




博主介绍: 大家好,我是想成为Super的Yuperman,互联网宇宙厂经验,17年医疗健康行业的码拉松奔跑者,曾担任技术专家、架构师、研发总监负责和主导多个应用架构。
近期专注: DeepSeek应用,RPA应用研究,主流厂商产品使用,开源RPA 应用等
技术范围: 长期专注java体系,软件架构,DDD,多年Golang、.Net、Oracle等经验
业务范围: 对传统业务应用技术转型,从数字医院到区域医疗,从院内业务系统到互联网医院及健康服务,从公立医院到私立医院都有一些经历及理解
*** 为大家分享一些思考与积累,欢迎持续关注公众号:【火星求索】 ***
AnythingLLM 不仅仅是另一个聊天机器人。它是一个全栈应用程序,这意味着它融合了从数据处理到用户界面的所有技术优势。最好的部分?它是开源且可定制的。这意味着如果您有技能,您可以根据自己的喜好进行调整。或者,如果您像我一样更喜欢现成的东西,那么它开箱即用,效果非常好。
AnythingLLM 更专注于文档知识库与问答场景,自带向量检索管理,可“多文档整合”,接入 Ollama 后实现本地化问答。
一、安装ollama
ollama官网:Ollama
下载地址:Download Ollama on macOS
打开以后注册并下载即可
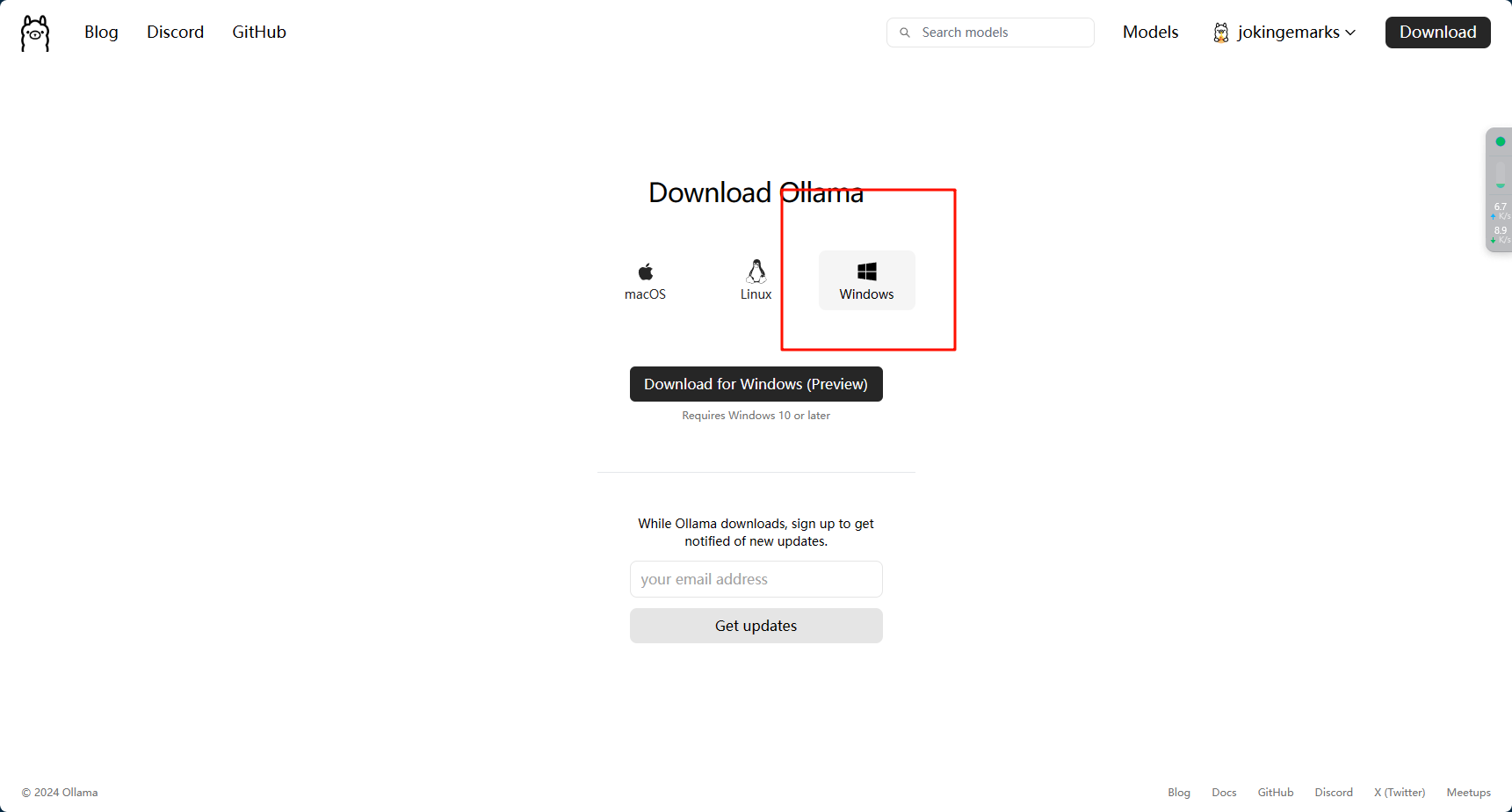
安装没有什么好说的,找到自己的系统安装即可,因为我的电脑没有搞虚拟机,所以就直接安装Windows的版本了
二、下载模型并运行ollama
安装ollama以后,通过管理员打开powershell
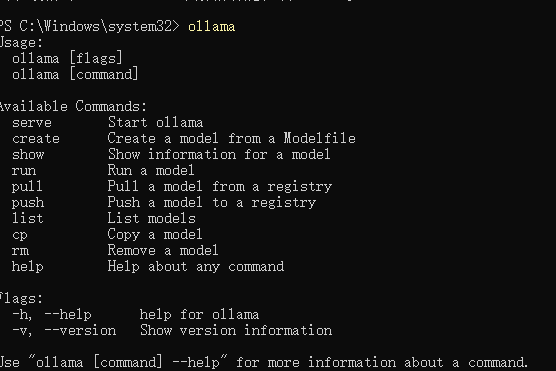
输入ollama,只要出现下面这些,说明安装成功了
打开ollama的模型的网页:library
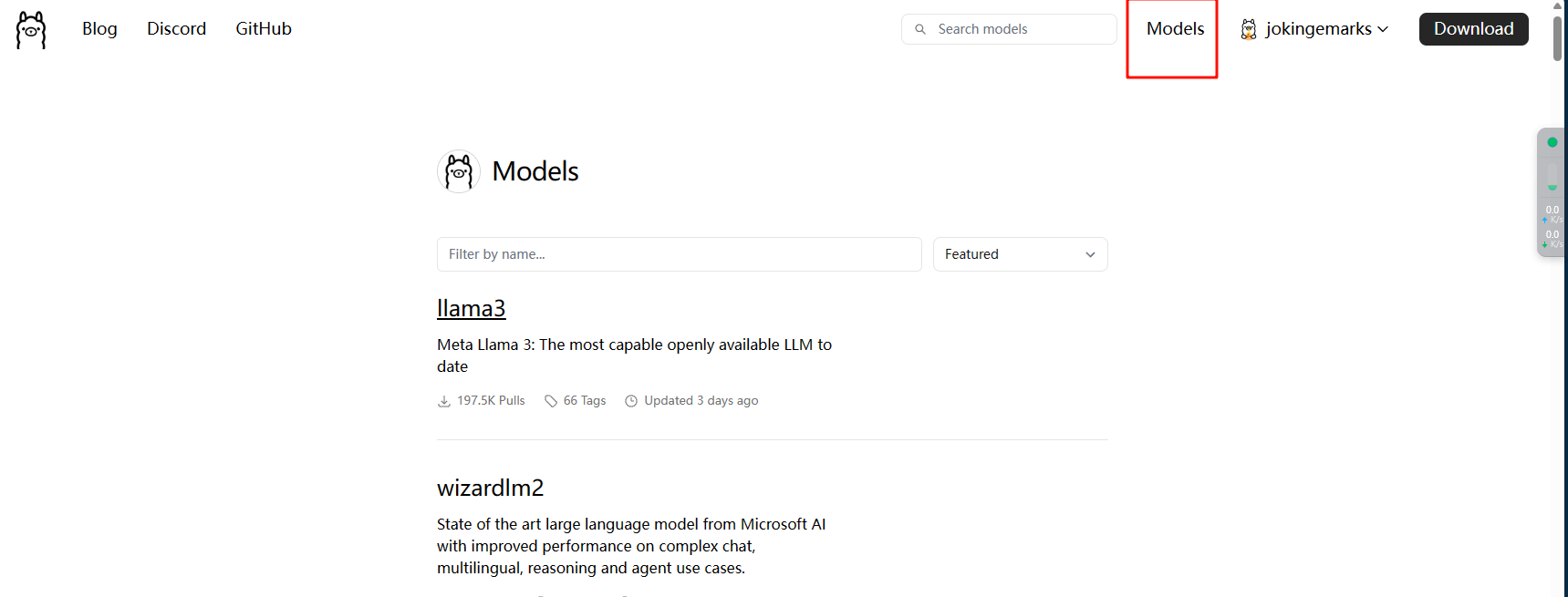
我们以llm3为例,双击进入
常用的命令有
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
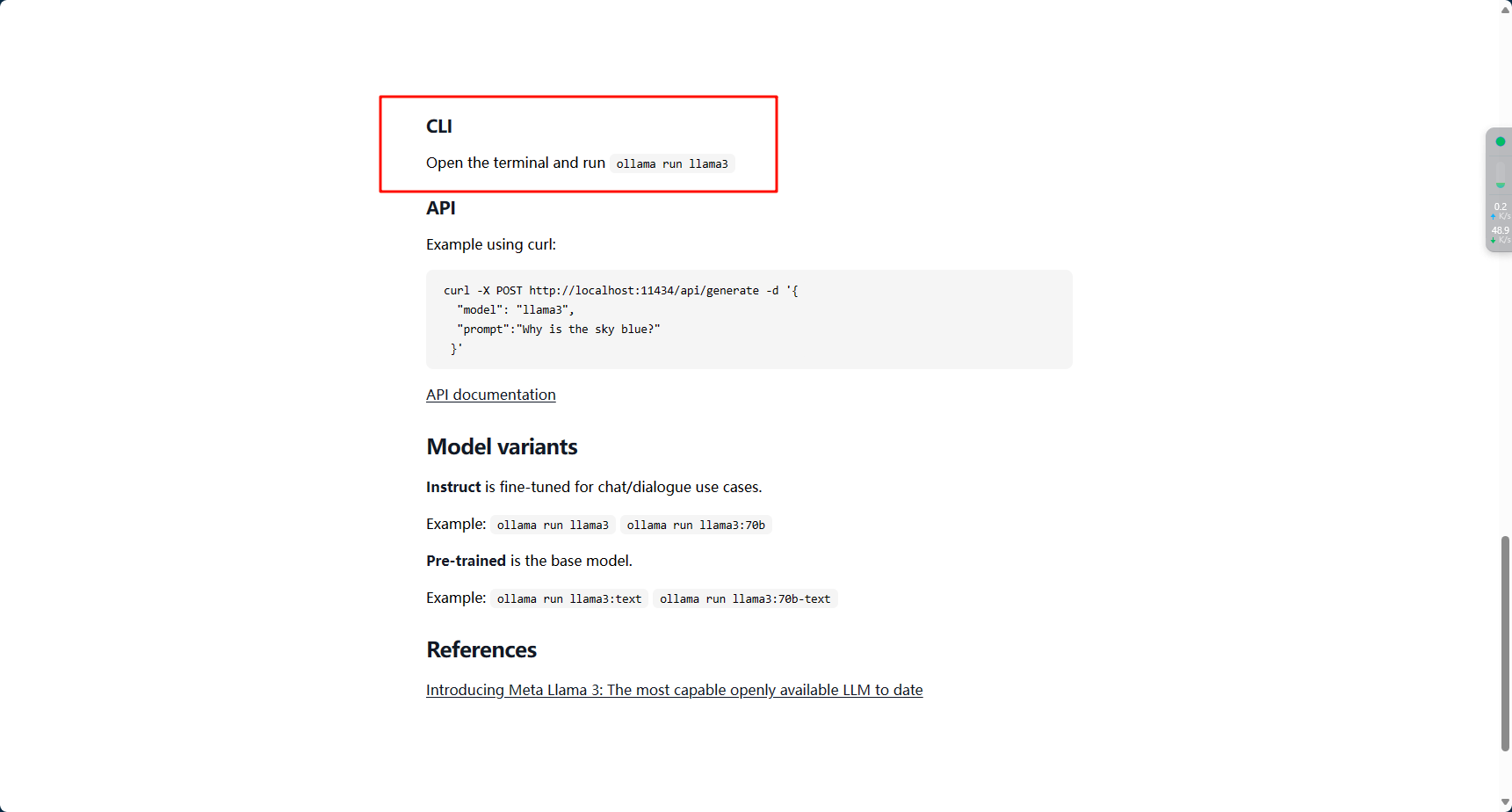
可以看到页面中让执行ollama run llama3即可
一般来说run是用来跑模型的,但是如果本地没有这个模型的话,ollama会自动下载
PS:国内的网络问题不知道有没有解决,下载模型的时候偶尔速度很快,但是很多时候速度很慢以至于提示TLS handshake timeout,这种情况建议重启电脑或者把ollama重启一下(不知道为啥,我同步打开GitHub的时候速度会明显快一些,可能也是错觉)
下载完成以后我们输入ollama list可以查下载了哪些模型

这里我们直接输入ollama run llama3,就可以开始对话了
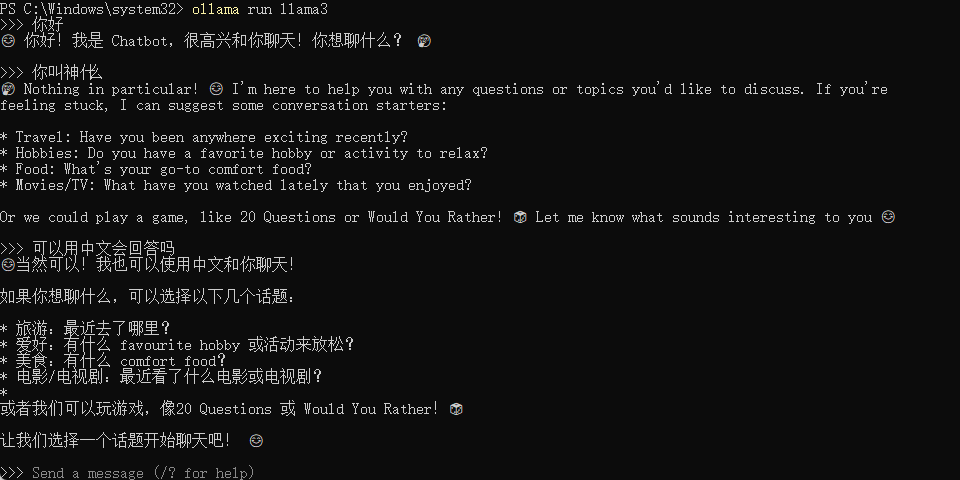
三、下载并配置AngthingLLM
AngthingLLM官网:https://useanything.com
下载链接:Download AnythingLLM for Desktop
同样的选择对应的系统版本即可
在使用前,需要启动Ollama服务
执行ollama serve,ollama默认地址为:http://127.0.0.1:11434
然后双击打开AngthingLLM
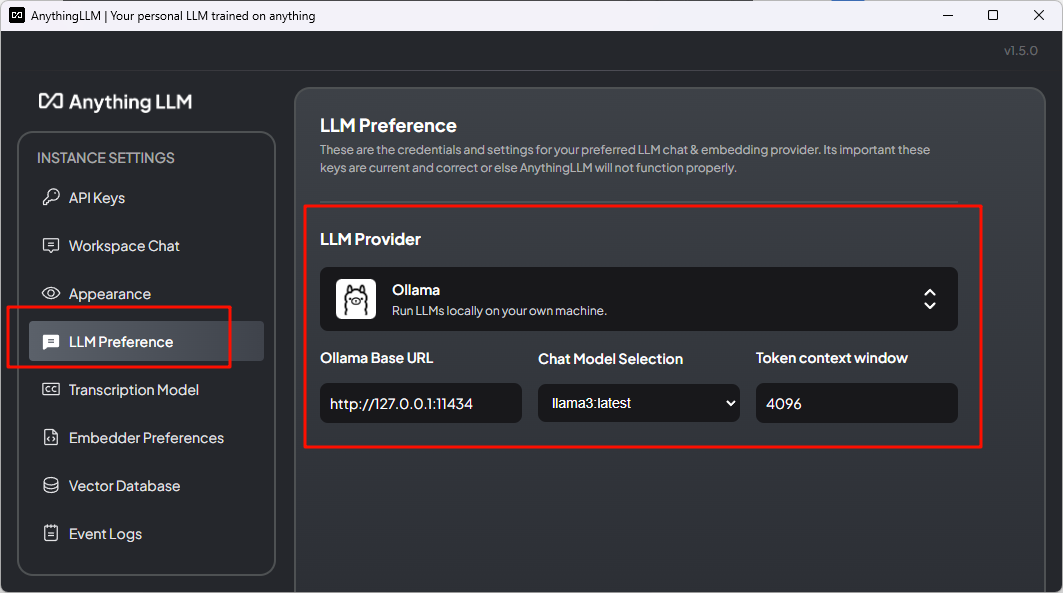
因为我已经配置过,所以不好截图最开始的配置界面了,不过都能在设置里面找到
首先是LLM Preference,LLM provider选择ollama,URL填写默认地址,后面的模型选择llama3,token填4096
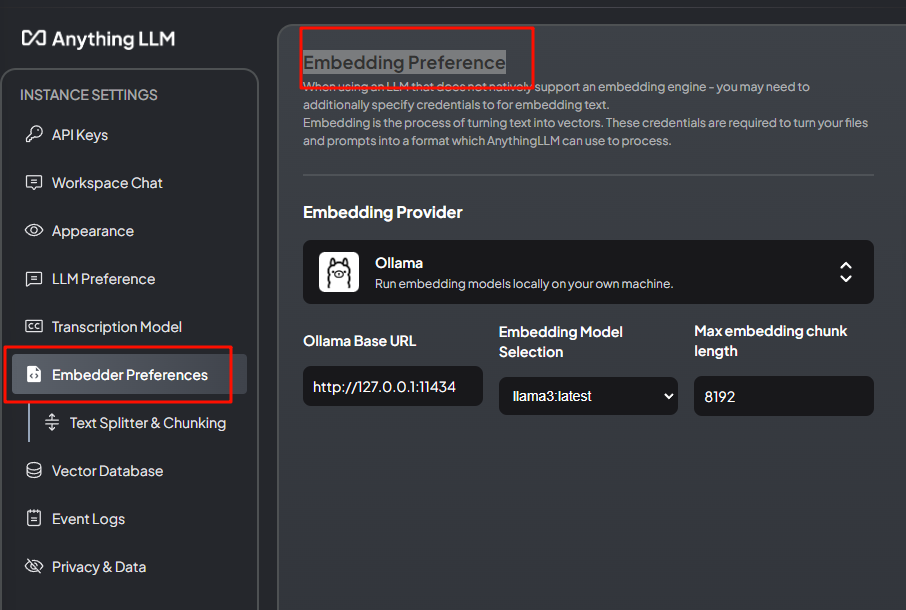
Embedding Preferenc同样选择ollama,其余基本一致,max我看默认8192,我也填了8192
Vector Database就直接默认的LanceDB即可
此时我们新建工作区,名字就随便取,在右边就会有对话界面出现了
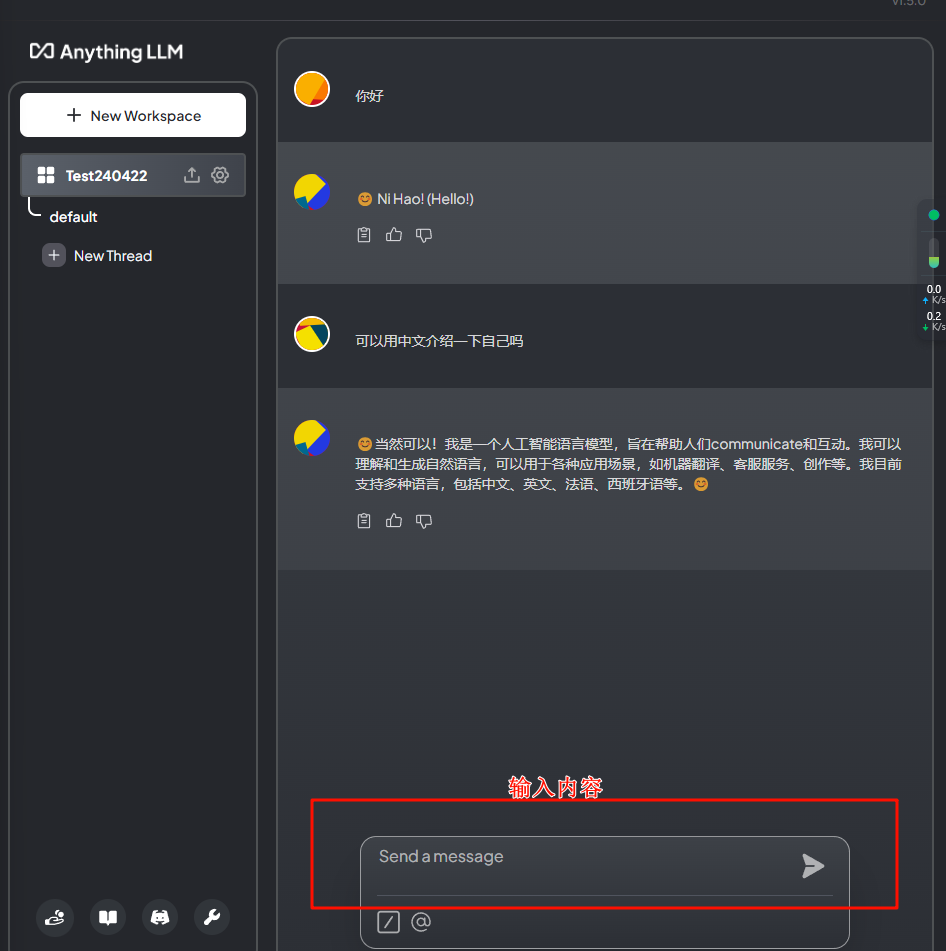
此时你就有了自己本地的语言模型了
是不是很简单,费时间的地方其实就在下载模型的时候,本来想用Open WebUI,但是电脑没有搞docker,就用AngthingLLM了,后续有空搞个docker用open webui
如果模型实在下不下来,也可以搞离线模型
Windows系统下ollama存储模型的默认路径是C:\Users\wbigo.ollama\models,一个模型库网址:魔搭社区
挺全的,但是说实话,llama3-8B我感觉挺拉胯的,可能英文好一些,中文的话使用不如qwen
最后
如果你觉得这篇文章对你有帮助,欢迎点赞、转发、评论!
公众号【火星求索】发送deepseek即可获取【清华大学DeepSeek 从入门到精通 系列】四连弹,以及可以获取收集整理的各种资料。



















 1327
1327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











