






 本文提出了一种基于多角度卷积和多种pooling类型的模型,用于计算句子相似度。模型通过两个并行的神经网络处理输入句子,使用不同类型的卷积核和pooling方法提取句子特征,再通过结构化的相似性测量层计算最终的相似度得分。
本文提出了一种基于多角度卷积和多种pooling类型的模型,用于计算句子相似度。模型通过两个并行的神经网络处理输入句子,使用不同类型的卷积核和pooling方法提取句子特征,再通过结构化的相似性测量层计算最终的相似度得分。
模型关于语句的相似度,由于变异以及长短不同表达,设计了一个这些中间,探究了输入的多个角度运用多个卷积类型以及多种类型的pooling,类似于运用了多个相似度函数。模型包括两个组成部分如图:

如图1,两个输入的句子由两个并行的神经网络处理,输出句子representation,两个句子表示由一个结构化的相似性测量层,然后相似性的特征通过一个全连接来最终计算相似度。
1、第一部分,为了句子相似性计算,把句子转化为为representation,运用不同的卷积类型以及pooling来获取输入的多个角度的不同的信息。
第二部分:一种语句相似性测量方式,运用多个相似测量方法,比较来自于句子模型中的局部表示
我们的模型有一个连体结构,分别有两个子网络,每一个处理一个句子,分别;子网络共享所有的权重,并且用一个相似测量层连接,然后用一个full获取最后的相似分数。
更重要的是我们并不需要额外的资源,例如wordnet或者语法解析对于文章感兴趣的;我们仅仅选择性的用词性标签和预训练好的词向量,最主要的不同时我们运用了不同类型的卷积核和在局部区域运用结构相似的测量方式。后来的实验会展示我们的大部分成功来自于输入句子的多角度提取特征,运用不同的卷积类型。
在第四章介绍句子模型,第五章介绍是我们的相似测量层
4、句子模型
这一章,我们的模型卷积模型对于每一个句子,用了两种不同的卷积类型核,将会在4.1进行描述,也会运用多种类型的pooling类型。
我们的输入是一个单词流,把句子可以理解为时间序列,邻近的单词具有关联性,那么sent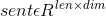
第i个单词的embedding,而
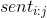
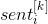
第i单词vector的第k维度,用 
4.1 在多个角度的卷积操作
我们定义一个元组<ws,wf,bf,hf>,ws是一个滑动窗口宽度,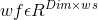
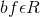
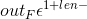
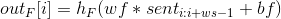
其中i属于[1,1+len-ws],这个核可以认为是时间序列卷积,它匹配的是局部区域的,由于这些filter考虑了每一个单词在整体的位置关系,我们称他们为整体滤波器,例如图2的左边图示:

其实质就是把一个词语向量为单位,然后获取短语的特征;
额外,通过构造每一个维度的卷积核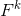
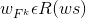
的维度,对于单词的embedding每一个维度分别有维度filter,
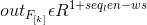
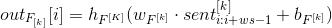
以上的方法能够提取句子更多丰富的信息,但是对于神经元的每一个维度分别代表什么具体含义,通常是没办法用具体含义来解释的,但是仍然可以从不同embedding 的维度来获取不同的信息,这是我们所关心的,在训练阶段词向量被更新,来鼓动模型获取不同的信息。
我们定义了一个卷积layer作为卷积filter的集合,而一个集合共享一种卷积类型(水平或者垂直),激活函数以及窗口ws,
4.2 多种pooling类型
卷积filter的输出outF向量通常再用一个pooling方法转化为标量,max_pooling 返回句子信息最大特征,在这篇文章中有应用了最小pooling以及均值pooling,个人认为只属于拼凑。
一组操作表示为(ws,pooling,sent)作为一个对象,包含了卷积层、pooling层和操作的句子,把这个组定义为block,那么基友两种类型block,
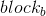

如图3 每一个block包含独立的pooling layer and 卷积,左侧的是应用整个词向量,右侧是应用于单独维度的卷积来获取更详细的信息,blockB,
我们定义blockA作为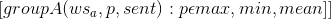
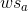
pooling,我们不是对于不同的pooling类型应用不同的filters 集合,我们用所有整体卷积层的A类块
定义 bolckB定义如下:
{gruopB(wsb,p,sent):p属于{max,min}}
因此blockB包含两组卷积layer ,窗口为wsb,一个是max-pooling,另外一个min-pooling,每一个groupB包含一个每一个embedding维度的卷积核,用B类型。
运用多个类型的pooling来提取不同类型的信息对于每一个filter类型,

















 5887
5887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









