




七、MySQL进阶
· 事务
·事务:一组数据库的操作(SQL)集合,这个集合中的操作(SQL语句)要么都执行,要么都不执行。
·保证数据库的完整性和一致性。保证数据的安全。
案例: 银行转账:张三→李四转钱
注意
·MySQL的事务默认自动提交的,也就是说,当执行完一条DML语句时,MySQL会立即隐式提交事务。
·在数据库增、删、改时,才需要开启事务,查询编号改变数据内容。
·一组SQL都执行成功了,提交(commit);
任意一条语句执行失败,则回滚(rollback);
步骤
# 查看或设置事务提交方式
select @@autocommit ; -- 此时autocommit=1
set @@autocommit = 0 ;
# 开启事务
start transaction 或 begin ;
# 执行sql语句
select * from account where name = '张三';
update account set money = money - 1000 where name = '张三';
update account set money = money + 1000 where name = '李四';
# 提交事务或者事务回滚(二选一)
commit;或者rollback;
事务四大特性(ACID)
·原子性(Atomicity)
事务是最小操作单元,要么操作都成功,要么都失败。
·一致性(Consistency)
事务完成时,数据的状态要保持一致。
·隔离性(Isolation)
事务在执行时不受外部并发的影响。
·持久性(Durability)
事务一旦提交或回滚,他对数据库中的改变就是永远的。一旦提交就不能回滚,一旦回滚就不能提交。
数据库并发问题
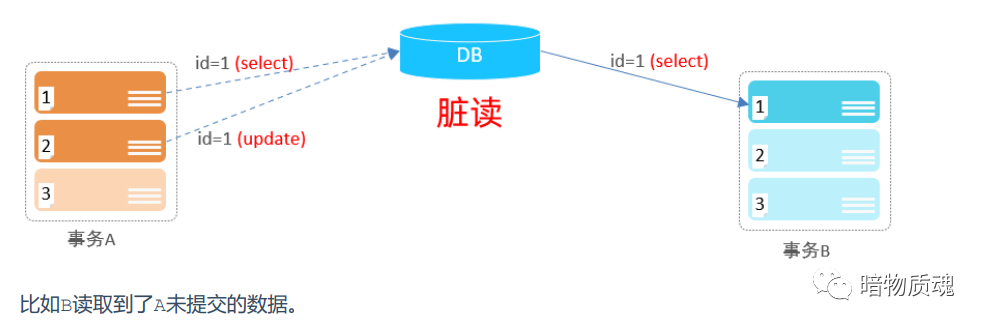
·脏读:一个事务读取到另外一个事务还没有提交的数据。(读到的内容和最终结果不一样)
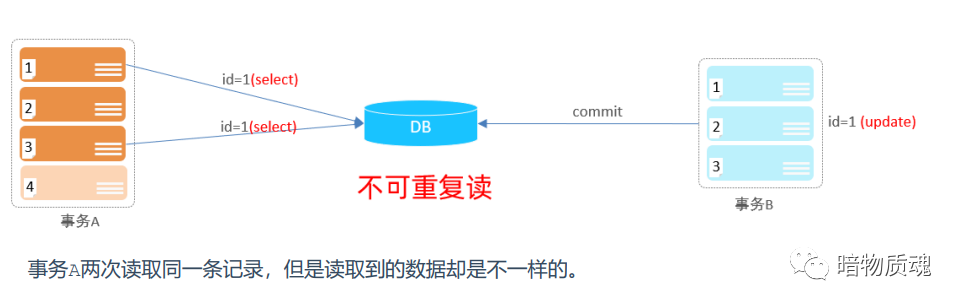
·不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同。
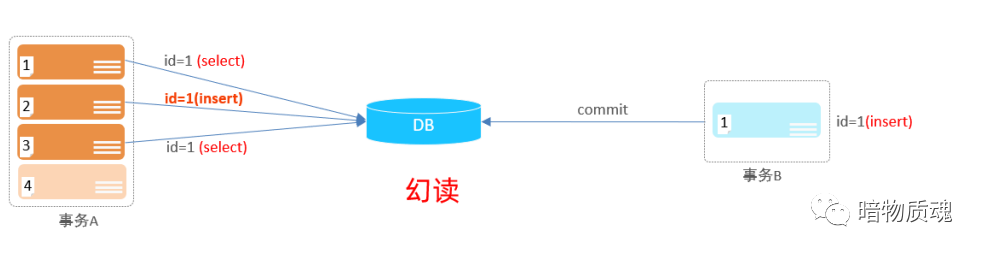
·幻读:一个事务按照查询条件查询数据时,没有对应数据行,但是在插入数据时,又发现这行数据已经存在,好像出现“幻影”。(比如同时修改)
事务隔离级别
·read uncommitted(读未提交)
允许读取未提交的数据,可能会遇到脏读。
·read committed (读已提交)
只能读取到已经提交的数据,可以避免脏读,但可能会出现不可重复读的问题。
·repeatable read(可重复读)
保证在同一个事务中,多次读取同一数据的结果是一致的,可以避免不可重复读的问题,但可能会出现幻读。
·serializable (可串行化、序列化)
最高的隔离级别,完全避免脏读、不可重复读和幻读,但性能较低。
· 视图
·视图(View)是虚拟的表,通常用于简化复杂查询。
视图中的数据来源于基表(基础表)。基表发生变动,视图会受到影响。视图中的数据是动态生成的,视图就是一条select语句执行后返回的结果集。
·视图的功能:
1、简化复杂查询
2、提升安全性
3、数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
步骤
# 创建
create view 视图名称 as select 字段名 from 表名 where 条件;
# 使用
select * from 视图名称;
# 修改或更新(原表也会改)
update view 视图名称 set 字段=新值;
create or replace view 视图名称 as select 字段 from 表名;
# 删除(对原表无影响)
drop view 视图名称;
视图特点
a.MySQL 视图是一个虚拟的表,它由一个 SQL 查询定义,并且不存储实际的数据;
b.视图的定义保存在数据字典内,创建视图所基于的表称为“基表”;
c.删除视图不会影响到“基表”,删除或修改“基表”会影响到视图;
d.视图的数据来自于查询执行的结果,并且可以像表一样被查询、更新和删除;
e.视图提供了一种简化复杂查询的方法,并且可以用来限制用户对数据库中特定数据的访问;
f.在视图中插入数据,都是基于“基表”的插入条件,会将数据添加到“基表”中的;
g.在视图中修改、删除数据,也都是基于“基表”的插入条件,也会将数据修改、删除作用到“基表”中的。
视图的使用规则
- 视图必须有唯一命名;
- 在mysql中视图的数量没有限制;
- 创建视图必须从管理员那里获得必要的权限;
- 视图支持嵌套,也就是说可以利用其他视图检索出来的数据创建新的视图;
- 在视图中可以使用order by,但是如果视图内已经使用该排序子句,则视图的ORDER BY将覆盖前面的ORDER BY;
- 视图不能索引,也不能关联触发器或默认值;
- 视图可以和表同时使用。
· 存储引擎
·存储引擎:实现对数据增、删、改、查、事务、索引的数据库核心组件。
MySQL的组成:
·连接层:通过网络或本地socket和客户端通信,登录、授权认证等安全方案。
·服务层:接受SQL语句,进行语句分析,下发指令让引擎层执行。
·引擎层:存储引擎真正地负责MySQL中数据的存储和提取,不同的需求可以使用不同的引擎。[核心]
·存储层:文件系统,用于存储数据,并完成与存储引擎的交互。
常用引擎:(后附总结表格)
·InnoDB(默认):支持事务(ACID)、支持行级锁、支持外键、聚簇索引,适合高并发、高安全场景,金融、电商、订单系统
·MyISAM:不支持事务、支持表级锁,适合对事务没有要求、读多写少的场景
·Memory:内存型存储引擎,支持哈希(hash)索引,适合缓存临时数据。
优点:读写速度快;
缺点:断电数据会丢失。(重启也会丢失数据)
·CSV:文本存储,列与列默认用逗号分隔;
优点:可直接用文本编辑器查看或修改数据,兼容性强(适合与其他系统交换数据);
缺点:性能差,不支持事务、索引、锁、
适合简单的数据存储例如:日志
|
常用引擎 |
特点 |
适用场景 |
|
InnoDB(默认) |
支持事务(ACID)、支持行级锁、支持外键、聚簇索引 |
高并发、高安全场景,如金融、电商、订单系统 |
|
MyISAM |
不支持事务、支持表级锁 |
对事务没有要求、读多写少的场景 |
|
Memory |
内存型存储引擎,支持哈希(hash)索引; |
缓存临时数据 |
|
CSV |
文本存储,列与列默认用逗号分隔; |
简单的数据存储,例如日志 |
# 使用存储引擎
create table mytab(
id int,
name varchar(30)
) engine = memory;
示例2
create table mytab1(
id int not null,
name varchar(30) not null
) engine = csv;

















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









