







连接联合与重塑
一、 分层索引:在一个轴上有多个索引层级
-
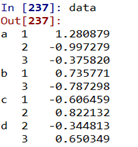
用列表创建分层索引: data=pd.Series(np.random.randn(9),
index=[[‘a’,‘a’,‘a’,‘b’,‘b’,‘c’,‘c’,‘d’,‘d’],[1,2,3,1,3,1,2,2,3]])
-
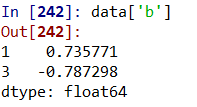
分层索引:与普通索引一样: 轴索引 data.loc[第一层级,第二层级,第三层级….]
data[‘b’]#取第一层级的“b‘列 data.loc[:,2:4] #取第一层级的全部行和第二层级的2-4行

-
取消分层索引: unstack()
data.unstack() data.unstack().stack()
data.unstack().stack()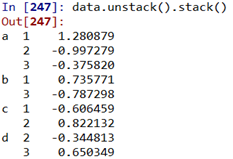
-
在列轴上也能创建分层索引,方法一样 columns=[[……][……]]
-
对层级命名:data.index.names=[‘key1’,’key2’]
-
层级排序: 对调两个层级的顺序用swaplevel
data.swaplevel(‘key1’,’key2’) 对调key1和key2的位置,
data.swaplevel (0,1) 对调第0层级和第1层级的位置 -
层级排序 按第0层级进行排序 data.sort_index(level=0,axis=0)
-
使用某一列作为索引:set_index
让某一列变成索引: data2=data.unstack().set_index(2) #把‘2‘这一列拿出来作为索引
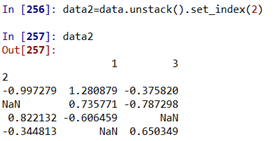
使用reset_index可以取消分层data.unstack().reset_index(2)
二、 联合merge (P226) merge(df1,df2,left_on,right_on,left_index,right_index,how,on….)
- 将两个DataFrame进行联合并合并: pd.merge(df1,df2,on=’key’)
df1和df2根据key列进行联合,相同的值会合并在一起,这里默认是内连接,即只显示他们的公共部分,交集 - 两个表的列名不相同,进行合并时需要指出通过哪个列联合
pd.merge(df1,df2,left_on=’key1’,right_on=’key2’) 左表df1的连接键是key1,右边表df2连接键是key2 - 规定连接的方式 pd.merge(df1,df2,on=’key’,how=’outer’)
一般默认内链接,outer -外连接 left-左连(也就是包含左表的所有行)right-右连 - 如果连接键不同,就会形成多对多的连接,产生笛卡儿积
- 多个键进行联合时,可以给连接键传入一个列表
Pd.merge(df1,df2,on=[’key1’,’key2’],how=’outer’) - 把索引当作连接键来进行合并: left_index=true 表示左表的索引为连接键
pd .merge(df1,df2,left_index=true, right_on=’key’) 连接键是左表的索引和右边的key列 - 根据多个索引进行合并:用join
Df1.join(df2) 表示根据df1和df2的索引进行连接合并
Df1.join([df2,df3]) 表示根据df1、df2、df3的索引进行合并,等同于concat
三、 表的连接concat(obj,axis,join,keys,names,ignore) - 将多个表按行或者按列拼接在一起:
pd.concat([s1,s2,s3],axis=0) j将s1,s2,s3按行方向拼接在一起
axis=1 按列方向拼接在一起 - 指定连接的方式:join 默认是外连 join=’inner’ 内连
pd.concat([s1,s2,s3], join=’inner’) #之连接相同的行列(内连接) - 指定用于拼接的轴:
pd.concat([s1,s2,s3], join_axes=[‘a’,’c’,’b’]) 拼接时值会出现a’,’c’,’b三行 - 连接后创建分层索引,可以使用set_index命令,也可以使用concat的内置参数keys:
pd.concat([s1,s2,s3],axis=0, keys=[‘one’,’two’,’three’]) 表示在行方向上创建一个one’,’two’,’three的第0层级的分层索引
pd.concat([s1,s2,s3],axis=1, keys=[‘one’,’two’,’three’]) 表示在列方向上创建一个one’,’two’,’three的分层索引
同时可以使用names命名生成的轴层级:pd.concat([s1,s2,s3],axis=1, keys=[‘one’,’two’,’three’],names=[‘upper’,lower’]) - 无相关性连接: ignore_index=true df1和df2不沿着轴保留索引,而是产生一段新的索引(长度为df1和df2的长度之和)
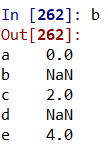
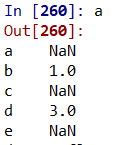
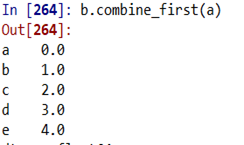
- 联合重叠数据(通过连接两个表来修补缺失值:) a.combine_first(b)
两表的结构相似时,进行联合,相同的部分重叠,缺失的部分补齐
四、 重塑与透视
- 堆叠:stack() 将列标签透视到行轴上去,实质是将列标签作为一个分层索引,


- 拆堆:unstack() 将行标签透视到列轴上,实质是取消分层索引,默认情况是从内层开始拆,也可以传入层级序号来选择拆堆的层级 eg:unstack(0) #拆除第0 层级

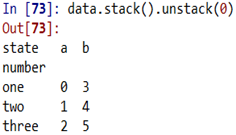
- 拆分有可能会产生缺失值,而堆叠一般会过滤缺失值,传入参数dropna=False将不会过滤缺失值 : data.stack(dropna=False)
- 将“长”表透视为“宽”表 P240:pivot(要作为行索引的列,要作为列索引的列,填充值)
将一列变换为多列,类似于数据透视表,重建索引轴
eg: data=ldata.pivot(‘date’,item’,’value’) #‘date为行标签,item为列标签,填充value
pivot的方法等价于set_index创建分层索引,然后再调用unstack将一个索引层返回到列上: data=ldata.set_index([‘date’,item’]).unstack(‘item’) - 将“宽”表透视为“长”表 P242: pd.melt(需要变换的表,[分组指标])
将多列合并成一列,实质是按照某一列的值分组,
eg: data2=pd.melt(df,[‘key’]) #将key列作为分组指标
区分:
- stack和set_index:
(1)stack是堆叠,将列标签透视到行轴上,创建一个分层索引
(2)set_index也可以创建分层索引,但是是将某一列的值作为分层索引 - unstack和reset_index:
(1)unstack是取消分层索引,将拆除的列返回在列轴上
(2)reset_index也是取消某一列的分层索引,将拆除的列返回在列数据值当中,而不是标签上

















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









