



上一篇文章为大家详细介绍了3D数字人是什么,那么,有形象、会表达、够专业的3D数字人,对企业和普通人意味着什么呢?
企业梦寐以求的24小时在线又不会喊累的数字员工,能否变成现实?
个人能用数字人完成工作,实现“躺着赚钱”吗?
AI时代下,曾经娱乐巨头才能做出来的3D内容,又该如何走进千家万户、突破“内容壁垒”呢?
或许你还没有意识到,3D数字人已经带来了一场变革。今天我们就来聊聊,3D数字人对企业和个人都有哪些重要的影响。
3D数字人≈白领AI化,24h在线工作不是梦
在一家公司里,往往有法务、财务、产品、市场、HR和销售等白领岗位,这些从事脑力活动的知识从业者,日常需要做文字、沟通和表达等工作。
企业需要平衡员工的工作时间、产出和薪酬,即便有业务需要,也不能让员工无限加班。
如果,有员工能24小时×365天一直在线,还能保持高质量标准化的工作产出就好了。
每个人需要休息和生活,显然做不到不吃不喝不睡觉地去工作。
但是,现在有了3D数字人,TA可以满足老板们的“幻想”,成为全年无休的“优秀员工”了!
换句话说,3D数字人是企业白领的AI化,也是企业在视频化AI时代中,解决人才和业务规模化增长的“杀手锏”。
首先,在组织人效方面,企业经常面临着金牌员工数量有限、培养耗时且难以规模化复制的难题,其工作成果也难沉淀为企业知识资产。
3D数字人作为企业各部门忠诚的“金牌员工”,能为企业沉淀数字化的知识资产,在与用户的每次交互中了解需求,不断迭代企业的知识资产,帮助每个员工站在企业最高认知上发挥特长。
其次,在业务增长方面,企业员工难以同时在不同地方与众多客户沟通交流,限制了业务拓展效率。
3D数字人能对外代表企业形象,成为7*24 小时在线的数字员工,实在全渠道、规模化地与用户交流,提升转化率。
此外,3D数字人也可以充当金牌销售,在不同渠道用最佳状态为客户介绍产品,不仅能在社交媒体做产品种草,还能作为金牌主播直播带货,持续迭代销售能力,促进业务规模化增长。
通过视频和直播等交互方式,3D数字人可以完成销售、客服、培训和营销等各类工作,还不会任性地离职,不会喊苦喊累,同时保持高质量的工作产出和工作态度,帮助企业持续吸引粉丝和目标消费者。
以前企业需要招10个不同岗位员工才能完成的工作,现在可以用更低的成本搭建一个“3D数字人”员工矩阵。
比如用【3D数字人智能客服+3D数字人金牌销售+数字人代言人IP】组成一个“王炸团队”,包揽售前、售中和售后的工作,还可以任意实现数字人员工几十倍、上百倍地规模化扩张。

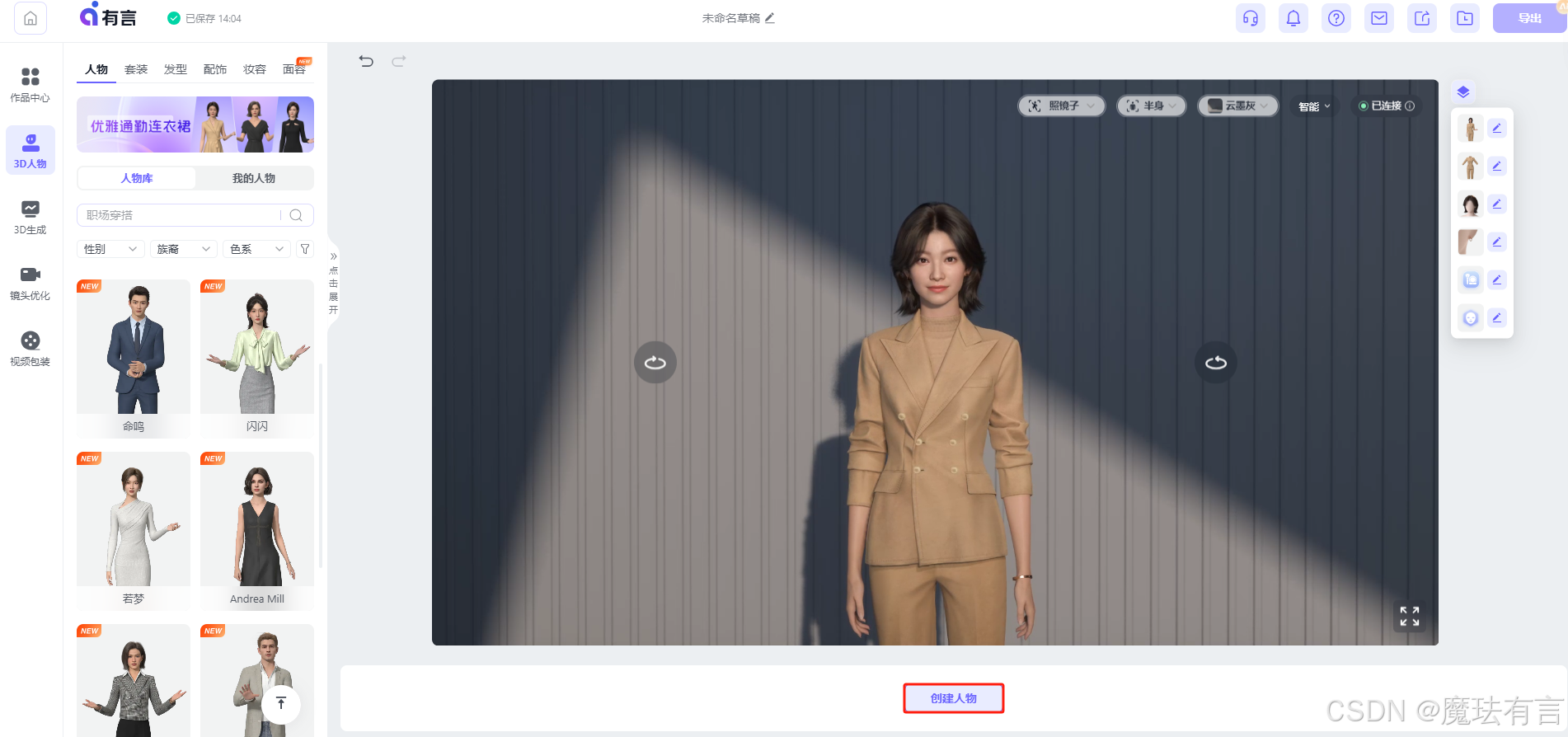
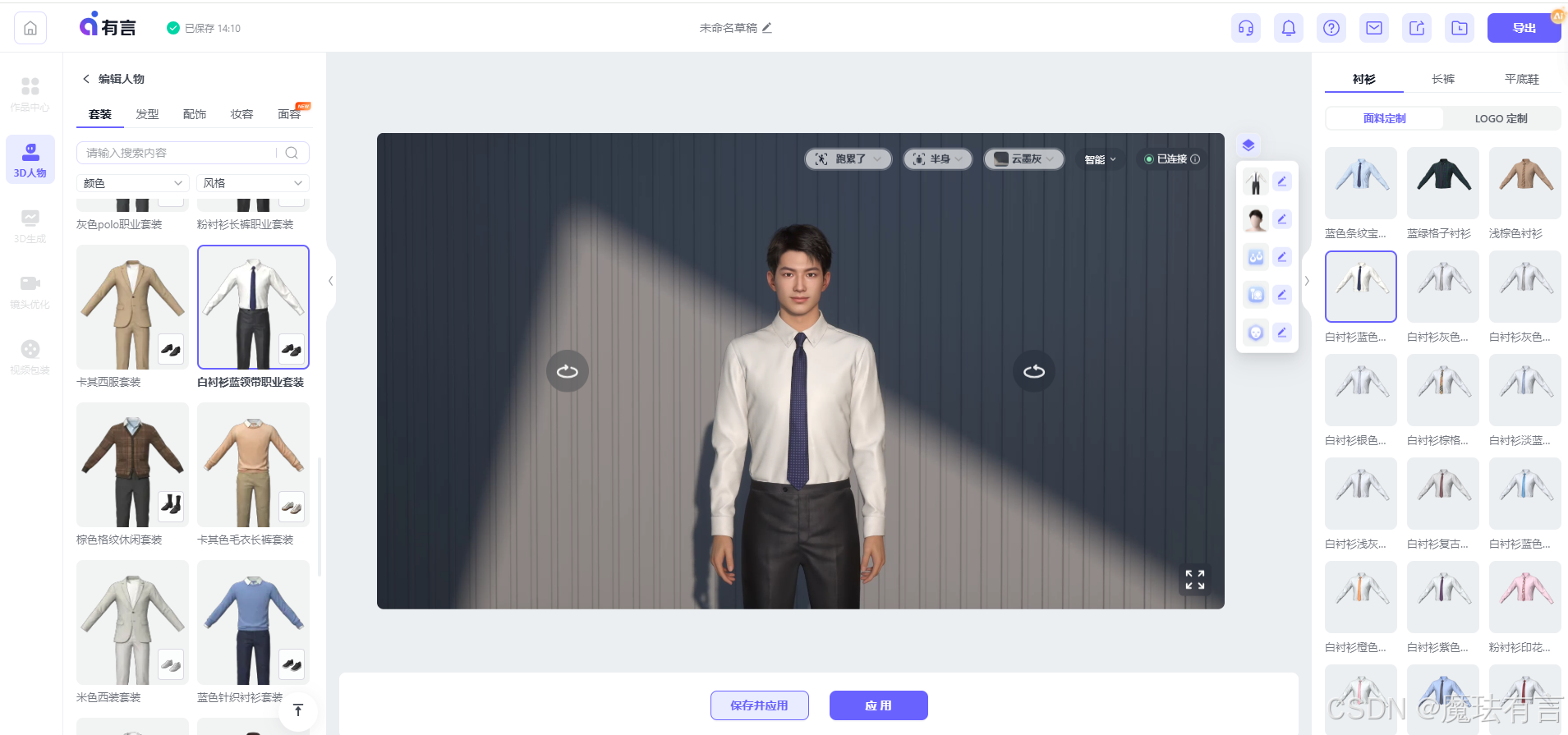
此外,3D数字人还会“72变”,面容、妆容、服装、发型、配饰、声音和场景都可以任意改造和搭配,你可以随心所欲地“造人”。
在不同的业务场景下,3D数字人可以灵活变装,像真人根据不同场合改变穿着一样;
你还能赋予它们不同的“性格特点”,选择端庄严肃或俏皮活泼的音色,让3D数字人“完美”胜任不同的岗位。
比如,在发布会场景等严肃场景,你可以为3D数字人挑选西服等正装,配上端庄大气的主持人音色,打造一个高大上的3D数字人主持人。
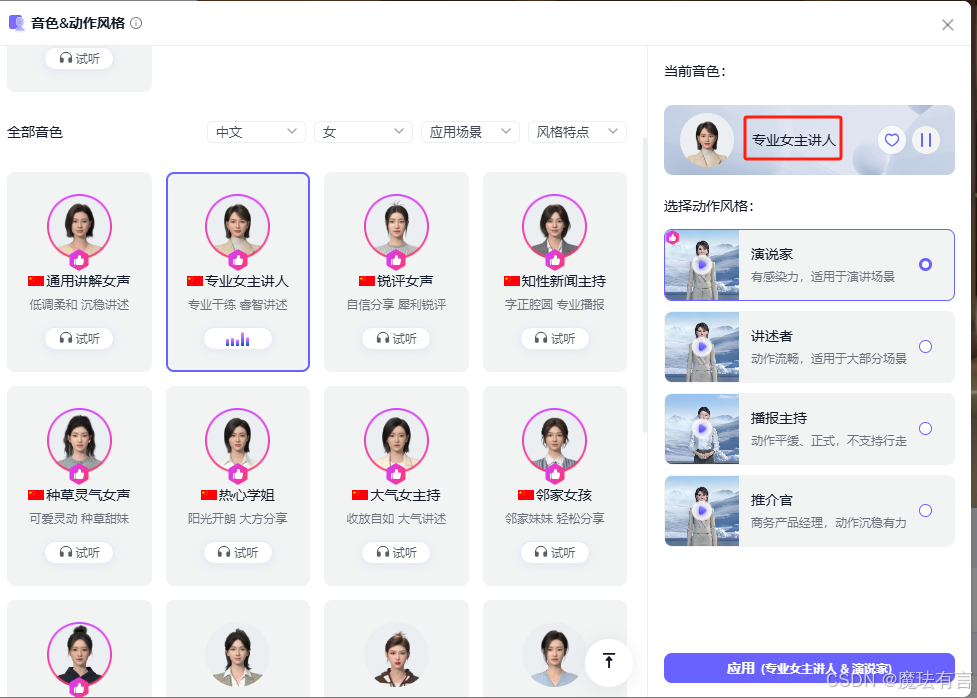
在种草营销等轻松的场景,你可以选择则更具视觉张力的妆容、发型、配饰与服装搭配,结合灵动活泼的主播种草音色,拥有一个媲美“李佳琦”的数字人主播;
你甚至可以按照节日等不同情况选择假日“限定”妆造,更好地契合各种业务情境的沟通交流。

可以说,3D数字人是企业在视频化、可交互的AI时代,解决组织人效和业务规模化增长的最优解。
普通人能用3D数字人做什么?
AI时代下,不仅企业需要3D数字人提高生产力,每个普通人也需要一个属于自己的3D数字人,更好且更高效地表达内容。
对于个人来说,3D数字人是个人在视频化、可交互视频的数字分身,是与他人沟通的重要表达工具。
一方面,内容视频化的潮流势不可挡,但传统的视频和直播内容生产周期长、成本高。
录制前得化妆准备、录制中说错得重录、录制后要后期剪辑包装,此外,还要有出色的表达能力和专业布景的场地,才能呈现出不错的视觉效果。
另一方面,个人传统的内容生产模式,无法实现同时面对不同群体,做不同内容沟通和交流。
有没有工具能代替真人出镜录制,最好还能承包布景、剪辑和后期等前期后期工作呢?
3D数字人可以!
作为一种表达工具,3D数字人能替代个人出镜录制,实现低成本且高效地产出高质量内容。
比如,自媒体博主能借助3D数字人,无需经历拍摄、后期等繁琐流程,就能轻松生成用于社交媒体的视频;
老师们能够用3D数字人把PPT课件转化为生动的视频课件,大大减少了制作内容的时间成本,还提高了教学质量,能用生动的视频吸引学生的注意力,达到更好的教学效果。
3D数字人不仅提高了内容生产的效率和质量,还打破了时间和空间限制,解决了多渠道的交互问题。
比如,知识博主可以使用3D数字人直播,无需搭建专业直播间,在家就能开展专业级的直播与粉丝互动,还能实现 1v1、7×24 小时的持续沟通交流;
此外,老师可以通过3D数字人一键开播与学生和家长交流;
医生和护士再也不用担心分身乏术忙不过来,3D数字人能同时为所有患者叮嘱术前术后注意事项,还能1对1地做好患者沟通和答疑。

这意味着,3D 数字人能让每一个普通人能够在不同渠道与他人进行全方位、不间断的沟通交流,极大地拓展了内容的传播和交互。
在AIGC的冲击下,每个人需要一种更高效的方式做表达,在视频化时代用优质的内容提高自己的影响力,如今,3D数字人,就是最好的选择。
从PGC到UGC到AIGC,人人都能用3D数字人的时代来了!
过去,内容行业经历了从PGC(专业生产内容)到UGC(用户生产内容)的变化。
曾经3D内容的制作和生产被巨头和专业人士“垄断”,只有好莱坞导演、头部娱乐集团和技术大佬们才能“烧钱”做出3D内容。
比如,3D电影《阿凡达》的成本动辄上亿美金,中国首款3A游戏《黑神话:悟空》每小时的开发成本大约在1500万元到2000万元。
别说普通人,这样以千万为单位计算的时间成本、以帧为单位制作的时间成本,很多企业都难以承担。
不过,随着AIGC的出现,内容产业迎来了新一轮的变革。
以前“高不可攀”的3D内容,现在每个人都能几乎无门槛使用了!
大荧幕上的3D人物可以出现在手机里,出现在抖音、快手、小红书、视频号和B站等社交媒体上,每个人都能像好莱坞导演一样,定制自己的3D数字人,做3D视频、打造IP,变得前所未有地简单!
现在,魔珐打造了一站式3D数字人AI视频创作平台——有言。
魔珐有言凭借其全栈AIGC能力,打破了那道横亘在人们与3D内容之间的高墙,让每家企业、每个人都能够即刻拥有专属的3D数字人。
无需拍摄、无需剪辑、无需后期,3D数字人,AI视频一键生成。
凭借强大的文生文、文生语音、文生3D动画、文生3D镜头等技术,有言的3D数字人可以依据不同的场景与内容,生成自然又高质量的表情、手势、走路动作和声音,一键产出3D数字人视频。
如果你是创业者,即便没有高昂的预算请明星代言、拍广告大片,也用3D数字人制作出好莱坞电影级的品牌宣传视频;
还可以用3D数字人做直播、客服和销售,24小时在线和消费者及客户互动;
你还可以定制专属数字人IP,对内做培训,对外做代言,实现业务增长。
如果你是个人创作者,你可以用3D数字人实现内容规模化的生产,一个人就能成为一家MCN;
即便你有“口吃”,也能用3D数字人流畅地表达你的奇思妙想;
如果你有“容貌焦虑”不想出镜,可以用数字分身替你出镜做视频;
即使你还不会说一口流利的英文,也能用3D数字人做地道的英语演讲和工作汇报,甚至还能一键做出多语种视频,消灭语言障碍、面对全球观众。
终于,“躺着赚钱”不再是白日做梦,3D数字人不仅能替你出镜做视频,还能替你与粉丝互动和直播,替你24小时“在线打工”。
有言3D数字人不仅实现了企业和普通人之间的“技术平权”,也为每个普通人和创业者都带来了一场“内容平权”。

















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









