




摘要
By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. (通过利用大量的多样化的任务通用的数据集,这些数据转化为知识,现在大模型都能够高水平的解决特定的下有任务,无论是零样本方式还是少量的指定任务数据集,也就是语言大模型现在已经得到验证,利用强化学习能够使用一个大模型,解决各种任务)。While this capabilityhas been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data。(尽管这个方法已经在计算机视觉,自然语言处理,语音识别任务中,但是在机器恩这个领域任然需要验证,由于机器人收集真实数据比较困难,所以模型的通用泛化能力非常重要)。We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data(我们相信存在一个高质量的架构能够很好地利用多样化的机器人数据,并且训练的关键在于模型的训练是开放式的,并且无某一个任务无关性,或者换句话说是不针对特定任务,而是对所有任务的通用训练,类似于现在的语言大模型)。In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties(这篇文章,我们提出了机器人的transformer,显示出很有前瞻行的模型)
introduction
End-to-end robotic learning, with either imitation or reinforcement, typically involves collecting task-specific data in either single-task (Kalashnikov et al., 2018; Zhang et al., 2018) or multitask (Kalashnikov et al., 2021b; Jang et al., 2021) settings that are narrowly tailored to the tasks that the robot should perform.(现在端到端的机器人学习,主要是强化学习及模仿学习,主要收集指定任务的训练数据,或者是专门为机器人多任务设置的数据)。This workflow mirrors the classic approach to supervised learning in other domains, such as computer vision and NLP, where task-specific datasets would be collected, labeled, and deployed to solve individual tasks, with little interplay between the tasks themselves.()这些工作流与类似于计算机视觉或nlp领域类似,需要再指定任务收集数据,标注,部署来解决独立的任务,多个任务之间互动性很小。Recent years have seen a transformation in vision, NLP, and other domains, away from siloed, small scale datasets and models and towards large, general models pre-trained on broad, large datasets.(近些年来,在视觉和nlp的领域逐渐从孤立,小数据,单任务训练逐渐转变为大的,一般通用模型和大量数据的模型训练)。The keys to the success of such models lie with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the knowledge present in large-scale datasets.(这些模型关键因素在于能够使用开放的,任务独立的训练,主要在于好的架构能够学习大量的知识从非常多的数据中学习)If a model can “sponge up” experience to learn general patterns in language or perception, then it can bring them to bear on individual tasks more efficiently(如果一个模型能够吸收大量知识,并且能够学到通用的模式,那么这个模型能够更加有效的应用于单个任务中)。While removing the need for large taskspecific datasets is appealing generally in supervised learning, it is even more critical in robotics, where datasets might require engineering-heavy autonomous operation or expensive human demonstrations.(能够去除针对特定任务的大量数据标注工作在监督学习中是非常有吸引力的,这在robotics中也是非常重要的,由于需要复杂的昂贵的标注工作,甚至需要人类的演示)。We therefore ask: can we train a single, capable, large multi-task backbone model on data consisting of a wide variety of robotic tasks? (我们是否能训练一个能力比较强支撑多任务的基础模型,并且能够对于新任务利用零样本进行适配,环境或者objects)
Building such models in robotics is not easy. Although recent years have seen several large multitask robot policies proposed in the literature (Reed et al., 2022; Jang et al., 2021),(构建这样的模型并不容易,尽管这些年已经提出了多任务的机器人训练模型)。, such models often have limited breadth of real-world tasks, as with Gato (Reed et al., 2022), or focus on training tasks rather than generalization to new tasks, as with recent instruction following methods (Shridhar et al., 2021; 2022), or attain comparatively lower performance on new tasks (Jang et al., 2021)(但是这些模型在真是世界的任务中缺乏广度,意思就是不具备拓展性,在新任务中性能较差,这些模型主要集中在训练任务本身而不是把能力拓展到新任务中,)
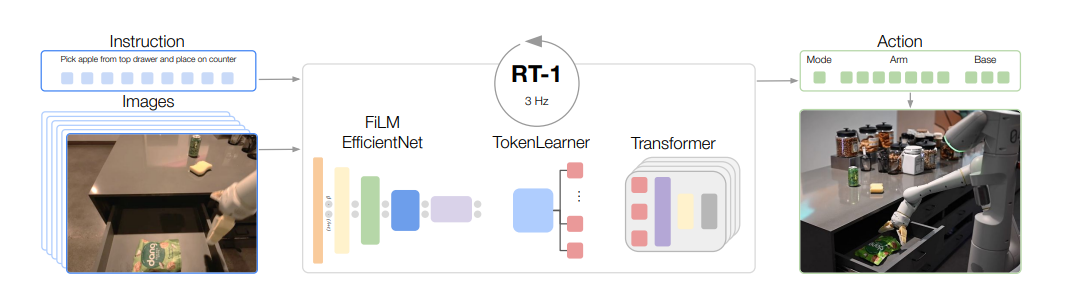
picke apple from top drawer and place on counter
RT-1 takes images and natural language instructions and outputs discretized base and arm actions. Despite its size (35M parameters), it does this at 3 Hz, due to its efficient yet high-capacity architecture: a FiLM (Perez et al., 2018) conditioned EfficientNet (Tan & Le, 2019), a TokenLearner (Ryoo et al., 2021), and a Transformer (Vaswani et al., 2017).(RT-1把图像与自然语言指令作为输入,输出离散的底座和手臂action,尽管他的模型大小为35M参数,他以3HzP频率运行,主要得益于基于条件的EfficientNet FiLM, a 个可学习的TokenLearner,及transformer。

(b) RT-1’s large-scale, real-world training (130k demonstrations) and evaluation (3000 real-world trials) show impressive generalization, robustness, and ability to learn from diverse data.(RT-1大尺度的模型,能够训练真实世界的130K个场景数据训练,评估了3000个其他场景,展示了令人深刻的泛化能力及鲁棒性,以及学习多样化数据的能力)。
The two main challenges lie in assembling the right dataset and designing the right model(两个主要的挑战在于组装正确的数据集以及涉及正确模型)While data collection and curation is often the “unsung hero” of many large-scale machine learning projects (Radford et al., 2021; Ramesh et al., 2021),(数据的搜集及策划往往是默默的核心英雄,对于大部分机器学习来说)。this is especially true in robotics, where datasets are often robot-specific and gathered manually (Dasari et al., 2019; Ebert et al., 2021)(对于机器人学习来说更是这样,但是这些数据都是指定的数据并且大部分是人工收集的)。As we will show in our evaluations, good generalization requires datasets that combine both scale and breadth, covering a variety of tasks and settings。(正如我们的评估,好的泛化性数据既具备规模有包含广度,包含多样化的任务和设置)。At the same time, the tasks in the dataset should be sufficiently well-connected to enable generalization, such that the model can discover the patterns between structural similar tasks and perform new tasks that combine those patterns in novel ways(同时,任务的数据集应该具备能够泛化的关联性,意思就是能够产生模式同类型任务,这样模型能够学习相似任务的模板,在新的任务能够结合这些模式产生与此任务相关的新模式)。

















 2997
2997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









