




近日,一段数字人视频引发了全网热议,画面中,一个外观与真人无异的女子在说话的同时缓缓走动。这也让不少网友质疑,视频中所出现的会走路的数字人物并非是由技术生成,而是真人拍摄。“数字人不都是固定不动的吗?哪有会走路的数字人呢?”一位网友说道。

为了弄清这段视频的制作方式,小编特意在反复观看的基础上,结合多方资料和业内人士的佐证,最终确认该段视频中所出现的人物为技术生成的数字人无疑。而为了确保万无一失,小编还根据该视频所显示的文字和背景中所出现的灰.豚AI数字人这一信息,就“视频中人物是否为数字人”这一问题致电官方,并得到了肯定的回答。

“这段视频是我们内部在灰.豚数字人系统中完成的作品,而其中所出现的人物则是我们通过最近上线的灰豚MotionAI大模型生成的动态数字人,除了大家看到的走路之外,她还能完成跑步、跳舞,甚至开车等动作。”他们技术部总监罗先生说道。
同时,罗先生还表示,在制作该数字人视频之前,灰豚MotionAI大模型已经经历了半年的公测期,再三确认足够成熟之后,才选择于近日正式发布。“作为数字人源码厂商,我们这边技术更新了之后,肯定是要同步到私有化技术输出、OEM数字人系统以及数字人源码部署的全部客户企业,出现再小的岔子,影响都会无限放大。”罗先生说道。

而在此之前,他们已经在其所搭建的数字人系统内,搭建了海量公模和照片克隆、AI数字人克隆系统、AI声音人克隆系统等静态数字人克隆功能源码,再加上它所拥有的三维重建、TTSA+音视频驱动技术、ARKit表情识别及AIGC以及“1+N”数字人训练模式等技术资源,所生成的静态数字人无论是基本外观,还是表情、情绪和肢体动作等细节都与真人无限接近,还兼具成长属性和行业属性以及文本或语音进行驱动等多种效果。
在此前提下,此次MotionAI大模型的发布,不仅意味着他们所生成的数字人从固定不动到自由行动的转变,更是能够通过数字人与观众之间的交流感,让它所搭建的数字人系统中所具备的AI绘画、AI文案、AI直播语音互动、文生视频和AI复活以及客户企业所定制的其他功能发挥出更大的效果,进一步帮助中小型企业等用户群体实现降本增效。
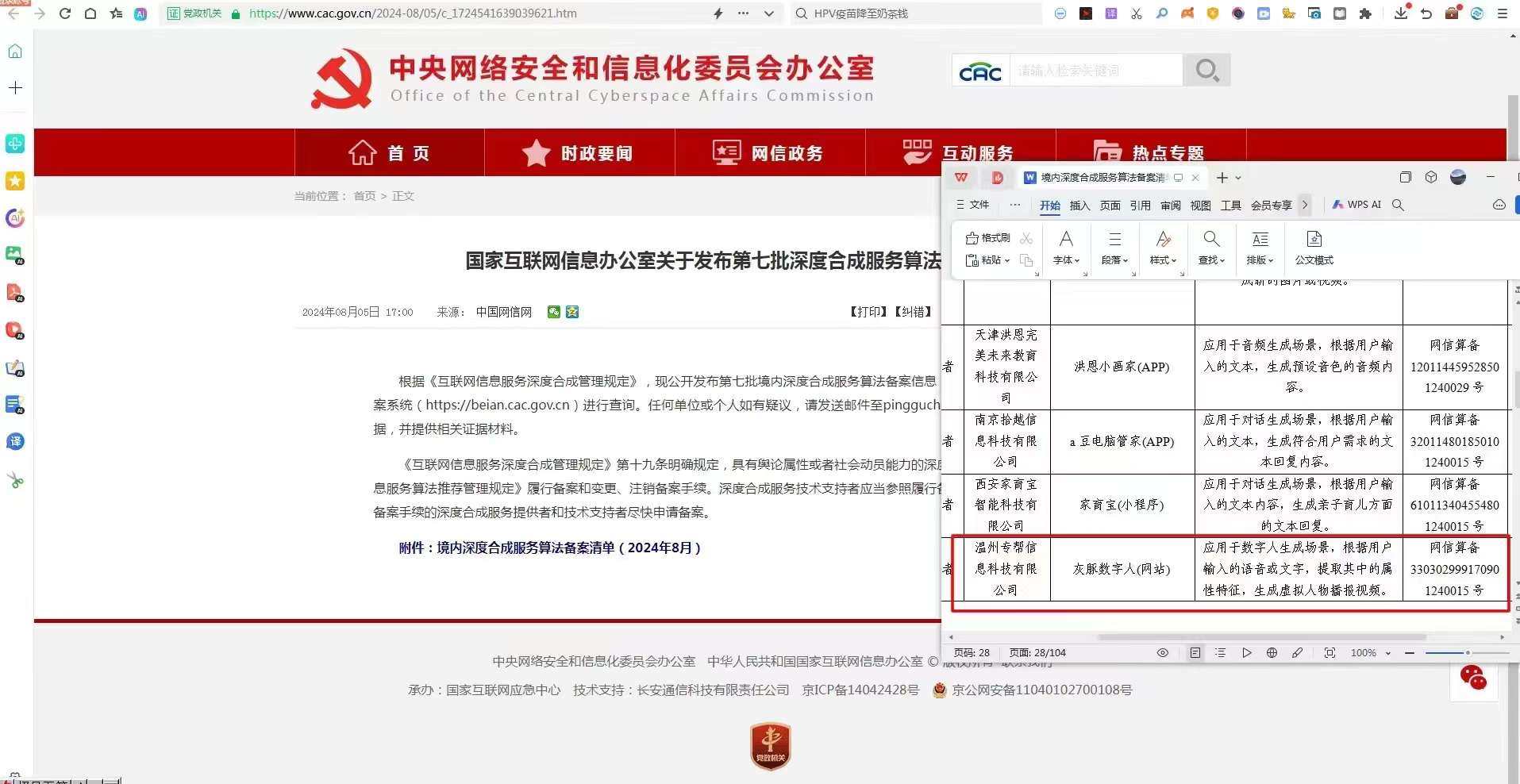
目前,灰豚MotionAI大模型已经取得中央网信办人工智能算法备案,并完成了私有化技术输出、OEM数字人系统以及数字人源码部署等全部客户企业数字人系统中的同步应用。在此基础上,他们所提供的国内领先AI智能运营和公域平台引流方案、一对一保姆式帮扶、专业陪跑以及招商扶持等多项运营支持势必会在数字人系统的落地方面发挥更大的效用。
至于这些效用对会走路的数字人成为数字人中的“顶流”会产生多大的推力,有会给数字人行业创造多少新的惊喜,让我们拭目以待!

















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









