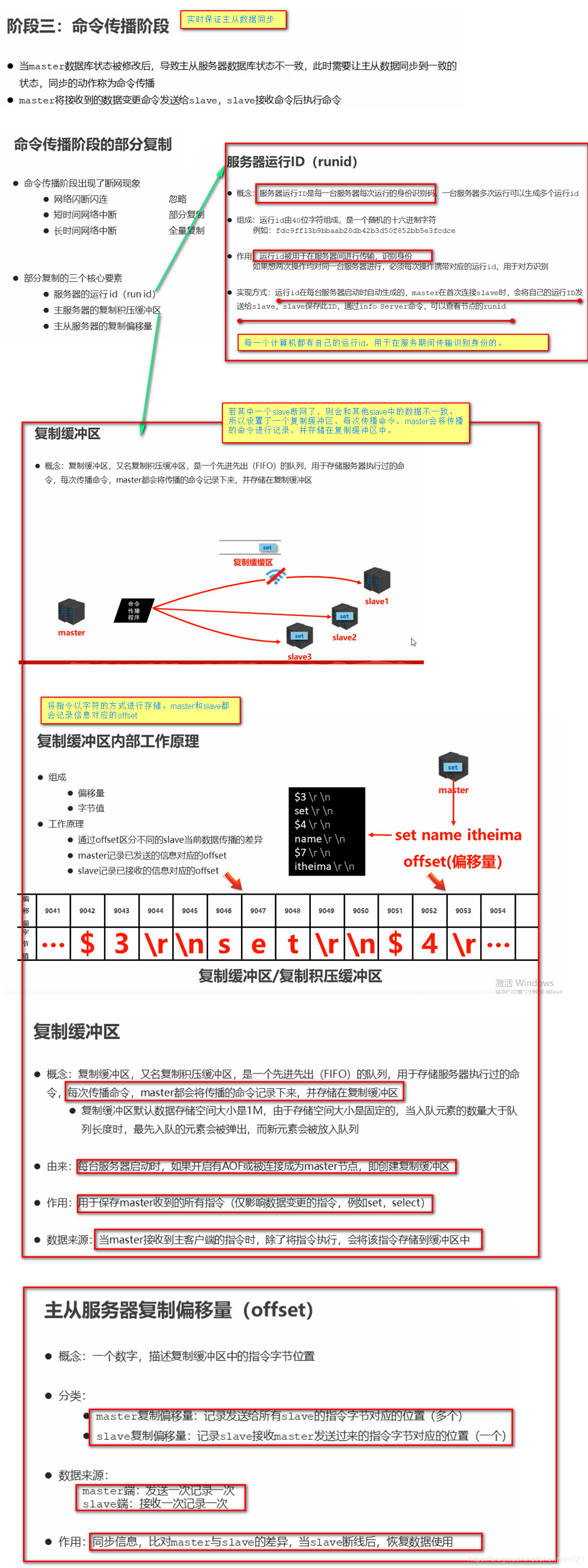
4. 数据同步+命令传播阶段工作流程

5. 常见问题

哨兵
1. 哨兵简介
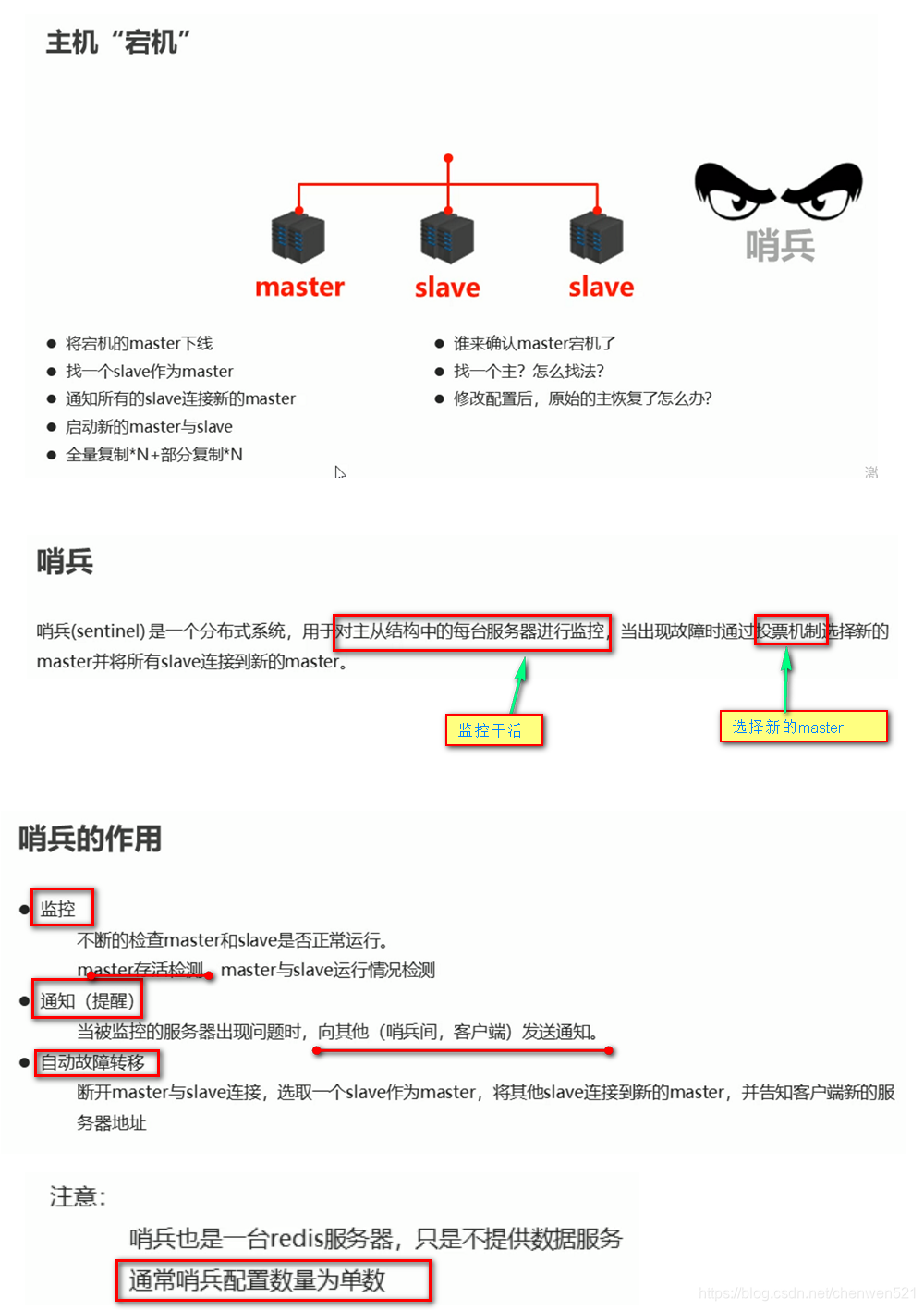
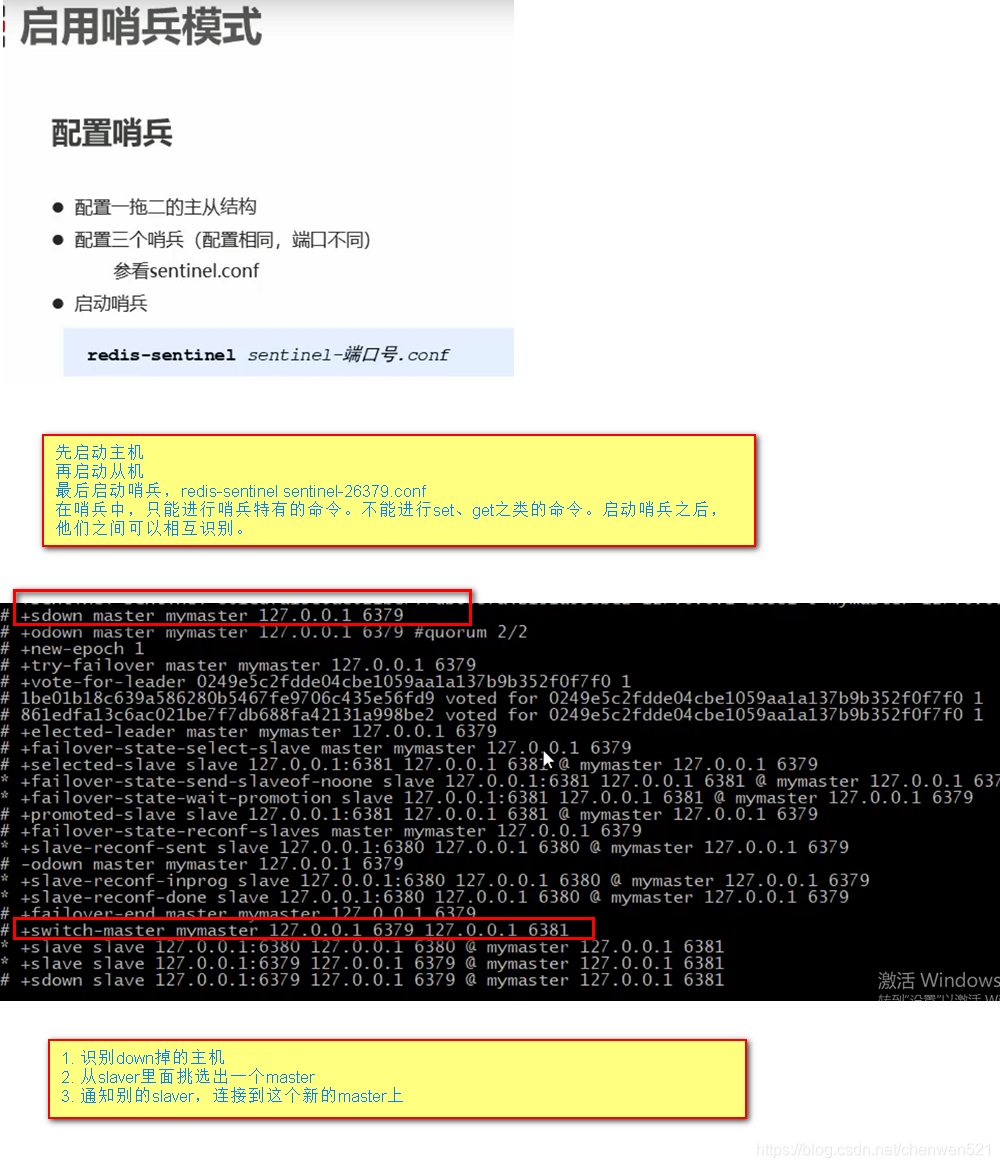
2. 哨兵的配置
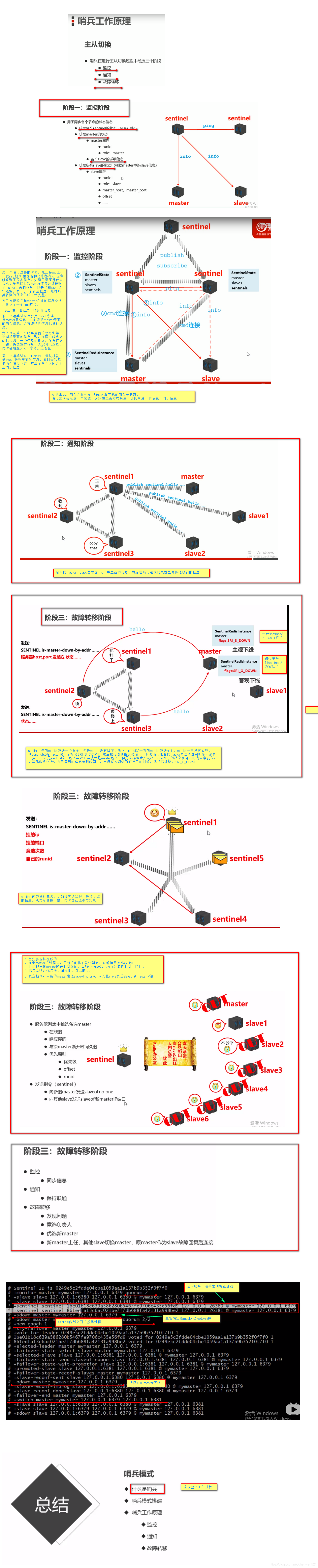
3. 哨兵工作原理
集群
1. 简介


















 173万+
173万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









