



 本文详细介绍了JPG文件的结构,包括SOI、APP0、DQT、SOF0、DHT等段的组成,以及JPEG压缩的四步骤。接着,探讨了JPG图像的常见隐写方法,如修改DQT、jphide、JSteg和OutGuess算法,并推荐了Steghide和Stegdetect隐写检测工具。
本文详细介绍了JPG文件的结构,包括SOI、APP0、DQT、SOF0、DHT等段的组成,以及JPEG压缩的四步骤。接着,探讨了JPG图像的常见隐写方法,如修改DQT、jphide、JSteg和OutGuess算法,并推荐了Steghide和Stegdetect隐写检测工具。
首先,先来介绍下JPG文件
JPG文件使用的是一种有损的压缩算法,通过去除冗余信息和不可见的细节来减少文件大小
JPG图片的组成:SQI(文件头)+APP0(图像识别信息)+DQT(定义量化表)+SOF0(图像基本信息)+DHT(定义HUFFMAN表)+DRI(定义重新开始间隔)+SOS扫描开始+EOI(文件尾)j
加粗部分是JPG图像构成所必须的部分
JPEG(Joint Photographic Experts Group)压缩方式主要分为以下四个步骤:
- 颜色空间转换:将RGB颜色空间转换为亮度-色度(YCbCr)颜色空间。
- 离散余弦变换(DCT):对每个8×8像素块中的Y、Cb和Cr分量进行DCT变换,将其转换为频域表示。
- 量化:对DCT系数进行进一步的量化。通过除以一个量化矩阵来降低更多的精度
- 编码:使用哈夫曼(HUFFMAN)编码对量化后的DCT系数进行编码,以减小存储空间。
JPG文件的格式分为一个个的段来存储,段的长度和多少是不一定的。只要包含了足够的信息,那么JPG文件就是可以被打开的;。JPG文件的每个段都一定包含两部分:第一个是段的标识,第二个是段的长度。
既然说了JPG每个段一定包含两部分,那么先来讲讲每个段的结构
段的结构:
|
名称 |
字节数 |
数据 |
说明 |
|
段标识 |
1 |
FF |
每个新段的开始标识 |
|
段类型 |
1 | 每个段都不同 |
类型编码 |
|
段长度 |
2 | 不固定 |
包括段内容和段长度本身,不包括段表示和段类型 |
|
段内容 |
≤65533字节 |
接下来我们使用010 Editor工具打开一个JPG图像来观察一下
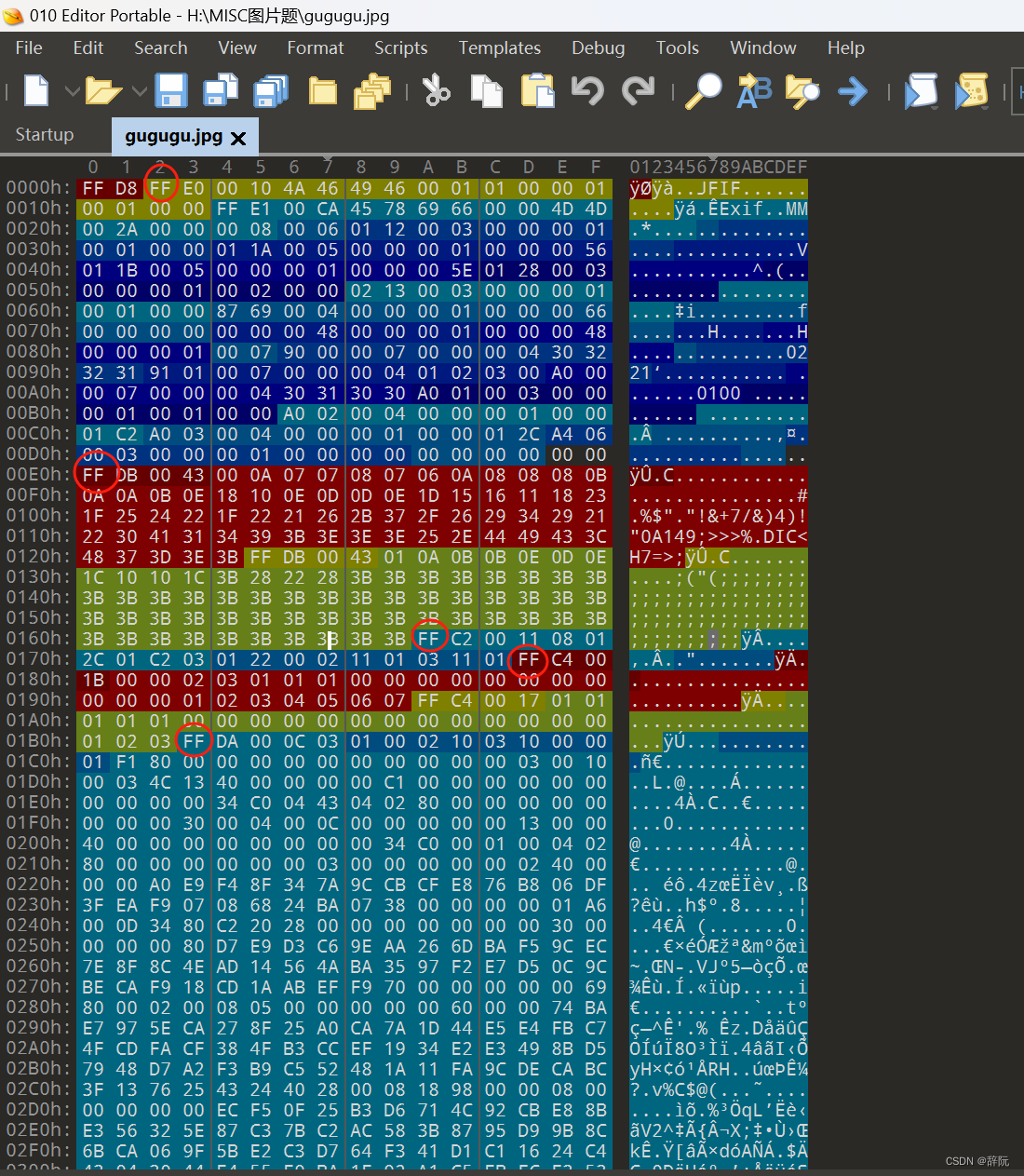
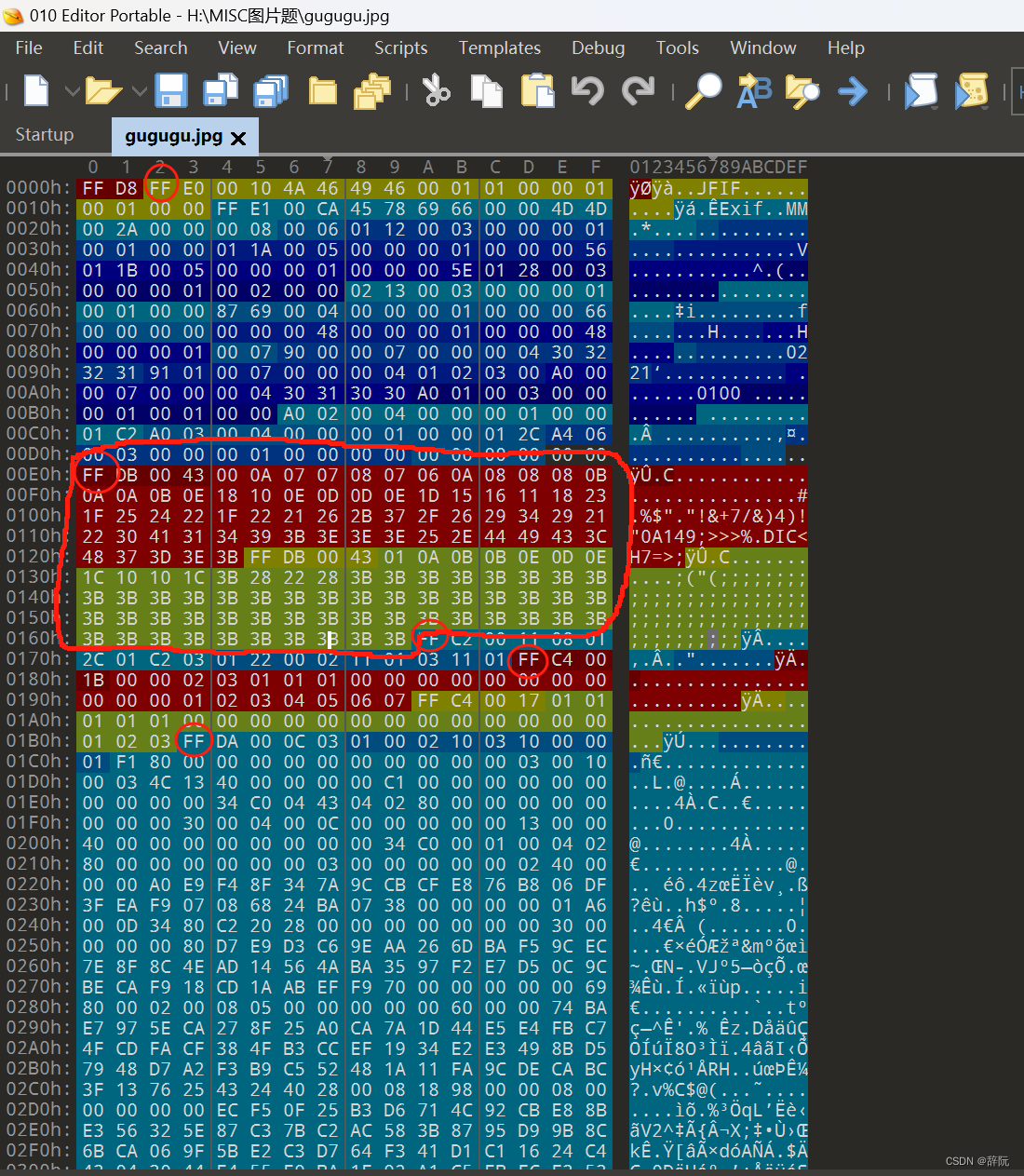
圈起来的就是就是我所说的每个段所一包含的两部分的第一个部分,也就是段的标识。我们使用010 Editor工具可以发现,许多部分被划为了不同的颜色,这就是不同的段,圈起来的FF,就是每个段的开头,段的标识。
段类型
|
名称 |
标记码 |
说明 |
|
SOI |
D8 |
文件头 |
|
EOI |
D9 |
文件尾 |
|
SOFO |
C0 |
帧开始 |
|
SOF1 |
C1 |
同上 |
|
DHT |
C4 |
定义HUFFMAN(哈夫曼)表 |
|
SOS |
DA |
扫描行开始 |
|
DQT |
DB |
定义量化表 |
|
DRI |
DD |
定义重新开始间隔 |
|
APP0 |
E0 |
定义交换格式和图象识别信息 |
|
COM |
FE |
注释 |
SOI文件头
JPG文件的开始两个字节都是FF D8这是固定的
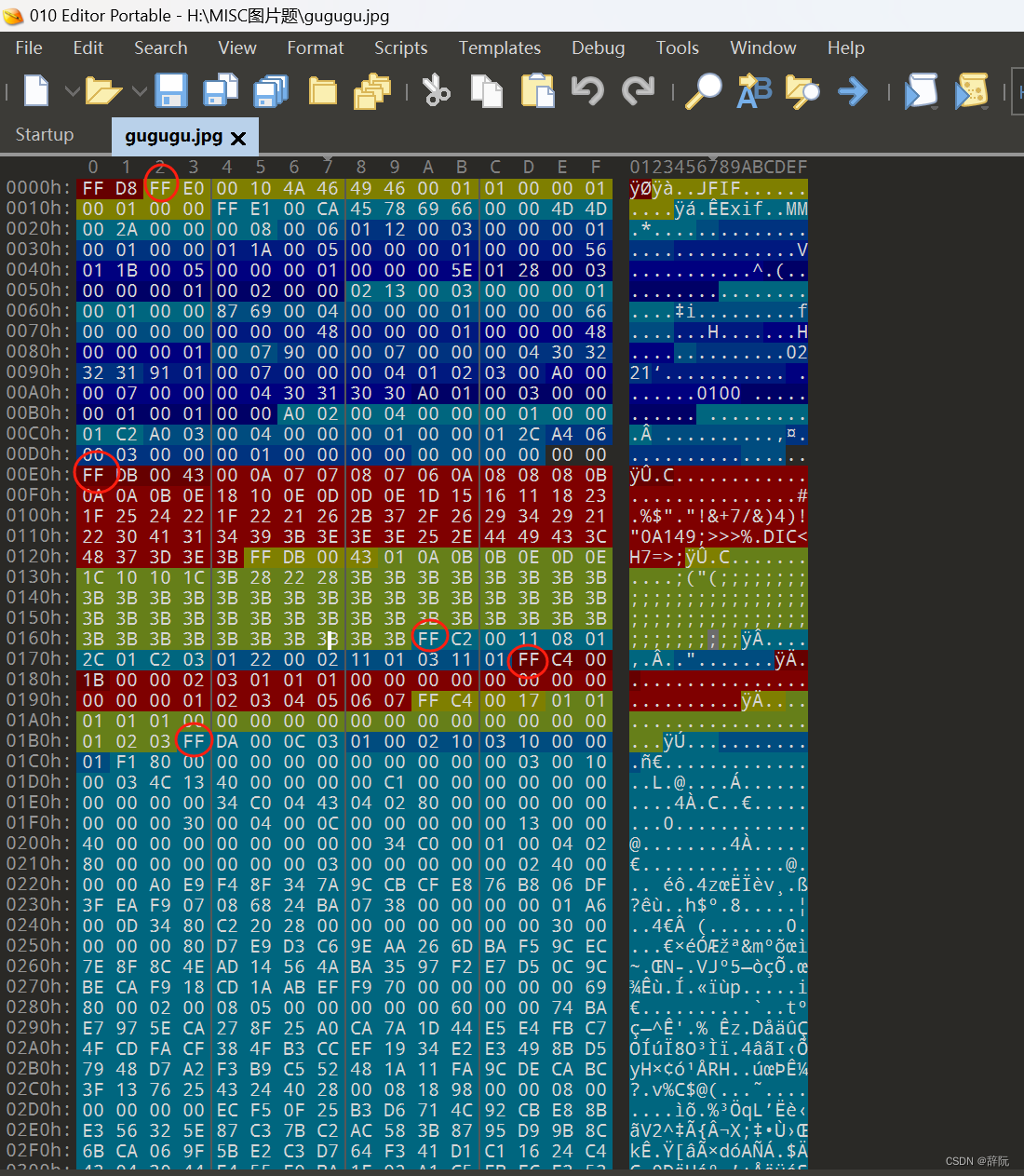
可以看到FF D8正是这个JPG文件的文件头
SOI后跟的就是APP0(图像识别信息了)
APP0格式
|
名称 |
字节数 |
值 |
说明 |
|
段标识 |
1 |
FF | |
|
段类型 |
1 |
E0 | |
|
段长度 |
2 |
0010=16 |
如果有RGB缩略图就=16+3n |
|
以下为段内容 | |||
|
交换格式 |
5 |
4A 46 49 46 00 |
"JFIF"的的ASCII码 |
|
主版本号 |
1 | ||
|
次版本号 |
1 | ||
|
密度单位 |
1 |
0=无单位;1=点数/英寸;2=点数/厘米 | |
|
X像素密度 |
2 |
水平方向的密度 | |
|
Y像素密度 |
2 |
垂直方向的密度 | |
|
缩略图X像素 |
1 |
缩略图水平像素数目 | |
|
缩略图Y像素 |
1 |
缩略图垂直像素数目 | |
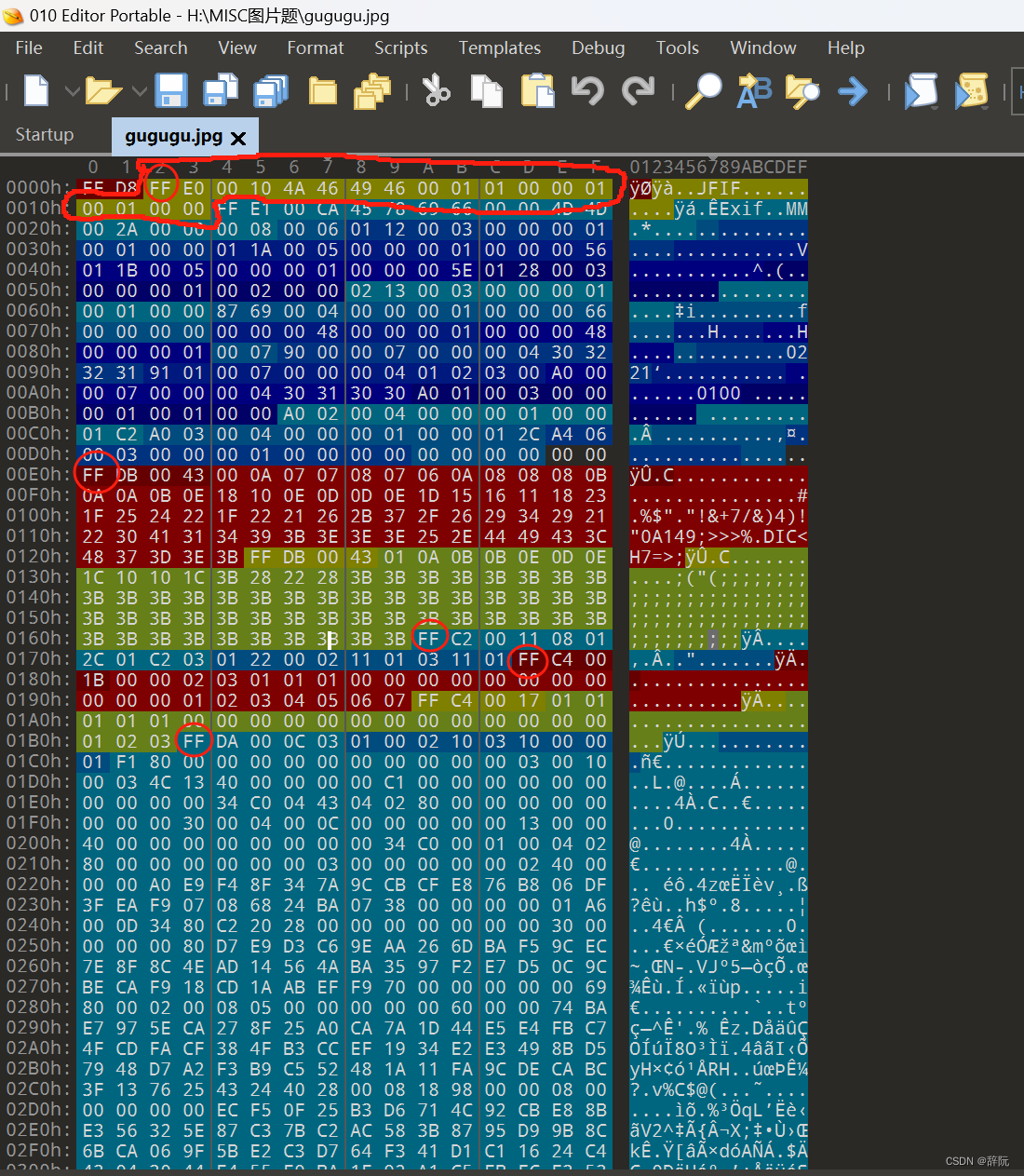
如上图,圈起来的就是APP0部分
DQT(定义量化表)
|
名称 |
字节数 |
值 |
说明 |
|
段标识 |
1 |
FF | |
|
段类型 |
1 |
D8 | |
|
段长度 |
2 |
00 43=67 |
其值=3+n(当只有一个QT时) |
|
以下为段内容 | |||
|
QT信息 |
1 |
0-3位:QT号;4-7位:QT精度(0=8bit,1字节;否则=16bit,2字节) | |
|
QT |
n |
n=64×QT精度的字节数 | |
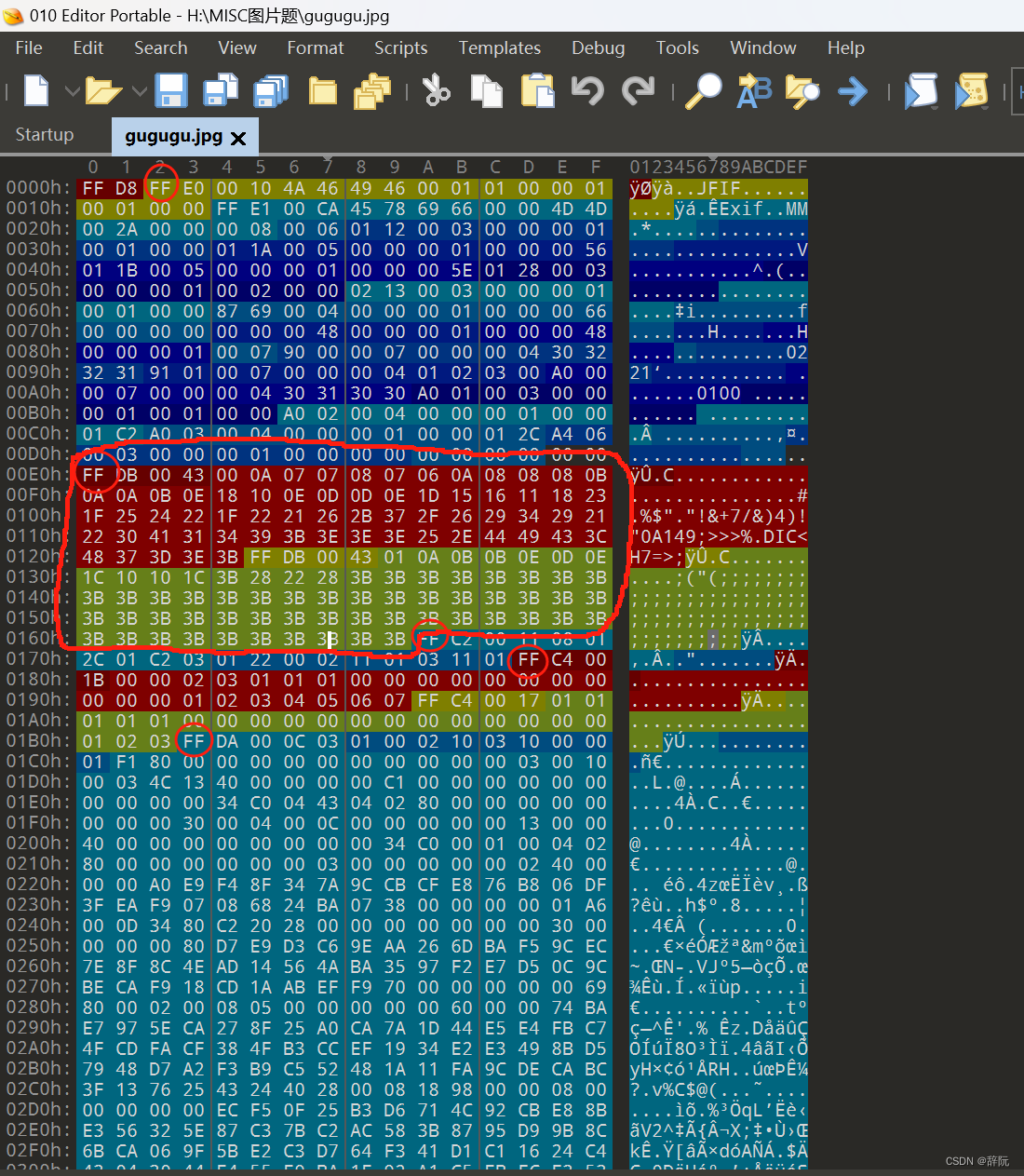
如上图,圈起来的就是DQT部分,全起来的可以看到是由两个部分的DQT
JPG文件里,一般是有两个DQT段的,分别为Y值(亮度),C值(色度)
SOF0(图像基本信息)
|
名称 |
字节数 |
值 |
说明 |
|
段标识 |
1 |
FF | |
|
段类型 |
1 |
C0 | |
|
段长度 |
2 |
其值=8+组件数量×3 | |
|
以下为段内容 | |||
|
样本精度 |
1 |
8 |
每个样本位数 |
|
图片高度 |
2 | ||
|
图片宽度 |
2 | ||
|
组件数量 |
1 |
3 |
1=灰度图,3=YCbCr/YIQ色彩图,4=CMYK彩色图 |
|
以下每个组件占3个字节 | |||
|
组件ID |
01=Y,02=Cb,03=Cr,04=I,05=Q | ||
|
采样系数 |
先把这一字节转换为二进制数,0-3字节表示垂直采样系数,4-7字节表示水平采样系数 | ||
|
量化表号 | |||

如上图,圈起来的就是SOF0,需要注意的是,如果FF后面跟的不是C0的话,比如C2及其他的字节,那么可能标表示图片采用了非标准的JPG格式或其他压缩算法
如果您遇到了SOF0第二字节处非C0的情况,那么可能有以下几种情况:
- 图片使用了非标准的 JPEG 格式或者其他压缩算法。
- 图片受损或者格式错误,导致解析时出现了错误的标记。
- 该标记并不是 JPEG 格式中的有效标记,而是其他格式的标记或者数据中的随机值。
00 11:是组件数量,算法公式是=8+组件数量×3,00 11转换为十进制数为17,17=8+3×3,所以组件数量有3个
组件数量有三个,所以组件ID,采样系数,和量化表号都会有,分别是01 22 00,02 11 01,03 11 01
01 22 00:第一个字节是01,所以对应的是Y组件,22转换为二进制数是0010010,0-3位值是2,4-7位值也是2,所以垂直采样系数和水平采样系数都是2,第三个字节是0,所以量化表号是0。
02 11 01:第一个字节是02,所以对应的是Cb组件,11转换为二进制数是00010001,0-3位值是1,4-7位值也是1,所以垂直采样系数和水平采样系数都是1。第三个字节是1,所以量化表号是1。
03 11 01:第一个字节是03,所以对应的是Cr组件,11转换为二进制数是00010001,0-3位值是1,4-7位值也是1,所以垂直采样系数和水平采样系数都是1。第三个字节是01,所以量化表号是1。
DHT定义HUFFMAN表
|
名称 |
字节数 |
值 |
说明 |
|
段标识 |
1 |
FF | |
|
段类型 |
1 |
C4 | |
|
段长度 |
2 |
其值=19+n(当只有一个HT表时) | |
|
以下为段内容 | |||
|
HT信息 |
1 |
这一字节需要转换为二进制数,然后观察第四位,第4位如果是0那么就是DC表,是1就是AC表,5-7位:必须0 | |
|
HT位表 |
16 |
这16个数之和应该≤256 | |
|
HT值表 |
n |
n=表头16个数之和 | |
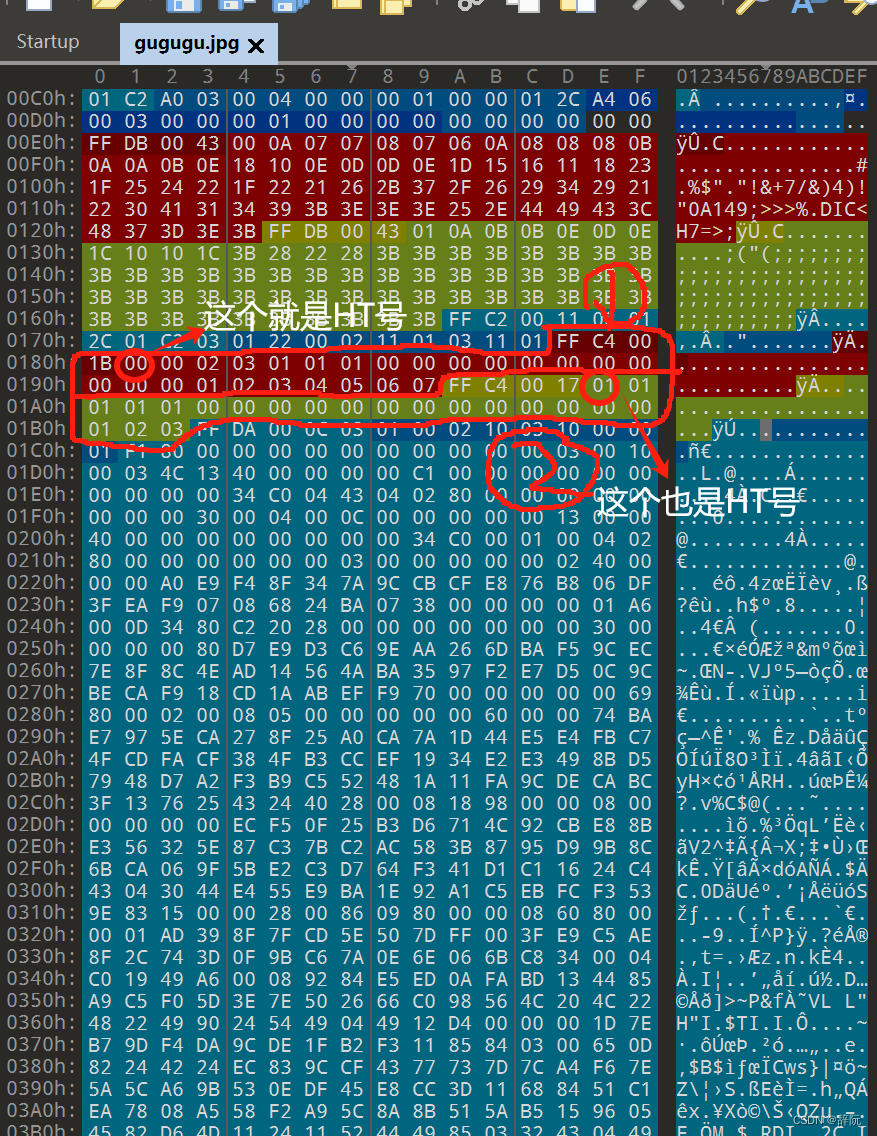
如上图所示,一共有2个HUFFMAN表
(1)FF C4:定义了HUFFMAN表头两个字节
(2)段长度为2个字节:①是00 1B=27(不包含表头也就是FF C4),27=(段长度2个字节+HT信息1个字节+HT位表16字节)+8(这个数代表HT表有8个字节)
(3)HT信息1字节:如上图,HT信息是00,00这个十六进制数转换为二进制数就是00000000,第四位是0,所以①是DC表
举例:如果这一字节数是10,那么转换为二进制数就是00010000,第四位数是1,那么就是AC表
(4)HT位表16个字节,这16个字节和要小于等于256
以①为例,00 02 03 01 01 01 00 00 00 00 00 00 00 00 00 00这是HT位表的16个字节,加起来值为8,说明HT值表有8个字节
(5)HT值表有8个字节,也就是00 01 02 03 04 05 06 07这8个字节
SOS扫描开始
|
名称 |
字节数 |
值 |
说明 |
|
段标识 |
1 |
FF | |
|
段类型 |
1 |
DA | |
|
段长度 |
2 |
000C |
其值=6+2x扫描行内组件数量 |
|
以下为段内容 | |||
|
扫描行内组件数量 |
1 |
3 |
必须≥1,≤4(否则错误),通常为3 |
|
以下每个组件占2字节 | |||
|
组件ID |
1 |
1=Y,2=Cb,3=Cr,4=I,5=Q | |
|
HUFFMAN表号 |
1 |
0-3位:AC表号,4-7DC表号 | |
|
剩余三个字节 |
3 |
用途不明,忽略 | |
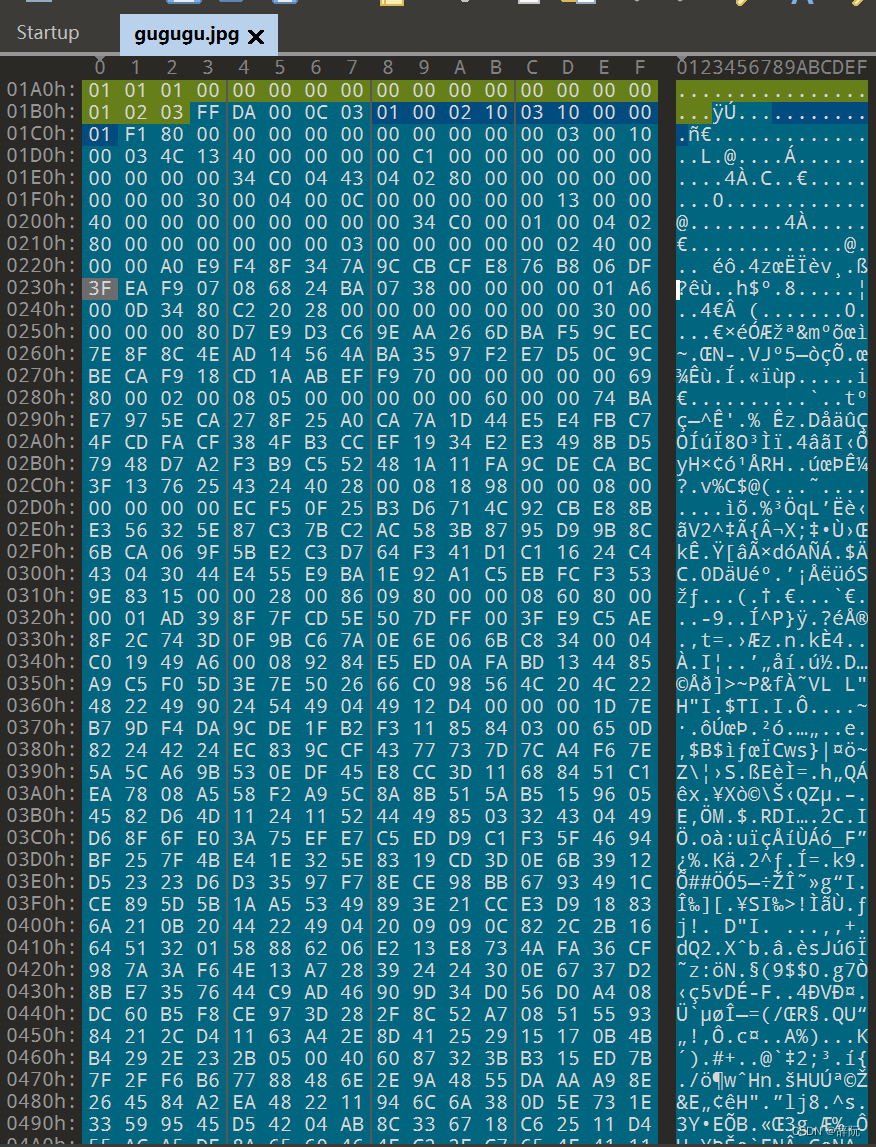
(1)扫描行开头:2字节,FF DA
(2)段长度:2字节,这里是00 0C=12
(3)扫描行内组件数量:1字节,这里是03,代表组件数量为3
(4)每个组占用2字节:第一个字节是组件ID(1 = Y, 2 = Cb, 3 = Cr, 4 = I, 5 = Q),组件ID和HUFFMAN表号为一组,占2字节,第二个字节的0-3位是AC表号,4-7位是DC表号。表号的值是0-3
01 00:Y组件,AC表号是0,DC表号是0
02 10:Cb组件,AC表号是1,DC表号是0
03 10:Cr组件,AC表号是1,DC表号是0
EOI文件尾
|
名称 |
字节数 |
值 |
|
段标识 |
1 |
FF |
|
段类型 |
1 |
D9 |
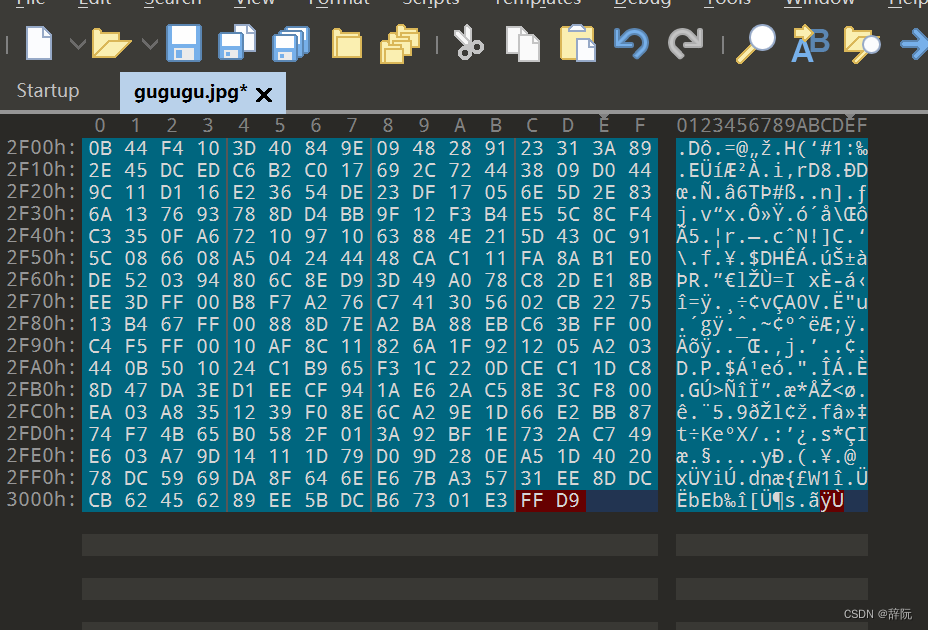
这两个字节构成了JPG文件的尾部,FF D9后面是不会再有信息的,如果有,就可以判断应该是有插入的隐写信息的
讲完了结构,我们来讲讲JPG图像常见的隐写方法
修改DQT隐写
我们可以修改DQT里的内容,来做到隐藏内容
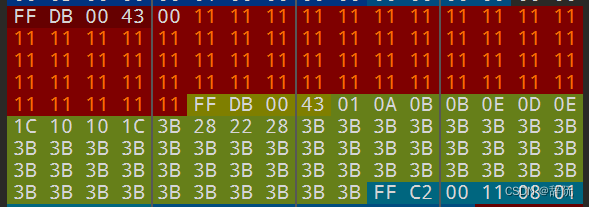
如上图,我们把不影响DQT的开头和段长度修改后,将其他每个字节都替换为了11,我们保存可以查看下原图和修改后的图片的区别
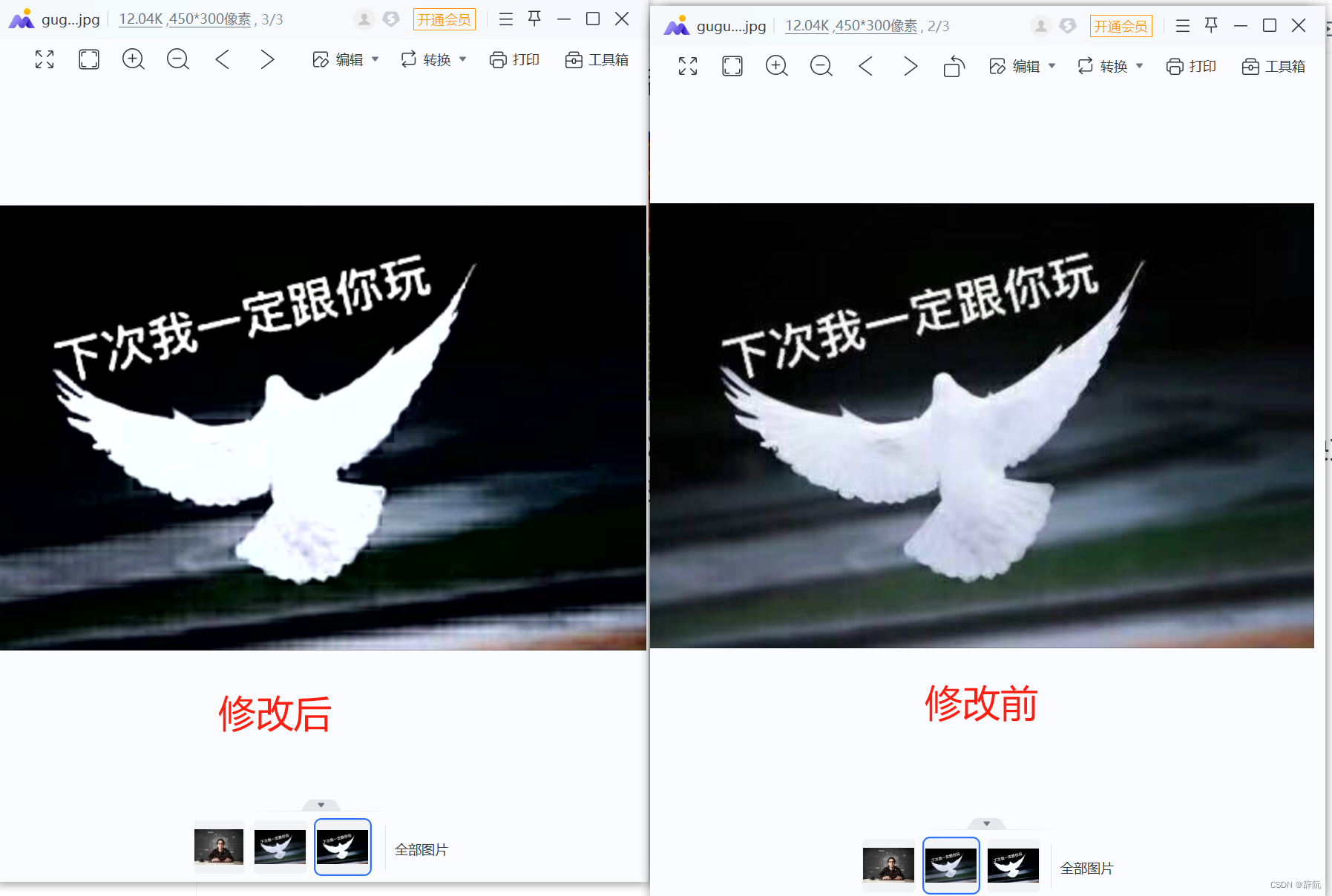
如上图,可以发现,修改后会比原图更明亮
jphide隐写算法
算法原理:使用blowfish算办法加密信息,利用控制表确定信息的隐藏位置及嵌入秘密的方式,同时结合blowfish生成的随机序列控制具体位置的嵌入。
隐写过程大致为:1.解压jpg图像,得到DCT系数。2.根据用户给定的密码对隐藏信息进行blowfish加密。3.利用blowfish算法生成伪随机序列,并根据此招到需要改变的DCT系数,将其末位改变为需要隐藏的信息的值。4.最后,把DCT系数重新压缩为JPG图片
JSteg隐写算法
算法原理:使用JPG图像量化后的离散余弦变换(DCT)系数的最低比特来承载秘密信息
隐写过程:1.需要确定的就是当前位置的DCT系数不能为0或1,不满足该条件则跳过,若满足条件则进行下一步。2.判断该位置的DCT系数的最低比特是否与秘密信息的比特数值相同,相同的话就结束本次操作,不相同就使用秘密信息比特替换
OutGuess隐写算法
OUustGuess的信息嵌入过程和JSteg完全一样,纠正阶段会修改DCT系数以消除在嵌入过程中造成的统计特征的变化。
OutGuess 0.2中加入了用户密钥设置,在整幅图像中根据密钥的不同按照一定的原则挑选DCT系数进行修改,是的嵌入信息随机化,难以被检测出来。
这里推荐两个工具,用来检测JPG图像是否存在隐写
一个是Steghide隐写工具,一个是Stegdetect
Steghide隐写工具:链接:https://pan.baidu.com/s/1PEw2y8j7gAAvqvFY7WHtGA
提取码:a2le
Stegdetect隐写工具:链接:https://pan.baidu.com/s/1ddHbWew2oh2yuLV7T7uXoA
提取码:c1r6
这边就不再讲解如何使用了,有兴趣的可以自己上别的博主那里查看一下


















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









