



先掌握pytorch,学好pytorch, 才能学好人工智能
名词解释
卷积Convolution 运算
是一种常用的图像处理方法,通过卷积核在输入信号(图像)上滑动并进行乘加操作,从而实现对图像的滤波和特征提取。
卷积核
是卷积神经网络中的一个重要概念,也称为滤波器、过滤器。它可以看作是一种模式、一种特征。在卷积神经网络中,卷积核通过滑动窗口的方式与输入图像进行卷积操作,从而提取输入图像中的各种特征。
卷积核由一组权重组成,这些权重可以被学习和调整以最好地提取输入图像中的特征。例如,一个卷积核可以用来检测边缘特征,通过对输入图像进行卷积操作,可以得到一个表示图像中边缘分布情况的特征图。
卷积神经网络中通常会使用多个不同的卷积核,每个卷积核可以提取不同的特征,这些特征可以进一步用于下游任务,例如图像分类、目标检测等。通过学习合适的卷积核权重,卷积神经网络可以自动学习到适合当前任务的特征表示,从而提高模型的性能。
在卷积运算中,卷积核可以看作是一组数字,这些数字定义了一种模式或特征。卷积核的大小一般比输入信号小,并且通常是一个奇数,例如3x3、5x5等。卷积核的值决定了在卷积运算中的权重,不同的权重可以提取不同的特征。
卷积运算的过程
- 将卷积核的中心位置与输入信号的某个像素点对齐。
- 在对齐位置,将卷积核上的每个元素与对应的输入信号像素点相乘。
- 将所有乘积的结果相加,得到卷积运算的输出结果。
- 将卷积核在输入信号上滑动,重复上述操作直至覆盖完整个输入信号。
卷积运算可以用于很多图像处理任务,例如边缘检测、模糊、锐化、特征识别等。通过调整卷积核的权重和形状,可以得到不同的效果和特征提取结果。
说明
一、卷积层在卷积神经网络中的重要性
卷积层是卷积神经网络(CNN)的核心组成部分,具有以下重要作用:
- 特征提取:通过卷积操作自动从输入数据中学习和提取特征。不同的卷积核可以检测不同的特征,如边缘、纹理、形状等。这使得网络能够以一种高效的方式对图像、音频、文本等各种类型的数据进行处理,而无需手动设计复杂的特征提取器。
- 参数共享:在卷积操作中,同一卷积核在不同位置上重复使用,大大减少了模型的参数数量。这不仅降低了计算成本,还提高了模型的泛化能力,减少了过拟合的风险。
- 局部连接:卷积层只对输入数据的局部区域进行连接,这使得网络能够捕捉局部的模式和结构。对于图像等具有空间结构的数据,局部连接能够有效地利用空间信息,同时减少了对全局信息的依赖,提高了模型的效率和鲁棒性。
二、卷积操作的过程与步骤
-
二维卷积(以图像为例):
- 输入是一个二维的图像矩阵,通常具有宽度、高度和通道数三个维度。例如,对于一张彩色图像,其输入形状可以表示为(高度,宽度,通道数)。
- 卷积核是一个较小的二维矩阵,通常具有宽度和高度两个维度,并且与输入图像的通道数相同。例如,对于一个 3x3 的卷积核,其形状可以表示为(3,3,通道数)。
- 卷积操作的过程如下:
- 将卷积核在输入图像上逐像素移动,从左上角开始,每次移动一个像素。
- 在每个位置上,将卷积核与输入图像对应位置的局部区域进行元素级乘法,然后将乘积相加,得到一个输出值。
- 重复这个过程,直到卷积核遍历完整个输入图像,得到一个输出特征图。
- 输出特征图的形状取决于输入图像的形状、卷积核的大小和卷积操作的步长等因素。一般来说,输出特征图的宽度和高度会比输入图像小,通道数与卷积核的数量相同。
-
一维卷积(以时间序列数据为例):
- 输入是一个一维的时间序列数据,例如音频信号或文本序列。
- 卷积核是一个较小的一维向量。
- 卷积操作的过程与二维卷积类似,将卷积核在输入数据上逐元素移动,进行元素级乘法和求和,得到输出值。
- 输出特征图是一个一维的向量,其长度取决于输入数据的长度、卷积核的大小和卷积操作的步长等因素。
-
三维卷积(以视频数据为例):
- 输入是一个三维的视频数据,具有宽度、高度、时间和通道数四个维度。
- 卷积核是一个三维的矩阵,具有宽度、高度和时间三个维度,并且与输入视频的通道数相同。
- 卷积操作的过程与二维卷积类似,将卷积核在输入视频上逐体素移动,进行元素级乘法和求和,得到输出值。
- 输出特征图是一个三维的矩阵,其形状取决于输入视频的形状、卷积核的大小和卷积操作的步长等因素。
三、区分一维 / 二维 / 三维卷积
-
输入数据维度:
- 一维卷积的输入数据是一维的,例如时间序列数据或文本序列。
- 二维卷积的输入数据是二维的,例如图像数据。
- 三维卷积的输入数据是三维的,例如视频数据。
-
卷积核维度:
- 一维卷积核是一维的向量。
- 二维卷积核是二维的矩阵。
- 三维卷积核是三维的矩阵。
-
应用场景:
- 一维卷积通常用于处理时间序列数据或文本序列,例如音频信号处理、自然语言处理等。
- 二维卷积主要用于处理图像数据,例如图像分类、目标检测等。
- 三维卷积适用于处理视频数据,例如视频分类、动作识别等。
四、转置卷积(Transpose Convolution)的由来以及实现方法
-
由来:
- 在卷积神经网络中,卷积操作通常会降低输入数据的空间维度,例如通过多次卷积和池化操作,图像的尺寸会逐渐减小。然而,在一些任务中,需要将低维的特征图恢复到高维的空间,例如在图像生成、超分辨率等任务中。
- 转置卷积就是为了解决这个问题而提出的,它也被称为反卷积或逆卷积。转置卷积可以看作是卷积操作的逆过程,通过在输入特征图上进行上采样,得到一个高维的输出特征图。
-
实现方法:
- 转置卷积的实现方法与卷积操作类似,但是需要对卷积核进行转置。具体来说,转置卷积的过程如下:
- 将输入特征图进行填充,通常是在边缘填充零,以增加特征图的尺寸。
- 将转置后的卷积核在填充后的输入特征图上逐像素移动,进行元素级乘法,然后将乘积相加,得到输出值。
- 重复这个过程,直到卷积核遍历完整个输入特征图,得到一个输出特征图。
- 输出特征图的形状取决于输入特征图的形状、卷积核的大小和转置卷积的步长等因素。一般来说,输出特征图的宽度和高度会比输入特征图大,通道数与卷积核的数量相同。
- 转置卷积的实现方法与卷积操作类似,但是需要对卷积核进行转置。具体来说,转置卷积的过程如下:
nn.Conv2d
一、主要参数
in_channels:输入图像的通道数。例如,对于彩色图像,通道数为 3(RGB)。out_channels:输出特征图的通道数,即卷积核的数量。每个卷积核会生成一个独立的特征图。kernel_size:卷积核的大小,可以是一个整数表示正方形卷积核的边长,也可以是一个元组(h, w)表示高度和宽度不同的卷积核。stride:卷积的步长,控制卷积核在输入图像上移动的步长。默认值为 1。padding:填充的大小,可以是一个整数表示在输入图像的四周均匀填充相同数量的像素,也可以是一个元组(pad_h, pad_w)表示在高度和宽度方向上分别填充不同数量的像素。默认值为 0。dilation:膨胀系数,用于控制卷积核之间的间隔。默认值为 1。groups:分组卷积的参数,控制输入和输出通道之间的连接方式。默认值为 1,表示普通卷积。bias:是否添加偏置项。默认值为True。
二、工作原理
- 输入图像经过卷积层时,每个卷积核与输入图像的局部区域进行卷积操作。卷积核在输入图像上滑动,对每个局部区域进行元素级乘法和求和,得到输出特征图中的一个像素值。
- 不同的卷积核可以学习到不同的特征,因此输出特征图的通道数等于卷积核的数量。
- 通过调整卷积层的参数,可以控制输出特征图的大小、特征提取的方式以及模型的复杂度。
三、示例用法
以下是一个使用nn.Conv2d的简单示例:
import torch
import torch.nn as nn
# 创建一个随机输入图像,形状为 (batch_size, in_channels, height, width)
input_image = torch.randn(1, 3, 32, 32)
# 创建一个卷积层
conv_layer = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
# 对输入图像进行卷积操作
output = conv_layer(input_image)
print(output.shape)
在这个示例中,我们创建了一个输入图像,然后使用nn.Conv2d创建了一个卷积层,并对输入图像进行卷积操作。输出特征图的形状取决于输入图像的形状、卷积层的参数以及卷积操作的方式。
四、应用场景
nn.Conv2d广泛应用于计算机视觉任务中,如图像分类、目标检测、图像分割等。它可以自动学习图像中的特征,提取有用的信息,从而提高模型的性能。
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
BASE_DIR = os.getcwd()
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from matplotlib import pyplot as plt
import random
import numpy as np
import sys
hello_pytorch_DIR = r"D:\\R report\\"
sys.path.append(hello_pytorch_DIR)
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train):
img_ = img_.detach().numpy() * 255
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(3) # 设置随机种子
# ================================= load img ==================================
path_img = os.path.join(r"D:\\R report\\", "a.jpg")
img = Image.open(path_img).convert('RGB') # 0~255
# convert to tensor
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img)
img_tensor.unsqueeze_(dim=0) # C*H*W to B*C*H*W
# ================================= create convolution layer ==================================
# ================ 2d
flag = 1
# flag = 0
if flag:
conv_layer = nn.Conv2d(3, 1, 3) # input:(i, o, size) weights:(o, i , h, w)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================ transposed
# flag = 1
flag = 0
if flag:
conv_layer = nn.ConvTranspose2d(3, 1, 3, stride=2) # input:(i, o, size)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================================= visualization ==================================
print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape))
img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_conv, cmap='gray')
plt.subplot(121).imshow(img_raw)
plt.show()
卷积前尺寸:torch.Size([1, 3, 4096, 3072])
卷积后尺寸:torch.Size([1, 1, 4094, 3070])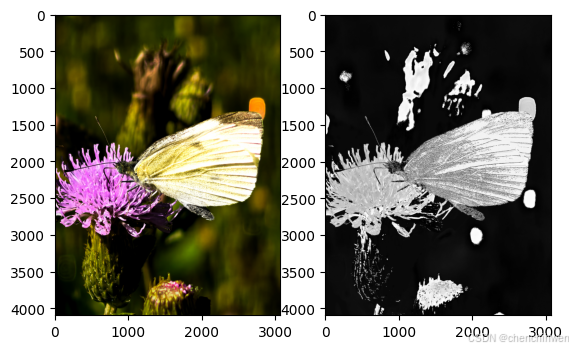
以下是对这段代码的详细解释:
一、环境设置和导入模块
- 设置环境变量
KMP_DUPLICATE_LIB_OK为TRUE,这通常用于解决在某些情况下可能出现的多线程库冲突问题。 - 获取当前工作目录并设置
BASE_DIR。 - 导入必要的模块,包括
torch.nn(用于构建神经网络层)、PIL(用于图像处理)、torchvision.transforms(用于图像变换)、matplotlib.pyplot(用于可视化)、random和numpy。
二、自定义函数定义
-
transform_invert函数:- 这个函数的目的是将经过一系列变换后的张量转换回 PIL 图像格式。
- 如果变换中包含
Normalize操作,它会根据归一化的均值和标准差对张量进行反归一化。 - 然后,将张量的维度顺序调整为
H*W*C(高度、宽度、通道数)。 - 如果张量的形状在通道维度上为 3,则将其转换为 RGB 模式的 PIL 图像;如果为 1,则转换为单通道的 PIL 图像。如果通道数不符合这两种情况,则抛出异常。
-
set_seed函数:- 用于设置随机种子,以确保实验的可重复性。它设置了 Python 的随机模块、NumPy 的随机生成器、PyTorch 的 CPU 和 GPU 随机生成器的种子。
三、设置随机种子
使用set_seed(3)设置随机种子为 3,确保后续的随机操作具有可重复性。
四、加载图像和进行变换
path_img指定了要加载的图像路径,使用Image.open打开图像并转换为 RGB 模式。- 通过
transforms.Compose创建一个图像变换对象,这里只包含了将图像转换为张量的操作。 - 将图像转换为张量并增加一个维度,使其形状变为
B*C*H*W(批量大小、通道数、高度、宽度)。
五、创建卷积层和进行计算
- 根据
flag的值选择创建二维卷积层或转置卷积层,并使用 Xavier 初始化方法初始化卷积层的权重。 - 对输入图像张量进行卷积操作,得到输出图像张量。
六、可视化结果
- 打印卷积前后图像张量的形状。
- 使用
transform_invert函数将卷积后的图像张量和原始图像张量转换回可显示的图像格式。 - 使用
matplotlib.pyplot进行可视化,将原始图像和卷积后的图像分别显示在两个子图中。


















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









