







目录
摘要
-
原文
We report on a series of experiments with convolutional neural networks (CNN) trained on top of pre-trained word vectors for sentence-level classification tasks. We show that a simple CNN with little hyperparameter tuning and static vectors achieves excellent results on multiple benchmarks. Learning task-specific vectors through fine-tuning offers further gains in performance. We additionally propose a simple modification to the architecture to allow for the use of both task-specific and static vectors. The CNN models discussed herein improve upon the state of the art on 4 out of 7 tasks, which include sentiment analysis and question classification.
-
翻译
我们报告了一系列在预训练词向量之上训练的卷积神经网络(CNN)实验,用于句子级分类任务。我们表明,几乎没有超参数调整和静态向量的简单CNN在多个基准上均能获得出色的结果。
通过微调学习特定任务的向量可进一步提高性能,另外建议对体系结构进行简单的修改,以允许使用特定任务的向量和静态向量,本文讨论的CNN模型在7个任务中的4个改进了现有技术,其中包括情感分析和问题分类。
-
单词解释
a series of 一系列、pre-trained word vectors预训练词向量、
sentence-level classification tasks.句子级分类任务、
hyperparameter tuning 超参数调整
static vectors静态向量。multiple benchmarks多个基准。fine-tuning 微调
the architecture体系、sentiment analysis 情感分析 question classification.问题分类
-
技术解读
超参数:超参数是在建立模型时用来控制算法行为的参数。这些参数不能从正常的训练过程中学习。他们需要在训练模型之前被分配。
超参数调整的方法:网格搜索、随机搜索、贝叶斯调参、手动调参。
预训练词向量方式: Word2Vec、 GLOVE、FastText、n-gram。
sequence-level task(句子级别任务):
如情感分类等各种句子分类问题; 推断两个句子的是否是同义等.(判断两个句子是相近、矛盾、中立)
即给出一对(a pair of)句子, 判断两个句子是entailment(相近), contradiction(矛盾)还是neutral(中立)的. 由于也是分类问题, 也被称为sentence pair classification tasks.
会自己找对应任务的相关经典数据集。
静态向量的简单CNN
将一个词在整个语料库中的共现上下文信息聚合至该词的向量表示中,也就是说,对于任意一个词,其向量表示是恒定的,不随其上下文的变化而变化。(缺陷无法表达多意性)
基准模型:
baseline一词应该指的是对照组,基准线,就是你这个实验有提升,那么你的提升是对比于什么的提升,被对比的就是baseline。
引言
-
原文
Deep learning models have achieved remarkable results in computer vision (Krizhevsky et al., 2012) and speech recognition (Graves et al., 2013) in recent years. Within natural language processing, much of the work with deep learning methods has involved learning word vector representations through neural language models (Bengio et al., 2003; Yih et al., 2011; Mikolov et al., 2013) and performing composition over the learned word vectors for classification (Collobert et al., 2011). Word vectors, wherein words are projected from a sparse, 1-of-V encoding (here V is the vocabulary size) onto a lower dimensional vector space via a hidden layer, are essentially feature extractors that encode semantic features of words in their dimensions. In such dense representations, semantically close words are likewise close—in euclidean or cosine distance—in the lower dimensional vector space.
-
翻译
近年来,深度学习模型在计算机视觉(Krizhevsky et al., 2012)和语音识别(Graves et al., 2013)中取得了显著的效果,在自然语言处理中,深度学习方法的许多工作都涉及通过神经语言模型(Bengio et al., 2003; Yih et al., 2011; Mikolov et al., 2013)来学习词向量表示。
并在学习的词向量进行分类(Collobert et al., 2011)。词向量本质是特征提取,其将词从稀疏的V编码1(这里V是词汇量)通过隐藏层投影到较低维度的向量空间上,该特征提取对词在其维度上的语义特征进行编码,在这种密集表示中,语义上相近的词在较低维向量空间中也很相近,(如欧几里得或余弦距离)。
-
单词解释
Deep learning models 深度学习模型、remarkable result显著的效果、
computer vision 计算机视觉、speech recognition 语音识别、
Within natural language processing 在自然语言处理中。
much of the work 许多工作、word vector representations词向量表示。
neural language models 神经语言模型、
the learned word vectors for classification 在学习的词向量上进行分类。
a sparse, 1-of-V encoding 稀疏的V编码1
a lower dimensional vector space 较低维度的空间向量。
via a hidden layer 通过隐藏层。 essentially feature extractors 本质是特征提取。
semantic features of words 词的语义特征。
dense representations 密集表示、semantically close words 语义上相近的词。
euclidean or cosine distance 欧几里德距离和余弦相似度距离。
-
技术解读
特征提取:词袋模型、TF-IDF文本、特征提取 、word2vector、GloVe、等
稀疏的词向量编码:
稀疏矩阵的存储
首先何谓稀疏矩阵,就是在矩阵中有众多的零元素。稀疏矩阵可以用稀疏度来进行定量判定。稀疏度的计算公式如下:

稀疏矩阵存储应该满足以下条件:
- 不存储 0 元素
- 能够快速恢复到矩阵形态
- 存储非零元素的数值和位置。
共有三种存储方式:散居存储、按列/行存储、三角存储
词的语义特征
语义信息:常说的上下文信息,也就是指一个单词与其周围单词之间的关联。
语义相似度
- 欧几里得距离
衡量多维空间中各个点之间得绝对距离,当数据很稠密并且连续时,这是一种很好得计算方法。
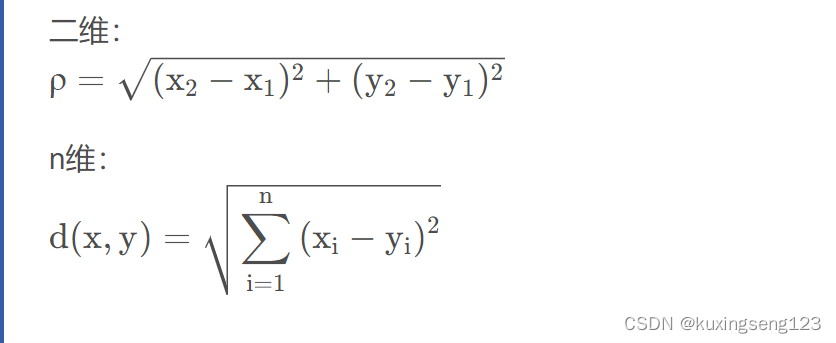
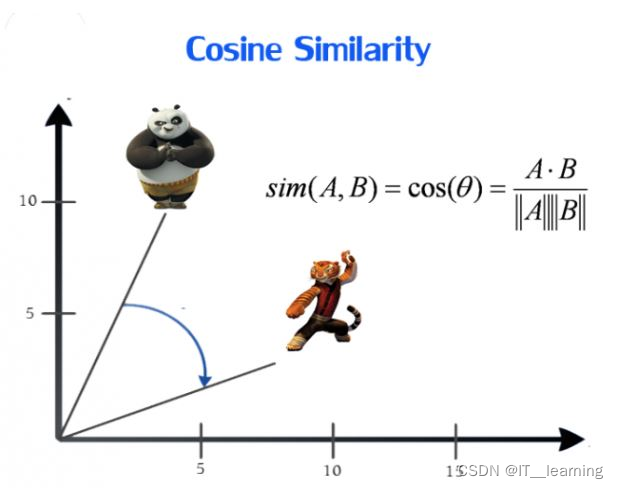
- 余弦相似度 Cosine Similarity
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
- 曼哈顿距离 Manhattan Distance
- 明可夫斯基距离(Minkowski distance)
- Jaccard 相似系数(Jaccard Coefficient)
- 斯皮尔曼(等级)相关系数(SRC :Spearman Rank Correlation)
原文
Convolutional neural networks (CNN) utilize layers with convolving filters that are applied to local features (LeCun et al., 1998). Originally invented for computer vision, CNN models have subsequently been shown to be effective for NLP and have achieved excellent results in semantic parsing (Yih et al., 2014), search query retrieval (Shen et al., 2014), sentence modeling (Kalchbrenner et al., 2014), and other traditional NLP tasks (Collobert et al., 2011).
翻译
卷积神经网络(CNN)利用带有卷积滤波器的图层应用于局部特征(LeCun et al., 1998)。 CNN模型最初是为计算机视觉而发明的,后来被证明对NLP有效,并且在语义解析(Yih et al., 2014)、搜索查询检索(Shen et al., 2014)、句子建模(Kalchbrenneret et al., 2014)和其他传统的NLP任务(Collobert et al., 2011)方面取得了优异的结果。
单词解释
local features 局部特征、 layers with convolving filters 带有卷积滤波器的图层。
semantic parsing 语义解析、search query retrieval 搜索查询检索、sentence modeling句子建模
技术解读
传统NLP任务:句子建模、语义解析、搜索查询检索。
CNN技术
主要结构
- 输入层(Input layer):输入数据;
- 卷积层(Convolution layer,CONV):使用卷积核进行特征提取和特征映射;
- 激活层:非线性映射(ReLU)
- 池化层(Pooling layer,POOL):进行下采样降维;
- 光栅化(Rasterization):展开像素,与全连接层全连接,某些情况下这一层可以省去;
- 全连接层(Affine layer / Fully Connected layer,FC):在尾部进行拟合,减少特征信息的损失;
- 激活层:非线性映射(ReLU)
- 输出层(Output layer):输出结果。
其中、卷积层、池化层和激活层可以叠加重复使用,这是CNN的核心结构。
在经过数次卷积和池化之后,最后会先将多维的数据进行“扁平化”,也就是把(height,width,channel)的数据压缩成长度为height × width × channel的一维数组,然后再与FC层连接,这之后就跟普通的神经网络无异了
卷积层(Convlotuion layer)
卷积层由一组滤波器组成,滤波器为三维结构,其深度由输入数据的深度决定,一个滤波器可以看作由多个卷积核堆叠形成。这些滤波器在输入数据上滑动做卷积运算,从输入数据中提取特征。在训练时,滤波器上的权重使用随机值进行初始化,并根据训练集进行学习,逐步优化。
(其实就是利用数学公式提取特征类)
- 卷积运算
卷积核
卷积运算是指以一定间隔滑动卷积核的窗口,将各个位置上卷积核的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算),将这个结果保存到输出的对应位置。卷积运算如下所示:
对于一张图像,卷积核从图像最始端,从左往右、从上往下,以一个像素或指定个像素的间距依次滑过图像的每一个区域。
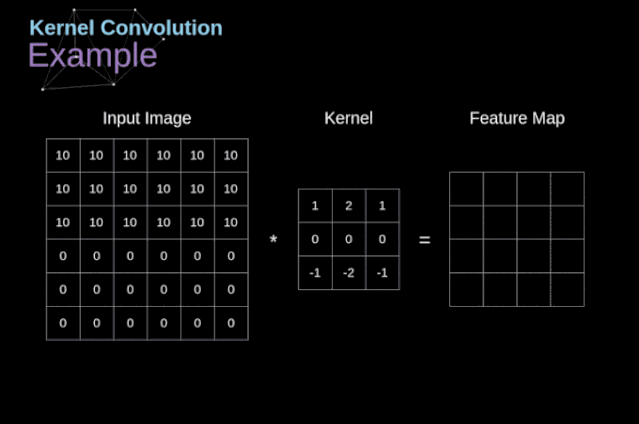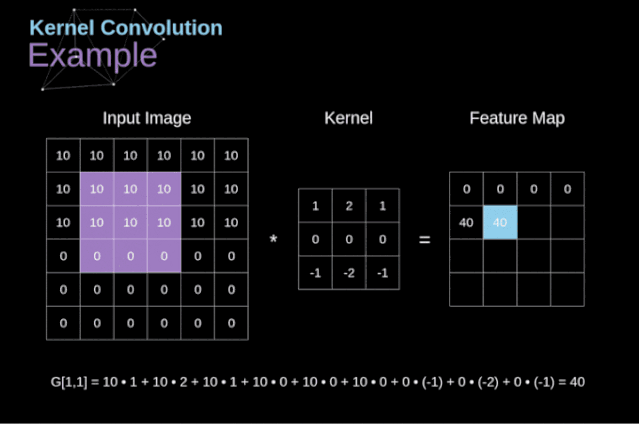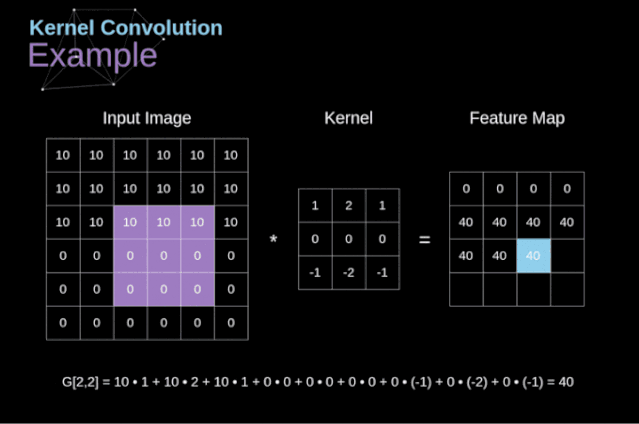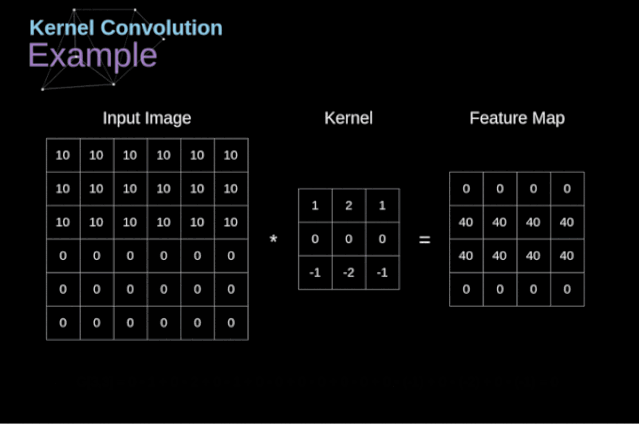

可以把卷积核理解为权重。每一个卷积核都可以当做一个“特征提取算子”,把一个算子在原图上不断滑动,得出的滤波结果就被叫做“特征图”(Feature Map),这些算子被称为“卷积核”(Convolution Kernel)。我们不必人工设计这些算子,而是使用随机初始化,来得到很多卷积核,然后通过反向传播优化这些卷积核,以期望得到更好的识别结果。
填充/填白(Padding)
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),使用填充的目的是调整输出的尺寸,使输出维度和输入维度一致; (输入维度和输出维度一致)
如果不调整尺寸,经过很多层卷积之后,输出尺寸会变的很小。所以,为了减少卷积操作导致的,边缘信息丢失,我们就需要进行填充(Padding)。(卷积操作导致的边缘信息损失)
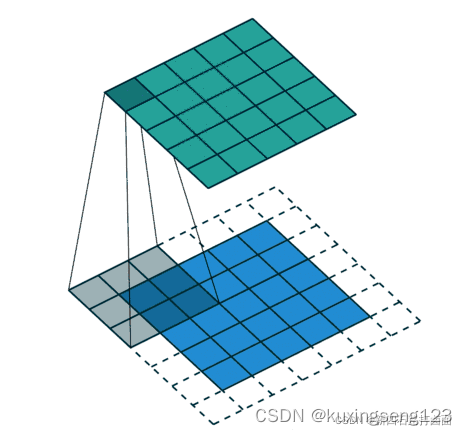
步幅与步长(Stride)
- 即卷积核每次滑动几个像素。前面我们默认卷积核每次滑动一个像素,其实也可以每次滑动2个像素。其中,每次滑动的像素数称为“步长”,步长为2的卷积核计算过程如下;
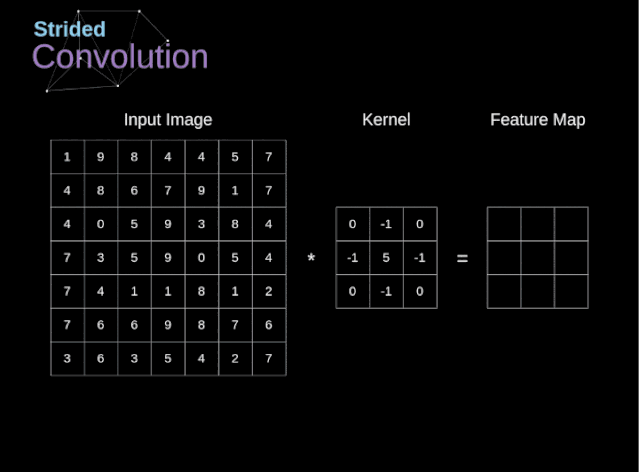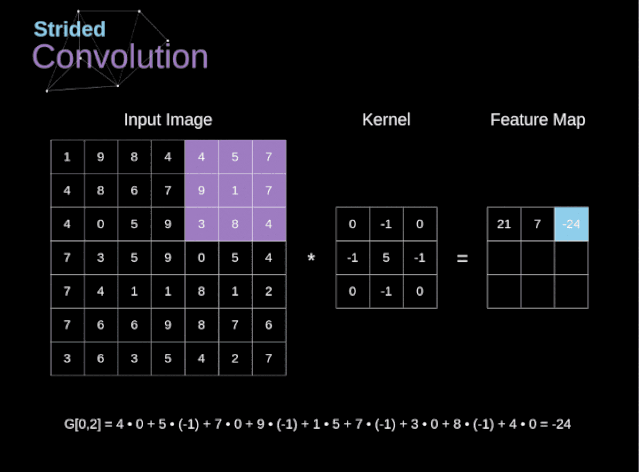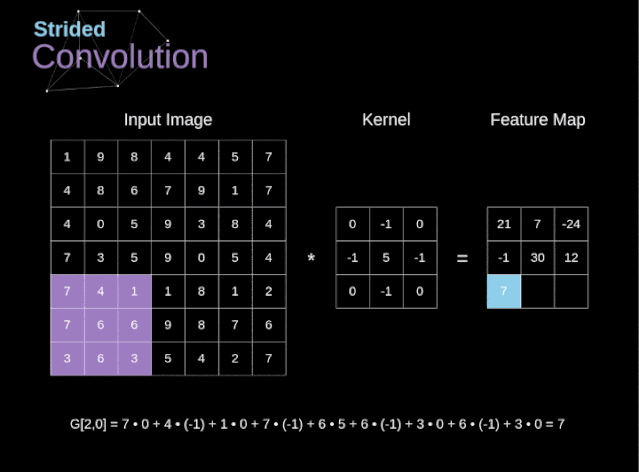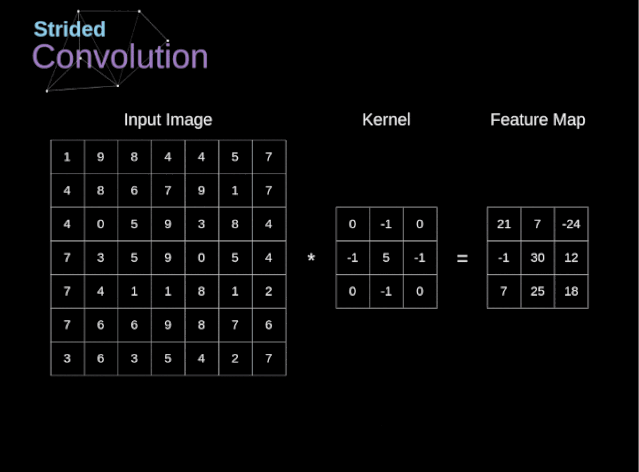
若希望输出尺寸比输入尺寸小很多,可以采取增大步幅的措施。但是不能频繁使用步长为2,因为如果输出尺寸变得过小的话,即使卷积核参数优化的再好,也会必可避免地丢失大量信息;
如果用f 表示卷积核大小,s 表示步长,w 表示图片宽度,h 表示图片高度,那么输出尺寸可以表示为:

滤波器(Fitter)
卷积核(算子)是二维的权重矩阵;而滤波器(Filter)是多个卷积核堆叠而成的三维矩阵。
在只有一个通道(二维)的情况下,“卷积核”就相当于“filter”,这两个概念是可以互换的
上面的卷积过程,没有考虑彩色图片有RGB三维通道(Channel),如果考虑RGB通道,那么每个通道都需要一个卷积核,只不过计算的时候,卷积核的每个通道在对应通道滑动,三个通道的计算结果相加得到输出。即:每个滤波器有且只有一个输出通道。
当滤波器中的各个卷积核在输入数据上滑动时,它们会输出不同的处理结果,其中一些卷积核的权重可能更高,而它相应通道的数据也会被更加重视,滤波器会更关注这个通道的特征差异。(滤波器更加关注这个通道的特征差异)
偏置
- 最后,偏置项和滤波器一起作用产生最终的输出通道。
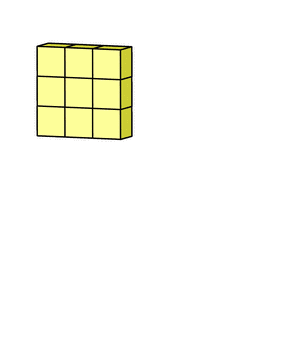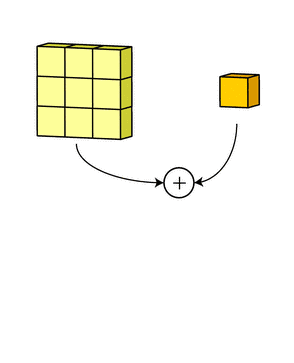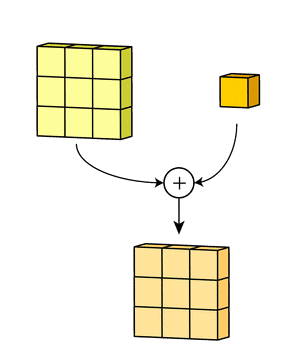
多个filter也是一样的工作原理:如果存在多个filter,这时我们可以把这些最终的单通道输出组合成一个总输出,它的通道数就等于filter数。这个总输出经过非线性处理后,继续被作为输入馈送进下一个卷积层,然后重复上述过程。
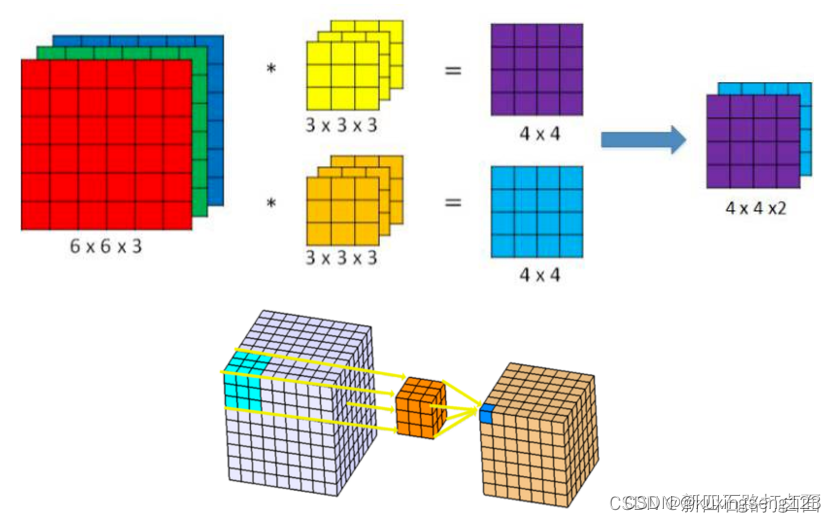
因此,这部分一共4个超参数:滤波器数量K ,滤波器大小F ,步长S ,零填充大小P 。
卷积的三种模式
三种卷积模式是对卷积核移动范围的不同限制。
-
**Full Mode:**从卷积核和图像刚相交时开始做卷积,白色部分填0。
-
**Same Mode:**当卷积核中心(K)与图像的边角重合时,开始做卷积运算,白色部分填0。可见其运动范围比Full模式小了一圈。
注意:这里的same还有一个意思,卷积之后输出的feature map尺寸保持不变<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3794
3794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











