




- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
这周来看一下Transformer是怎么将文本转换成向量,然后又输入到模型处理并得到最终的输出的。
文本输入处理
词向量
和常见的NLP任务一样,我们会先使用词嵌入(Embedding)算法,将文本序列转换成词向量。实际应用中的向量维数很高,不方便演示,以4维的词向量为例。
于是当我们输入的文本中有3个词时,就会生成三个维度为4的向量。
而在实际的应用过程中,我们会同时给模型输入多个句子,如果每个句子的长度不一样,模型就没有办法批量处理了,所以这里会有一个pad操作,选择一个合适的最大长度,达不到的用0填充,超出的进行截断。
最大序列长度是一个超参数,通常希望越大越好,但是更长的序列会占用更大的显存,所以还是要权衡。
位置向量
输入序列中的每个单词被转换成词向量后,还需要加上位置向量才能得到该词的最终向量表示。
Transformer对每个输入的词向量都加上了位置向量。这些向量有助于确定每个单词的位置特征、句子中不同单词之间的距离特征。
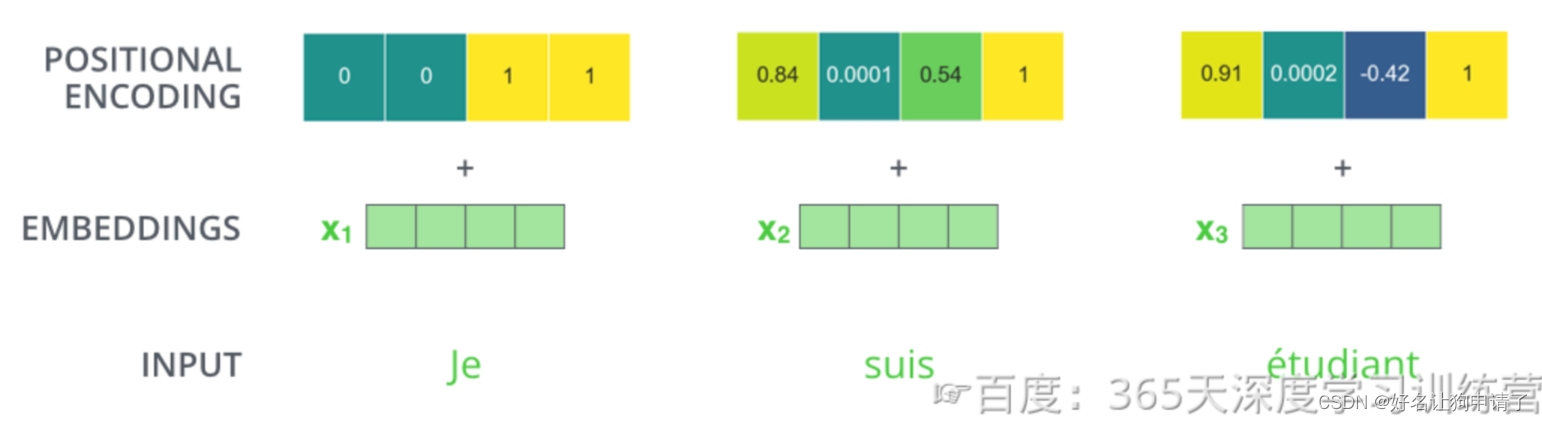
假设词向量和位置向量的维度是4,下图展示了一种可能 的位置向量+词向量。
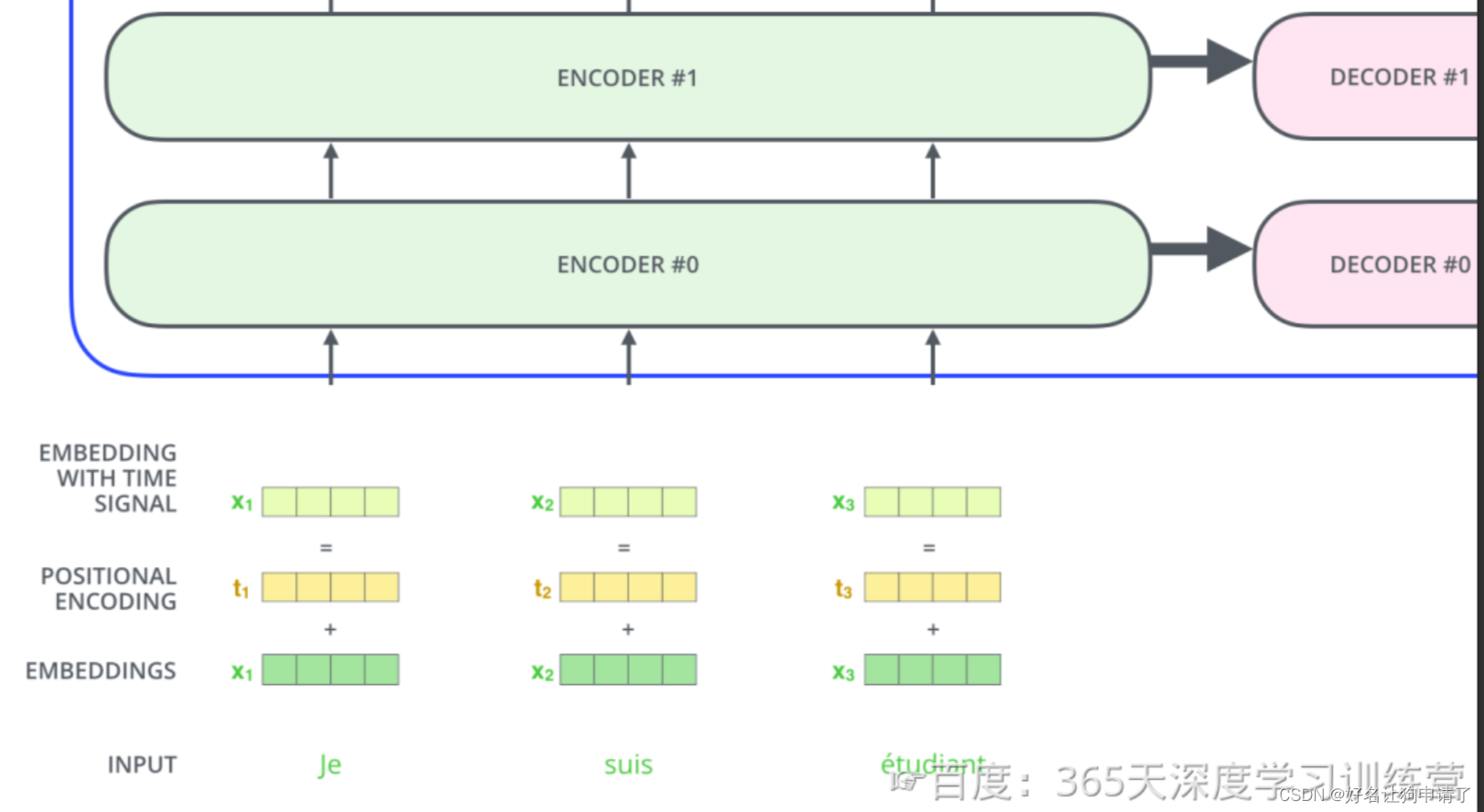
编码器 Encoder
编码器的输入是经过上一步的文本输入处理后的向量,这个向量将从编码器的第一层开始,第一层编码器输出的同样是一样向量序列,然后以此类推再送入下一层编码器。如图所示,在第一层中,向量先进入Self-Attention块,然后进入FFN神经网络,最后得到当前层的新向量作为输出。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1984
1984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









