



一、引言


二、 解决之道


三、 横向测评:主流动态代理供应商Zillow数据获取能力对比
测评对象与设定:

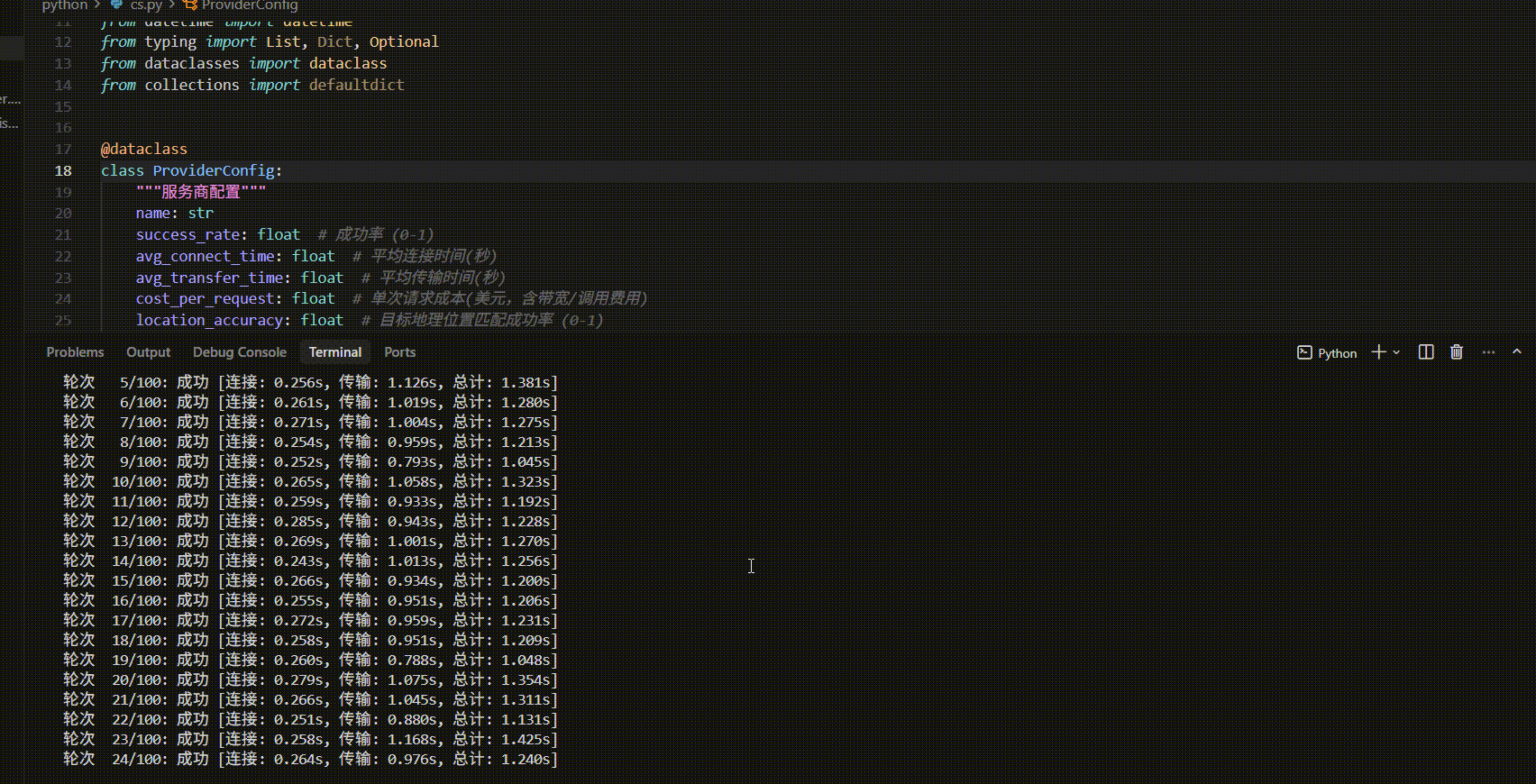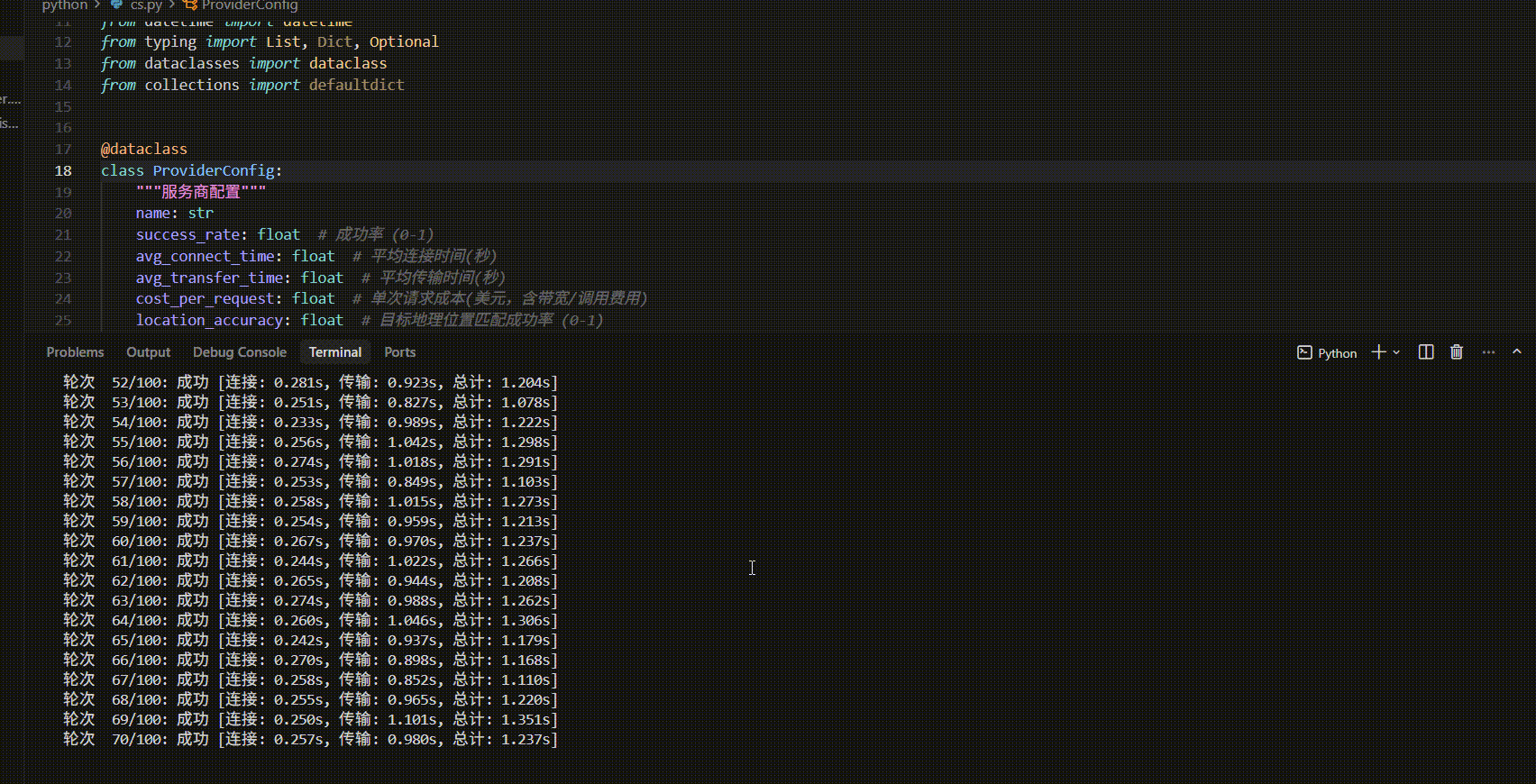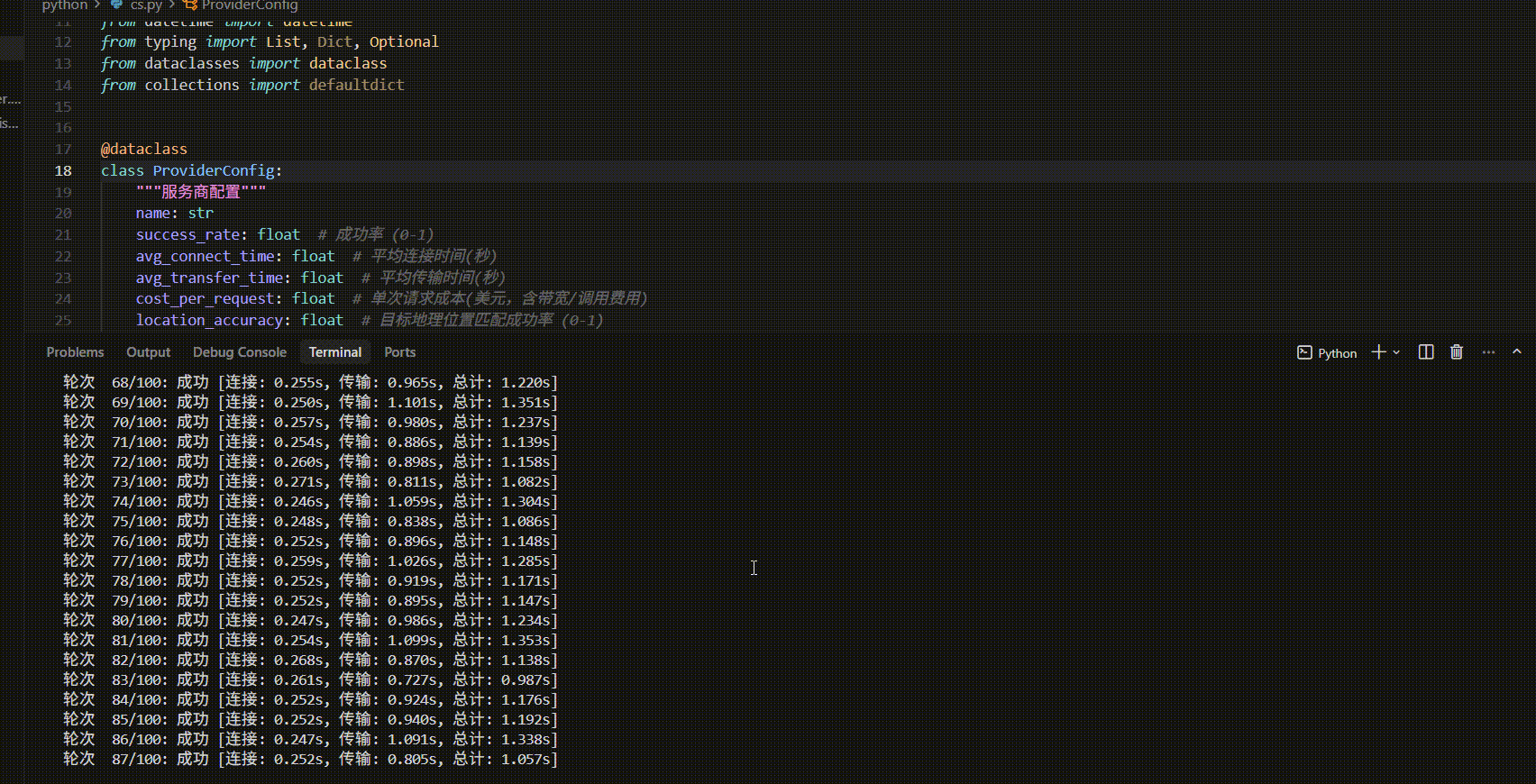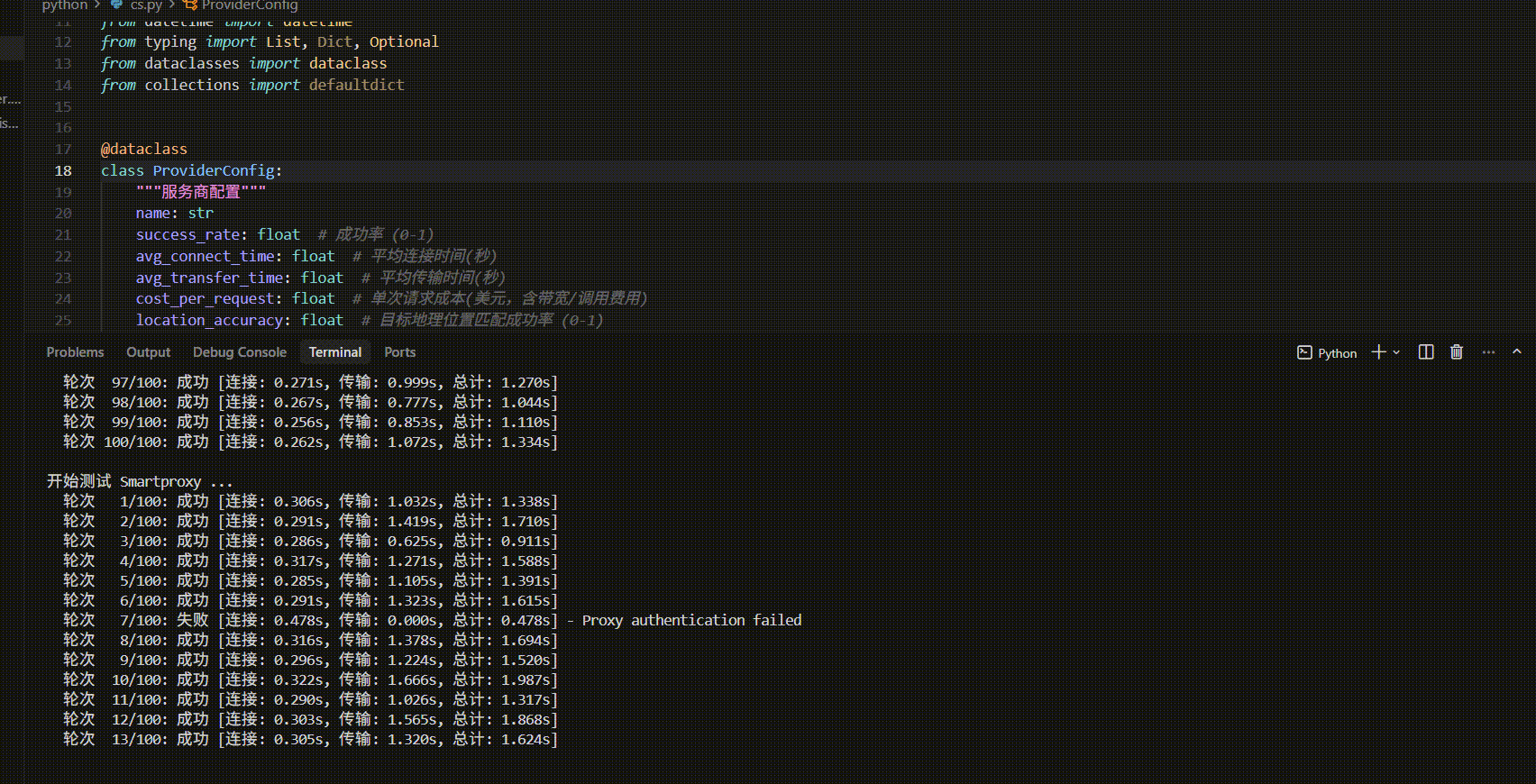


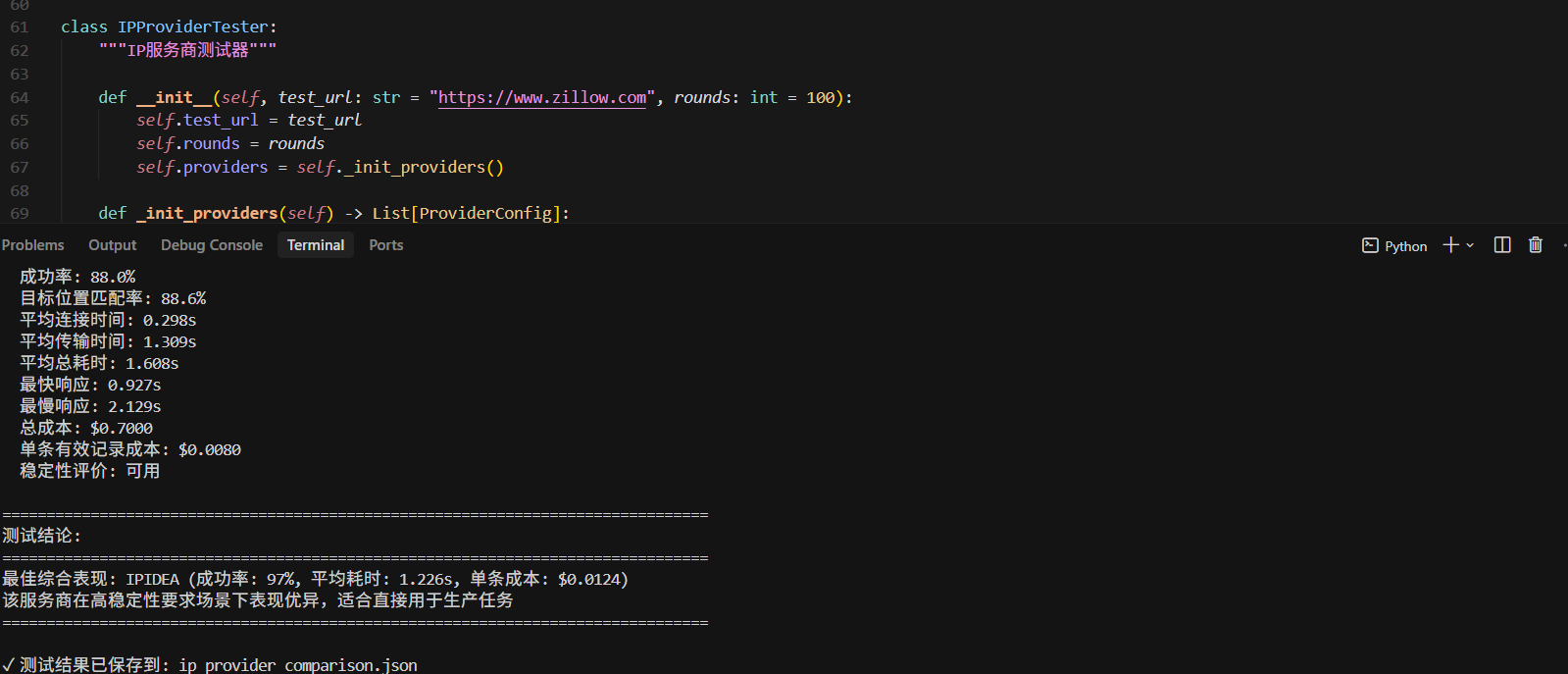
| 评估维度 | 请求成功率 | 位置精度 | 平均连接时间 | 平均总耗时 | 最快响应 | 最慢响应 | 稳定性评价 |
|---|---|---|---|---|---|---|---|
| 测试100条 | 98.00% | 91.80% | 0.260s | 1.207s | 0.987s | 1.425s | 良好 |


| 评估维度 | 请求成功率 | 位置精度 | 平均连接时间 | 平均总耗时 | 最快响应 | 最慢响应 | 稳定性评价 |
|---|---|---|---|---|---|---|---|
| 测试100条 | 97.00% | 92.80% | 0.268s | 1.330s | 1.029s | 1.644s | 良好 |


| 评估维度 | 请求成功率 | 位置精度 | 平均连接时间 | 平均总耗时 | 最快响应 | 最慢响应 | 稳定性评价 |
|---|---|---|---|---|---|---|---|
| 测试100条 | 92.00% | 87.00% | 0.301s | 1.591s | 0.911s | 2.155s | 良好 |

四、 实战项目:基于IPIDEA解决方案的Zillow数据采集实现


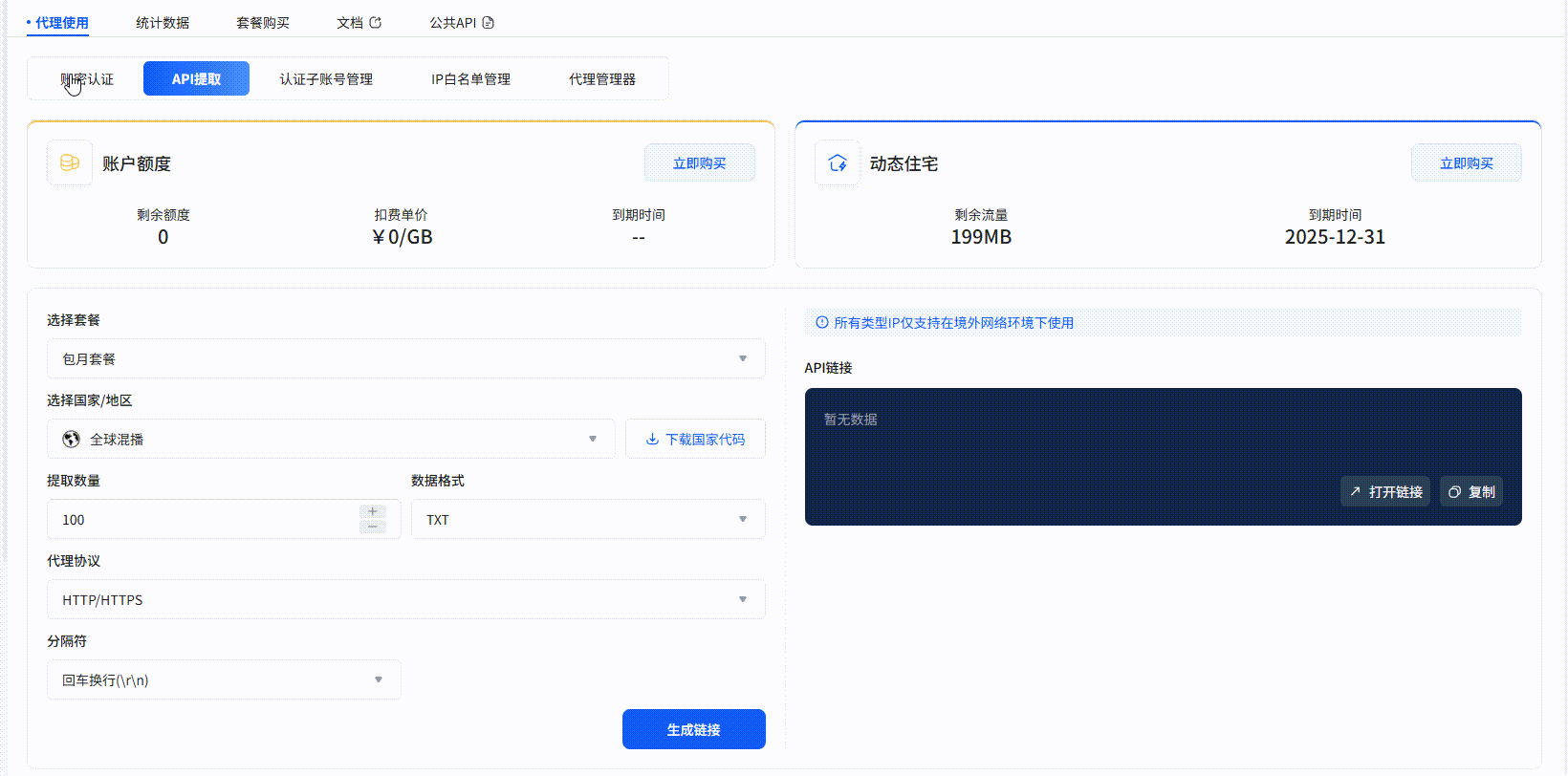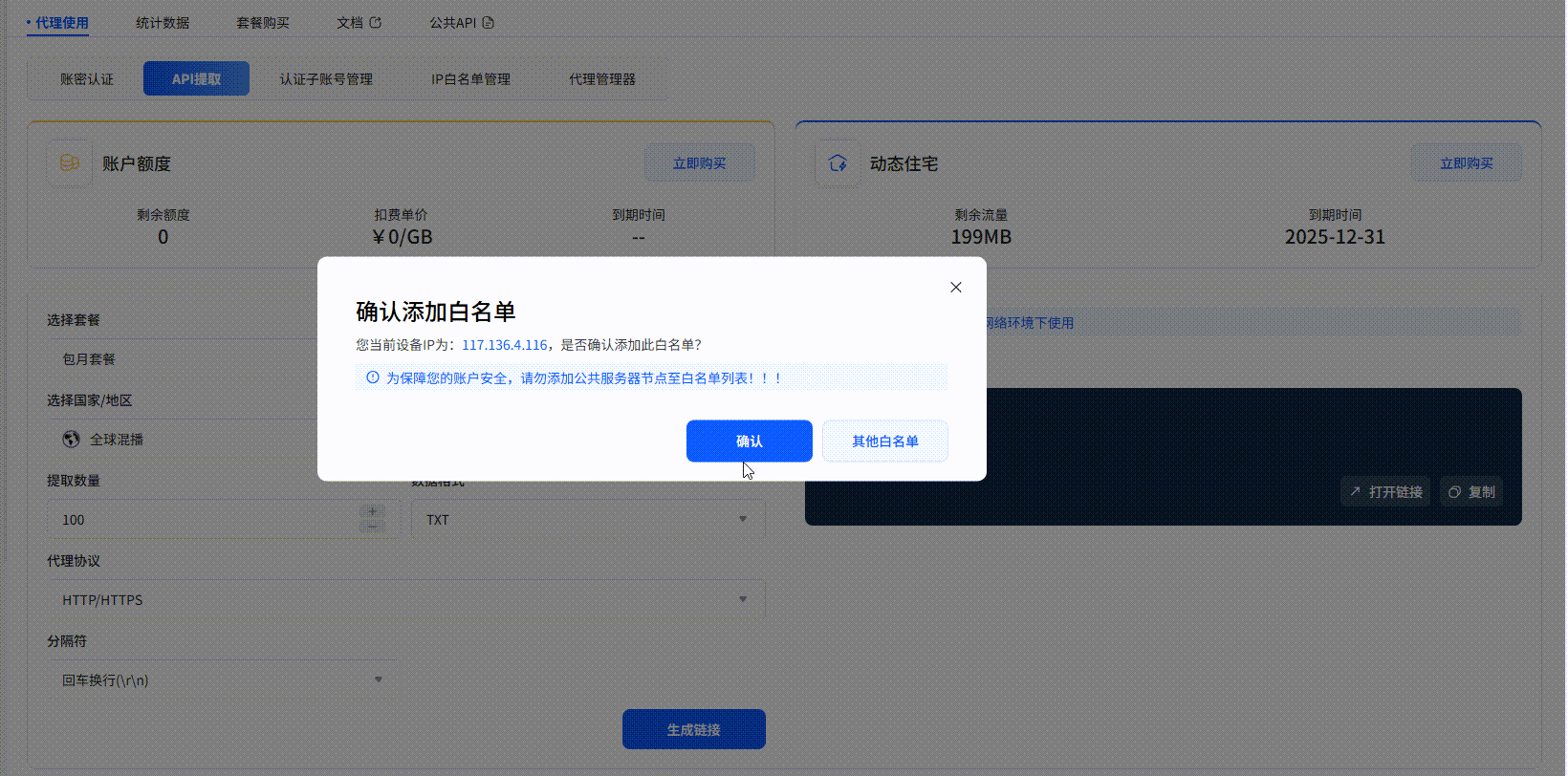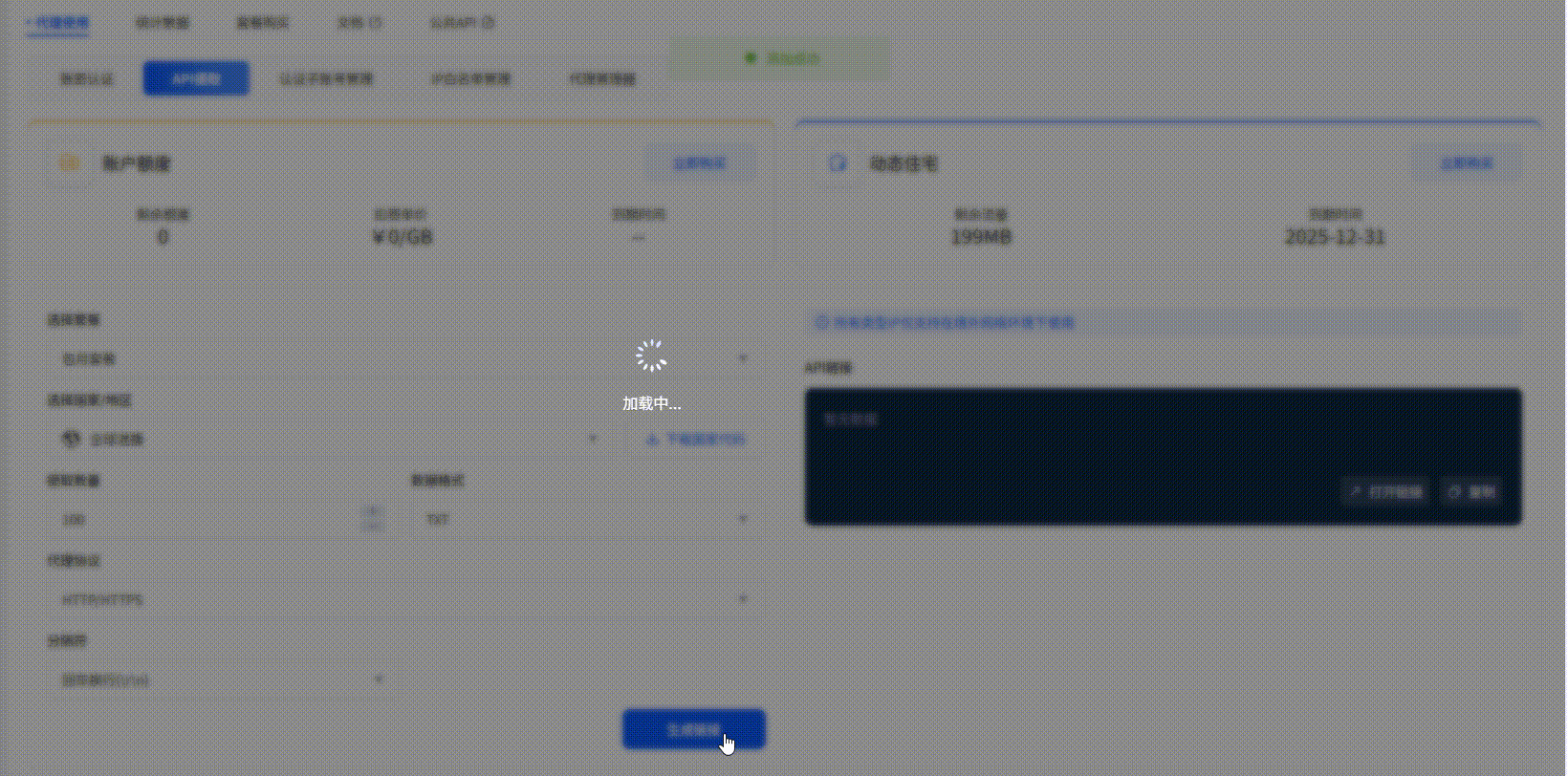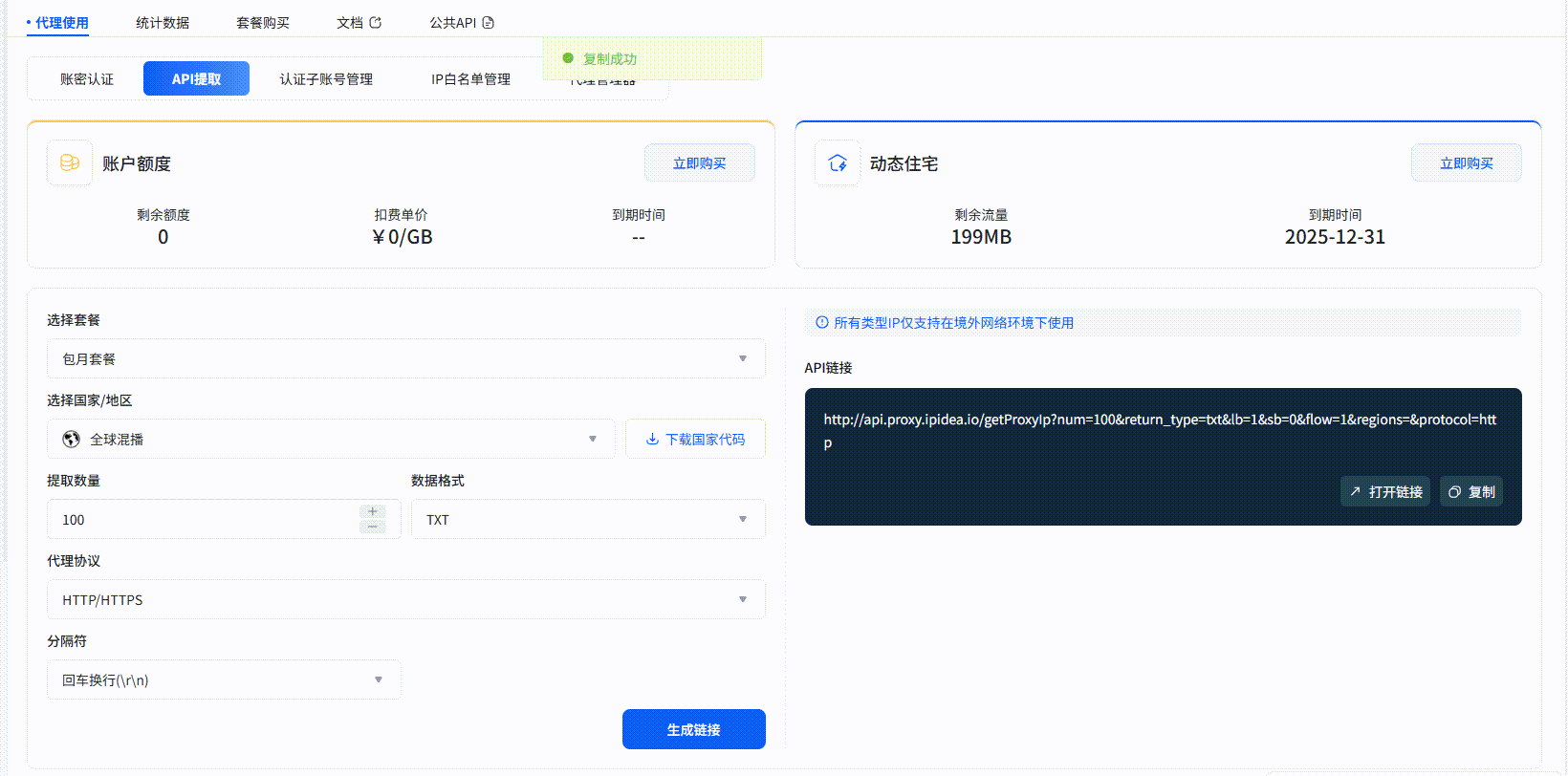
示例代码为:
# 代理池管理器核心伪代码
class ProxyPoolManager:
def __init__(self, api_key, endpoint, region='us'):
self.api_key = api_key
self.endpoint = endpoint
self.region = region
self.active_proxies = [] # 活跃代理列表
self.failed_proxies = [] # 失败代理列表
def fetch_proxies_from_api(self, num=10):
# 构建API请求参数
params = {
'num': num,
'return_type': 'json',
'protocol': 'http',
'regions': self.region,
'lb': 1 # 分隔符为\r\n
}
# 发送API请求获取代理列表
response = requests.get(self.endpoint, params=params)
proxy_list = response.json()['data']
return proxy_list
def test_proxy_connection(self, proxy):
"""测试代理连接性和延迟[citation:4]"""
test_url = "http://httpbin.org/get"
proxy_dict = {
'http': f'http://{proxy}',
'https': f'http://{proxy}'
}
try:
start_time = time.time()
response = requests.get(test_url, proxies=proxy_dict, timeout=5)
latency = time.time() - start_time
# 验证代理是否有效隐藏真实IP
if response.json()['origin'] in proxy:
return {
'proxy': proxy,
'latency': latency,
'status': 'active',
'location': self.get_ip_location(proxy)
}
except:
return {'proxy': proxy, 'status': 'failed'}
def get_ip_location(self, proxy_ip):
"""获取IP[citation:4]"""
# 使用外部API验证代理
response = requests.get(f'https://ipwhois.app/json/{proxy_ip.split(":")[0]}')
return response.json()
def manage_proxy_pool(self):
"""动态代理池管理"""
while True:
# 1. 检查活跃代理状态
for proxy in self.active_proxies:
if time.time() - proxy['last_used'] > 300: # 5分钟未使用
status = self.test_proxy_connection(proxy['address'])
proxy.update(status)
# 2. 移除失败代理
self.active_proxies = [p for p in self.active_proxies
if p['status'] == 'active']
# 3. 补充新代理
if len(self.active_proxies) < 5:
new_proxies = self.fetch_proxies_from_api(5)
for proxy in new_proxies:
tested = self.test_proxy_connection(proxy)
if tested['status'] == 'active':
self.active_proxies.append(tested)
# 4. 更新代理池状态显示
self.update_proxy_dashboard()
time.sleep(60) # 每分钟检查一次
效果如下:
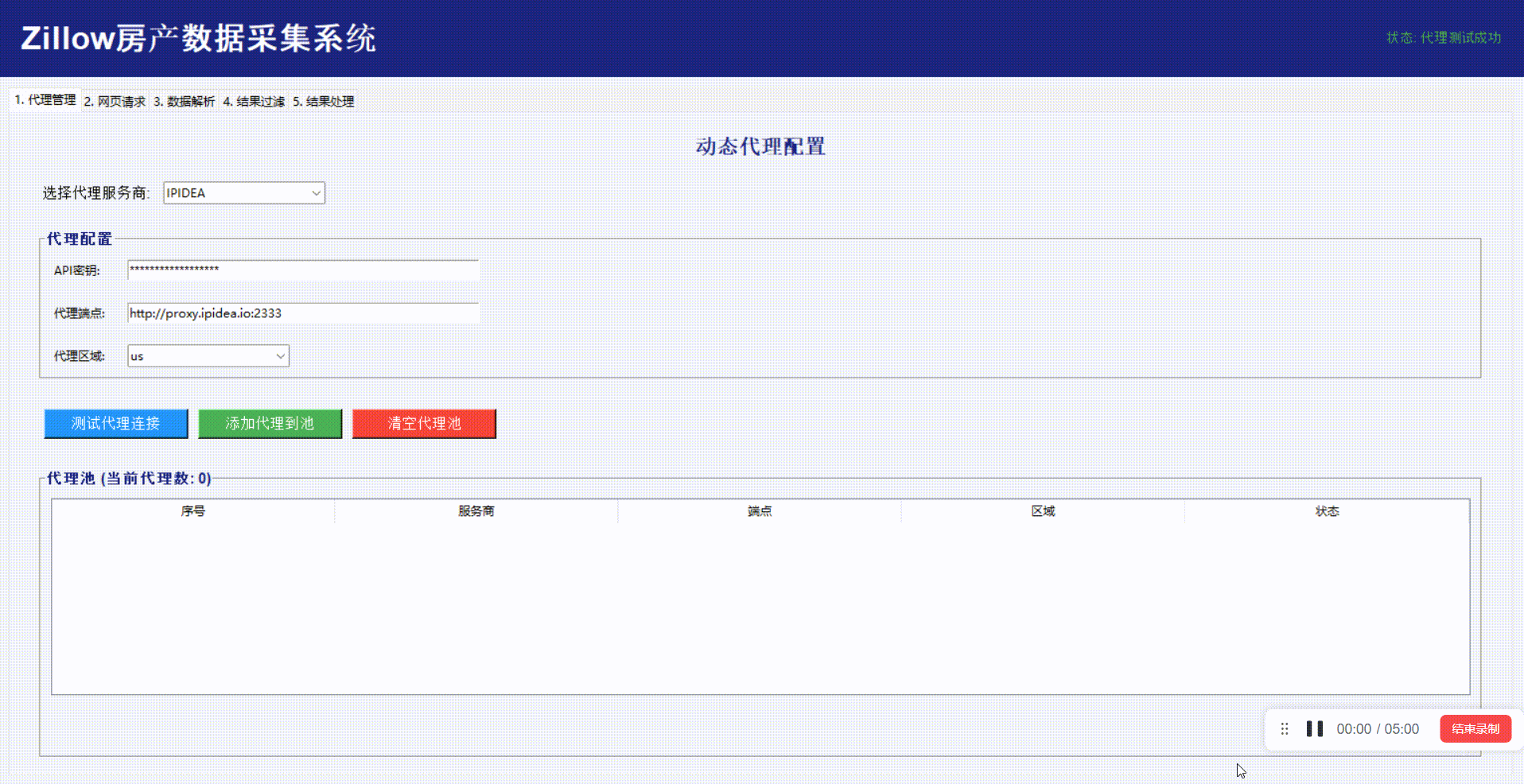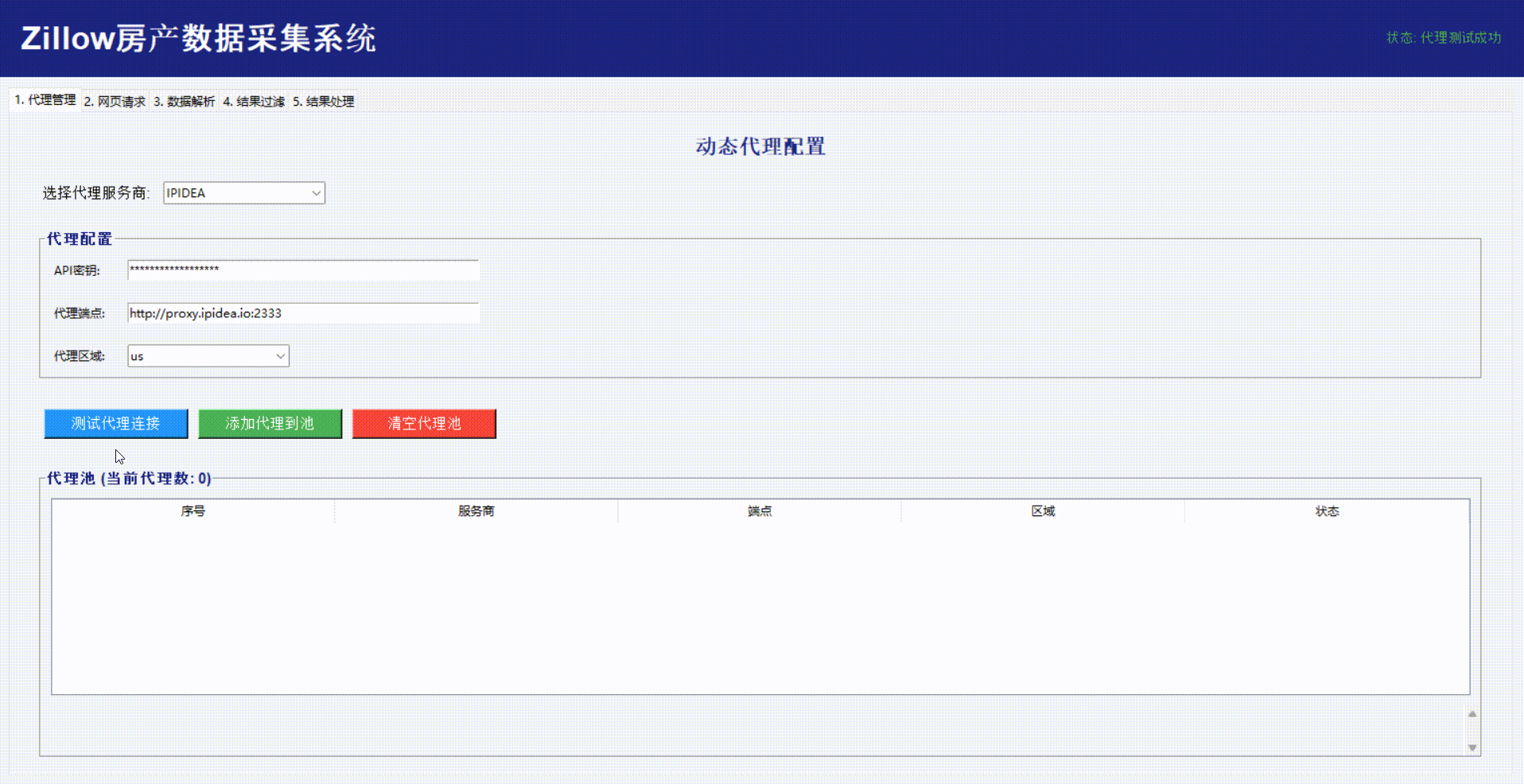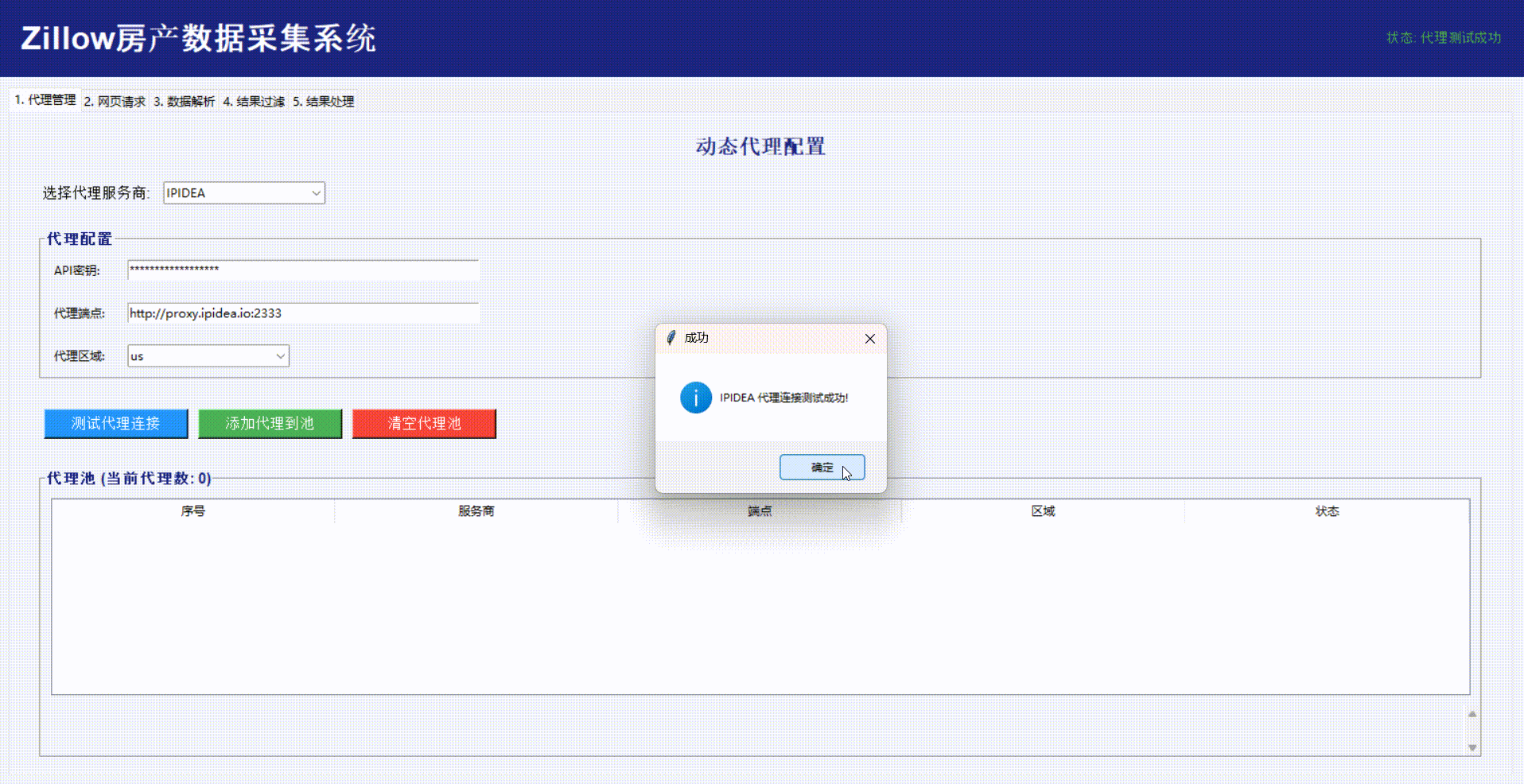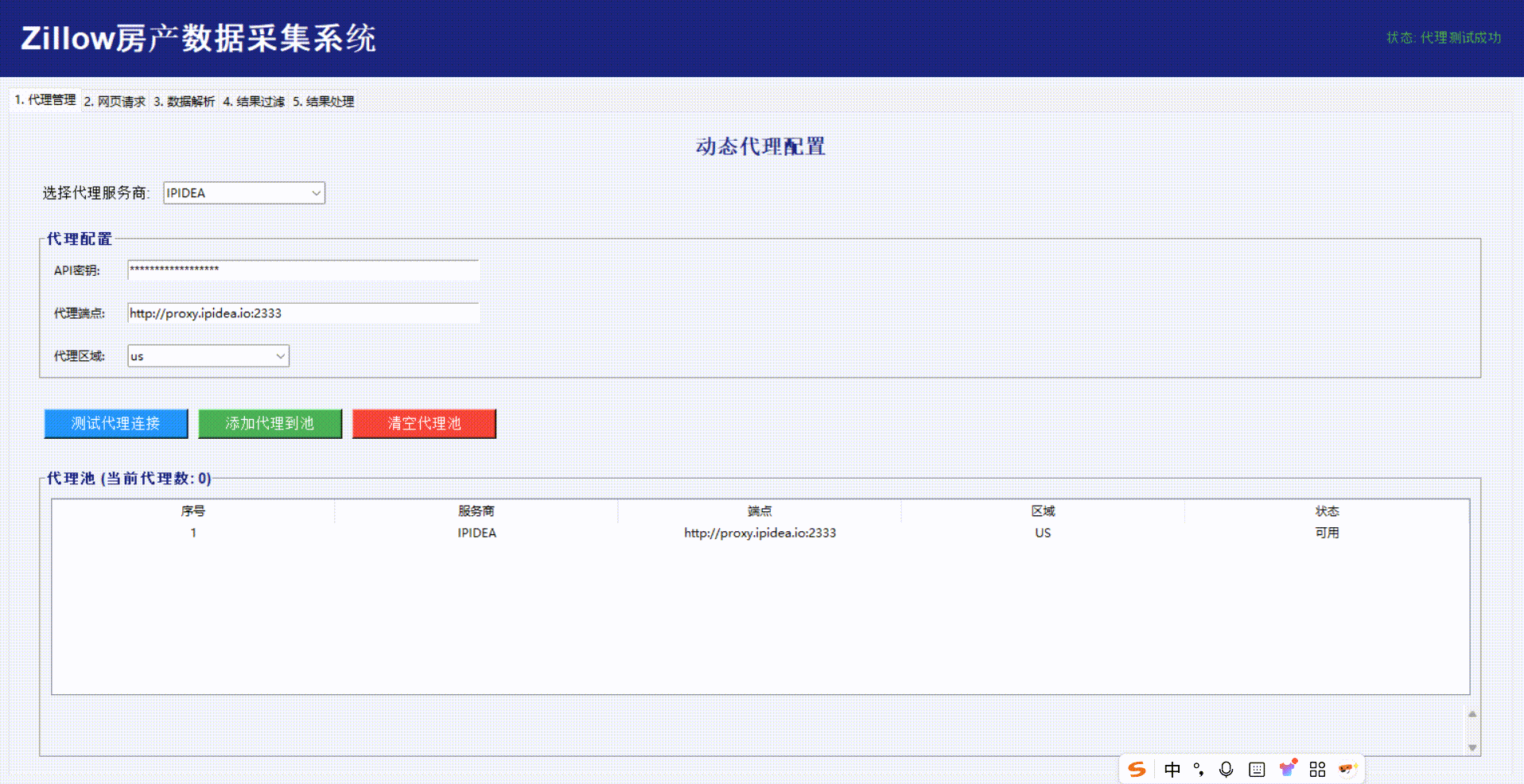
网页请求:

# 网页请求控制器伪代码
class WebRequestController:
def __init__(self, proxy_pool, config):
self.proxy_pool = proxy_pool
self.config = config # 包含超时、重试、间隔等参数
self.request_log = []
self.is_paused = False
self.is_stopped = False
async def create_browser_with_proxy(self):
"""创建带代理的浏览器实例[citation:9]"""
from playwright.async_api import async_playwright
# 从代理池获取有效代理
current_proxy = self.proxy_pool.get_next_proxy()
playwright = await async_playwright().start()
browser = await playwright.chromium.launch(
headless=True,
proxy={
'server': f'http://{current_proxy["address"]}',
'username': current_proxy.get('username', ''),
'password': current_proxy.get('password', '')
}
)
# 配置上下文,阻止不必要资源加载
context = await browser.new_context(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
)
# 路由处理器,优化性能
await context.route("**/*", self.route_handler)
return browser, context, current_proxy
async def route_handler(self, route):
"""路由处理器,阻止非必要资源[citation:9]"""
resource_type = route.request.resource_type
blocked_resources = ['image', 'stylesheet', 'font', 'media']
if resource_type in blocked_resources:
await route.abort()
else:
await route.continue_()
async def fetch_zillow_page(self, url, retry_count=3):
"""获取Zillow页面内容"""
attempt = 0
while attempt < retry_count and not self.is_stopped:
while self.is_paused:
await asyncio.sleep(1) # 暂停状态等待
browser, context, proxy = await self.create_browser_with_proxy()
try:
page = await context.new_page()
# 记录请求开始
self.log_request('start', url, proxy)
# 设置超时
await page.goto(url, timeout=self.config['timeout']*1000)
# 等待页面加载
await page.wait_for_selector('[data-test="property-details"]',
timeout=10000)
# 模拟人类行为:随机滚动
await self.simulate_human_scroll(page)
# 获取页面内容
content = await page.content()
# 记录成功
self.log_request('success', url, proxy, len(content))
await browser.close()
return content
except Exception as e:
# 记录失败
self.log_request('failed', url, proxy, error=str(e))
# 标记代理失败
self.proxy_pool.mark_proxy_failed(proxy)
attempt += 1
await asyncio.sleep(self.config['retry_interval'])
if attempt < retry_count:
self.log_request('retry', url, None, f'Attempt {attempt+1}')
return None
def log_request(self, event, url, proxy, **kwargs):
"""记录请求日志"""
log_entry = {
'timestamp': datetime.now().isoformat(),
'event': event,
'url': url,
'proxy': proxy['address'] if proxy else None,
**kwargs
}
self.request_log.append(log_entry)
self.update_request_dashboard(log_entry)
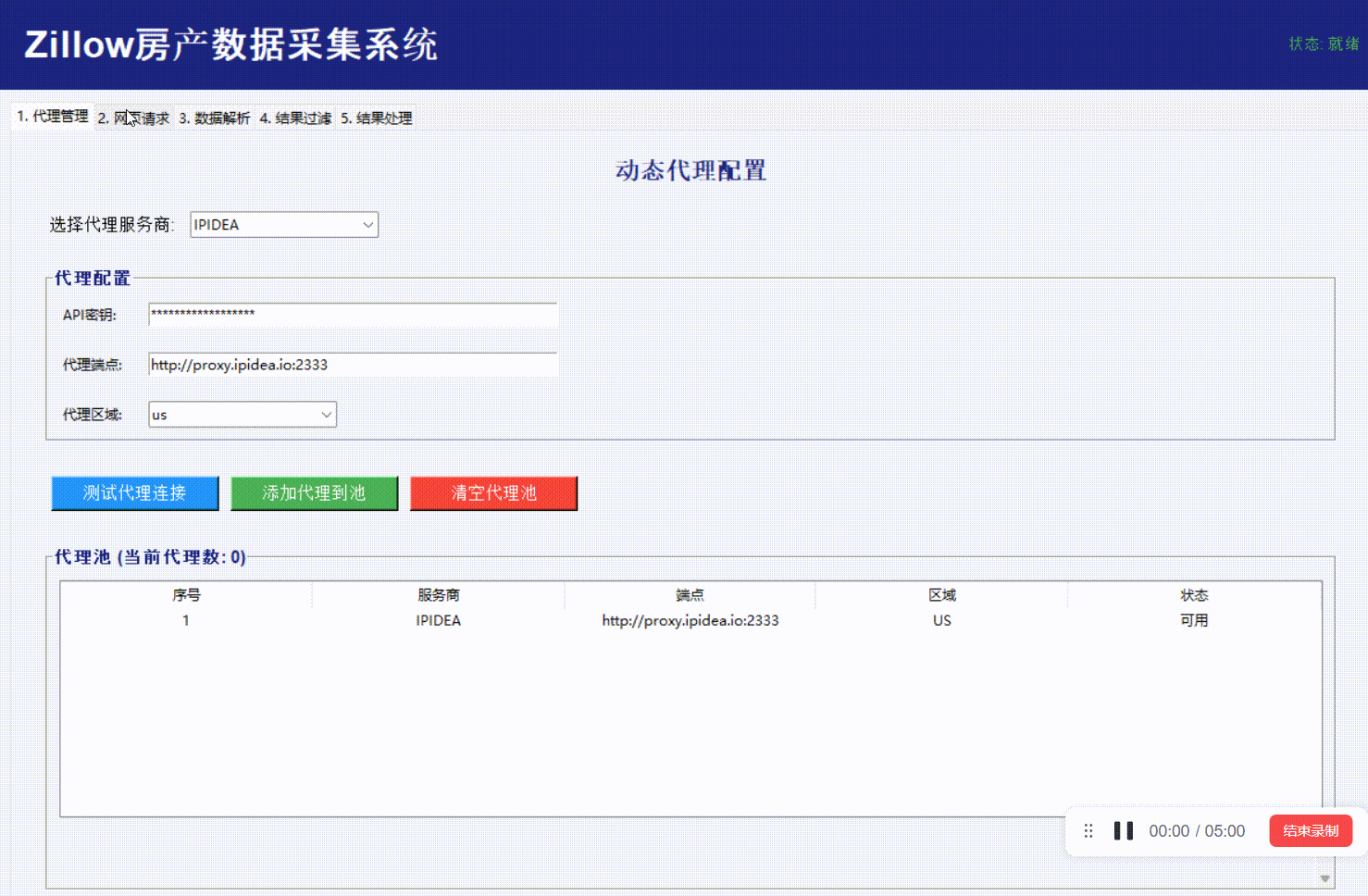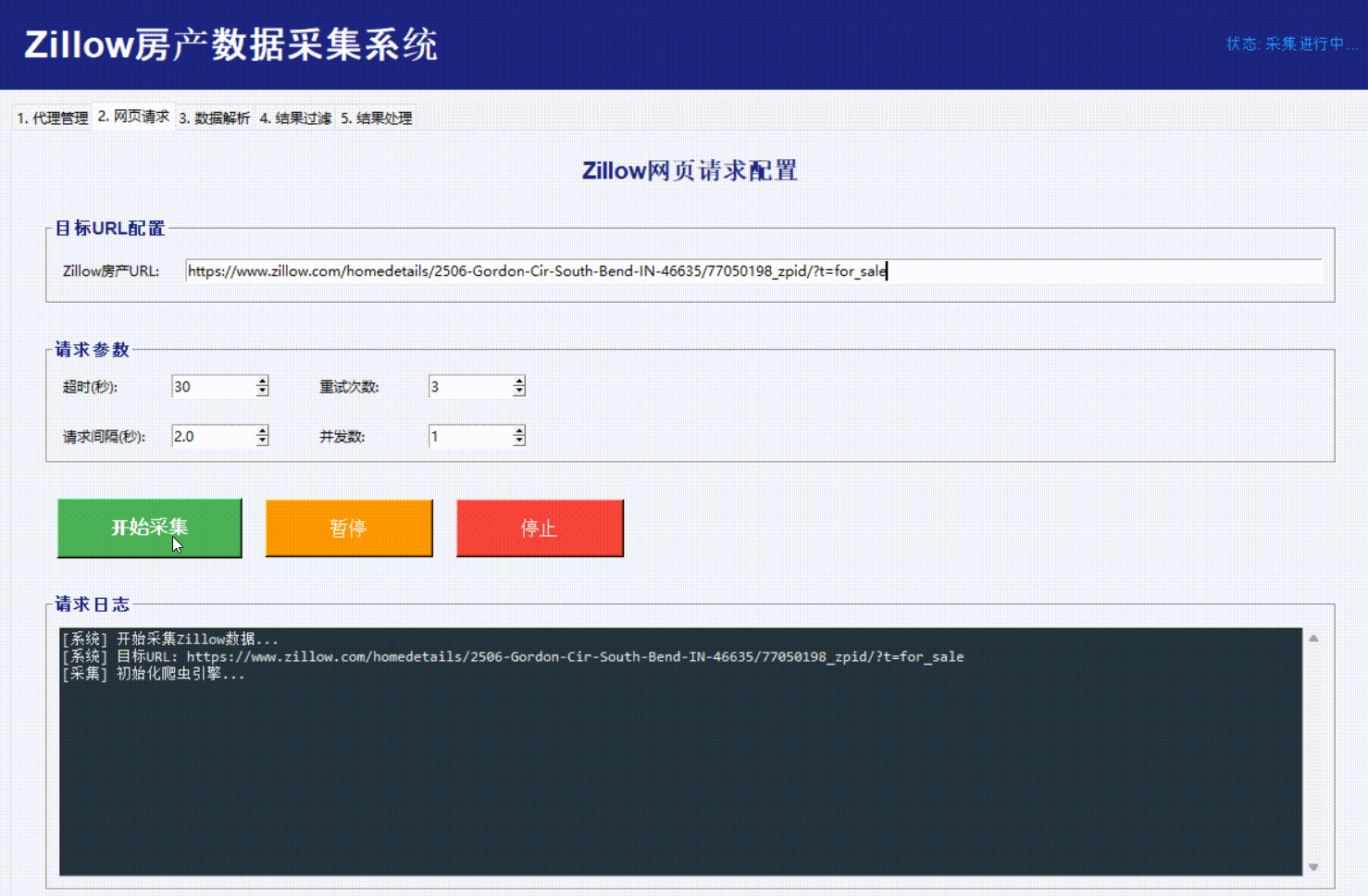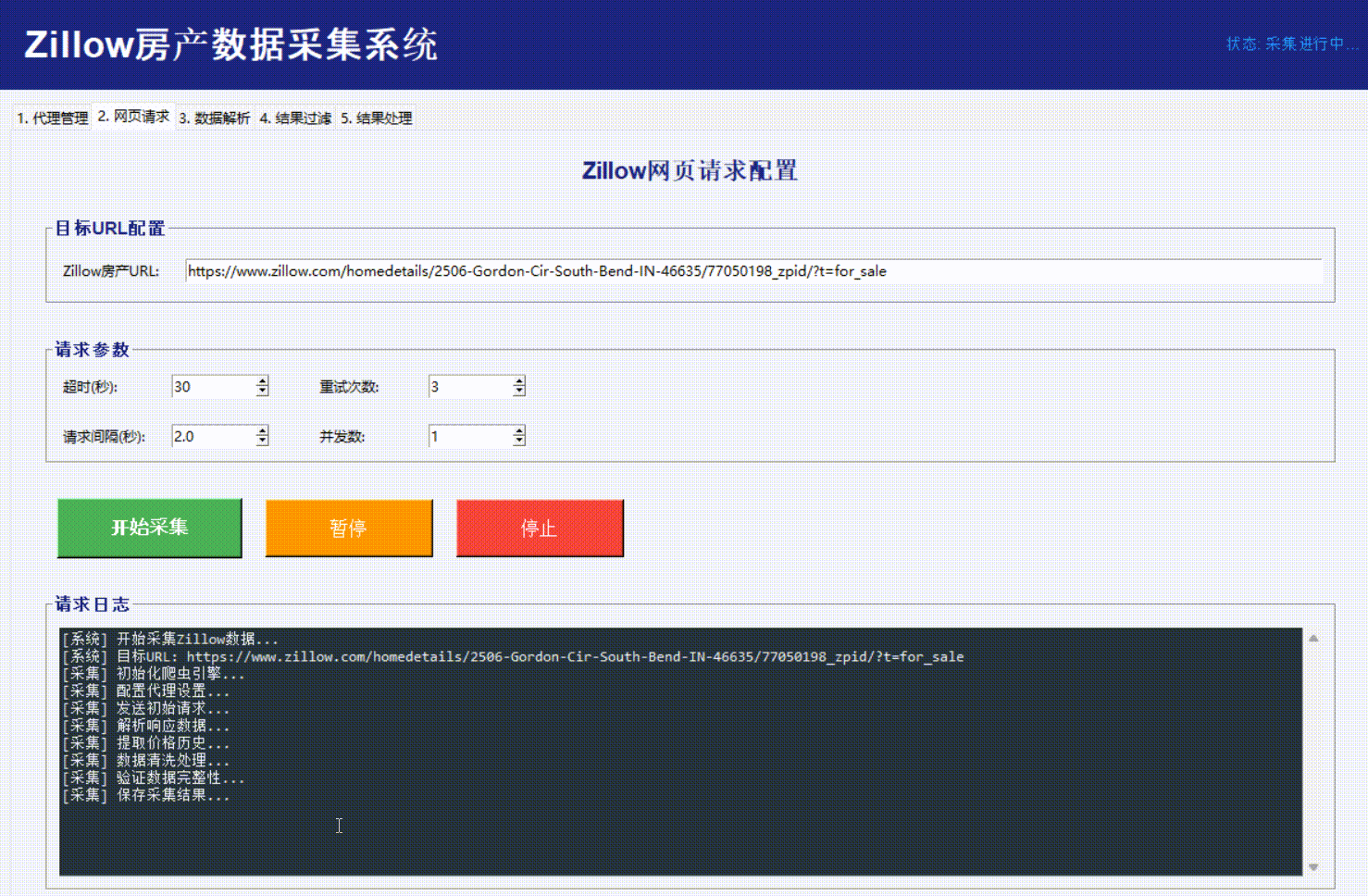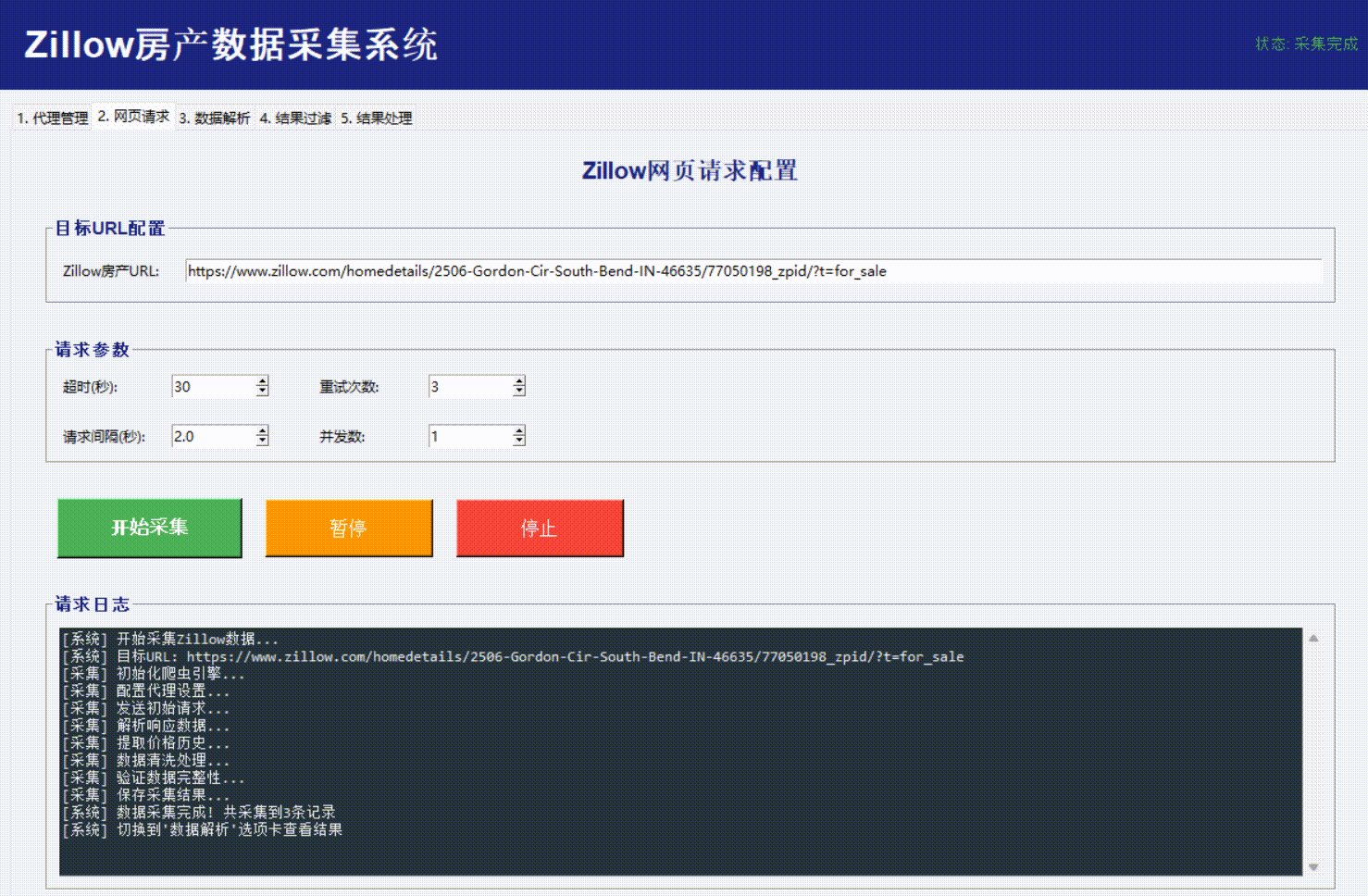
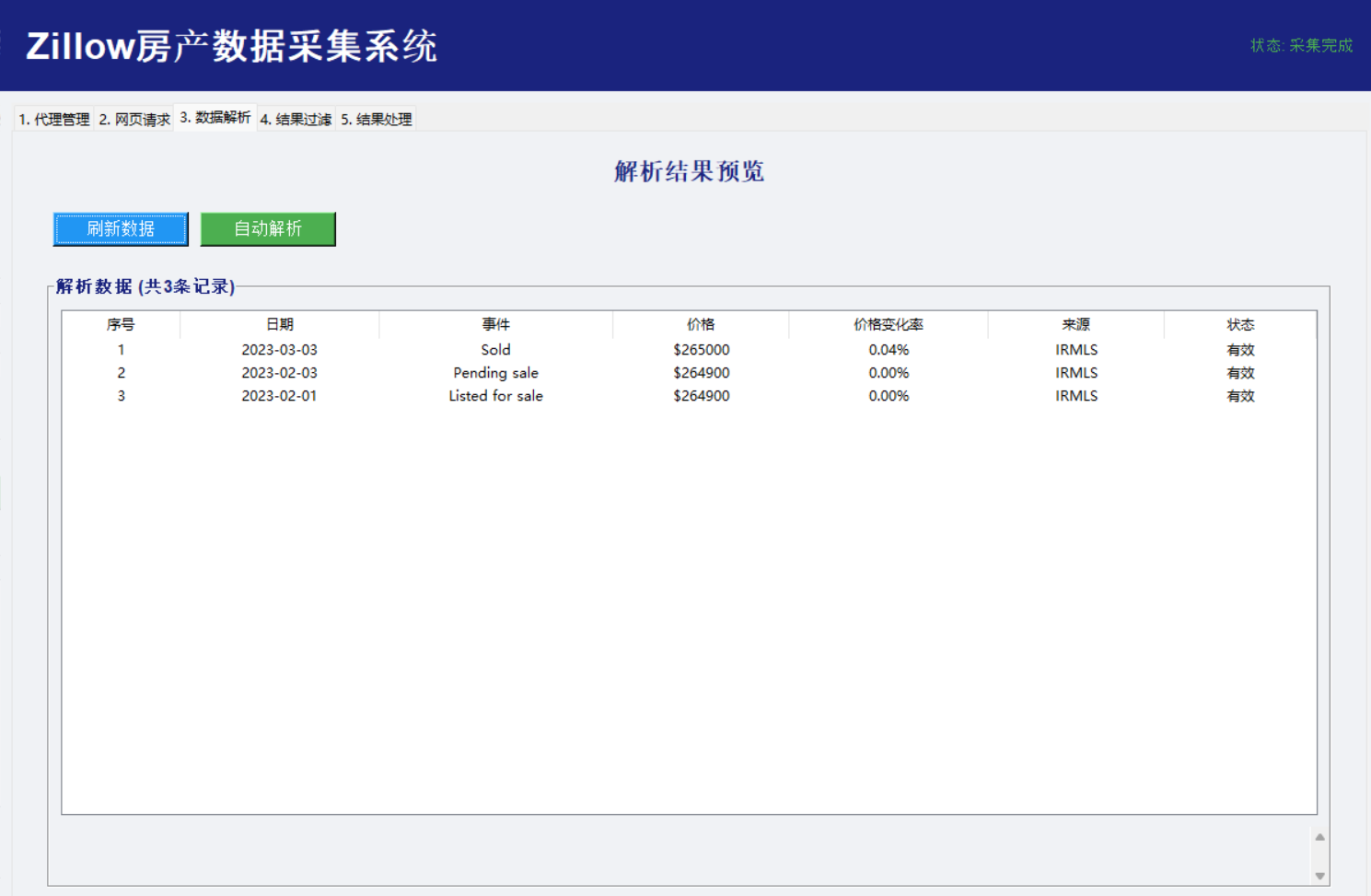
数据解析:

# Zillow数据解析器伪代码
class ZillowDataParser:
def __init__(self):
self.parsed_data = []
def extract_price_history(self, html_content):
"""从Zillow页面提取价格历史数据[citation:6]"""
# 方法1:从页面内嵌的JSON数据提取
price_history = self.extract_from_json_ld(html_content)
if price_history:
return price_history
# 方法2:从API响应提取
price_history = self.extract_from_api_data(html_content)
# 方法3:从页面元素提取(备选方案)
if not price_history:
price_history = self.extract_from_html_elements(html_content)
return price_history
def extract_from_json_ld(self, html):
"""从JSON-LD结构化数据提取"""
import re
import json
# 查找JSON-LD数据
pattern = r'<script type="application/ld\+json">(.*?)</script>'
matches = re.findall(pattern, html, re.DOTALL)
for match in matches:
try:
data = json.loads(match)
if '@type' in data and data['@type'] == 'SingleFamilyResidence':
return self.parse_json_ld_structure(data)
except:
continue
return None
def extract_from_api_data(self, html):
"""从Zillow的API响应数据提取[citation:6]"""
import re
import json
# 查找Zillow的Redux状态数据
pattern = r'window\.__PRELOADED_STATE__\s*=\s*({.*?});'
match = re.search(pattern, html, re.DOTALL)
if match:
try:
state_data = json.loads(match.group(1))
# 导航到价格历史数据
price_data = (state_data
.get('gdpClientCache', {})
.get('CachedHomeDetailQuery', {})
.get('property', {})
.get('priceHistory', []))
parsed_history = []
for event in price_data:
parsed_event = {
'date': event.get('date'),
'event': event.get('event'),
'price': event.get('price'),
'price_change_rate': event.get('priceChangeRate'),
'source': event.get('source'),
'posting_is_rental': event.get('isRental', False)
}
parsed_history.append(parsed_event)
return parsed_history
except Exception as e:
print(f"API数据解析错误: {e}")
return None
def parse_html_table_data(self, html):
"""表格化展示解析结果"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
# 查找价格历史表格
table = soup.find('table', {'data-test': 'price-history-table'})
if not table:
return []
rows = table.find_all('tr')[1:] # 跳过标题行
table_data = []
for row in rows:
cols = row.find_all('td')
if len(cols) >= 4:
row_data = {
'date': cols[0].text.strip(),
'event': cols[1].text.strip(),
'price': cols[2].text.strip(),
'source': cols[3].text.strip()
}
table_data.append(row_data)
return table_data
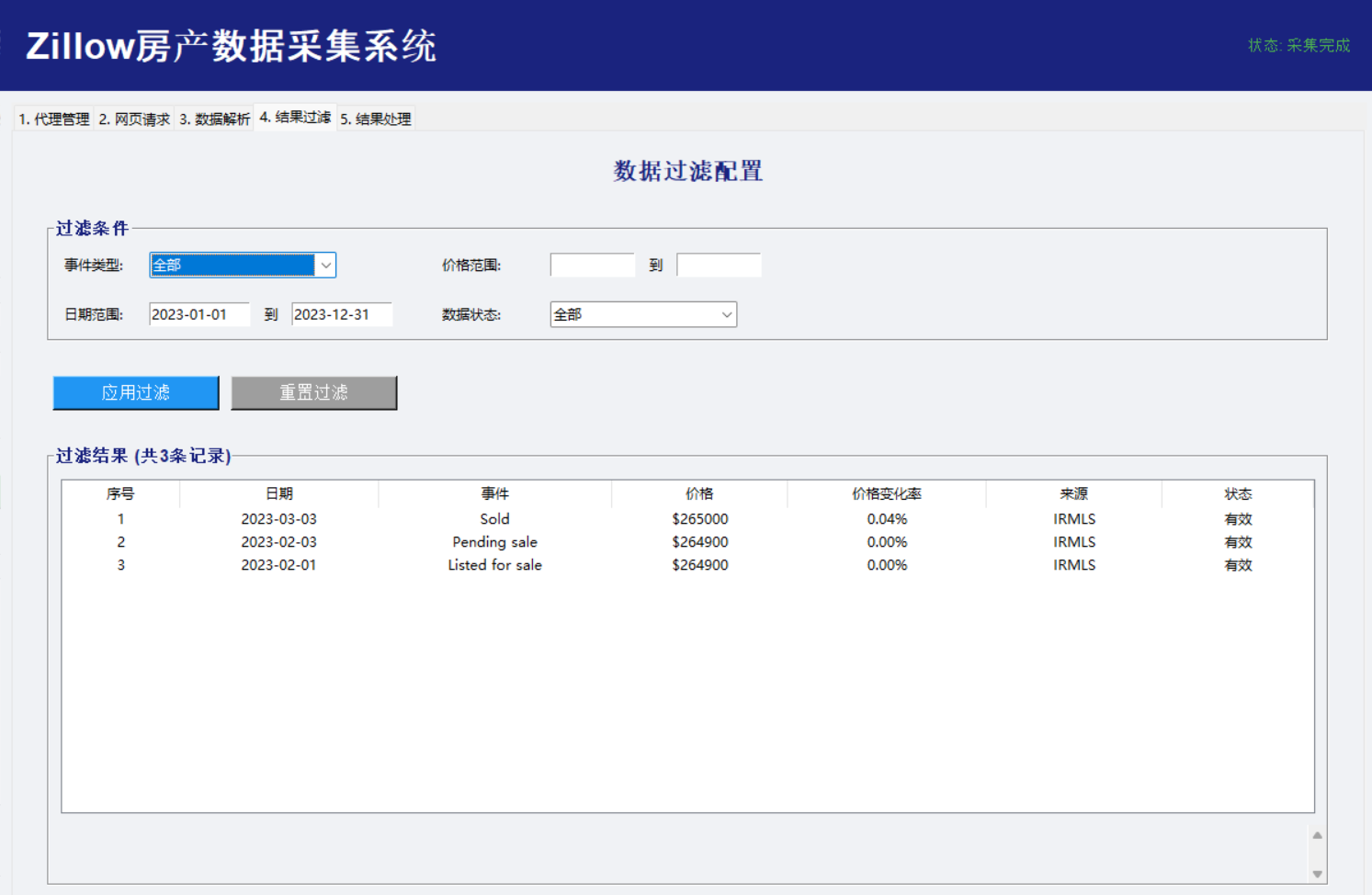
数据处理(筛选以及导出)

# 数据处理器伪代码
class DataProcessor:
def __init__(self, data_collection):
self.data = data_collection # 解析得到的数据集
def apply_filters(self, filters):
"""应用多条件过滤[citation:6]"""
filtered_data = self.data.copy()
# 事件类型过滤
if filters.get('event_type'):
filtered_data = [d for d in filtered_data
if d['event'] in filters['event_type']]
# 价格范围过滤
if filters.get('min_price') or filters.get('max_price'):
min_price = filters.get('min_price', 0)
max_price = filters.get('max_price', float('inf'))
filtered_data = [
d for d in filtered_data
if min_price <= self.parse_price(d['price']) <= max_price
]
# 日期范围过滤
if filters.get('start_date') or filters.get('end_date'):
start_date = pd.to_datetime(filters.get('start_date', '1900-01-01'))
end_date = pd.to_datetime(filters.get('end_date', '2100-01-01'))
filtered_data = [
d for d in filtered_data
if start_date <= pd.to_datetime(d['date']) <= end_date
]
# 数据状态过滤
if filters.get('data_status'):
status_filter = filters['data_status']
if status_filter == 'valid_only':
filtered_data = [d for d in filtered_data if not d.get('error')]
elif status_filter == 'error_only':
filtered_data = [d for d in filtered_data if d.get('error')]
return filtered_data
def export_to_multiple_formats(self, data, export_config):
"""多格式导出数据"""
export_results = {}
# CSV导出
if export_config.get('format') == 'csv' or 'all' in export_config.get('formats', []):
csv_path = self.export_to_csv(data, export_config.get('csv_options', {}))
export_results['csv'] = csv_path
# Excel导出
if export_config.get('format') == 'excel' or 'all' in export_config.get('formats', []):
excel_path = self.export_to_excel(data, export_config.get('excel_options', {}))
export_results['excel'] = excel_path
# JSON导出
if export_config.get('format') == 'json' or 'all' in export_config.get('formats', []):
json_path = self.export_to_json(data, export_config.get('json_options', {}))
export_results['json'] = json_path
# SQL导出
if export_config.get('format') == 'sql' or 'all' in export_config.get('formats', []):
sql_path = self.export_to_sql(data, export_config.get('sql_options', {}))
export_results['sql'] = sql_path
return export_results
def export_to_sql(self, data, options):
"""导出为SQL文件"""
table_name = options.get('table_name', 'zillow_price_history')
sql_content = f"""-- Zillow价格历史数据导出
-- 生成时间: {datetime.now()}
-- 记录数: {len(data)}
CREATE TABLE IF NOT EXISTS {table_name} (
id INTEGER PRIMARY KEY AUTOINCREMENT,
zpid TEXT,
date TEXT,
event TEXT,
price REAL,
price_change_rate REAL,
price_per_squarefoot REAL,
source TEXT,
posting_is_rental BOOLEAN,
timestamp TEXT,
url TEXT
);
"""
for record in data:
# 构建INSERT语句
columns = ['zpid', 'date', 'event', 'price', 'price_change_rate',
'price_per_squarefoot', 'source', 'posting_is_rental',
'timestamp', 'url']
values = []
for col in columns:
val = record.get(col, 'NULL')
if isinstance(val, str):
val = f"'{val.replace("'", "''")}'"
elif val is None:
val = 'NULL'
values.append(str(val))
sql_content += f"INSERT INTO {table_name} ({', '.join(columns)}) "
sql_content += f"VALUES ({', '.join(values)});\n"
# 保存SQL文件
filename = options.get('filename', f'zillow_export_{datetime.now().strftime("%Y%m%d_%H%M%S")}.sql')
with open(filename, 'w', encoding='utf-8') as f:
f.write(sql_content)
return filename
def analyze_data_statistics(self, data):
"""数据分析统计"""
if not data:
return {}
df = pd.DataFrame(data)
stats = {
'total_records': len(df),
'date_range': {
'start': df['date'].min(),
'end': df['date'].max()
},
'price_statistics': {
'min': df['price'].min(),
'max': df['price'].max(),
'average': df['price'].mean(),
'median': df['price'].median()
},
'event_distribution': df['event'].value_counts().to_dict(),
'source_distribution': df['source'].value_counts().to_dict(),
'data_quality': {
'valid_records': len(df[df['error'].isna()]),
'error_records': len(df[df['error'].notna()])
}
}
return stats
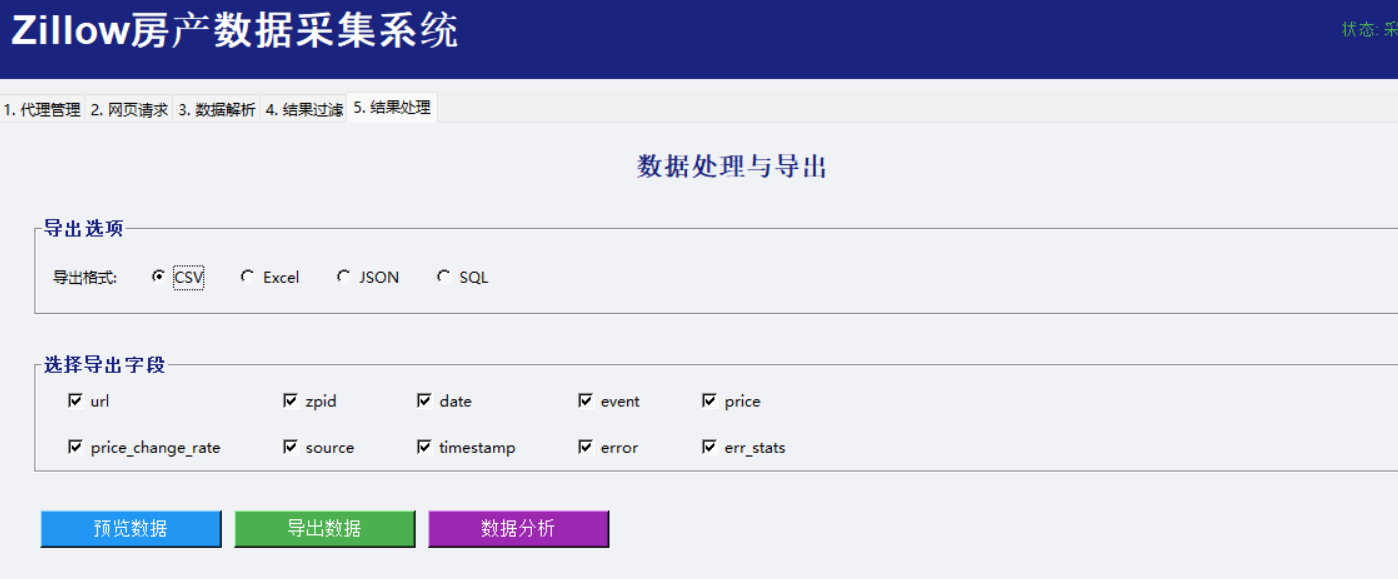
五、 进阶路径:更便捷的数据获取方式
网页抓取API

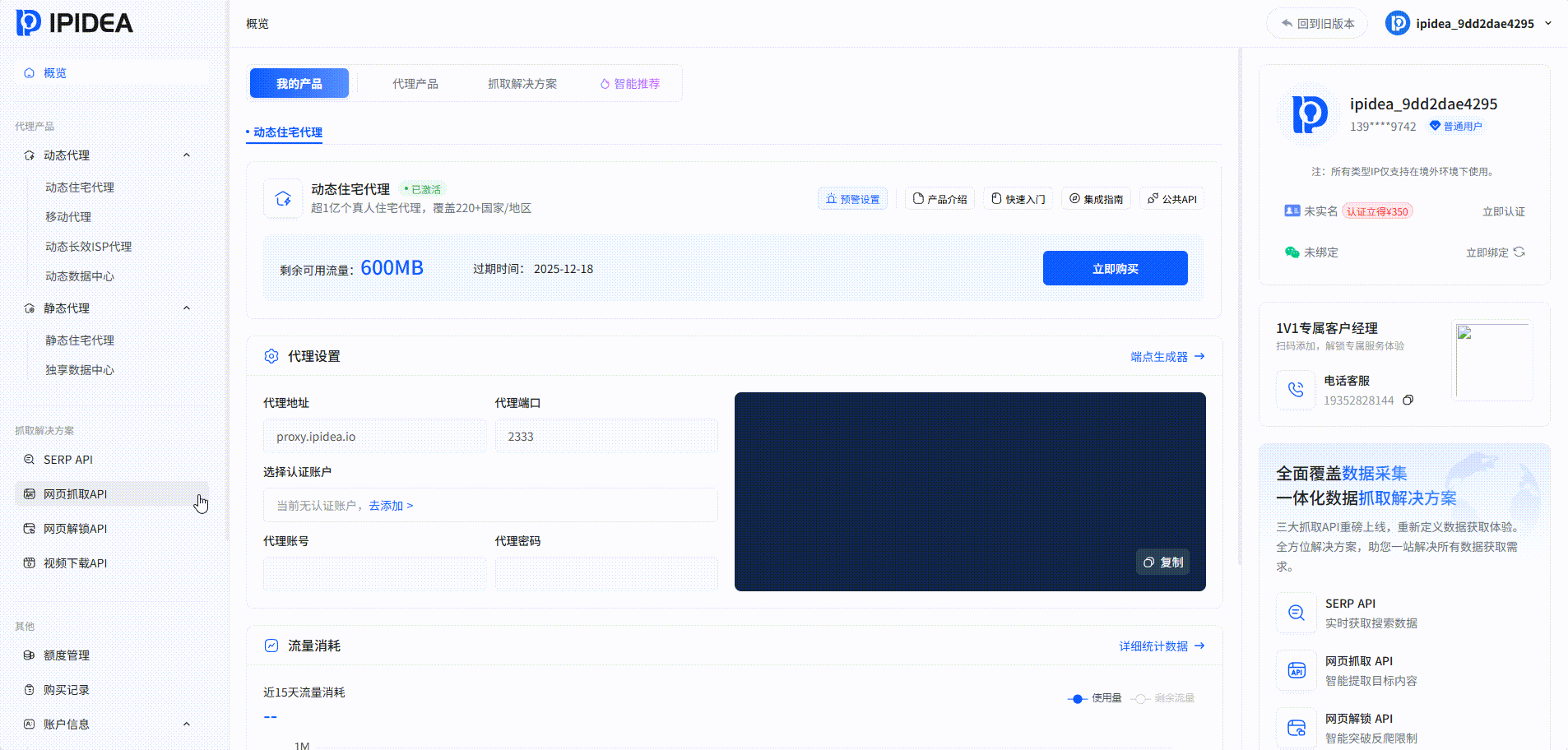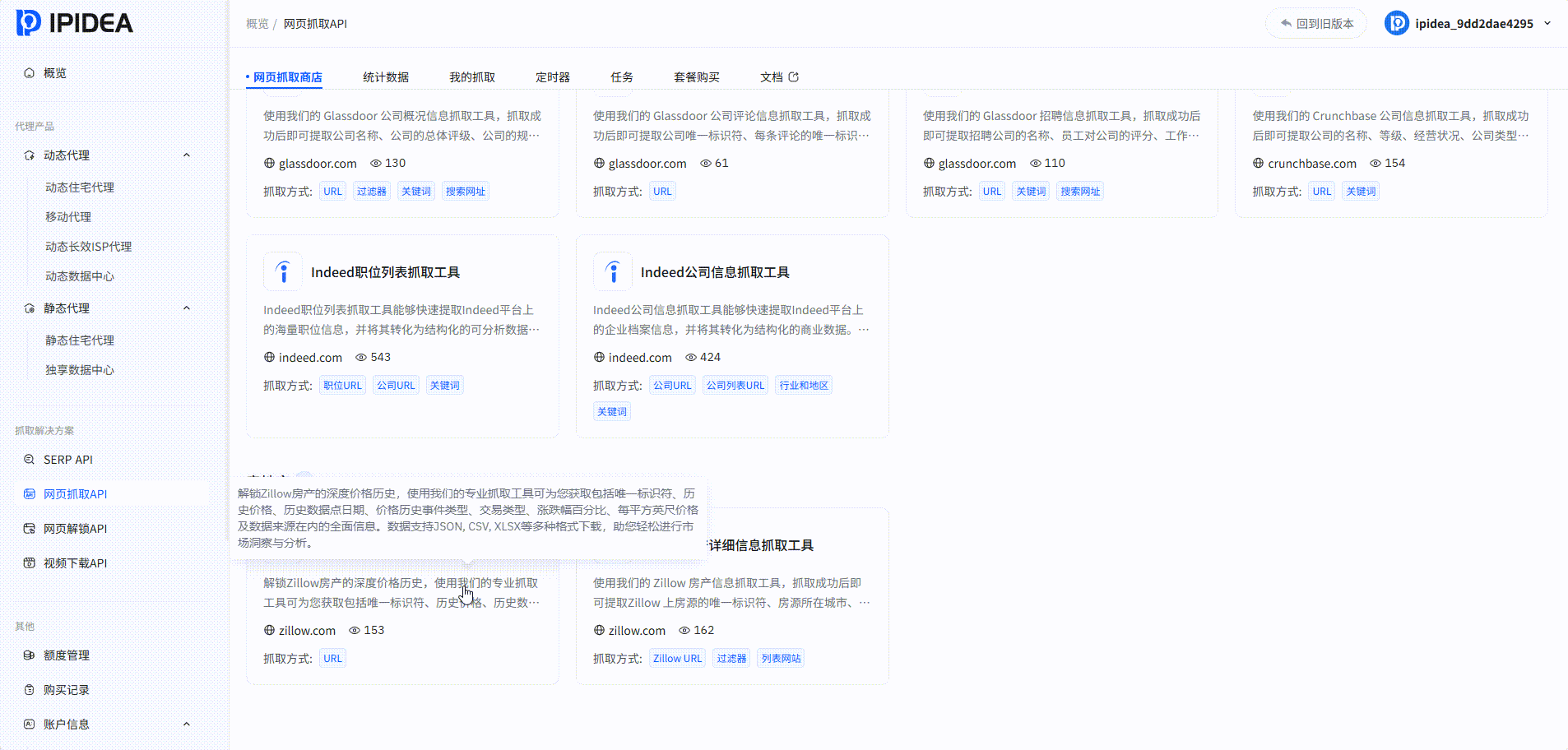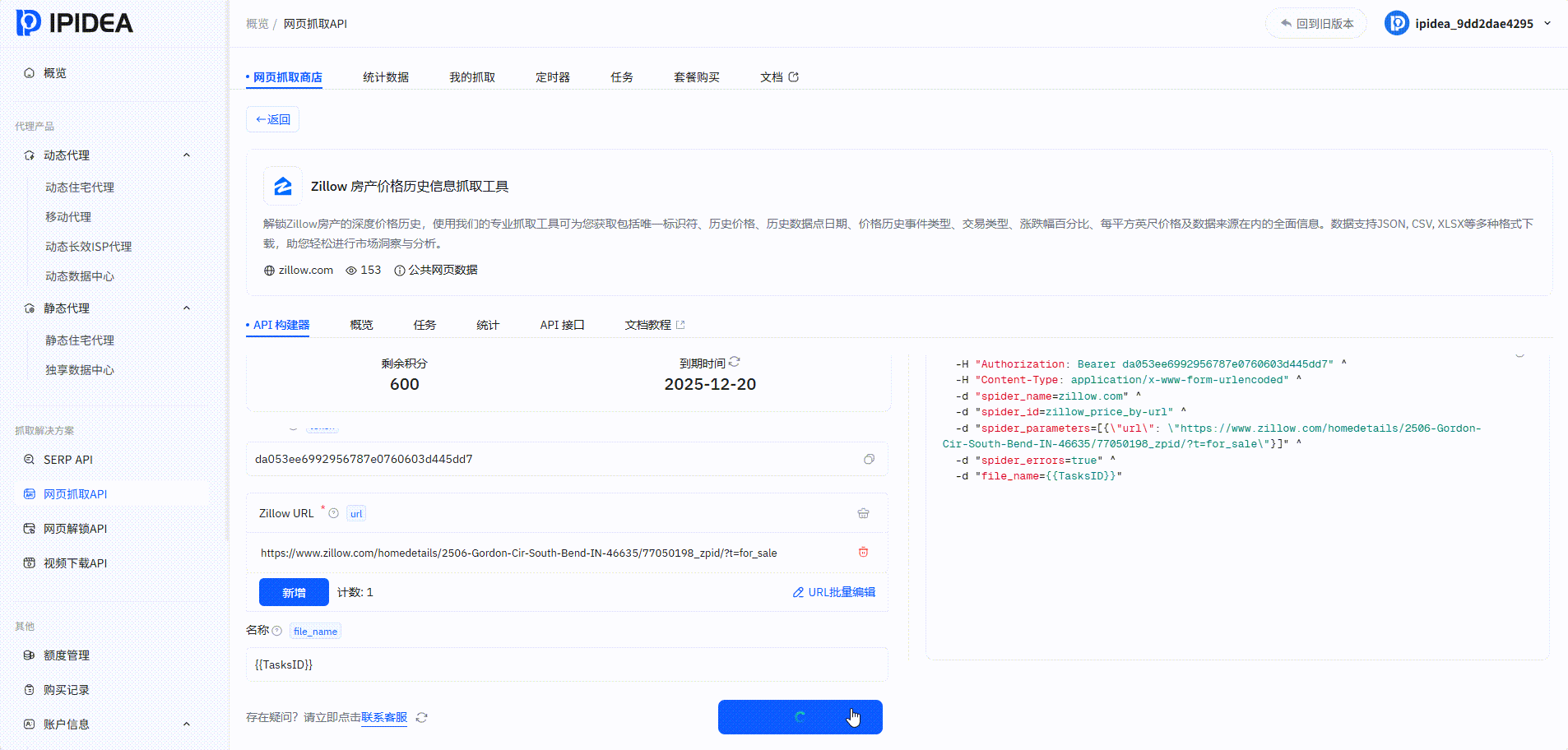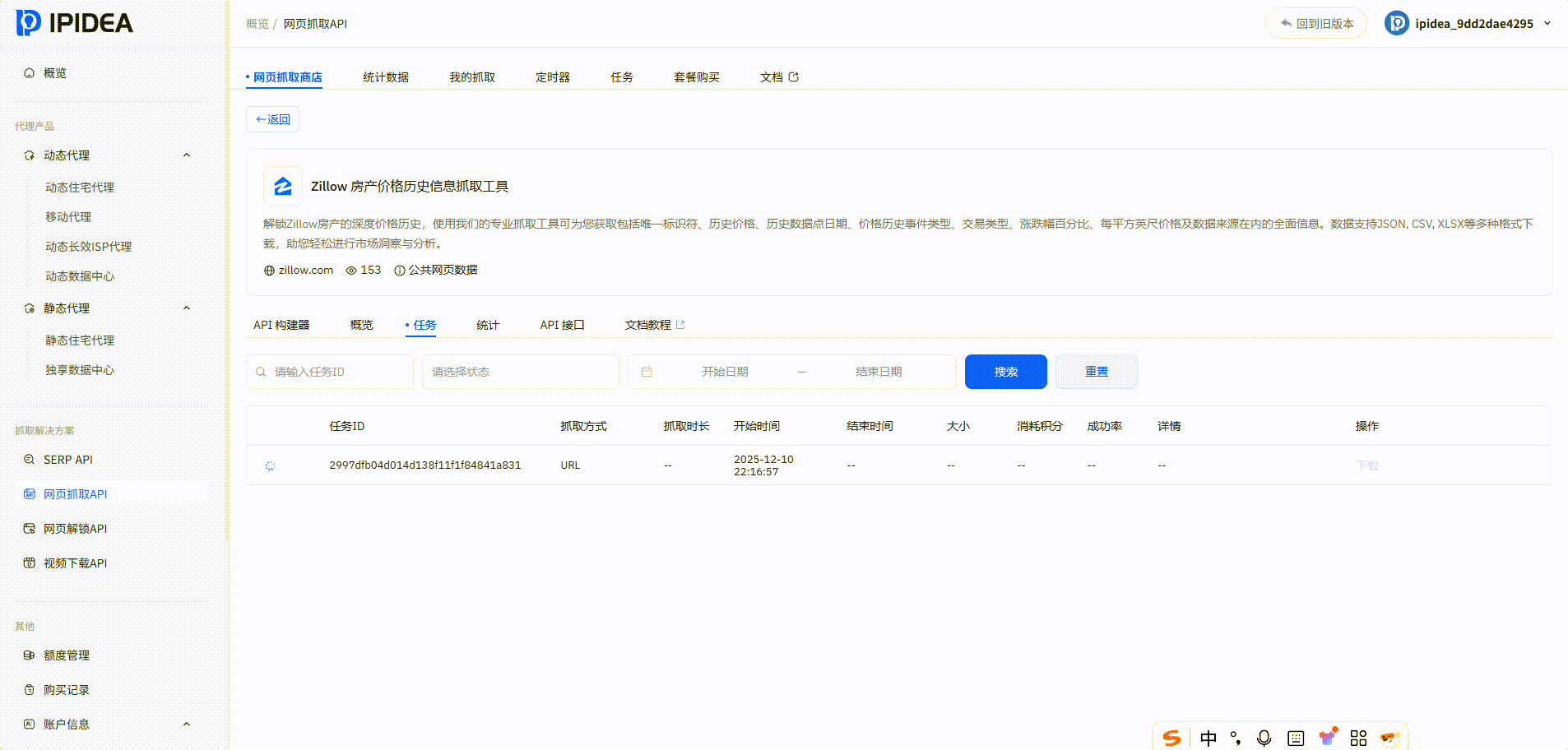

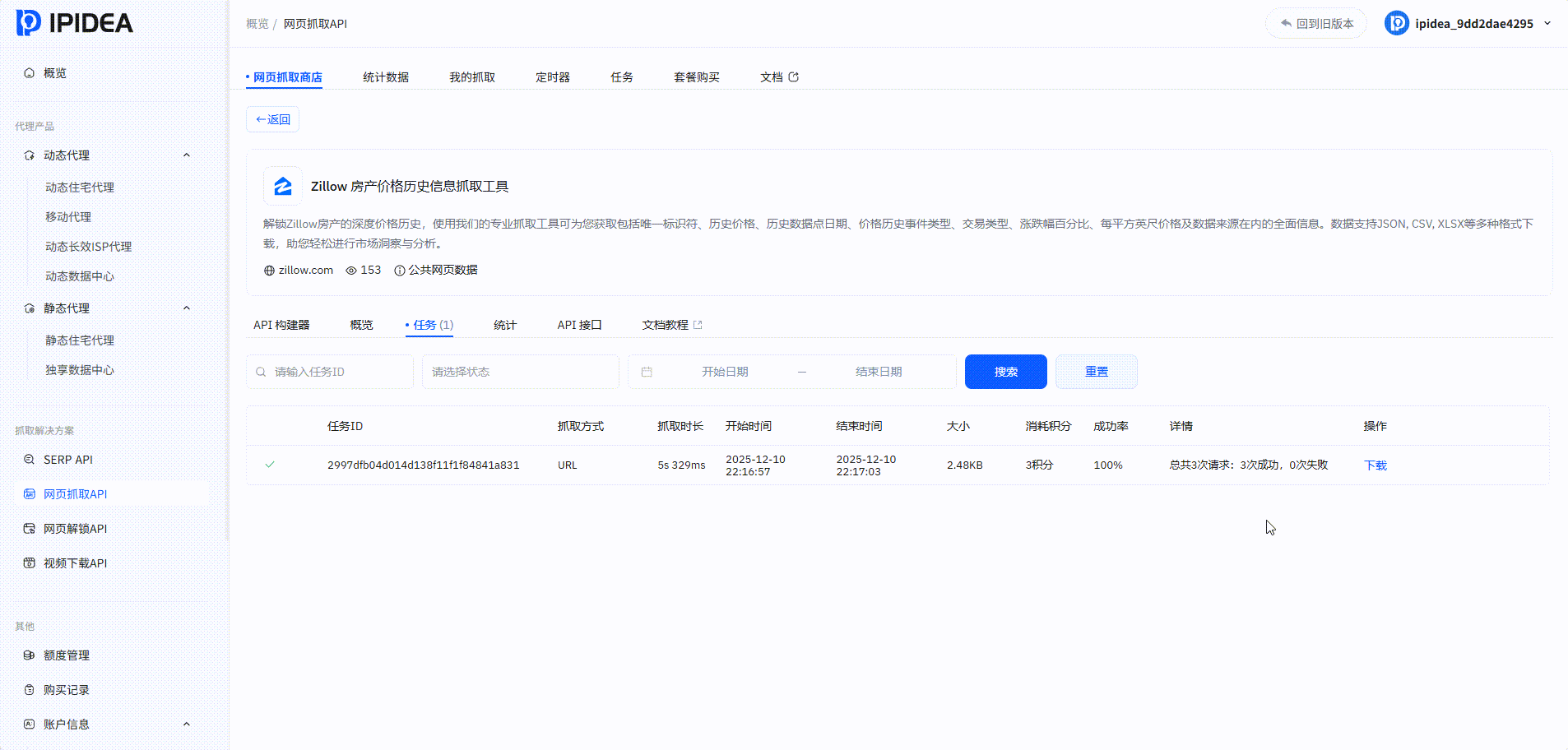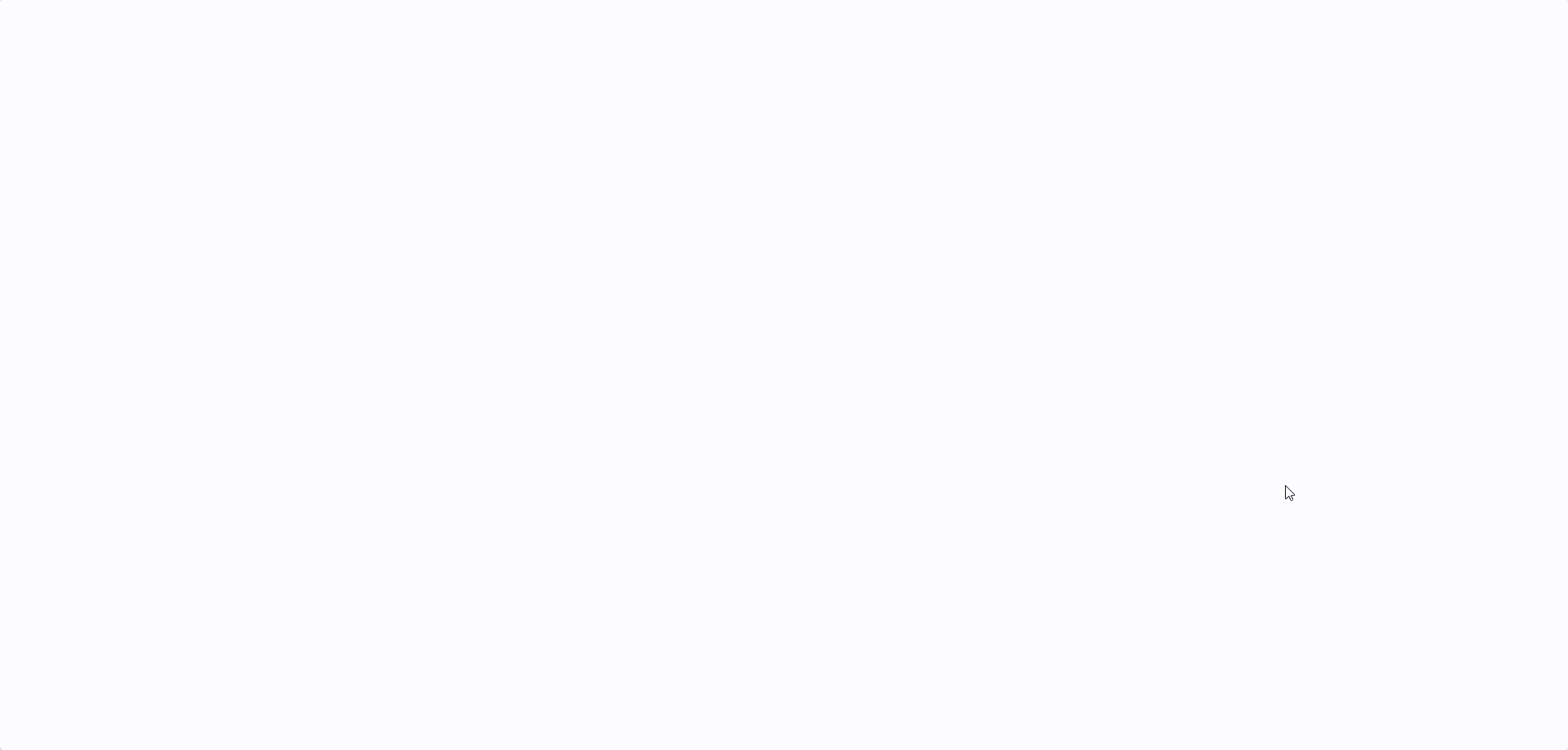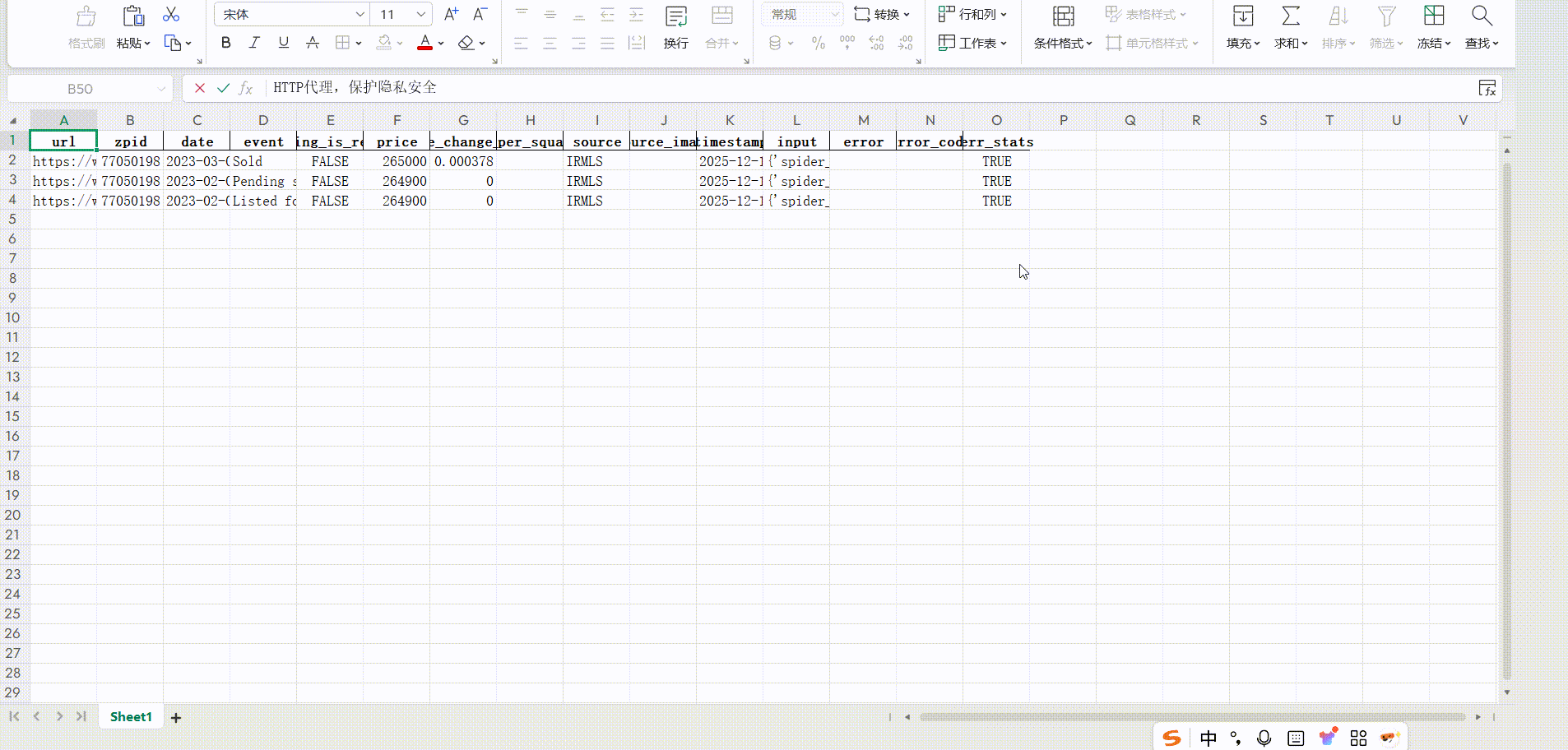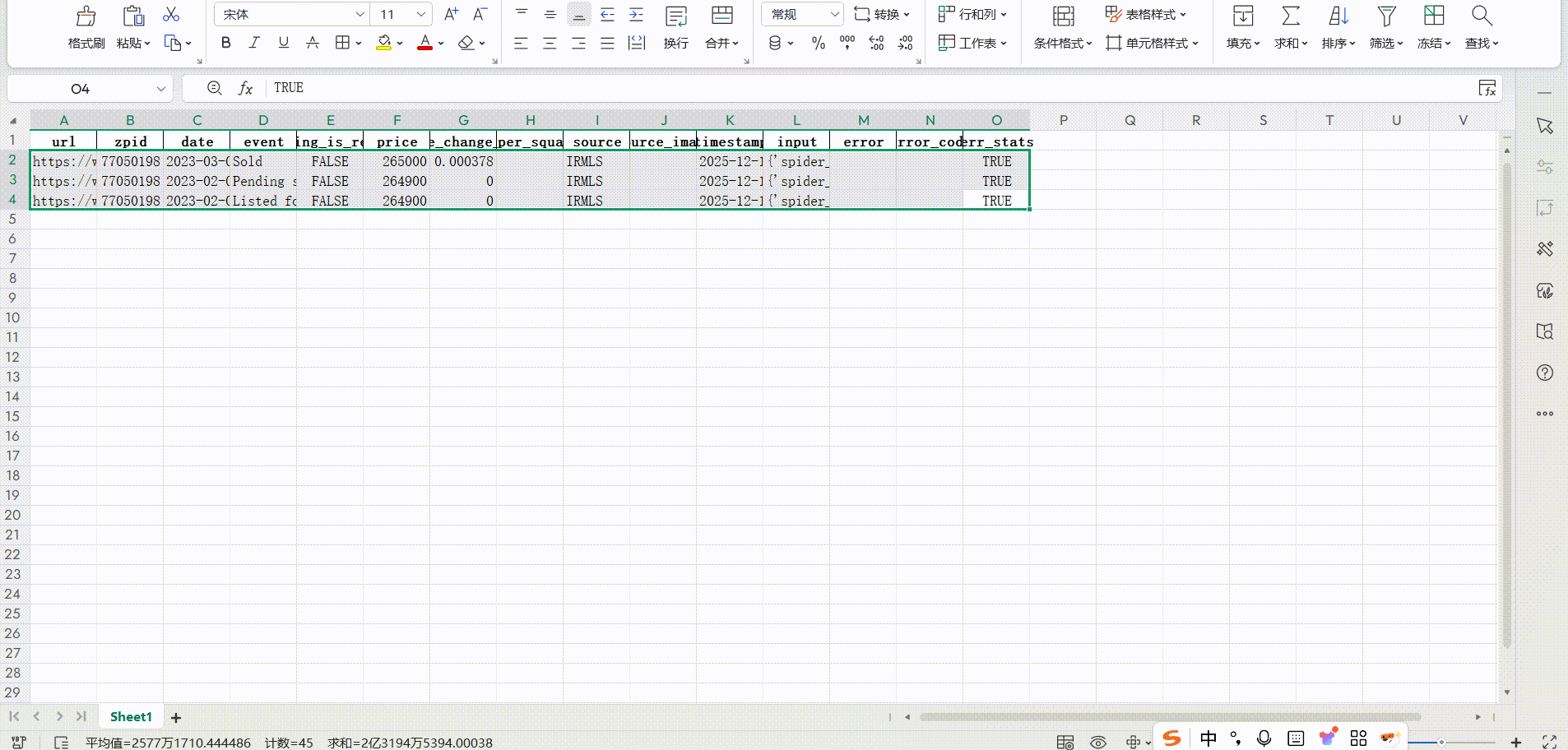
其他热门抓取工具实测:
SERP API:

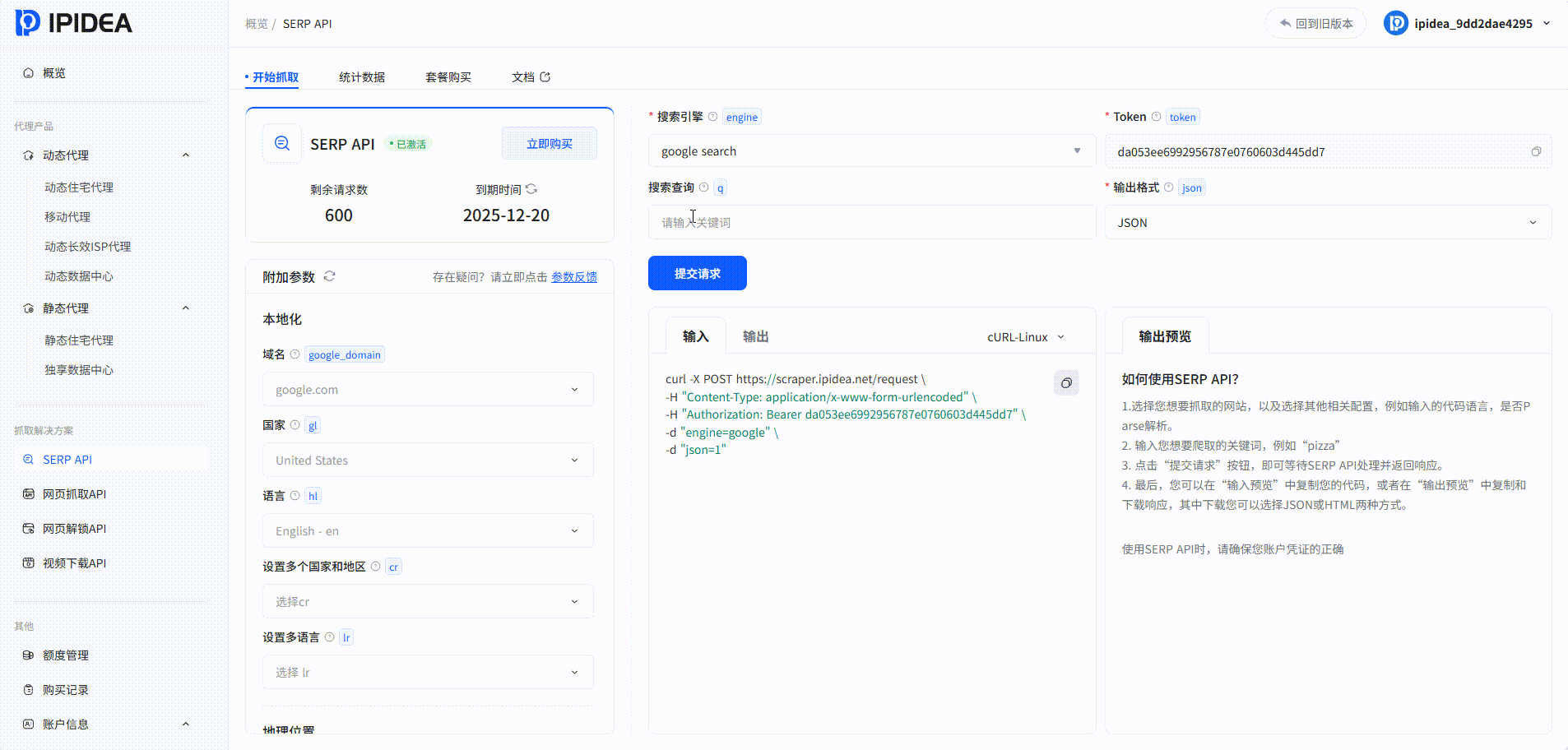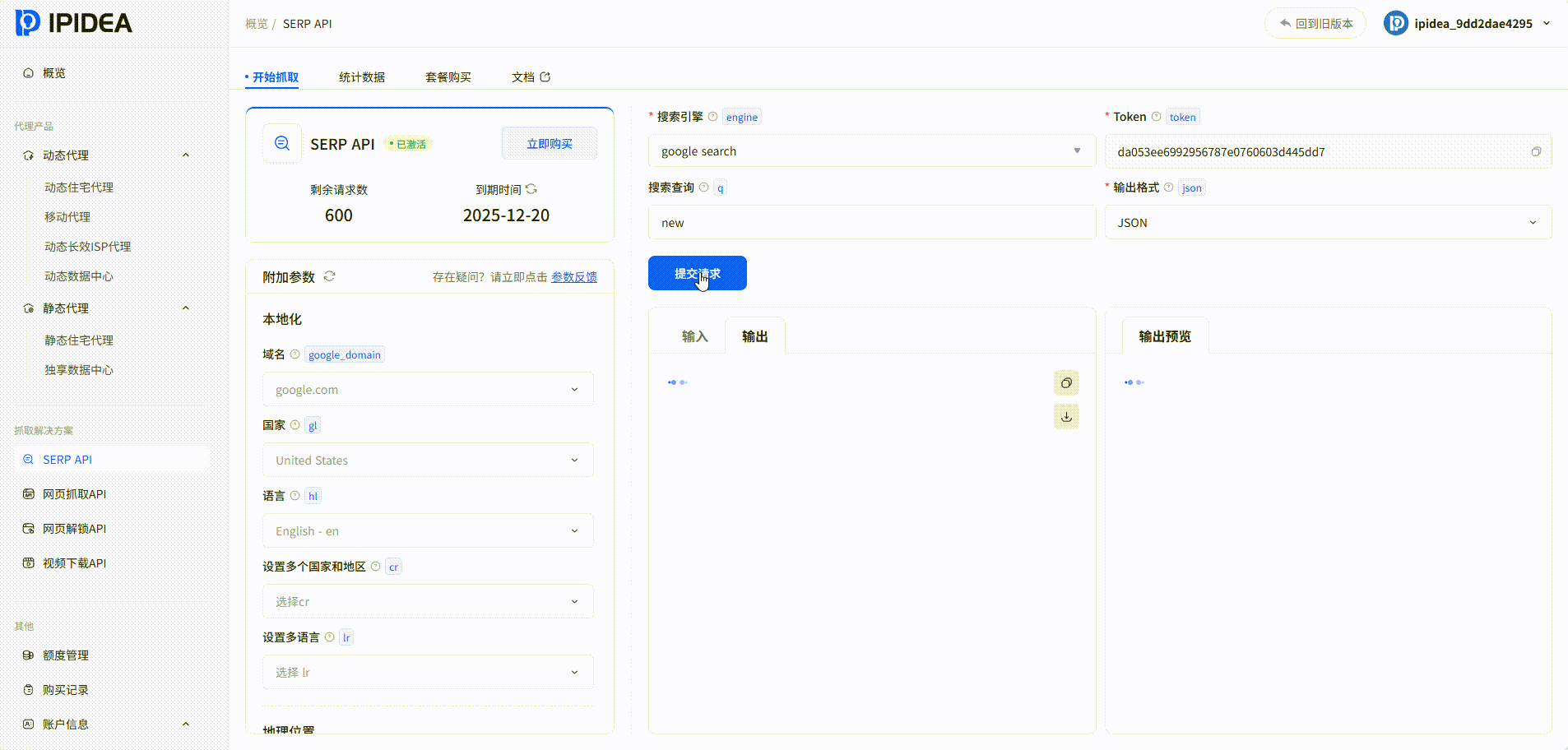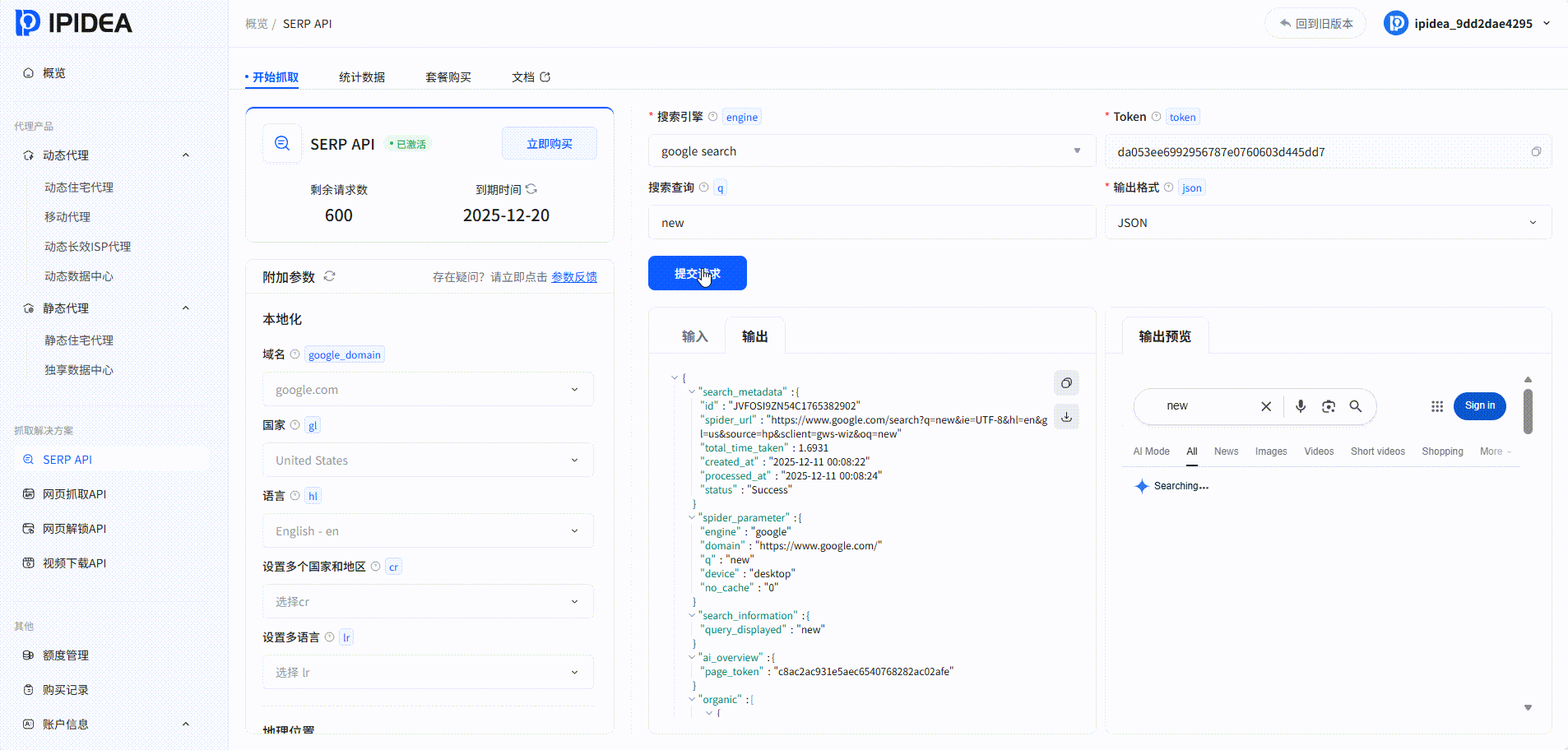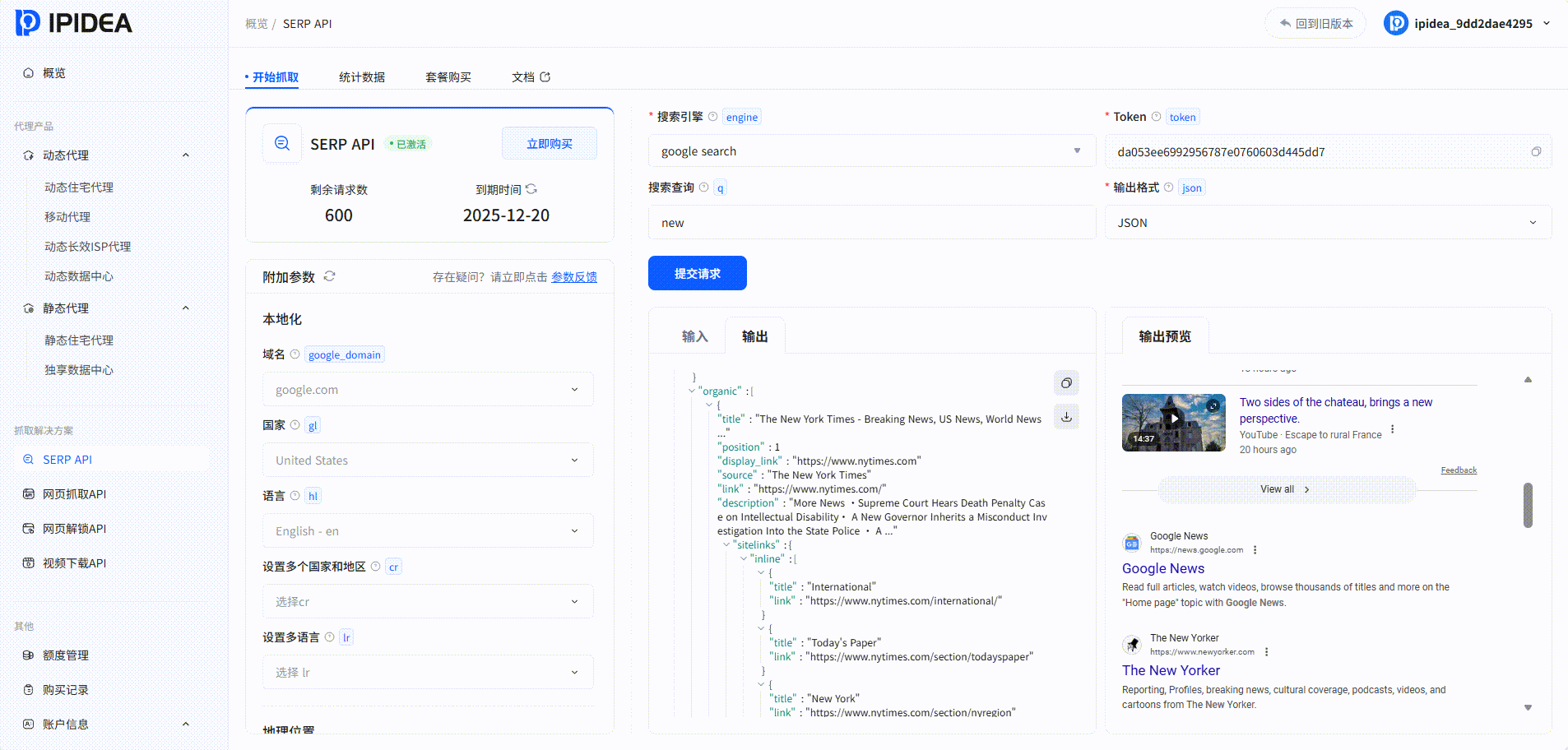
系统中的爬取结果:
| 成功率 | 搜索结果 | 平均总耗时(s) |
|---|---|---|
| 100% | JSON/HTML | 5.54s |
| 100% | JSON/HTML | 5.52s |
视频下载API

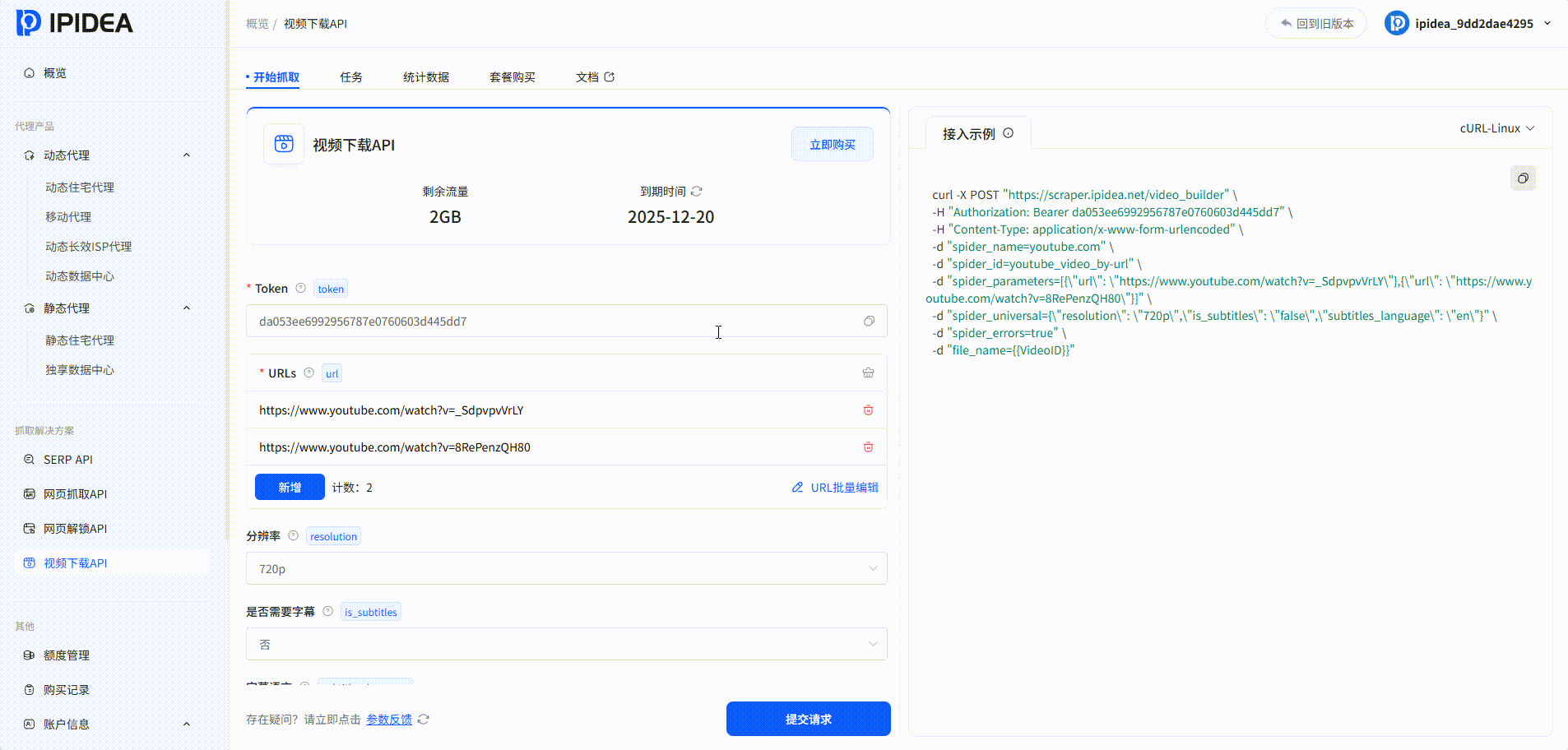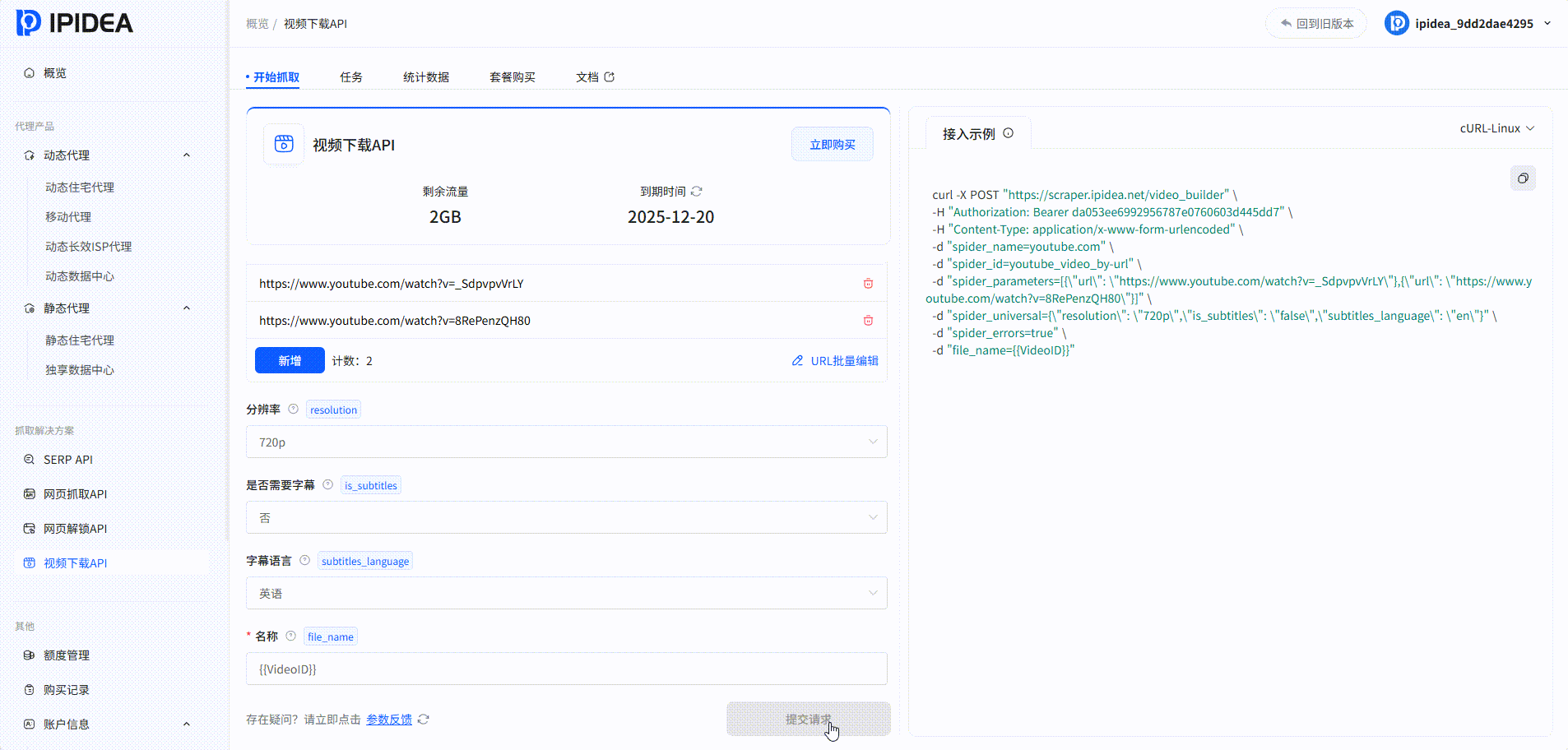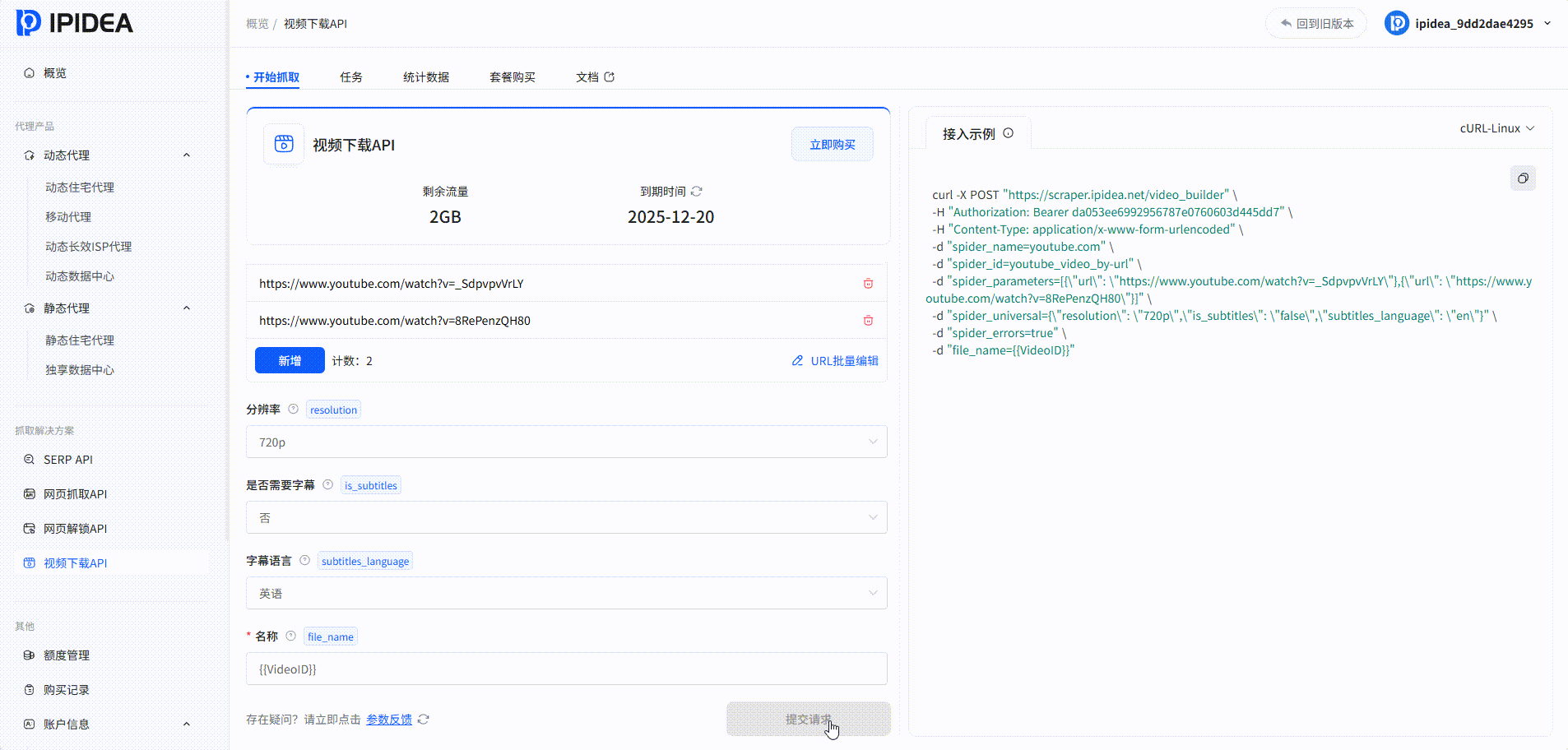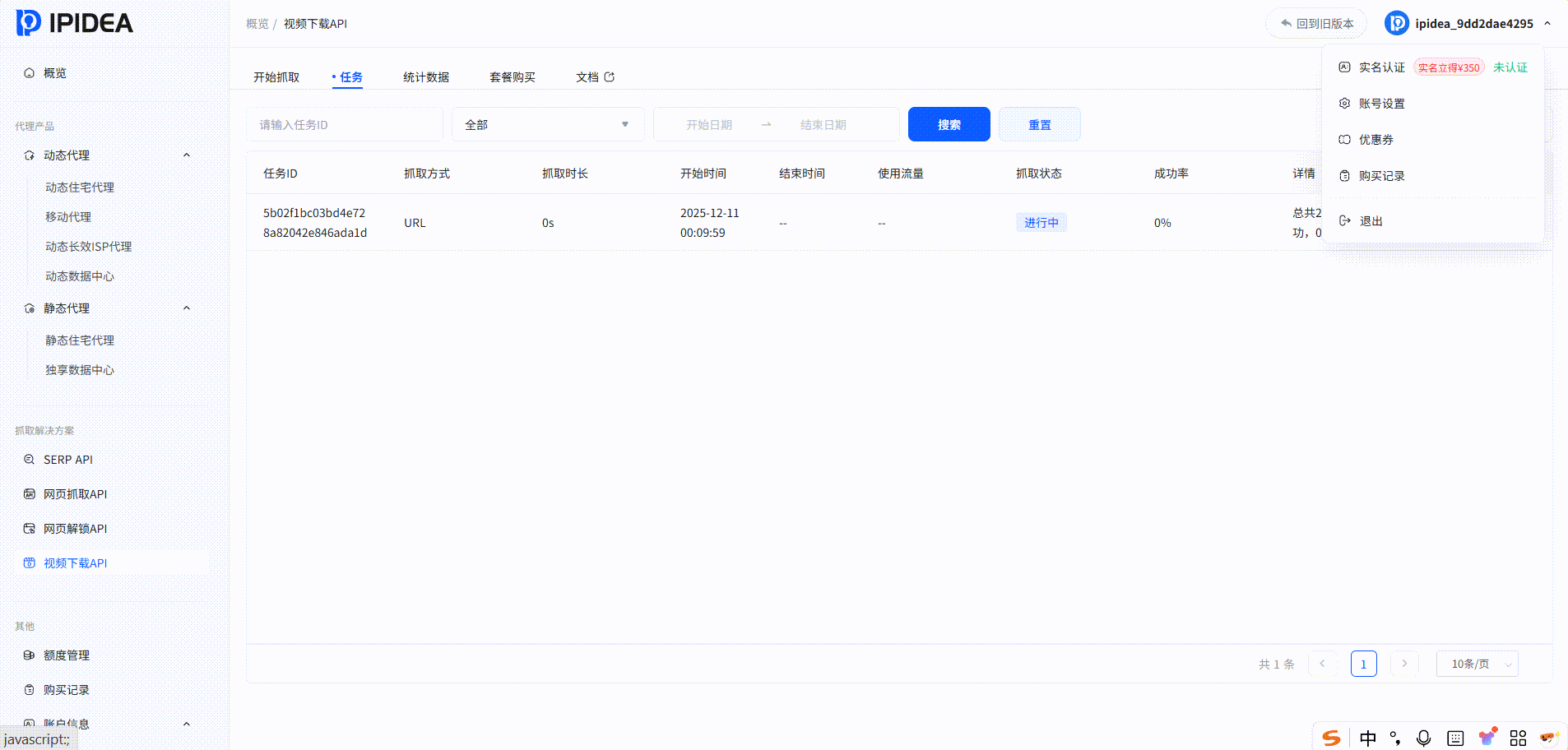

系统中的爬取结果:
| 成功率 | 搜索结果 | 平均总耗时(s) |
|---|---|---|
| 100% | 视频URL | 7m 20s |
| 100% | 视频URL | 7m 29s |
六、 总结:IPIDEA——助力合规获取Zillow数据价值的可靠工具





























 255
255



 到【灌水乐园】发言
到【灌水乐园】发言









