




· 索引
index(索引、目录、下标)
定义:加快数据查询的一类数据结构。类似于字典的目录,可以帮助我们快速找到我们需要的数据内容。
注意:索引是和存储引擎关联的,不同的存储引擎提供的索引类型是不同的。
优点:数据量大时,对于查询速度有较明显的提升(加速查询)。
缺点:会占用一定的存储空间;
会影响增删改的效率(降低写入速度);
索引的分类
l 数据结构(索引“长什么样”)
- BTREE索引:最常见的索引类型,大部分索引都支持"B树"索引。InnoDB、MyISAM
- 所有数据存储在叶子节点;
- 叶子节点通过双向链表连接,支持范围查询的高效遍历。
- 非叶子节点仅存储索引键,用于快速定位区间,减少单次查询的IO次数。
- 高度通常为 3-4 层,可存储千万级数据(单节点存储多个键值)。
- HASH 索引:Memory键值对,哈希函数,使用哈希算法。
- 哈希算法:将所有数据相加,经过取模(x%y)运算,得到固定长度的结果。这个结果就是键key,对应一个内存地址,将数据存放进去。查找数据时,通过计算找到key对应的地址,直接取值。
- R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,专门给 “地理空间数据” 用的,比如经纬度、地址坐标。就像地图上标了各个地点的坐标,能快速找到 “某个区域内的地点”。
l 逻辑结构(创建索引——为什么创建这个索引)
- 主键索引:是数据库中一种特殊的索引,用于唯一标识表中的每一条记录。具有唯一性、非空性、自动索引(定义主键自动添加索引)、优化查询、数据完整性等特性。
- 唯一索引:索引列的值必须唯一,但允许有空值;一个表可以有多个唯一索引,但只能有一个主键索引。
- 普通索引(单值索引、单列索引):即一个索引只包含单个列,一个表可以有多个单列索引
- 复合索引(多列索引):即一个索引包含多个列,与单值索引(只在一个列上创建)不同,复合索引能够提高基于多个列的查询效率
- Full-text (全文索引):全文索引也是MyISAM的一个特殊索引类型,主要用于长文本的关键词搜索,InnoDB从Mysql5.6版本开始支持全文索引
总结:
- 按数据结构:BTREE 是 “万能目录”,HASH 是 “快速钥匙”,R-tree 是 “地图坐标”。
- 按逻辑结构:主键是 “身份证”,唯一索引是 “不能重复的标签”,普通索引是 “单个列的目录”,复合索引是 “多列组合目录”,全文索引是 “文章关键词搜索工具”。
索引的数据结构

索引的使用(加上索引后表结构的key会显示MUL)
# 创建普通索引、单值索引
create index 索引名 on 表名(字段名);
# 创建唯一索引
create unique index 索引名 on 表名(字段名);
# 创建主键索引
alter table 表名 add primary key(字段名);
# 创建复合索引
create index 索引名 on 表名(字段1,字段2,……);
# 创建全文索引
create fulltext index 索引名 on 表名(字段名);
# 查看索引
show index from 表名;或者
show keys from 表名;
# 删除索引
drop index 索引名 on 表名;
# 添加一个唯一索引、、普通索引、、全文索引
alter table 表名 add unique/index/fulltext(这里需要修改什么类型就写什么单词) 索引名(字段);
· 锁
锁:锁是数据库中用于解决并发事务问题的机制,通过 “占位” 操作实现对数据的临时控制,其核心作用是解决多个事务同时操作数据时的并发冲突,从而避免脏读、不可重复读、幻读等问题。
步骤
# 查看锁
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
select 数据库,表名,索引名,锁类型,锁模式,锁的数据 from performance_schema.data_locks;
备注:
performance_schema 是 MySQL 内置的一个特殊数据库(系统库),专门用于监控数据库的运行状态、性能指标、锁信息、事件等底层数据,相当于数据库的 “监控中心”。
data_locks 是 performance_schema 库下的一个具体表,专门存储当前数据库中所有活跃的锁信息(包括表锁、行锁、锁类型、锁模式等)
# 加锁
lock tables 表名 read;
# 解锁
unlock tables;
# 加锁
lock tables 表名 write;
# 解锁
unlock tables;
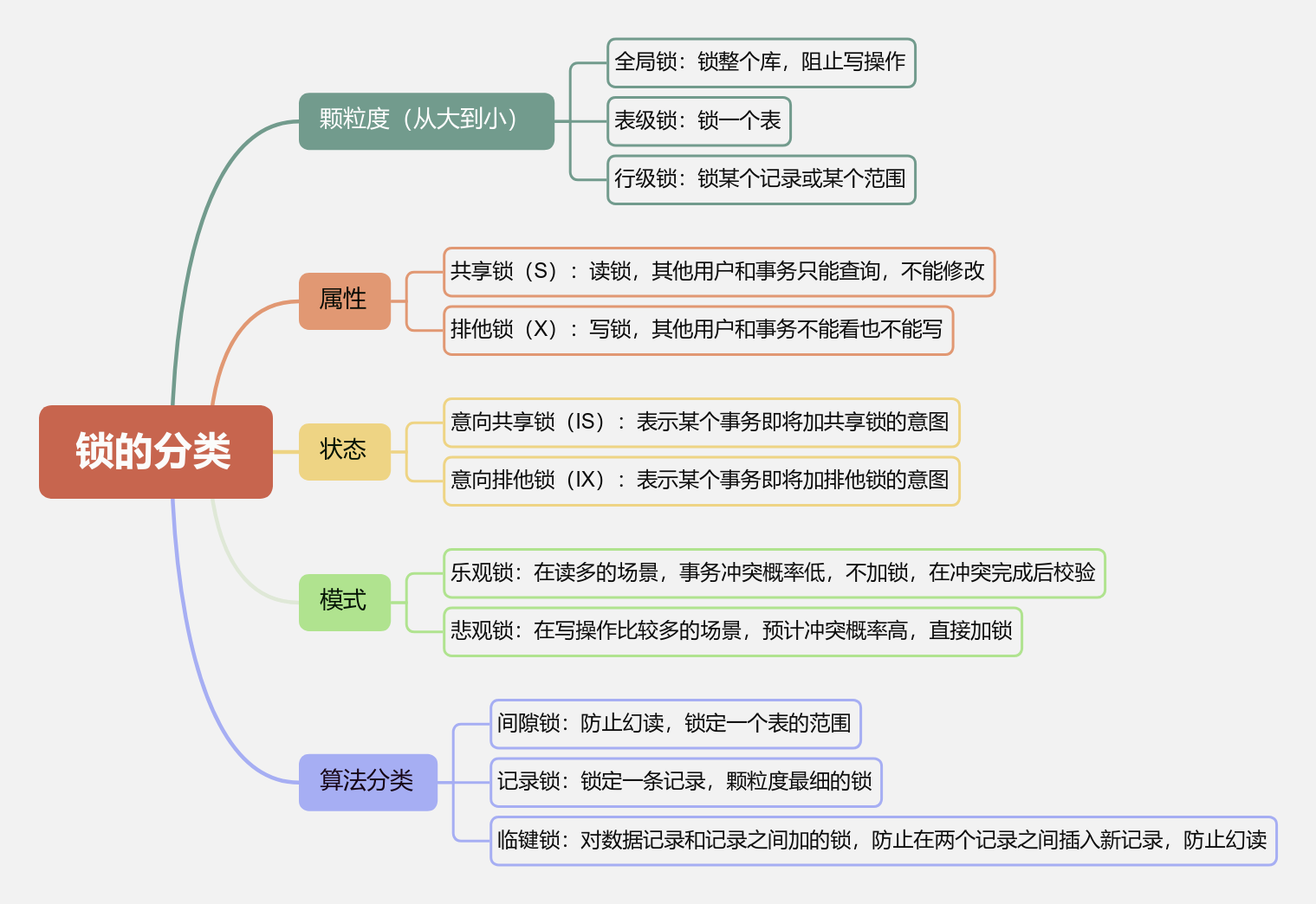
锁的分类
死锁
死锁:互相等待的"死循环"
- 原因:
事务1持有表a的排他锁,请求表b的排他锁;
事务2持有表b的排他锁,请求表a的排他锁;
然后事务1等待事务2释放表b的锁,事务2等待事务1释放表a的锁,
形成循环等待,导致死锁。
- 解决:
>InnoDB自动检测死锁,回滚其中一个事务(通过innodb_deadlock_detect=ON 控制)。
>优化:按固定顺序加锁(如按主键排序)、缩短事务时长、减少锁持有时间。
1. 设计事务
·减少事务的持续时间: 尽量将事务的执行时间缩短,减少持有锁的时间。
·按照相同的顺序访问资源: 确保所有事务按照相同的顺序访问锁资源,避免循环依赖。
·使用合理的锁粒度: 尽量避免对整个表进行锁定,尽量使用行级锁。
2. 处理死锁
·重试机制: 在应用程序中捕获死锁异常(通常是错误代码1213),并实现重试机制。重试机制可以在事务被回滚后自动重试,以期获得成功。
while True:
try:
# 执行数据库操作
break
except DeadlockException:
# 捕获死锁异常,重试
continue
·使用合理的隔离级别: 在事务中选择适当的隔离级别。通常,使用较低的隔离级别可以减少死锁的概率,但可能会增加脏读等其他问题。
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
mysql锁机制的核心是平衡并发性能与数据一致性,选择锁策略时需结合业务场景:
- 高并发事务:优先InnoDB行锁,确保索引有效(避免表锁),合理设置隔离级别(读已提交减少间隙锁)。
- 低并发/读多写少:MyISAM表锁或InnoDB表锁(如日志表)。
- 强一致性场景:悲观锁(SELECT...FORUPDATE),确保写操作互斥(如库存扣减)。
- 读多写少场景:乐观锁(版本号机制),减少锁竞争(如浏览量统计)。
- 全库备份:避免全局锁,用热备份工具(如xtrabackup)。

















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









