




 本文介绍了多模态学习如何从人类学习中汲取灵感,特别是视觉语言模型(VLM)的发展,如在图像和文本处理中的应用。文章详细讲述了如何使用ComfyUI-Dream-Interpreter部署全景梦境解析器,涉及多个模型的安装和运行流程。
本文介绍了多模态学习如何从人类学习中汲取灵感,特别是视觉语言模型(VLM)的发展,如在图像和文本处理中的应用。文章详细讲述了如何使用ComfyUI-Dream-Interpreter部署全景梦境解析器,涉及多个模型的安装和运行流程。
人类学习本质上是多模态 (multi-modal) 的,因为联合利用多种感官有助于我们更好地理解和分析新信息。理所当然地,多模态学习的最新进展即是从这一人类学习过程的有效性中汲取灵感,创建可以利用图像、视频、文本、音频、肢体语言、面部表情和生理信号等各种模态信息来处理和链接信息的模型。随着自然语言处理和计算机视觉的交叉融合,视觉-语言模型(VLM)已成为一个热门的研究领域。
视觉语言模型 (VLM) 采用多模态架构,可同时处理图像和文本数据。他们可以执行视觉问答 (VQA)、图像标题和文本到图像搜索类型的任务。VLM 利用多模态融合与交叉注意力、掩码语言建模和图像文本匹配等技术将视觉语义与文本表示相关联。此存储库包含有关著名视觉语言模型 (VLM) 的信息,包括有关其架构、训练过程和用于训练的数据集的详细信息。单击以展开以了解每种架构的更多详细信息。
接下来我们使用ComfyUI-Dream-Interpreter搭建一个全景的梦境解析器,话不多说,下面开始部署:
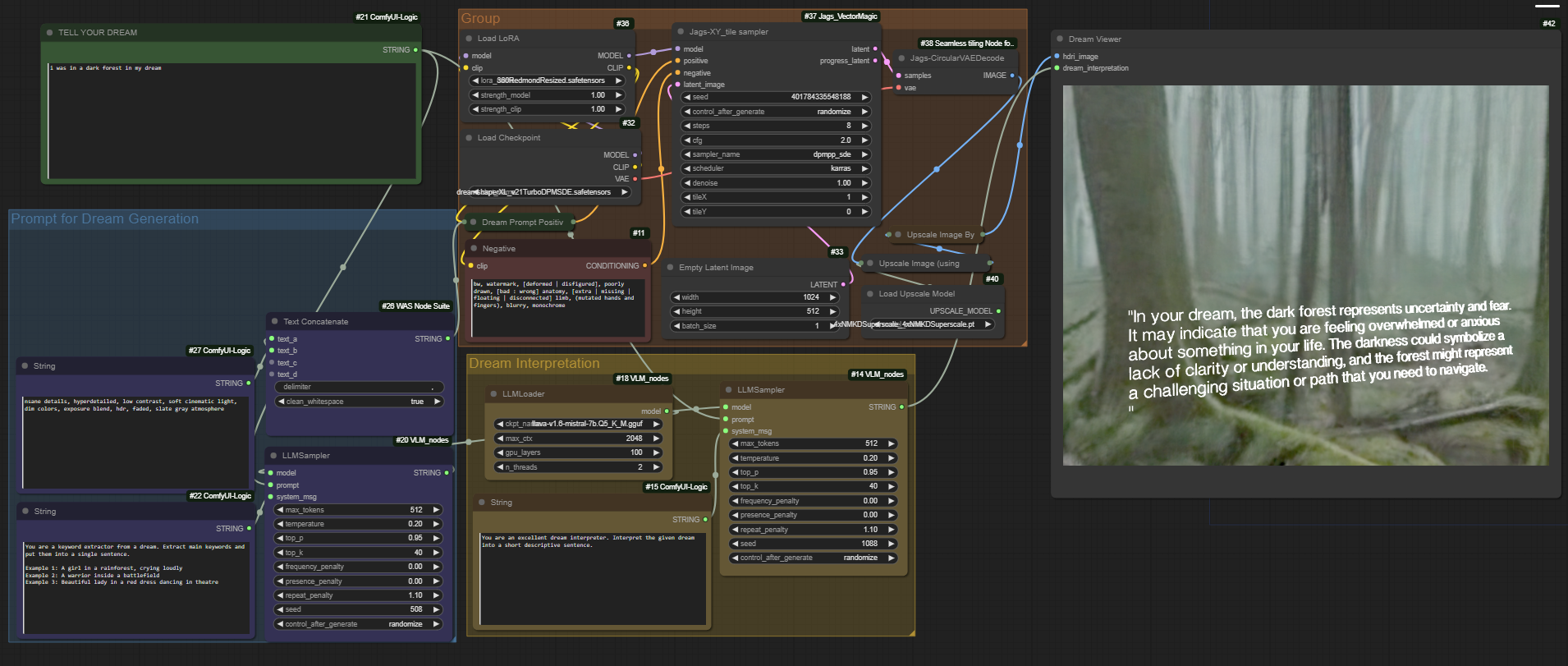
一:安装ComfyUI的三个节点插件
git clone https://github.com/gokayfem/ComfyUI-Dream-Interpreter.git
git clone https://github.com/gokayfem/ComfyUI_VLM_nodes.git
git clone https://github.com/jags111/ComfyUI_Jags_VectorMagic.git
二:下载工作流
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











